
A principios de 2018, se publicó un artículo El aprendizaje de refuerzo profundo aún no funciona ("Aprender con refuerzo aún no funciona"). La principal queja fue que los algoritmos de aprendizaje modernos con refuerzo requieren aproximadamente la misma cantidad de tiempo para resolver un problema que una búsqueda aleatoria regular.
¿Ha cambiado algo desde entonces? No
El aprendizaje reforzado se considera uno de los tres caminos principales para construir una IA fuerte. Pero las dificultades a las que se enfrenta esta área de aprendizaje automático y los métodos que los científicos están tratando de enfrentar estas dificultades sugieren que puede haber problemas fundamentales con este enfoque en sí.
Espera, ¿qué significa uno de los tres? ¿Cuáles son los otros dos?
Dado el éxito de las redes neuronales en los últimos años y el análisis de cómo funcionan con habilidades cognitivas de alto nivel, que anteriormente se consideraban características solo de humanos y animales superiores, hoy en la comunidad científica existe la opinión de que existen tres enfoques principales para crear IA fuerte en La base de las redes neuronales, que pueden considerarse más o menos realistas:
1. Procesamiento de textos
El mundo ha acumulado una gran cantidad de libros y textos en Internet, incluidos libros de texto y libros de referencia. El texto es conveniente y rápido para procesar en una computadora. Teóricamente, este conjunto de textos debería ser suficiente para entrenar una IA de conversación fuerte.
Está implícito que en estas matrices textuales se refleja la estructura completa del mundo (al menos, se describe en libros de texto y libros de referencia). Pero esto no es un hecho en absoluto. Los textos como una forma de presentación de información están fuertemente divorciados del mundo tridimensional real y el curso del tiempo en que vivimos.
Buenos ejemplos de IA entrenada en matrices de texto son los bots de chat y los traductores automáticos. Como para traducir el texto, debe comprender el significado de la frase y volver a contarla en palabras nuevas (en otro idioma). Existe una idea errónea común de que las reglas de gramática y sintaxis, incluida una descripción de todas las posibles excepciones, describen completamente un lenguaje en particular. Esto no es asi. El lenguaje es solo una herramienta auxiliar en la vida, cambia fácilmente y se adapta a nuevas situaciones.
El problema con el procesamiento de texto (incluso por sistemas expertos, incluso redes neuronales) es que no hay un conjunto de reglas, qué frases deben aplicarse en qué situaciones. Tenga en cuenta: no las reglas para construir las frases en sí mismas (qué hace la gramática y la sintaxis), sino qué frases en qué situaciones. En la misma situación, las personas pronuncian frases en diferentes idiomas que generalmente no están relacionadas entre sí en términos de la estructura del idioma. Compare frases con extrema sorpresa: "¡oh Dios!" y "¡oh santa mierda!". Bueno, y ¿cómo hacer una correspondencia entre ellos, conociendo el modelo de lenguaje? De ninguna manera Sucedió por casualidad históricamente. Necesita saber la situación y lo que suelen hablar en un idioma en particular. Es por esto que los traductores automáticos son tan imperfectos.
Se desconoce si este conocimiento puede distinguirse únicamente de una serie de textos. Pero si los traductores automáticos traducen perfectamente sin cometer errores tontos y ridículos, esto será una prueba de que es posible crear una IA fuerte solo basada en texto.
2. Reconocimiento de imagen
Mira esta imagen

Mirando esta foto, entendemos que el rodaje se realizó por la noche. A juzgar por las banderas, el viento sopla de derecha a izquierda. Y a juzgar por el tráfico de la derecha, el caso no está sucediendo en Inglaterra o Australia. Ninguna de esta información se indica explícitamente en los píxeles de la imagen, esto es conocimiento externo. En la foto solo hay signos por los cuales podemos usar el conocimiento obtenido de otras fuentes.
¿Sabes algo más mirando esta foto?Sobre eso y el discurso ... Y encuentrate una chica, finalmente
Por lo tanto, se cree que si entrena una red neuronal para reconocer objetos en una imagen, tendrá una idea interna de cómo funciona el mundo real. Y esta vista, obtenida de las fotografías, ciertamente corresponderá a nuestro mundo real y real. A diferencia de las matrices de textos donde esto no está garantizado.
El valor de las redes neuronales entrenadas en una serie de fotografías ImageNet (y ahora OpenImages V4 , COCO , KITTI , BDD100K y otras) no es en absoluto el reconocimiento de un gato en una foto. Y eso se almacena en la penúltima capa. Aquí es donde se encuentra un conjunto de características de alto nivel que describen nuestro mundo. Un vector de 1024 números es suficiente para obtener una descripción de 1000 categorías diferentes de objetos con un 80% de precisión (y en el 95% de los casos la respuesta correcta estará en las 5 opciones más cercanas). Solo piénsalo.
Es por eso que estas características de la penúltima capa se usan con tanto éxito en tareas completamente diferentes en la visión por computadora. Mediante transferencia de aprendizaje y puesta a punto. De este vector en 1024 números puede obtener, por ejemplo, un mapa de profundidad de la imagen
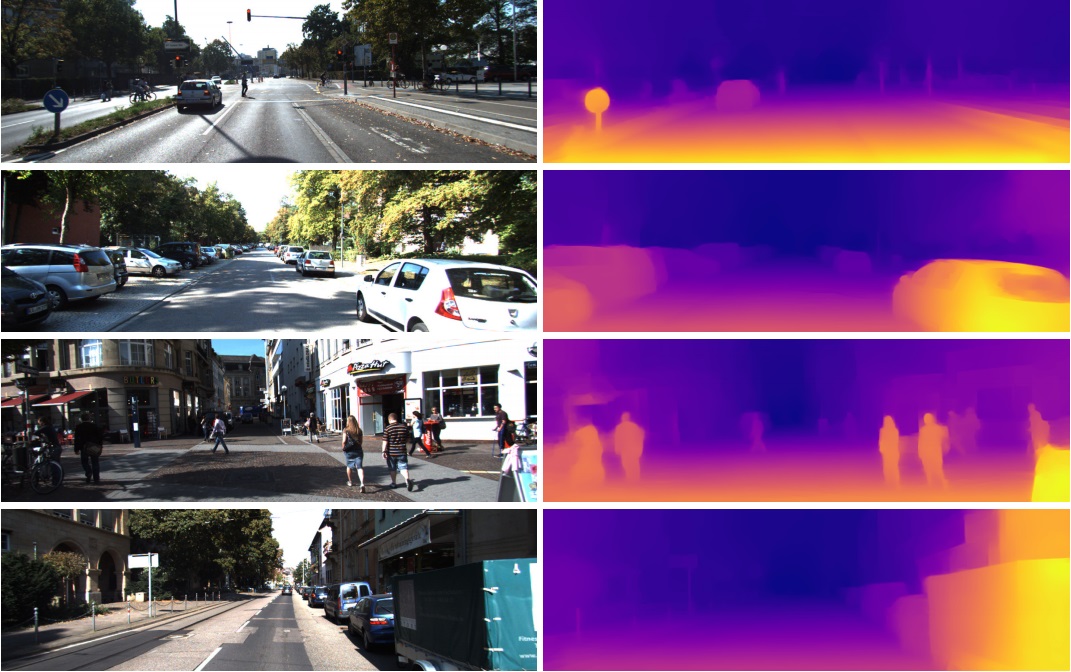
(un ejemplo del trabajo donde se utiliza una red Densenet-169 pre-entrenada prácticamente sin cambios)
O determinar la pose de una persona. Hay muchas aplicaciones
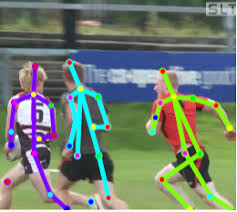
Como resultado, el reconocimiento de imágenes puede usarse potencialmente para crear una IA fuerte, ya que realmente refleja el modelo de nuestro mundo real. Un paso de la fotografía al video, y el video es nuestra vida, ya que obtenemos aproximadamente el 99% de la información visualmente.
Pero de la fotografía es completamente incomprensible cómo motivar a la red neuronal a pensar y sacar conclusiones. Ella puede ser entrenada para responder preguntas como "¿cuántos lápices hay en la mesa?" (esta clase de tareas se llama Visual Question Answering, un ejemplo de dicho conjunto de datos: https://visualqa.org ). O dé una descripción textual de lo que está sucediendo en la foto. Esta es la clase de tarea Subtítulos de imágenes .

¿Pero es esta inteligencia? Habiendo desarrollado este enfoque, en un futuro cercano, las redes neuronales podrán responder preguntas en video como "Dos gorriones estaban sentados en los cables, uno de ellos se fue volando, ¿cuántos gorriones quedaron?" Esto es matemática real, en casos un poco más complicados, inaccesibles para los animales y al nivel de la educación escolar humana. Especialmente si, a excepción de los gorriones, habrá pechos sentados junto a ellos, pero no es necesario tenerlos en cuenta, ya que la pregunta era solo sobre gorriones. Sí, definitivamente será inteligencia.
3. Aprendizaje de refuerzo
La idea es muy simple: alentar acciones que conduzcan a la recompensa y evitar el fracaso. Esta es una forma universal de aprendizaje y, obviamente, definitivamente puede conducir a la creación de una IA fuerte. Por lo tanto, ha habido mucho interés en el aprendizaje por refuerzo en los últimos años.
Mezclar pero no agitarPor supuesto, es mejor crear una IA fuerte combinando los tres enfoques. En imágenes y con entrenamiento de refuerzo, puedes obtener IA de nivel animal. Y agregando nombres textuales de objetos a las imágenes (una broma, por supuesto, obligando a la IA a mirar videos donde las personas interactúan y hablan, como cuando enseña a un bebé), y volver a entrenar en una matriz de texto para obtener conocimiento (un análogo de nuestra escuela y universidad), en teoría puede obtener Nivel humano AI. Capaz de hablar.
El aprendizaje reforzado tiene una gran ventaja. En el simulador, puede crear un modelo simplificado del mundo. Entonces, para una figura humana, solo 17 grados de libertad son suficientes, en lugar de 700 en una persona viva (número aproximado de músculos). Por lo tanto, en el simulador puede resolver el problema en una dimensión muy pequeña.
Mirando hacia el futuro, los algoritmos modernos de aprendizaje por refuerzo no pueden controlar arbitrariamente el modelo de una persona, incluso con 17 grados de libertad. Es decir, no pueden resolver el problema de optimización, donde hay 44 números en la entrada y 17. En la entrada, es posible hacerlo solo en casos muy simples, con un ajuste fino de las condiciones iniciales y los hiperparámetros. E incluso en este caso, por ejemplo, para enseñar un modelo humanoide con 17 grados de libertad para correr y comenzar desde una posición de pie (que es mucho más simple), necesita varios días de cálculos en una GPU potente. Y los casos un poco más complicados, por ejemplo, aprender a levantarse de una pose arbitraria, tal vez nunca aprendan en absoluto. Esto es un fracaso
Además, todos los algoritmos de aprendizaje por refuerzo funcionan con redes neuronales deprimentemente pequeñas, pero no pueden hacer frente al aprendizaje de redes grandes. Las redes de convolución grandes se usan solo para reducir la dimensión de la imagen a varias características, que se alimentan a los algoritmos de aprendizaje con refuerzo. El mismo humanoide en funcionamiento está controlado por una red Feed Forward con dos o tres capas de 128 neuronas. Enserio? Y en base a esto, ¿estamos tratando de construir una IA fuerte?
Para tratar de entender por qué sucede esto y qué tiene de malo el aprendizaje por refuerzo, primero debe familiarizarse con las arquitecturas básicas del aprendizaje por refuerzo moderno.
La estructura física del cerebro y el sistema nervioso está ajustada por la evolución al tipo específico de animal y sus condiciones de vida. Entonces, en el curso de la evolución, una mosca desarrolló un sistema nervioso y un trabajo de neurotransmisores en los ganglios (un análogo del cerebro en los insectos) para esquivar rápidamente a un matamoscas. Bueno, no de un matamoscas, sino de aves que han pescado durante 400 millones de años (es broma, las mismas aves aparecieron hace 150 millones de años, muy probablemente de ranas 360 millones de años). Un rinoceronte lo suficiente como un sistema nervioso y cerebro para girar lentamente hacia el objetivo y comenzar a correr. Y allí, como dicen, el rinoceronte tiene mala vista, pero este no es su problema.
Pero además de la evolución, cada individuo específico, desde el nacimiento y durante toda la vida, trabaja precisamente con el mecanismo de aprendizaje habitual con refuerzo. En el caso de los mamíferos, y también de los insectos , el sistema de dopamina hace este trabajo. Su trabajo está lleno de secretos y matices, pero todo se reduce al hecho de que, en caso de un premio, el sistema de dopamina, a través de mecanismos de memoria, de alguna manera corrige las conexiones entre las neuronas que estaban activas inmediatamente antes. Así es como se forma la memoria asociativa.
Que, debido a su asociatividad, se utiliza en la toma de decisiones. En pocas palabras, si la situación actual (neuronas activas actuales en esta situación) a través de la memoria asociativa activa las neuronas de placer, entonces el individuo selecciona las acciones que realizó en una situación similar y que recordó. "Elige acciones" es una definición pobre. No hay elección Las neuronas de memoria de placer simplemente activadas, fijadas por el sistema de dopamina para una situación dada, activan automáticamente las neuronas motoras, lo que conduce a la contracción muscular. Esto es si se necesita una acción inmediata.
El aprendizaje artificial con refuerzo, como campo de conocimiento, es necesario para resolver estos dos problemas:
1. Elija la arquitectura de la red neuronal (lo que la evolución ya ha hecho por nosotros)
La buena noticia es que las funciones cognitivas superiores que se realizan en la neocorteza en los mamíferos (y en el cuerpo estriado de los córvidos ) se realizan en una estructura aproximadamente uniforme. Aparentemente, esto no necesita alguna "arquitectura" rígidamente prescrita.
La diversidad de las regiones del cerebro probablemente se deba a razones puramente históricas. Cuando, a medida que evolucionaron, nuevas partes del cerebro crecieron sobre las bases que quedaron de los primeros animales. Por el principio funciona, no tocar. Por otro lado, en diferentes personas, las mismas partes del cerebro reaccionan a las mismas situaciones. Esto puede explicarse tanto por la asociatividad (características y "neuronas de la abuela" formadas naturalmente en estos lugares durante el proceso de aprendizaje) como por la fisiología. Que las vías de señalización codificadas en los genes conducen precisamente a estas áreas. No hay consenso, pero puede leer, por ejemplo, este artículo reciente: "Inteligencia biológica y artificial" .
2. Aprenda a entrenar redes neuronales de acuerdo con los principios de aprendizaje con refuerzo
Esto es lo que el Aprendizaje de refuerzo moderno está haciendo principalmente. ¿Y cuáles son los éxitos? En realidad no
Enfoque ingenuo
Parece que es muy simple entrenar una red neuronal con refuerzo: realizamos acciones aleatorias, y si obtenemos una recompensa, consideramos las acciones tomadas como "referencia". Los colocamos en la salida de la red neuronal como etiquetas estándar y entrenamos la red neuronal mediante el método de propagación inversa del error, para que produzca exactamente esa salida. Bueno, el entrenamiento de red neuronal más común. Y si las acciones condujeron al fracaso, entonces ignore este caso o suprima estas acciones (establecemos algunas otras como salida, por ejemplo, cualquier otra acción aleatoria). En general, esta idea repite el sistema de dopamina.
Pero si intentas entrenar cualquier red neuronal de esta manera, no importa cuán compleja sea la arquitectura, recursiva, convolucional u ordinaria, entonces ... ¡No funcionará!
Por qué Desconocido
Se cree que la señal útil es tan pequeña que se pierde en el contexto del ruido. Por lo tanto, la red no aprende el método estándar de propagación inversa del error. Una recompensa ocurre muy raramente, tal vez una vez en cientos o incluso miles de pasos. E incluso LSTM recuerda un máximo de 100-500 puntos en la historia, y luego solo en tareas muy simples. Pero en los más complejos, si hay 10-20 puntos en la historia, entonces ya es bueno.
Pero la raíz del problema está precisamente en recompensas muy raras (al menos en tareas de valor práctico). Por el momento, no sabemos cómo entrenar redes neuronales que recuerden casos aislados. Lo que el cerebro enfrenta con brillantez. Puedes recordar algo que sucedió solo una vez en la vida. Y, por cierto, la mayor parte de la capacitación y el trabajo del intelecto se basa en esos casos.
Esto es algo así como un terrible desequilibrio de clases en el campo del reconocimiento de imágenes. Simplemente no hay formas de lidiar con esto. Lo mejor que han podido encontrar hasta ahora es simplemente enviar a la entrada de la red, junto con nuevas situaciones, situaciones exitosas del pasado almacenadas en un búfer especial artificial. Es decir, enseñar constantemente no solo casos nuevos, sino también casos antiguos exitosos. Naturalmente, dicho búfer no se puede aumentar infinitamente, y no está claro qué almacenar exactamente en él. Todavía estoy tratando de arreglar temporalmente las rutas dentro de la red neuronal, que estuvieron activas durante un caso exitoso, para que el entrenamiento posterior no las sobrescriba. Una analogía bastante cercana a lo que está sucediendo en el cerebro, en mi opinión, aunque tampoco han logrado mucho éxito en esta dirección. Como las nuevas tareas entrenadas en su cálculo utilizan los resultados de las neuronas que salen de las rutas congeladas, como resultado, la señal solo interfiere con las nuevas congeladas, y las viejas tareas dejan de funcionar. Hay otro enfoque curioso: entrenar la red con nuevos ejemplos / tareas solo en la dirección ortogonal a las tareas anteriores ( https://arxiv.org/abs/1810.01256 ). Esto no sobrescribe la experiencia previa, pero limita drásticamente la capacidad de la red.
En Meta-Learning se está desarrollando una clase separada de algoritmos diseñados para lidiar con este desastre (y al mismo tiempo dar esperanza para lograr una IA fuerte). Estos son intentos de enseñarle a una red neuronal varias tareas a la vez. No en el sentido de que reconoce diferentes imágenes en una tarea, es decir, diferentes tareas en diferentes dominios (cada uno con su propia distribución y panorama de soluciones). Diga, reconozca fotos y ande en bicicleta al mismo tiempo. Hasta ahora, el éxito tampoco es muy bueno, ya que generalmente todo se reduce a preparar una red neuronal por adelantado con pesas universales generales, y luego rápidamente, en solo unos pocos pasos de descenso de gradiente, para adaptarlos a una tarea específica. Ejemplos de algoritmos de meta-aprendizaje son MAML y Reptile .
En general, solo este problema (la incapacidad de aprender de ejemplos únicos exitosos) pone fin al entrenamiento moderno con refuerzo. Todo el poder de las redes neuronales ante este triste hecho es hasta ahora impotente.
Este hecho, que la forma más simple y obvia no funciona, obligó a los investigadores a volver al clásico Aprendizaje por refuerzo basado en tablas. Lo cual, como ciencia, apareció en la antigua antigüedad, cuando las redes neuronales ni siquiera estaban en el proyecto. Pero ahora, en lugar de calcular manualmente los valores en tablas y fórmulas, ¡usemos un aproximador tan poderoso como redes neuronales como las funciones objetivas! Esta es la esencia del aprendizaje de refuerzo moderno. Y su principal diferencia con el entrenamiento habitual de las redes neuronales.
Q-learning y DQN
El aprendizaje por refuerzo (incluso antes de las redes neuronales) nació como una idea bastante simple y original: hagamos acciones aleatorias, y luego para cada celda en la tabla y cada dirección de movimiento, calculamos de acuerdo con una fórmula especial (llamada la ecuación de Bellman, esta palabra será para conocer en casi todos los trabajos con entrenamiento de refuerzo) qué tan buena es esta celda y la dirección elegida. Cuanto mayor sea este número, más probable es que este camino conduzca a la victoria.
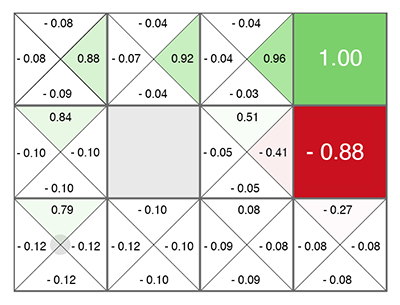
No importa en qué celda aparezcas, ¡muévete por el verde en crecimiento! (hacia el número máximo a los lados de la celda actual).
Este número se llama Q (de la palabra calidad - calidad de elección, obviamente), y el método es Q-learning. Reemplazando la fórmula para calcular este número con una red neuronal, o más bien enseñando la red neuronal usando esta fórmula (más un par de trucos más relacionados puramente con las matemáticas de las redes neuronales de entrenamiento), Deepmind obtuvo el método DQN . Este es quien en 2015 ganó el montón de juegos de Atari y marcó el comienzo de una revolución en Deep Reinforcement Learning.
Desafortunadamente, este método en su arquitectura funciona solo con acciones discretas discretas. En la DQN, el estado actual (la situación actual) se alimenta a la entrada de la red neuronal, y en la salida la red neuronal predice el número Q. Y dado que la salida de la red enumera todas las acciones posibles a la vez (cada una con su propia Q predicha), resulta que la red neuronal en DQN implementa la función clásica Q (s, a) de Q-learning. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
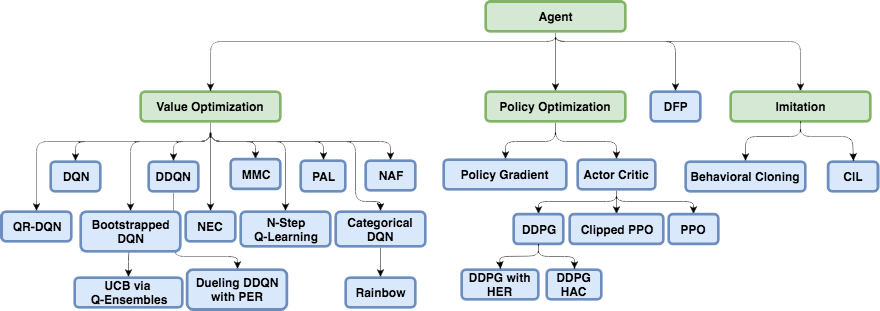
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
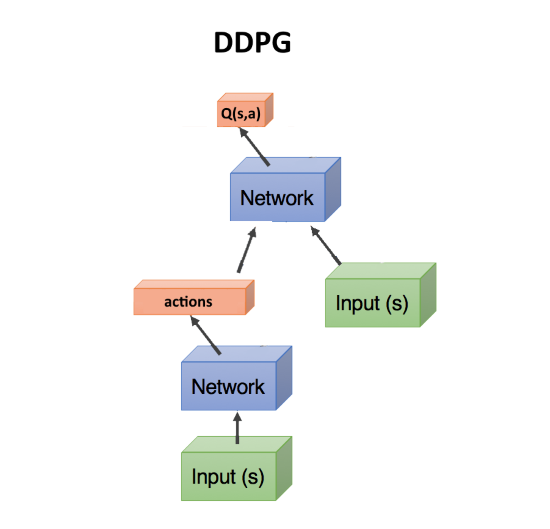
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
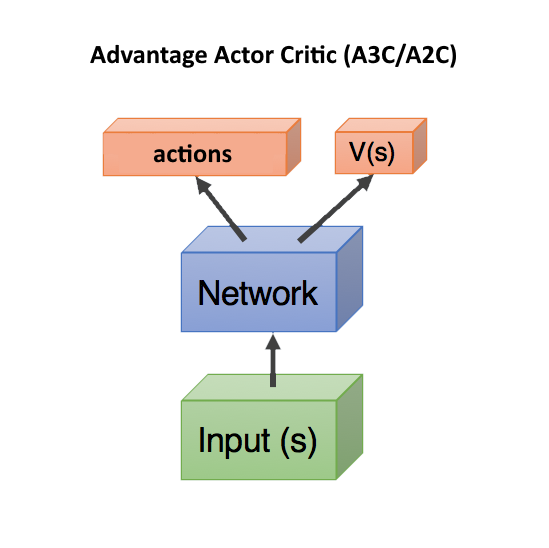
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
Recientemente, el algoritmo Soft-Actor-Critic (SAC) ha ido ganando popularidad. No es muy diferente de PPO, solo se ha agregado un objetivo al aprender a aumentar la entropía en la política. Hacer que el comportamiento del agente sea más aleatorio. No, no asi. Que el agente pudo actuar en situaciones más aleatorias. Esto aumenta automáticamente la confiabilidad de la política, una vez que el agente está listo para cualquier situación aleatoria. Además, el SAC requiere un poco menos de ejemplos de entrenamiento que PPO, y es menos sensible a la configuración de hiperparámetros, lo que también es una ventaja. Sin embargo, incluso con SAC, para entrenar a un humanoide a correr con 17 grados de libertad, comenzando desde una posición de pie, necesita aproximadamente 20 millones de fotogramas y aproximadamente un día de cálculo en una GPU. Las condiciones iniciales más difíciles, por ejemplo, para enseñar a un humanoide a levantarse de una pose arbitraria, pueden no enseñarse en absoluto.
Total, la recomendación general en el aprendizaje de refuerzo moderno: use SAC, PPO, DDPG, DQN (en ese orden, descendente).
Basado en modelos
Hay otro enfoque interesante, indirectamente relacionado con el aprendizaje por refuerzo. Esto es para construir un modelo del entorno y usarlo para predecir lo que sucederá si tomamos alguna medida.
Su desventaja es que no dice de ninguna manera qué acciones deben tomarse. Solo sobre su resultado. Pero una red neuronal de este tipo es fácil de entrenar, solo entrena con cualquier estadística. Resulta algo así como un simulador mundial basado en una red neuronal.
Después de eso, generamos una gran cantidad de acciones aleatorias, y cada una se maneja a través de este simulador (a través de una red neuronal). Y miramos cuál traerá la máxima recompensa. Hay una pequeña optimización: generar no solo acciones aleatorias, sino también desviarse de acuerdo con la ley normal de la trayectoria actual. Y, de hecho, si levantamos la mano, entonces con una alta probabilidad necesitamos continuar levantándola. Por lo tanto, antes que nada, debe verificar las desviaciones mínimas de la trayectoria actual.
El truco aquí es que incluso un simulador físico primitivo como MuJoCo o pyBullet produce alrededor de 200 FPS. Y si entrena una red neuronal para predecir hacia adelante al menos unos pocos pasos, entonces, para entornos simples, puede obtener fácilmente lotes de 2000-5000 predicciones a la vez. Dependiendo de la potencia de la GPU, puede obtener un pronóstico de decenas de miles de acciones aleatorias por segundo debido a la paralelización en la GPU y la velocidad de cálculo en la red neuronal. La red neuronal aquí simplemente actúa como un simulador muy rápido de la realidad.
Además, dado que la red neuronal puede predecir el mundo real (este es un enfoque basado en modelos, en el sentido general), el entrenamiento puede llevarse a cabo completamente en la imaginación, por así decirlo. Este concepto en Reinforcement Learning se llama Dream Worlds o World Models. Esto funciona bien, una buena descripción está aquí: https://worldmodels.imtqy.com . Además, tiene una contraparte natural: los sueños ordinarios. Y desplazamiento múltiple de eventos recientes o planeados en la cabeza.
Imitación de aprendizaje
Debido a la impotencia de que los algoritmos de aprendizaje por refuerzo no funcionan en grandes dimensiones y tareas complejas, las personas se propusieron al menos repetir las acciones de los expertos en forma de personas. Aquí, se lograron buenos resultados (inalcanzables mediante el aprendizaje de refuerzo convencional). Entonces, OpenAI resultó pasar el juego La venganza de Montezuma . El truco resultó ser simple: colocar al agente inmediatamente al final del juego (al final de la trayectoria mostrada por la persona). Allí, con la ayuda de PPO, gracias a la proximidad de la recompensa final, el agente aprende rápidamente a caminar a lo largo de la trayectoria. Después de eso lo ponemos un poco atrás, donde rápidamente aprende a llegar al lugar que ya ha estudiado. Y así, cambiando gradualmente el punto de "reaparición" a lo largo de la trayectoria hasta el comienzo del juego, el agente aprende a pasar / simular la trayectoria experta a lo largo del juego.
Otro resultado impresionante es la repetición de movimientos para personas filmadas en Motion Capture: DeepMimic . La receta es similar al método OpenAI: cada episodio no comienza desde el principio de la ruta, sino desde un punto aleatorio a lo largo de la ruta. Entonces PPO estudia con éxito los alrededores de este punto.
Debo decir que el sensacional algoritmo Go-Explore de Uber, que superó la venganza de Montezuma con puntos récord, no es un algoritmo de refuerzo de aprendizaje. Esta es una búsqueda aleatoria regular, pero comienza con una celda celular visitada aleatoriamente (una celda gruesa en la que caen varios estados). Y solo cuando la búsqueda hasta el final del juego se encuentra mediante una búsqueda tan aleatoria, la red neuronal se entrena utilizando el aprendizaje de imitación. De manera similar a OpenAI, es decir comenzando al final de la trayectoria.
Curiosidad (Curiosidad)
Un concepto muy importante en el aprendizaje por refuerzo es la curiosidad. En la naturaleza, es un motor para la investigación ambiental.
El problema es que, como medida de curiosidad, no puede usar un simple error de predicción de red, lo que sucederá después. De lo contrario, dicha red se colgará frente al primer árbol con follaje ondulante. O frente a un televisor con cambio de canal aleatorio. Dado que el resultado debido a la complejidad será imposible de predecir y el error siempre será grande. Sin embargo, esta es precisamente la razón por la que a nosotros (las personas) nos encanta mirar el follaje, el agua y el fuego. Y cómo trabajan otras personas =). Pero tenemos mecanismos de protección para no colgar para siempre.
Uno de esos mecanismos fue inventado como el Modelo Inverso en la Exploración de Curiosidad por
Predicción auto supervisada . En resumen, un agente (red neuronal), además de predecir qué acciones se realizan mejor en una situación dada, también trata de predecir qué sucederá con el mundo después de las acciones tomadas. Y usa esta predicción del mundo para el siguiente paso, para que él y el paso actual puedan predecir sus acciones tomadas antes (sí, es difícil, no puedes resolverlo sin una pinta).
Esto lleva a un efecto curioso: el agente se vuelve curioso solo sobre lo que puede influir con sus acciones. No puede influir en las ramas que se balancean de un árbol, por lo que no le interesan. Pero él puede caminar por el distrito, por lo que siente curiosidad por caminar y explorar el mundo.
Sin embargo, si el agente tiene un control remoto de TV que cambia canales aleatorios, ¡entonces puede afectarlo! Y tendrá curiosidad por hacer clic en los canales hasta el infinito (ya que no puede predecir cuál será el próximo canal, porque es aleatorio). Google intentó evadir este problema en el trabajo de Curiosidad Episódica a través de Accesibilidad .
Pero quizás el mejor resultado de vanguardia se deba a la curiosidad, OpenAI actualmente posee la idea de la Destilación de red aleatoria (RND) . Su esencia es que toma una segunda red, completamente aleatoriamente inicializada, y el estado actual se alimenta a ella. Y nuestra red neuronal de trabajo principal está tratando de adivinar la salida de esta red neuronal. La segunda red no está entrenada, permanece fija todo el tiempo tal como se inicializó.
Cual es el punto? El punto es que si nuestra red de trabajo ya ha visitado y estudiado algún estado, entonces podrá predecir con mayor o menor éxito la salida de esa segunda red. Y si este es un estado nuevo, donde nunca hemos estado, entonces nuestra red neuronal no podrá predecir la salida de esa red RND. Este error al predecir la salida de esa red inicializada aleatoriamente se utiliza como un indicador de curiosidad (da grandes recompensas si no podemos predecir su salida en esta situación).
Por qué esto funciona no está del todo claro. Pero escriben que esto elimina el problema cuando el objetivo de predicción es estocástico y cuando no hay suficientes datos para hacer una predicción de lo que sucederá a continuación (lo que da un gran error de predicción en los algoritmos de curiosidad ordinarios). De una forma u otra, pero RND realmente mostró excelentes resultados de investigación basados en la curiosidad en los juegos. Y hace frente al problema de la televisión aleatoria.
Con RND, la curiosidad en OpenAI por primera vez honestamente (y no a través de una búsqueda aleatoria preliminar, como en Uber) pasó el primer nivel de la venganza de Montezuma. No siempre y de manera poco confiable, pero de vez en cuando resulta.

Cual es el resultado?
Como puede ver, en solo unos años, el aprendizaje por refuerzo ha recorrido un largo camino. No solo unas pocas soluciones exitosas, como en las redes convolucionales, donde las conexiones resudales y omitidas permitieron entrenar redes de cientos de capas de profundidad, en lugar de una docena de capas con la función de activación Relu sola, que superó el problema de la desaparición de los gradientes en sigmoide y tanh. En el aprendizaje con refuerzo, ha habido progreso en los conceptos y en la comprensión de las razones por las cuales esta o aquella versión ingenua de la implementación no funcionó. La palabra clave "no funcionó".
Pero desde el punto de vista técnico, todo aún se basa en las predicciones de los mismos valores Q, V o A. No hay dependencias de tiempo a diferentes escalas, como en el cerebro (el aprendizaje jerárquico por refuerzo no cuenta, la jerarquía es demasiado primitiva en comparación con la asociatividad en el cerebro vivo). No hay intentos de llegar a una arquitectura de red diseñada específicamente para el aprendizaje de refuerzo, como sucedió con LSTM y otras redes recurrentes para secuencias de tiempo. El aprendizaje por refuerzo pisa fuerte en el acto, se regocija en pequeños éxitos o se mueve en una dirección completamente equivocada.
Me gustaría creer que una vez en el aprendizaje por refuerzo habrá un avance en la arquitectura de las redes neuronales, similar a lo que sucedió en las redes convolucionales. Y veremos un aprendizaje de refuerzo realmente funcional. Aprendiendo en ejemplos aislados, trabajando con memoria asociativa y trabajando en diferentes escalas de tiempo.