El lenguaje R hoy es una de las herramientas más potentes y multifuncionales para trabajar con datos, pero como sabemos casi siempre, en cualquier barril de miel hay una mosca en la pomada. El hecho es que R tiene un solo subproceso por defecto.
Lo más probable es que esto no te moleste durante un tiempo suficientemente largo, y es poco probable que hagas esta pregunta. Pero, por ejemplo, si se enfrenta a la tarea de recopilar datos de una gran cantidad de cuentas publicitarias de la API, por ejemplo Yandex.Direct, entonces puede reducir significativamente, al menos dos o tres veces, el tiempo que lleva recopilar datos mediante subprocesos múltiples.

El tema de los subprocesos múltiples en R no es nuevo, y se ha planteado repetidamente en Habré aquí , aquí y aquí , pero la última publicación se remonta a 2013, y como dicen, todo lo nuevo está bien olvidado. Además, el subprocesamiento múltiple se discutió previamente para calcular modelos y entrenar redes neuronales, y hablaremos sobre el uso de la asincronía para trabajar con la API. Sin embargo, me gustaría aprovechar esta oportunidad para agradecer a los autores de estos artículos porque Me ayudaron mucho a escribir este artículo con sus publicaciones.
Contenido
La segunda parte del artículo, que trata con opciones más modernas para implementar multihilo en R, está disponible aquí .
¿Qué es multihilo?
Un subproceso (cálculos secuenciales) : un modo de cálculo en el que todas las acciones (tareas) se realizan secuencialmente, la duración total de todas las operaciones dadas en este caso será igual a la suma de la duración de todas las operaciones.
Multithreading (computación paralela) : un modo de computación en el que las acciones (tareas) específicas se realizan en paralelo, es decir al mismo tiempo, mientras que el tiempo total de ejecución de todas las operaciones no será igual a la suma de la duración de todas las operaciones.
Para simplificar la percepción, veamos la siguiente tabla:
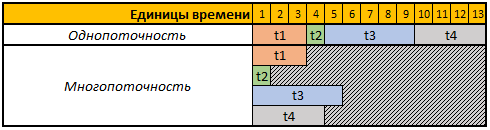
La primera fila de la tabla dada son unidades de tiempo condicionales, en este caso no nos importan segundos, minutos o cualquier otro período de tiempo.
En este ejemplo, necesitamos realizar 4 operaciones, cada operación en este caso tiene una duración de cálculo diferente, en modo de subproceso único, las 4 operaciones se realizarán secuencialmente una tras otra, por lo tanto, el tiempo total para su ejecución será t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
En modo multihilo, las 4 tareas se realizarán en paralelo, es decir, Para comenzar la siguiente tarea, no es necesario esperar hasta que se complete la anterior, por lo que si comenzamos nuestra tarea en 4 subprocesos, el tiempo de cálculo total será igual al tiempo de cálculo de la tarea más grande, en nuestro caso es la tarea t3, cuya duración de cálculo en nuestro ejemplo es 5 unidades temporales, respectivamente, y el tiempo de ejecución de las 4 operaciones en este caso será igual a 5 unidades temporales.
¿Qué paquetes usaremos?
Para los cálculos en modo multiproceso, utilizaremos los doParallel foreach , doSNOW y doParallel .
El paquete foreach permite usar la construcción foreach , que es esencialmente un bucle for mejorado.
Los doParallel doSNOW y doParallel son esencialmente hermanos gemelos, lo que le permite crear clústeres virtuales y usarlos para realizar cálculos paralelos.
Al final del artículo, utilizando el paquete rbenchmark mediremos y compararemos la duración de las operaciones de recopilación de datos desde la API Yandex.Direct utilizando todos los métodos descritos a continuación.
Para trabajar con la API Yandex.Direct, usaremos el paquete ryandexdirect, en este artículo lo usaremos como ejemplo, puede encontrar más detalles sobre sus capacidades y funciones en la documentación oficial .
Código para instalar todos los paquetes necesarios:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
Desafío
Debe escribir un código que solicite una lista de palabras clave de cualquier número de cuentas de publicidad de Yandex.Direct. El resultado debe recopilarse en un marco de fecha, en el que habrá un campo adicional con el inicio de sesión de la cuenta publicitaria a la que pertenece la palabra clave.
Además, nuestra tarea es escribir un código que realice esta operación lo más rápido posible en cualquier número de cuentas publicitarias.
Autorización en Yandex.Direct
Para trabajar con la API de la plataforma de publicidad Yandex.Direct, inicialmente se requiere pasar por una autorización bajo cada cuenta de la cual planeamos solicitar una lista de palabras clave.
Todo el código que se proporciona en este artículo refleja un ejemplo de trabajo con cuentas de publicidad Yandex regulares. Si trabaja con una cuenta de agente, debe usar el argumento AgencyAccount y pasarle el inicio de sesión de la cuenta de agente. Puede obtener más información sobre cómo trabajar con cuentas de agente de Yandex.Direct utilizando el paquete ryandexdirect aquí .
Para la autorización, es necesario ejecutar la función yadirAuth desde el paquete yadirAuth , para repetir el código a continuación es necesario para cada cuenta desde la cual solicitará una lista de palabras clave y sus parámetros.
ryandexdirect::yadirAuth(Login = " ")
El proceso de autorización en Yandex.Direct a través del paquete ryandexdirect completamente seguro, a pesar de que pasa a través de un sitio de terceros. Ya hablé en detalle sobre la seguridad de su uso en el artículo "Qué tan seguro es usar paquetes R para trabajar con la API de sistemas de publicidad" .
Después de la autorización, se creará un archivo login.yadirAuth.RData debajo de cada cuenta en su directorio de trabajo, que almacenará las credenciales para cada cuenta. El nombre del archivo comenzará en el inicio de sesión especificado en el argumento Inicio de sesión . Si necesita guardar los archivos no en el directorio de trabajo actual, sino en alguna otra carpeta, use el argumento TokenPath , pero en este caso, cuando solicite palabras clave usando la función yadirGetKeyWords también debe usar el argumento TokenPath y especificar la ruta a la carpeta donde guardó los archivos con credenciales
Solución secuencial de un solo subproceso con bucle for
La forma más fácil de recopilar datos de varias cuentas a la vez es usar el bucle for . Simple pero no el más efectivo, porque Uno de los principios de desarrollo en el lenguaje R es evitar el uso de bucles en el código.
A continuación se muestra un código de ejemplo para recopilar datos de 4 cuentas utilizando el bucle for, de hecho, puede utilizar este ejemplo para recopilar datos de cualquier número de cuentas publicitarias.
Código 1: procesamos 4 cuentas usando el bucle for habitual library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
La medición del tiempo de ejecución con la función system.time mostró el siguiente resultado:
Tiempo de trabajo:
Usuario: 178.83
sistema: 0.63
pasado: 320.39
La recopilación de palabras clave para 4 cuentas tomó 320 segundos, y de los mensajes de información que muestra la función yadirGetKeyWords durante la operación, se ve la cuenta más grande, de las cuales se recibieron 5970 palabras clave y se procesaron 142 segundos.
Solución de subprocesos múltiples en R
Ya escribí anteriormente que para multihilo usaremos los doParallel doSNOW y doParallel .
Quiero llamar la atención sobre el hecho de que casi cualquier API tiene sus propias limitaciones, y la API Yandex.Direct no es una excepción. De hecho, la ayuda para trabajar con Yandex.Direct API dice:
No se permiten más de cinco solicitudes API simultáneas en nombre de un usuario.
Por lo tanto, a pesar del hecho de que en este caso consideraremos un ejemplo con la creación de 4 transmisiones, al trabajar con Yandex.Direct puede crear 5 transmisiones incluso si envía todas las solicitudes bajo el mismo usuario. Pero es más racional usar 1 subproceso por 1 núcleo de su procesador, puede determinar la cantidad de núcleos físicos del procesador usando el parallel::detectCores(logical = FALSE) , la cantidad de núcleos lógicos se puede encontrar usando parallel::detectCores(logical = TRUE) . Una comprensión más detallada de lo que un núcleo físico y lógico es posible en Wikipedia .
Además del límite en el número de solicitudes, existe un límite diario en el número de puntos para acceder a la API Yandex.Direct, puede ser diferente para todas las cuentas, cada solicitud también consume un número diferente de puntos dependiendo de la operación que se realice. Por ejemplo, para consultar una lista de palabras clave, se le deducirán 15 puntos por una consulta completa y 3 puntos por cada 2000 palabras, puede averiguar cómo se anulan los puntos en el certificado oficial . También puede ver información sobre el número de puntos anotados y disponibles, así como su límite diario en mensajes de información devueltos a la consola por la función yadirGetKeyWords .
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
Tratemos con doSNOW y doParallel en orden.
Paquete DoSNOW y funciones multiproceso
Reescribimos la misma operación para el modo de cálculos de subprocesos múltiples, creamos 4 hilos en este caso, y en lugar del ciclo for , usamos la construcción foreach .
Código 2: Computación paralela con doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
En este caso, la medición del tiempo de ejecución con la función system.time mostró el siguiente resultado:
Tiempo de trabajo:
usuario: 0,17
sistema: 0.08
pasado: 151.47
El mismo resultado, es decir recibimos la colección de palabras clave de 4 cuentas Yandex. Direct en 151 segundos, es decir 2 veces más rápido Además, acabo de escribir en el último ejemplo cuánto tiempo tardó en cargar una lista de palabras clave de la cuenta más grande (142 segundos), es decir. En este ejemplo, el tiempo total es casi idéntico al tiempo de procesamiento de la cuenta más grande. El hecho es que con la ayuda de la función foreach , lanzamos simultáneamente el proceso de recopilación de datos en 4 flujos, es decir, Al mismo tiempo, los datos recopilados de las 4 cuentas, respectivamente, el tiempo total es igual al tiempo de procesamiento de la cuenta más grande.
makeCluster una pequeña explicación al código 2 , la función makeCluster responsable de la cantidad de subprocesos, en este caso creamos un clúster de 4 núcleos de procesador, pero como escribí anteriormente cuando trabajaba con Yandex.Direct API, puede crear 5 subprocesos, independientemente de cuántas cuentas necesita procesar 5-15-100 o más, puede enviar 5 solicitudes a la API al mismo tiempo.
A continuación, la función registerDoSNOW inicia el clúster creado.
Después de eso, usamos la construcción foreach , como dije antes, esta construcción es un bucle mejorado. Establece el contador como el primer argumento, en el ejemplo que llamé login y iterará sobre los elementos del vector de inicio de sesión en cada iteración, obtendríamos el mismo resultado en el bucle for si escribiéramos for ( login in logins) .
A continuación, debe indicar en el argumento .combine la función con la que combinará los resultados obtenidos en cada iteración, las opciones más comunes son:
rbind : une las tablas resultantes fila por fila una debajo de la otra;cbind : une las tablas resultantes en columnas;"+" : resume el resultado obtenido en cada iteración.
También puede usar cualquier otra función, incluso autoescrita.
El argumento .inorder = F le permite acelerar la función un poco más si no le importa en qué orden combinar los resultados, en este caso el orden no es importante para nosotros.
Luego viene el operador %dopar% , que inicia el ciclo en modo de cómputo paralelo, si usa el operador %do% , las iteraciones se ejecutarán secuencialmente, así como también cuando se usa el ciclo for habitual.
La función stopCluster detiene el clúster.
El subprocesamiento múltiple, o más bien la construcción foreach en modo multiproceso, tiene algunas características, de hecho, en este caso, comenzamos cada proceso paralelo en una nueva sesión R limpia. Por lo tanto, para usar las funciones genéricas y los objetos dentro de él que se definieron fuera de la construcción foreach , debe exportarlos usando el argumento .export . Este argumento toma un vector de texto que contiene los nombres de los objetos que usará dentro de foreach .
Además, foreach , en modo paralelo, no ve los paquetes conectados previamente de forma predeterminada, por lo que también deberán pasarse dentro de foreach utilizando el argumento .packages . También es necesario transferir paquetes enumerando sus nombres en un vector de texto, por ejemplo .packages = c("ryandexdirect", "dplyr", "lubridate") . En el ejemplo de código anterior 2 , simplemente cargamos de esta manera el paquete ryandexdirect en cada iteración de foreach .
Paquete DoParallel
Como escribí anteriormente, los doParallel doSNOW y doParallel son gemelos, por lo que tienen la misma sintaxis.
Código 5: Computación paralela con doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
Tiempo de trabajo:
usuario: 0.25
sistema: 0.01
pasado: 173.28
Como puede ver en este caso, el tiempo de ejecución difiere ligeramente del ejemplo anterior del código de computación paralela que usa el paquete doSNOW .
Prueba de velocidad entre los tres enfoques revisados
Ahora ejecute la prueba de velocidad utilizando el paquete rbenchmark .
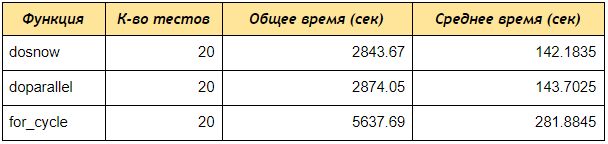
Como puede ver, incluso en una prueba de 4 cuentas, los doParallel doSNOW y doParallel recibieron datos por palabras clave 2 veces más rápido que el bucle secuencial, si crea un grupo de 5 núcleos y procesa 50 o 100 cuentas, la diferencia será aún más significativa.
Código 6: Script para comparar la velocidad de subprocesamiento múltiple y computación secuencial # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
En conclusión, daré una explicación del código 5 anterior, con el que probamos la velocidad del trabajo.
Inicialmente, creamos tres funciones:
for_fun : una función que solicita palabras clave de varias cuentas y las for_fun secuencialmente a través de un ciclo regular.
dosnow_fun : una función que solicita una lista de palabras clave en modo multiproceso, utilizando el paquete doSNOW .
dopar_fun : una función que solicita una lista de palabras clave en modo multiproceso, utilizando el paquete doParallel .
A continuación, dentro de la construcción dentro, ejecutamos la función de benchmark desde el paquete rbenchmark , especificamos los nombres de las pruebas (for_cycle, dosnow, doparallel), y cada función especificamos las funciones, respectivamente: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
El argumento de las réplicas es responsable de la cantidad de pruebas, es decir. ¿Cuántas veces ejecutaremos cada función?
El argumento de columnas le permite especificar qué columnas desea recibir, en nuestro caso 'prueba', 'replicaciones', 'transcurrido' significa devolver las columnas: nombre de la prueba, número de pruebas, tiempo total de ejecución de todas las pruebas.
También puede agregar columnas calculadas, ( { average = elapsed/replications } ), es decir la salida será una columna promedio que dividirá el tiempo total entre el número de pruebas, por lo que calculamos el tiempo promedio de ejecución de cada función.
La orden es responsable de ordenar los resultados de la prueba.
Conclusión
En este artículo, en principio, se describe un método bastante universal para acelerar el trabajo con la API, pero cada API tiene sus límites, por lo tanto, específicamente en esta forma, con tantos hilos, el ejemplo anterior es adecuado para trabajar con Yandex.Direct API, para usarlo con la API de otros servicios, inicialmente es necesario leer la documentación sobre los límites en la API para el número de solicitudes enviadas simultáneamente, de lo contrario, puede obtener un error de Too Many Requests .
La continuación de este artículo está disponible aquí .