Las arquitecturas de centro de datos de uso general (tales centros de datos todavía se usan ampliamente hoy en día) han funcionado bien sus tareas en el pasado, pero la mayoría de ellas han alcanzado recientemente sus límites de escalabilidad, rendimiento y eficiencia. La arquitectura de dichos centros de datos generalmente usa el principio de asignación de recursos agregados: procesadores, discos duros y anchos de canales de red.
En este caso, se produce un cambio en el volumen de recursos utilizados (aumento o disminución) en dichos centros de datos de forma discreta, con coeficientes predeterminados. Por ejemplo, con un coeficiente de 2, podemos obtener esta serie de configuraciones:
- 2CPU, 8 GB de RAM, 40 GB de almacenamiento;
- 4 CPU, 16 GB de RAM, 80 GB de almacenamiento;
- 8CPU, 32GB RAM, 160GB de almacenamiento;
- ...
Sin embargo, para muchas tareas, estas configuraciones son económicamente ineficaces, a menudo algunas configuraciones intermedias son suficientes para los clientes, por ejemplo: 6CPU, 16GB RAM, 100GB de almacenamiento. Por lo tanto, llegamos a la comprensión de que el enfoque universal anterior para la asignación de recursos del centro de datos es ineficaz, especialmente cuando se trabaja con grandes datos de manera intensiva (por ejemplo, datos rápidos, análisis, inteligencia artificial, aprendizaje automático). Los usuarios en tales casos desean tener capacidades de control más flexibles de los recursos utilizados, necesitan la capacidad de escalar de forma independiente los procesadores, la memoria y el almacenamiento de datos, los canales de red. El objetivo final de esta idea es crear una infraestructura de componentes flexible.
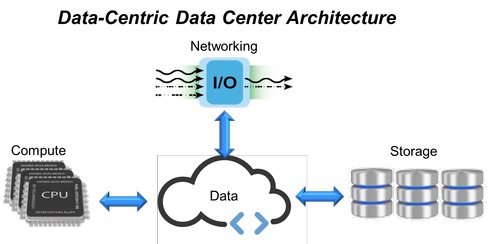 Fig. 1. Arquitectura del centro de datos centrada en datos.
Fig. 1. Arquitectura del centro de datos centrada en datos.En respuesta a tales requisitos, llegaron los centros de datos de infraestructura hiperconvergente (HCI, Infraestructura hiperconvergente) que combinan todos los recursos informáticos, sistemas de almacenamiento y canales de red en un solo sistema virtualizado (Fig. 1). Sin embargo, en esta estructura, para expandir los límites de la escalabilidad (agregar nuevos sistemas de almacenamiento, memoria o canales de red), se requieren servidores adicionales. Esto predeterminó la aparición de un enfoque basado en la expansión de la infraestructura HCI con módulos fijos (cada uno de los cuales contiene procesadores, memoria y almacenamiento de datos), que en última instancia no proporciona el nivel de flexibilidad y rendimiento predecible que tanto demanda en los centros de datos modernos.
HCI ya está siendo reemplazado por infraestructuras desagregadas por componentes (CDI, Infraestructuras desagregadas componibles), que están diseñadas para superar las limitaciones de las soluciones de TI convergentes o hiperconvergentes y proporcionar una mayor flexibilidad para los centros de datos.
El advenimiento de la infraestructura desagregada por componentesPara superar los problemas asociados con la arquitectura de los centros de datos de propósito general (una proporción fija de recursos, subutilización y redundancia), primero se desarrolló una infraestructura convergente, que consta de recursos de hardware preconfigurados dentro de un solo sistema. Los recursos informáticos, los sistemas de almacenamiento y las interacciones de red en ellos son discretos y los volúmenes de su consumo se configuran mediante programación. Luego, las estructuras convergentes se transformaron en hiperconvergentes (HCI), donde todos los recursos de hardware se virtualizan, y la asignación de las cantidades necesarias de recursos informáticos, almacenamiento y canales de red se automatiza a nivel de software.
A pesar de que HCI integra todos los recursos en un único sistema virtualizado, este enfoque también tiene sus inconvenientes. Para agregar al cliente, por ejemplo, una cantidad significativamente mayor de almacenamiento, RAM o expandir el canal de red, en la arquitectura HCI, esto requerirá el uso de módulos de procesador adicionales, incluso si no se usarán directamente para operaciones informáticas. Como resultado, tenemos una situación en la que, al crear centros de datos que son más flexibles que las arquitecturas anteriores, todavía usan elementos de construcción inflexibles.
Según las encuestas de usuarios de TI de centros de datos corporativos medianos y grandes, aproximadamente el 50% de la capacidad de almacenamiento total disponible se asigna para uso real, mientras que las aplicaciones usan solo la mitad del volumen de almacenamiento asignado, y el tiempo de CPU también se usa en aproximadamente un 50%. Por lo tanto, el enfoque que utiliza sistemas estructurales fijos conduce a su baja carga y no proporciona la flexibilidad necesaria y el rendimiento predecible. Para resolver estos problemas, se creó un modelo desglosado, que es fácil de ensamblar a partir de módulos funcionales separados utilizando herramientas de software con una API abierta.
La infraestructura desagregada por componentes (CDI) es una arquitectura de centro de datos en la que los recursos físicos (potencia informática, almacenamiento y canales de red se consideran servicios). Proporcionar a las aplicaciones de los usuarios todos los recursos necesarios para cumplir con su carga actual ocurre en tiempo real, logrando así un rendimiento óptimo dentro del centro de datos.
Modelo de anti-convergencia desglosado por componentes
Los servidores virtuales en una infraestructura desagregada por componentes (Fig. 2) se crean al vincular recursos de grupos independientes de sistemas informáticos, almacenamiento y dispositivos de red, en contraste con HCI, donde los recursos físicos están vinculados a servidores HCI. De esta forma, los servidores CDI se pueden crear y reconfigurar según sea necesario de acuerdo con los requisitos de una carga de trabajo particular. Al utilizar el acceso API al software de virtualización, la aplicación puede solicitar los recursos necesarios, recibiendo la reconfiguración instantánea del servidor en tiempo real, sin intervención humana, un paso real hacia un centro de datos autogestionado.
 Fig. 2: Modelo hiperconvergente (HCI) y componente desagregado (CDI).
Fig. 2: Modelo hiperconvergente (HCI) y componente desagregado (CDI).Una parte importante de la arquitectura CDI es la interfaz de comunicación interna, que garantiza la separación (desagregación) de los dispositivos de almacenamiento de un servidor en particular de su potencia informática y su provisión para su uso por otras aplicaciones.
NVMe-over-Fabrics se usa aquí como el protocolo principal. Proporciona los retrasos de transferencia de datos de extremo a extremo más pequeños entre las aplicaciones y los dispositivos de almacenamiento. Como resultado, esto permite que CDI brinde a los usuarios todos los beneficios del almacenamiento de conexión directa (baja latencia y alto rendimiento), brindando capacidad de respuesta y flexibilidad a través del intercambio de recursos.
 Fig. 3. La estructura de NVMe-over-Fabrics.
Fig. 3. La estructura de NVMe-over-Fabrics.La tecnología NVMe (Non-Volatile Memory Express) es una interfaz optimizada, de alto rendimiento y baja latencia que utiliza una arquitectura y un conjunto de protocolos diseñados específicamente para conectar SSD a servidores a través del bus PCI Express. Para CDI, este estándar se ha ampliado a NVMe-over-Fabrics, más allá de los servidores locales.
Esta especificación permite que los dispositivos flash se comuniquen a través de la red (utilizando diferentes protocolos de red y medios de transmisión; consulte la Figura 3), proporcionando el mismo alto rendimiento y un retraso de transmisión tan bajo como los dispositivos NVMe locales. Al mismo tiempo, prácticamente no hay restricciones en la cantidad de servidores que pueden compartir dispositivos NVMe-over-Fabrics o en la cantidad de dispositivos de almacenamiento a los que puede acceder un servidor.
Las necesidades de las aplicaciones intensivas de big data actuales superan las capacidades de las arquitecturas tradicionales de centros de datos, especialmente en términos de escalabilidad, rendimiento y eficiencia. Con la llegada de CDI (infraestructura desagregada por componentes), los arquitectos de centros de datos, proveedores de servicios en la nube, integradores de sistemas, desarrolladores de software de almacenamiento y OEM pueden proporcionar servicios de almacenamiento y computación con mayor rentabilidad, flexibilidad, eficiencia y facilidad de escalabilidad, proporcionando dinámicamente el SLA requerido para todos. cargas de trabajo