Hola Mi nombre es Ivan Smurov y lidero el grupo de investigación de PNL en ABBYY. Puedes leer sobre lo que nuestro grupo está haciendo
aquí . Recientemente di una conferencia sobre Procesamiento del Lenguaje Natural (PNL) en la
Escuela de Aprendizaje Profundo ; este es un grupo en la Escuela de Matemáticas Aplicadas y Ciencias de la Computación PhysTech en MIPT para estudiantes de último año interesados en la programación y las matemáticas. Tal vez las tesis de mi conferencia sean útiles para alguien, así que las compartiré con Habr.
Como no se puede entender todo al mismo tiempo, dividiremos el artículo en dos partes. Hoy hablaré sobre cómo se usan las redes neuronales (o el aprendizaje profundo) en PNL. En la segunda parte del artículo, nos centraremos en una de las tareas de PNL más comunes: la tarea de extraer entidades con nombre (reconocimiento de entidad con nombre, NER) y analizar en detalle la arquitectura de sus soluciones.
¿Qué es la PNL?
Esta es una amplia gama de tareas para procesar textos en un lenguaje natural (es decir, el idioma que las personas hablan y escriben). Hay un conjunto de tareas clásicas de PNL, cuya solución es de uso práctico.
- La primera y más importante tarea histórica es la traducción automática. Se ha practicado durante mucho tiempo y hay un progreso tremendo. Pero la tarea de obtener una traducción totalmente automática de alta calidad (FAHQMT) sigue sin resolverse. En cierto modo, este es el motor de PNL, una de las tareas más grandes que puede hacer.

- La segunda tarea es la clasificación de los textos. Se proporciona un conjunto de textos, y la tarea es clasificar estos textos en categorías. Cual? Esta es una pregunta para el cuerpo.
La primera y una de las formas más prácticas de aplicarlo desde un punto de vista práctico es la clasificación de las letras en spam y boor (no spam).
Otra opción clásica es la clasificación multiclase de noticias en categorías (rubricación): política exterior, deportes, carpa, etc. O, digamos, recibe cartas y desea separar los pedidos de la tienda en línea de los boletos aéreos y las reservas de hotel.
La tercera aplicación clásica del problema de clasificación de texto es el análisis sentimental. Por ejemplo, la clasificación de las revisiones como positivas, negativas y neutrales.
Dado que hay tantas categorías posibles en las que puede dividir textos, la clasificación de texto es una de las tareas prácticas más populares de la PNL. - La tercera tarea es recuperar entidades nombradas, NER. Seleccionamos en las secciones de texto que corresponden a un conjunto preseleccionado de entidades, por ejemplo, necesitamos encontrar todas las ubicaciones, personas y organizaciones en el texto. En el texto "Ostap Bender - Director de la oficina de" Horns and Hooves "debe comprender que Ostap Bender es una persona y" Horns and Hooves "es una organización. Por qué esta tarea es necesaria en la práctica y cómo resolverla, hablaremos en la segunda parte de nuestro artículo.
 La cuarta tarea está relacionada con la tercera: la tarea de extraer hechos y relaciones (extracción de relaciones). Por ejemplo, hay una actitud de trabajo (Ocupación). Del texto "Ostap Bender - Director de la oficina" Horns and Hooves "está claro que nuestro héroe está conectado con las relaciones profesionales con" Horns and Hooves ". Lo mismo puede decirse de muchas otras maneras: "La oficina de Ostap Bender está encabezada por la oficina de" Horns and Hooves ", u" Ostap Bender ha pasado del simple hijo del teniente Schmidt al jefe de la oficina de "Horns and Hooves" ". Estas oraciones difieren no solo en el predicado, sino también en la estructura.
La cuarta tarea está relacionada con la tercera: la tarea de extraer hechos y relaciones (extracción de relaciones). Por ejemplo, hay una actitud de trabajo (Ocupación). Del texto "Ostap Bender - Director de la oficina" Horns and Hooves "está claro que nuestro héroe está conectado con las relaciones profesionales con" Horns and Hooves ". Lo mismo puede decirse de muchas otras maneras: "La oficina de Ostap Bender está encabezada por la oficina de" Horns and Hooves ", u" Ostap Bender ha pasado del simple hijo del teniente Schmidt al jefe de la oficina de "Horns and Hooves" ". Estas oraciones difieren no solo en el predicado, sino también en la estructura.
Ejemplos de otras relaciones que a menudo se destacan son Compra y Venta, Propiedad, el hecho de nacer con atributos como fecha, lugar, etc. (Nacimiento) y algunos otros.
La tarea parece no tener una aplicación práctica obvia, pero, sin embargo, se utiliza en la estructuración de información no estructurada. Además, esto es importante en los sistemas de preguntas y respuestas y de diálogo, en los motores de búsqueda, siempre que necesite analizar una pregunta y comprender con qué tipo se relaciona, así como las restricciones que hay en la respuesta.

- Las siguientes dos tareas son probablemente las más exageradas. Estos son sistemas de preguntas y respuestas (chat bots). Amazon Alexa, Alice son ejemplos clásicos de sistemas de conversación. Para que funcionen correctamente, se deben resolver muchas tareas de PNL. Por ejemplo, la clasificación de texto ayuda a determinar si caemos en uno de los escenarios de chatbot orientados a objetivos. Supongamos, "la cuestión de los tipos de cambio". La extracción de la relación es necesaria para identificar marcadores de posición para la plantilla de secuencia de comandos, y la tarea de llevar a cabo un diálogo sobre temas comunes ("conversadores") nos ayudará en una situación en la que no hemos caído en ninguno de los escenarios.
Los sistemas de preguntas y respuestas también son algo comprensible y útil. Usted hace una pregunta a un automóvil, el automóvil está buscando una respuesta en una base de datos o cuerpo de texto. Ejemplos de tales sistemas son IBM Watson o Wolfram Alpha. - Otro ejemplo del clásico problema de PNL es la sammarización. El enunciado del problema es simple: el sistema de entrada acepta un texto grande y el resultado es un texto más pequeño, que de alguna manera refleja el contenido de uno grande. Por ejemplo, se requiere una máquina para generar un recuento de un texto, su nombre o anotación.

- Otra tarea popular es la minería de argumentos, la búsqueda de justificación en el texto. Se le da un hecho y un texto, necesita encontrar una justificación para este hecho en el texto.
De ninguna manera es la lista completa de tareas de PNL. Hay docenas de ellos. En general, todo lo que se puede hacer con texto en un lenguaje natural se puede atribuir a las tareas de PNL, solo los temas enumerados son de oído y tienen las aplicaciones prácticas más obvias.
¿Por qué es difícil resolver tareas de PNL?
La redacción de las tareas no es muy complicada, pero las tareas en sí no son simples, porque trabajamos con el lenguaje natural. Los fenómenos de la polisemia (las palabras polisémicas tienen un significado inicial común) y la homonimia (las palabras con diferentes significados se pronuncian y escriben igual) son características de cualquier lenguaje natural. Y si un hablante nativo de ruso entiende bien que la
recepción cálida tiene poco en común con la
técnica de lucha , por un lado, y la
cerveza tibia , por otro, el sistema automático tiene que aprender esto durante mucho tiempo. Por qué es mejor traducir "
Presione la barra espaciadora para continuar " al aburrido "
Para continuar, presione la barra espaciadora " que "La
barra espaciadora continuará funcionando ".
- Polisemia: parada (proceso o construcción), mesa (organización u objeto), pájaro carpintero (pájaro o persona).
- Homonimia: llave, arco, cerradura, estufa.

- Otro ejemplo clásico de complejidad del lenguaje es el pronombre anáfora. Por ejemplo, permítanos recibir el texto " Conserje dos horas de nieve, estaba insatisfecho ". El pronombre "él" puede referirse tanto al conserje como a la nieve. Por contexto, entendemos fácilmente que es un conserje, no nieve. Pero lograr que la computadora también haya entendido esto fácilmente no es fácil. El problema del pronombre anáfora aún no está muy bien resuelto; los intentos activos por mejorar la calidad de las decisiones continúan.
- Otra complejidad añadida es la elipsis. Por ejemplo, " Petia comió una manzana verde y Masha comió una roja ". Entendemos que Masha comió una manzana roja. Sin embargo, hacer que la máquina entienda esto tampoco es fácil. Ahora la tarea de restaurar los puntos suspensivos se está resolviendo en casos pequeños (varios cientos de oraciones), y en ellos la calidad de la restauración completa es francamente débil (del orden de 0,5). Está claro que para aplicaciones prácticas, tal calidad no es buena.
Por cierto, este año en la conferencia de
Diálogo , las pistas se llevarán a cabo tanto en la anáfora como en la separación (un tipo de elipse) para el idioma ruso. Para ambas tareas, los casos se ensamblaron con un volumen varias veces mayor que los volúmenes de los edificios existentes en la actualidad (además, para la separación, el volumen del caso es un orden de magnitud mayor que los volúmenes de los casos, no solo para el ruso, sino para todos los idiomas en general). Si desea participar en concursos en estos edificios,
haga clic aquí (con registro, pero sin SMS) .
Cómo se resuelven las tareas de PNL
A diferencia del procesamiento de imágenes, aún puede encontrar artículos sobre PNL que describen soluciones que utilizan algoritmos clásicos como
SVM o
Xgboost , no redes neuronales, y que muestran resultados que no son demasiado inferiores a las soluciones de vanguardia.
Sin embargo, hace varios años, las redes neuronales comenzaron a derrotar a los modelos clásicos. Es importante tener en cuenta que, para la mayoría de las tareas, las soluciones basadas en métodos clásicos eran únicas, por regla general, no similares a la resolución de otros problemas tanto en la arquitectura como en la forma en que se produce la recopilación y el procesamiento de los atributos.
Sin embargo, las arquitecturas de redes neuronales son mucho más generales. La arquitectura de la red en sí misma, muy probablemente, también es diferente, pero mucho más pequeña, hay una tendencia hacia la universalización total. Sin embargo, con qué características y cómo trabajamos exactamente, ya es casi lo mismo para la mayoría de las tareas de PNL. Solo las últimas capas de redes neuronales difieren. Por lo tanto, podemos suponer que se ha formado una sola tubería de PNL. Sobre cómo está organizado, ahora le diremos más.
Pipeline nlp
Esta forma de trabajar con signos, que es más o menos igual para todas las tareas.
Cuando se trata de lenguaje, la unidad básica con la que trabajamos es la palabra. O más formalmente una "ficha". Usamos este término porque no está muy claro qué es 2128506, ¿es una palabra o no? La respuesta no es obvia. El token generalmente está separado de otros tokens por espacios o signos de puntuación. Y como puede comprender por las dificultades que describimos anteriormente, el contexto de cada token es muy importante. Existen diferentes enfoques, pero en el 95% de los casos, el contexto que se considera durante el trabajo del modelo es una propuesta que incluye el token inicial.
Muchas tareas generalmente se resuelven a nivel de propuesta. Por ejemplo, traducción automática. La mayoría de las veces, simplemente traducimos una oración y no utilizamos un contexto más amplio. Hay tareas en las que este no es el caso, por ejemplo, los sistemas de diálogo. Es importante recordar sobre qué se le preguntó antes al sistema para que pueda responder preguntas. Sin embargo, la oferta también es la unidad principal con la que trabajamos.
Por lo tanto, los primeros dos pasos de la tubería que se realizan para resolver casi cualquier tarea son la segmentación (división de texto en oraciones) y la tokenización (división de oraciones en tokens, es decir, palabras individuales). Esto se hace con algoritmos simples.
A continuación, debe calcular las características de cada token. Como regla, esto sucede en dos etapas. El primero es calcular atributos de token independientes del contexto. Este es un conjunto de signos que de ninguna manera dependen de otras palabras que rodean nuestro token. Los atributos comunes independientes del contexto son:
- incrustaciones
- signos simbólicos
- características adicionales específicas de una tarea o idioma en particular
Hablaremos sobre incrustaciones y signos simbólicos con más detalle a continuación (sobre signos simbólicos, no hoy, sino en la segunda parte de nuestro artículo), pero por ahora vamos a dar posibles ejemplos de signos adicionales.
Una de las características más utilizadas es la parte del discurso o la etiqueta POS (parte del discurso). Dichas características pueden ser importantes para resolver muchos problemas, por ejemplo, analizar tareas. Para los idiomas con morfología compleja, como el idioma ruso, los caracteres morfológicos también son importantes: por ejemplo, en cuyo caso es el sustantivo, qué tipo de adjetivo. De esto podemos sacar diferentes conclusiones sobre la estructura de la propuesta. Además, la morfología es necesaria para la lematización (reducción de palabras a formas iniciales), con la ayuda de la cual podemos reducir la dimensión del espacio de características y, por lo tanto, el análisis morfológico se usa activamente para la mayoría de los problemas de PNL.
Cuando resolvemos un problema en el que la interacción entre diferentes objetos es importante (por ejemplo, en la tarea de extracción de relaciones o al crear un sistema de preguntas y respuestas), necesitamos saber mucho sobre la estructura de la propuesta. Esto requiere análisis. En la escuela, todos analizaron una oración para un tema, predicado, suma, etc. El análisis sintáctico es algo en este espíritu, pero más complicado.
Otro ejemplo de una característica adicional es la posición del token en el texto. Podemos saber a priori que alguna entidad se encuentra con mayor frecuencia al comienzo del texto o viceversa al final.
Todos juntos (incrustaciones, signos simbólicos y adicionales) forman un vector de signos simbólicos que no depende del contexto.
Características sensibles al contexto
Los signos de token sensibles al contexto son un conjunto de signos que contienen información no solo sobre el token en sí, sino también sobre sus vecinos. Hay diferentes formas de calcular estos síntomas. En los algoritmos clásicos, la gente a menudo simplemente caminaba por la "ventana": tomaron varias (por ejemplo, tres) fichas al original y varias fichas después, y luego calcularon todos los signos en dicha ventana. Este enfoque no es confiable, ya que la información importante para el análisis puede estar a una distancia mayor que la ventana, respectivamente, podemos perder algo.
Por lo tanto, ahora todas las características sensibles al contexto se calculan a nivel de propuesta de una manera estándar: utilizando redes neuronales recurrentes bidireccionales LSTM o GRU. Para obtener los atributos de token sensibles al contexto de los atributos independientes del contexto de todos los tokens de oferta se envían al RNN bidireccional (de una o varias capas). La salida del RNN bidireccional en el i-ésimo momento en el tiempo es un signo sensible al contexto del i-token, que contiene información sobre ambos tokens anteriores (ya que esta información está contenida en el i-ésimo valor del RNN directo) y sobre los siguientes (t .k. esta información está contenida en el valor correspondiente del RNN inverso).
Además, para cada tarea individual, hacemos algo diferente, pero las primeras capas, hasta RNN bidireccional, se pueden usar para casi cualquier tarea.
Este método de obtención de características se denomina canalización de PNL.
Vale la pena señalar que en los últimos 2 años, los investigadores han estado tratando activamente de mejorar la tubería de PNL, tanto en términos de velocidad (por ejemplo, transformador, una arquitectura basada en la auto atención que no contiene RNN y, por lo tanto, puede aprender y aplicar más rápido), y con punto de vista de los signos utilizados (ahora están utilizando activamente signos basados en modelos de lenguaje previamente entrenados, por ejemplo
ELMo , o están utilizando las primeras capas del modelo de lenguaje previamente entrenado y los vuelven a capacitar en el caso disponible para la tarea:
ULMFit ,
BERT ).
Incrustaciones de forma de palabra
Echemos un vistazo más de cerca a lo que es incrustar. En términos generales, incrustar es una representación concisa del contexto de una palabra. ¿Por qué es importante conocer el contexto de una palabra? Porque creemos en una hipótesis de distribución: que las palabras que tienen un significado similar se usan en contextos similares.
Tratemos ahora de dar una definición rigurosa de incrustación. La incrustación es un mapeo de un vector discreto de características categóricas en un vector continuo con una dimensión predeterminada.
Un ejemplo canónico de incrustación es la incrustación de palabras (incrustación de forma de palabra).
¿Qué suele actuar como un vector de características discretas? Un vector booleano que corresponde a todos los valores posibles de una determinada categoría (por ejemplo, todas las partes posibles del discurso o todas las palabras posibles de algún diccionario limitado).
Para incrustaciones de forma de palabra, esta categoría suele ser el índice de la palabra en el diccionario. Digamos que hay un diccionario con una dimensión de 100 mil. En consecuencia, cada palabra tiene un vector discreto de signos: un vector booleano de dimensión 100 mil, donde en un lugar (el índice de la palabra en nuestro diccionario) es uno, y el resto son ceros.
¿Por qué queremos asignar nuestros vectores de características discretas a dimensiones continuas dadas? Debido a que los vectores con una dimensión de 100 mil no son muy convenientes de usar para los cálculos, los vectores de enteros de dimensiones 100, 200 o, por ejemplo, 300, son mucho más convenientes.
En principio, no podemos tratar de imponer restricciones adicionales a tal mapeo. Pero como estamos construyendo un mapeo de este tipo, intentemos asegurarnos de que los vectores de palabras con significado similar también estén cerca en algún sentido. Esto se hace usando una simple red neuronal de retroalimentación.
Entrenamiento de incrustación
¿Cómo se entrenan las incrustaciones? Estamos tratando de resolver el problema de restaurar una palabra por contexto (o viceversa, restaurar un contexto por palabra). En el caso más simple, obtenemos el índice en el diccionario de la palabra anterior (el vector booleano de la dimensión del diccionario) como entrada y tratamos de determinar el índice en el diccionario de nuestra palabra. Esto se hace usando una cuadrícula con una arquitectura extremadamente simple: dos capas completamente conectadas. Primero viene una capa completamente conectada del vector booleano de la dimensión del diccionario a la capa oculta de la dimensión de incrustación (es decir, simplemente multiplicando el vector booleano por la matriz de la dimensión deseada). Y luego viceversa, una capa totalmente conectada con softmax de una capa oculta de dimensión incrustada en un vector de dimensión de diccionario. Gracias a la función de activación softmax, obtenemos la distribución de probabilidad de nuestra palabra y podemos elegir la opción más probable.
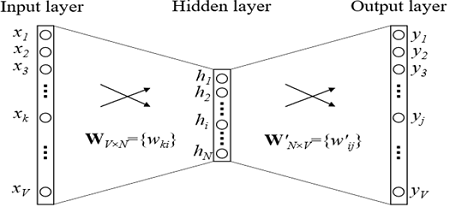
En los modelos utilizados en la práctica, la arquitectura es más compleja, pero no por mucho. La principal diferencia es que no utilizamos un vector del contexto para definir nuestra palabra, sino varios (por ejemplo, todo en una ventana de tamaño 3). Una opción un poco más popular es cuando tratamos de predecir no una palabra por contexto, sino un contexto por palabra. Este enfoque se llama Skip-gram.
Pongamos un ejemplo de la aplicación de una tarea que se resuelve durante el entrenamiento de incrustaciones (en la variante CBOW, predicciones de palabras por contexto). Por ejemplo, supongamos que un contexto de token consta de 2 palabras anteriores. “ ”, , , “”.
, ( ), , .
, , , (, , ). — .
, , . , , , .
, — ELMo, ULMFit, BERT. , ( , , , ).
?
, 2 .
- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
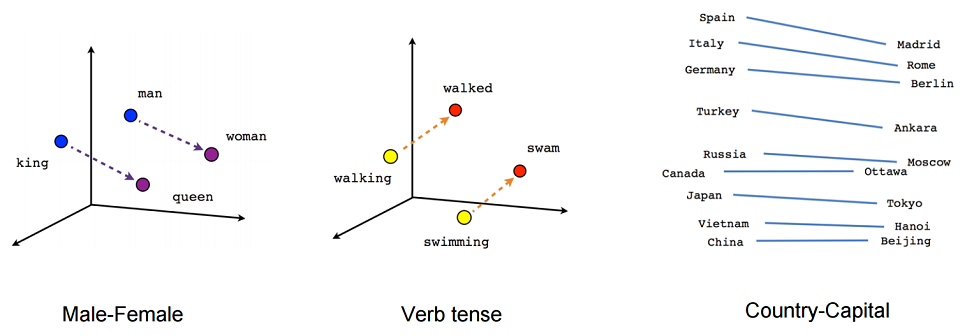
, .
, , , , , . , , , , .
NER. , , . , , , , .