
El aprendizaje automático se usa activamente en muchas áreas de nuestras vidas. Los algoritmos ayudan a reconocer las señales de tráfico, filtran el correo no deseado, reconocen las caras de nuestros amigos en Facebook e incluso ayudan a negociar en las bolsas de valores. El algoritmo toma decisiones importantes, por lo que debe asegurarse de que no se pueda engañar.
En este artículo, que es el primero de una serie, le presentaremos el problema de la seguridad de los algoritmos de aprendizaje automático. Esto no requiere un alto nivel de conocimiento del aprendizaje automático del lector, es suficiente tener una idea general de esta área.
Primero, damos los términos utilizados en el tema de la seguridad de los algoritmos de aprendizaje automático:
Un ejemplo de confrontación es un vector que alimenta una entrada a un algoritmo en el cual el algoritmo produce una salida incorrecta.
Ataque adversario : un algoritmo de acción cuyo objetivo es obtener un ejemplo adversario.
Para comprender el problema de los ejemplos adversarios, recordemos una de las tareas del aprendizaje automático: aprender con un profesor en la calificación. En este problema, tenemos pares de "etiqueta de objeto", y debemos aprender a predecir el valor de los nuevos objetos.
Si consideramos este problema desde un punto de vista geométrico, es necesario dividir el espacio de tal manera que prediga la clase "correcta" en el nuevo objeto. Además, si tuviéramos un conjunto de datos generales (por ejemplo, para un conjunto de dígitos manuscritos MNIST para tener todo tipo de imágenes de todos los dígitos), este hiperplano podría llevarse a cabo idealmente siempre que las clases sean separables. Pero dado que la población general no existe con mayor frecuencia, para resolver este problema usamos algoritmos de aprendizaje automático para aproximar el hiperplano "ideal" con la mayor precisión posible utilizando los datos que tenemos.
Cualquier desviación del hiperplano del ideal da lugar a una cierta "brecha", en la que los objetos se clasifican incorrectamente. Es por eso que aparecen ejemplos como el panda, clasificado como gibbon. Y la tarea del atacante se reduce a cambiar el vector de los parámetros del objeto para que caiga en esta "brecha".
Ejemplos de ataques adversos
Hay una red neuronal que detecta la cara en una fotografía. Ella hace frente con éxito a la tarea (imagen a la izquierda). Pero después de agregar un poco de ruido a esta foto (imagen a la derecha), el algoritmo en el ejemplo de confrontación obtenido (imagen en el centro) ya no detecta la cara en la imagen.

Este ejemplo, demostrado en el artículo " Ataques adversos en detectores faciales que utilizan la optimización restringida basada en redes neuronales", es interesante porque muchos sistemas de reconocimiento de rostros reales utilizan enfoques de redes neuronales para detectar rostros. Una persona no notará la diferencia al mirar ambas imágenes.
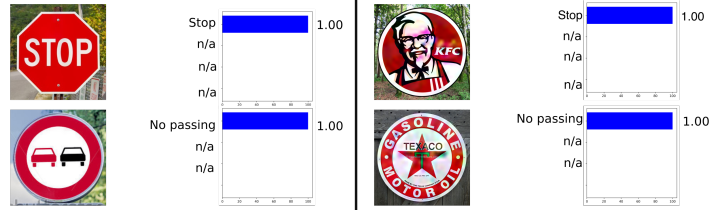
El siguiente ejemplo fue tomado de automoción, a saber, el reconocimiento de señales de tráfico. Este ejemplo es interesante porque el ejemplo de confrontación no tiene que ser un objeto al menos algo cercano a los objetos en los que se entrenó la red. Por ejemplo, en Rogue Signs: engañando al reconocimiento de señales de tráfico con anuncios maliciosos y logotipos , se demostró que la red neuronal original "reconocerá" el ejemplo de confrontación de la señal KFC como una señal STOP con un 100% de probabilidad.
Muchos podrían dudar del uso de ejemplos adversos en el mundo real, ya que los ejemplos anteriores se probaron en una computadora, mientras que en la vida real es difícil obtener dicho objeto. Pero esto no es así. Sintetizar ejemplos adversos robustos mostró que un ejemplo de confrontación realizado en una computadora puede imprimirse con éxito en una impresora 3D, y el algoritmo cometerá los mismos errores que con una simulación por computadora.

Aquí puede ver una tortuga impresa en una impresora 3D que no fue reconocida como tortuga en ningún ángulo.
El siguiente ejemplo muestra lo que se puede hacer si vamos más allá de la comprensión habitual de los ataques adversos. A saber, reprogramar la red de origen para usar su propia carga útil. En otras palabras, aprendemos a usar la red neuronal de otra persona para resolver el problema que plantea el atacante. Por ejemplo, la Reprogramación Adversal de la Red Neural demostró cómo una red entrenada en ImageNet calculó perfectamente el número de cuadrados en una imagen y reconoció los números del conjunto MNIST.
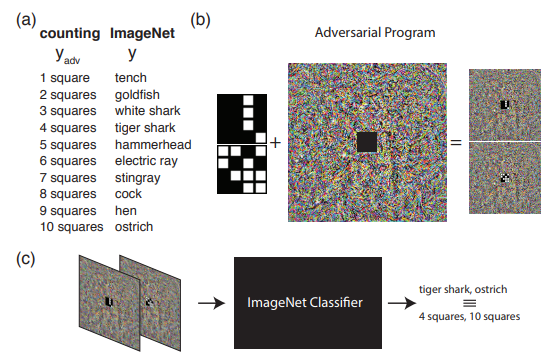
La imagen muestra el algoritmo para trabajar con la Reprogramación Adversarial, que se recomienda conocer mejor en el artículo original.
En este artículo, me gustaría hablar específicamente sobre los métodos para generar ejemplos adversarios, y en el segundo artículo pasaremos a los métodos de protección y prueba de algoritmos de aprendizaje automático.
Clasificación de ataque
Todos los ataques se pueden dividir en 2 clases: WhiteBox (WB) y BlackBox (BB) . En el caso de WB, conocemos toda la información sobre el modelo entrenado del algoritmo, mientras que en el caso de BB solo tenemos acceso a la entrada y salida del modelo. De hecho, la opción GrayBox todavía es posible cuando no conocemos la información sobre el modelo entrenado, pero hay información sobre el tipo de algoritmo y sus hiperparámetros. Pero este tipo no se destaca en una clase separada, ya que la información adicional no es suficiente para ir a WB, lo que significa que esto es solo un conjunto adicional de información para llevar a cabo un ataque BB.
A continuación, vale la pena clasificar los ataques dirigidos y no dirigidos . Los ataques dirigidos significan que el ataque se lleva a cabo en una determinada dirección. Por ejemplo, en el conjunto de datos MNIST, entrenamos la red neuronal y tomamos la imagen 0 del conjunto de prueba. Una red neuronal entrenada produce una probabilidad de clase 0 de 1.00 en este objeto. Si queremos que el ejemplo de adversario sea reconocido como clase 1 después de aplicar el ataque de adversario, entonces usaremos el ataque dirigido. De lo contrario, si no es particularmente importante para nosotros a qué clase la red neuronal recibirá la imagen (lo principal es que ya no es clase 0), entonces dicho ataque será No Dirigido.
Además, los ataques se dividen en una métrica según la cual 2 objetos se consideran similares: normas norma: el número de parámetros modificados. Distancia euclidiana entre dos vectores. Máxima diferencia de elementos entre dos vectores.
Bibliotecas Python
Las bibliotecas de datos de Python le permiten trabajar con ejemplos adversarios. Estos son FoolBox, CleverHans y ART-IBM.
| Tonto | Cleverhans | ART-IBM |
|---|
| Marcos soportados | TensorFlow, Keras, Theano, PyTorch, Lasagne, MXNet | TensorFlow, Keras | TensorFlow, Keras, promesa MXNet, PyTorch |
Ahora veamos los ataques con un poco más de detalle y comencemos con los ataques de WhiteBox.
Ataque L-BFGS
La declaración del método L-BFGS se puede escribir de la siguiente manera.
De ello se deduce que queremos minimizar la función de pérdida en la dirección de la clase objetivo con la restricción de que los cambios introducidos fueron mínimos. Al mismo tiempo, se propuso resolver dicho problema en el artículo original utilizando el método L-BFGS, de ahí el nombre de este ataque.
Artículo original: propiedades intrigantes de las redes neuronales
Este ataque se presenta en 2 de 3 bibliotecas expresadas anteriormente: FoolBox y CleverHans.
Y la aplicación de este ataque en FoolBox toma 3 líneas de código en Python:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
El uso de L-BFGS lo ayudará a encontrar los mejores ejemplos adversos en función de sus limitaciones, pero, en primer lugar, buscar dicho ejemplo puede llevar mucho tiempo y, en segundo lugar, es muy posible que el método simplemente no converja.
Ataque FGSM
La siguiente etapa de desarrollo fue el FGSM (Fast Sign Gradient Method), que se puede mostrar usando la fórmula:
Este método funciona mucho más rápido que L-BFGS. Aquí simplemente tomamos los signos de la función de gradiente de la función de pérdida original, multiplicando el signo por algunos , agregar a la imagen original.

Aquí hay un ejemplo de cómo funciona este método. Un mapa de ruido con igual a 0.007, y resulta que la foto del panda ahora se reconoce como Gibbon con una probabilidad de 99.3%
Este método es simple de implementar, pero al mismo tiempo, el resultado de este método es muy ruidoso.
Artículo original - Explicación y aprovechamiento de ejemplos adversarios
Puede encontrar la implementación de este método en bibliotecas, y usar foolbox tampoco tomará mucho tiempo.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
Ataque profundo
DeepFool es un método no dirigido. Su principal diferencia con los métodos anteriores es que trata de hacer un mapa de ruido mínimo, lo que engañará al algoritmo. El método no le permite hacer una clase particular de una clase, pero sí cualquier otra que esté más cerca de la imagen original.

Un ejemplo muestra la imagen original, en la línea inferior, el método FGSM y en el medio, solo un ataque DeepFool. Se puede ver que la tarjeta de ruido es mucho más pequeña que con FGSM.
Artículo original - DeepFool: un método simple y preciso para engañar a las redes neuronales profundas
Tal ataque puede llevarse a cabo utilizando cualquiera de las bibliotecas enumeradas, y la implementación en ART-IBM toma solo 3 líneas de código:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
Ataque jacobiano de mapa de prominencia
En el método JSMA, se considera una derivada directa, sobre la base de la cual se construye un mapa de gradiente. En el mapa, cada parámetro del objeto corresponde de hecho a la contribución de este parámetro para cambiar el resultado final del algoritmo. Por lo tanto, el método le permite cambiar la menor cantidad posible de parámetros en el objeto atacado. Y, en consecuencia, funciona en normal
Artículo original - Las limitaciones del aprendizaje profundo en entornos adversos
Este ataque puede llevarse a cabo utilizando CleverHans o ART-IBM. Y en CleverHans, se ve así:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
Ataque de un píxel
La pregunta lógica es, ¿cuál es el número mínimo de píxeles que deben cambiarse para llevar a cabo un ataque al algoritmo, y como muchos ya han adivinado por el nombre del ataque, 1 píxel es suficiente.

Por ejemplo, la imagen de un caballo con solo un píxel cambiado se convierte en una rana con una probabilidad del 99.9%
Artículo original: un ataque de píxeles para engañar a las redes neuronales profundas
Este ataque solo se admite en FoolBox, y su implementación es la siguiente:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
Aquí vale la pena hacer una reserva y decir que la implementación del algoritmo en Foolbox, en comparación con el artículo original, aunque tiene un objetivo común (cambiar el número específico de píxeles en la imagen), pero difiere en el método de obtención de la imagen.
Métodos basados en la generalización del modelo BlackBox
La mayoría de los métodos requieren una comprensión de cómo está estructurada la arquitectura del modelo, el conocimiento de los valores exactos de sus parámetros, pero en la práctica esto rara vez es posible. Y es por eso que aparece una dirección de ataque separada: los ataques BlacBox / GrayBox. Para tales ataques, es suficiente tener acceso a la entrada y salida del modelo.
Uno de los métodos para implementar un ataque en el modelo BlackBox es generalizar este modelo al modelo Estudiante (en la imagen Sustituto).
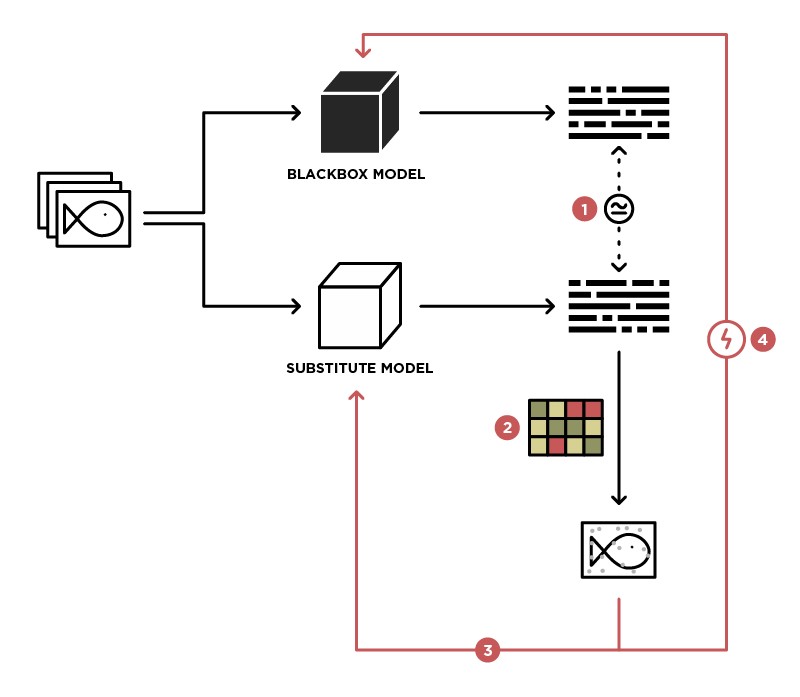
Al tener acceso para enviar datos al modelo BlackBox (Profesor) y acceso a la salida de este modelo, podemos crear un conjunto de datos en el que es posible entrenar a nuestro propio modelo (Estudiante), generalizando así el modelo Maestro. Después de eso, puede usar el ataque WhiteBox en el modelo de Estudiante, y con un alto grado de probabilidad, este ataque también tendrá lugar en el modelo de Profesor. La probabilidad de tal ataque es mayor, más conocimiento sobre el modelo de Profesor que tenemos. Por ejemplo, sabemos que el modelo Profesor procesa imágenes, la mayoría de las veces se utilizan arquitecturas pre-entrenadas (ResNet, Inception) con pesos ImageNet para el procesamiento de imágenes. Basado en el modelo de Student con la misma arquitectura, la probabilidad de un ataque exitoso será maximizada.
Artículo original - Prácticos ataques de caja negra contra el aprendizaje automático
Este método no se presenta en ninguna de las bibliotecas y requiere una implementación independiente del modelo de Student, y los ataques se pueden llevar a cabo utilizando los métodos descritos anteriormente.
Métodos basados en GAN
La siguiente etapa en el desarrollo de los ataques BlackBox fueron los ataques basados en la incorporación del modelo BlackBox en la arquitectura de la red generativa-adversaria (GAN), una red que permite la generación de nuevos objetos, que posteriormente se transferirán al modelo Black-Box.
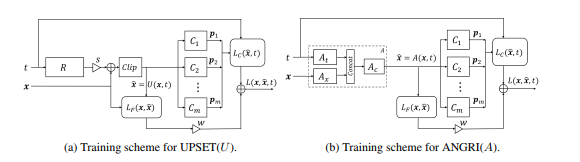
Este método permitió la generación de ejemplos adversos para casi cualquier arquitectura. También requiere acceso a la entrada y salida del modelo atacado.
Lea más sobre este método en el artículo original: UPSET y ANGRI: Rompiendo clasificadores de imágenes de alto rendimiento
Como habrás adivinado, estos métodos no están representados en ninguna de las bibliotecas.
Conclusión
De hecho, hay una gran cantidad de ataques. Este artículo cubre solo algunos de ellos. Esperamos que este material le haya ayudado a comprender los conceptos básicos de ejemplos adversos y sus algoritmos de generación. Para una revisión más detallada, le recomendamos que lea los artículos y materiales originales de la lista de referencias.
Nos vemos en el próximo artículo, que se centrará en los métodos de protección y prueba de algoritmos de aprendizaje automático.
Referencias
- Amenaza de ataques adversos al aprendizaje profundo en visión artificial: una encuesta : una excelente visión general de los métodos de ataque en algoritmos de aprendizaje profundo en visión artificial
- Atacar el aprendizaje automático con ejemplos adversos : un blog de OpenAI dedicado a ejemplos adversos
- Impresionante aprendizaje automático Adversarial : github con enlaces a muchos materiales útiles sobre temas Adversarial
- Presentación sobre Machine Learning Adversarial - Presentación de la conferencia MoscowPythonConf2018 sobre Machine Learning Adversarial