Introduccion
En un artículo anterior (
"Parte 2: Uso de bloques Cypress PSoC UDB para reducir el número de interrupciones en una impresora 3D" ), noté un hecho muy interesante: si una máquina en UDB eliminó datos de FIFO demasiado rápido, logró notar el estado de que hay nuevos no hay datos en FIFO, después de lo cual pasa a un estado falso
Inactivo . Por supuesto, estaba interesado en este hecho. Mostré los resultados abiertos a un grupo de conocidos. Una persona respondió que todo esto era bastante obvio, e incluso mencionó las razones. El resto no estaba menos sorprendido que yo al comienzo de la investigación. Por lo tanto, algunos expertos no encontrarán nada nuevo aquí, pero sería bueno llevar esta información al público en general para que todos los programadores de microcontroladores la tengan en cuenta.
No es que fuera un colapso de algún tipo de cobertura. Resultó que todo esto está bien documentado, pero el problema es que no está en lo principal, sino en documentos adicionales. Y personalmente, estaba felizmente ignorante, creyendo que DMA es un subsistema muy ágil que puede aumentar dramáticamente la eficiencia de los programas, ya que hay una transferencia sistemática de datos sin distraer el incremento del registro y organizar el ciclo con los mismos comandos. En cuanto a mejorar la eficiencia, todo es cierto, pero debido a cosas ligeramente diferentes.
Pero lo primero es lo primero.
Experimentos con Cypress PSoC
Hagamos una máquina simple. Condicionalmente tendrá dos estados: el estado inactivo y el estado en el que caerá cuando haya al menos un byte de datos en FIFO. Al ingresar a tal estado, simplemente toma estos datos y luego nuevamente cae en un estado de reposo. La palabra "condicional" no la cité accidentalmente. Tenemos dos FIFO, por lo que haré dos de esos estados, uno para cada FIFO, para asegurarme de que son completamente idénticos en comportamiento. El gráfico de transición para la máquina resultó así:
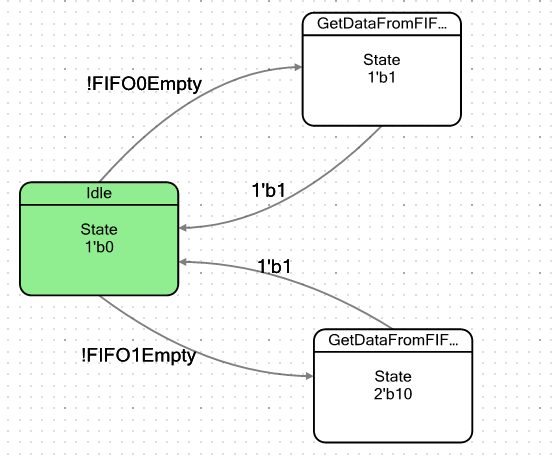
Los indicadores para salir del estado inactivo se definen de la siguiente manera:
No olvide enviar los bits del número de estado a las entradas de Datapath:

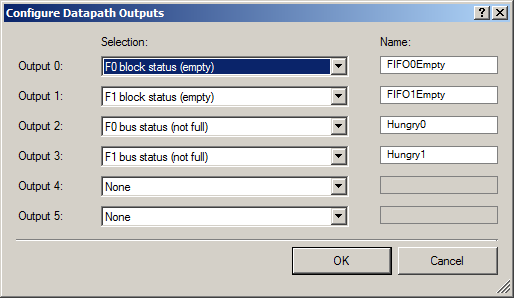
En el exterior, emitimos dos grupos de señales: un par de señales de que FIFO tiene espacio libre (para que DMA pueda comenzar a cargar datos) y un par de señales de que FIFO están vacías (para mostrar este hecho en un osciloscopio).

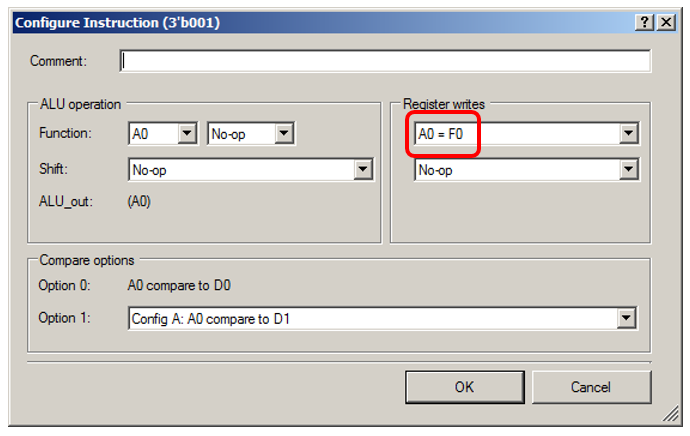
ALU simplemente tomará datos ficticios de FIFO:

Déjame mostrarte los detalles del estado "0001":
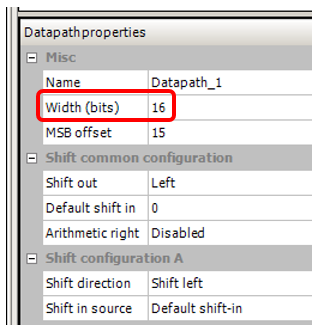
También configuré el ancho del bus, que estaba en el proyecto en el que noté este efecto, 16 bits:
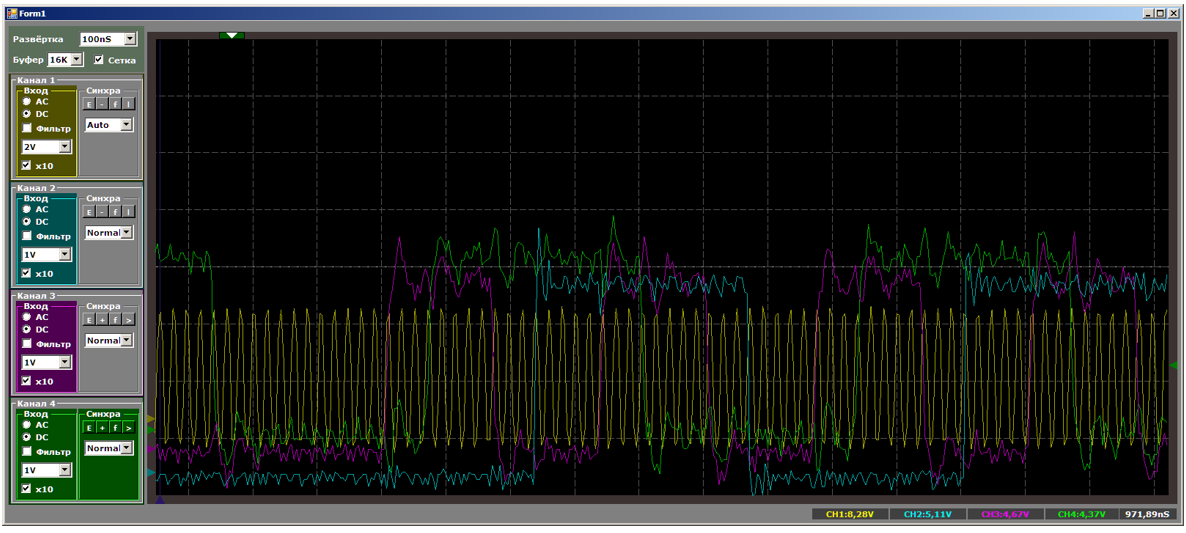
Pasamos al esquema del proyecto en sí. Exteriormente, doy no solo señales de que el FIFO está vacío, sino también pulsos de reloj. Esto me permitirá prescindir de las mediciones del cursor en un osciloscopio. Solo puedo tomar medidas con el dedo.
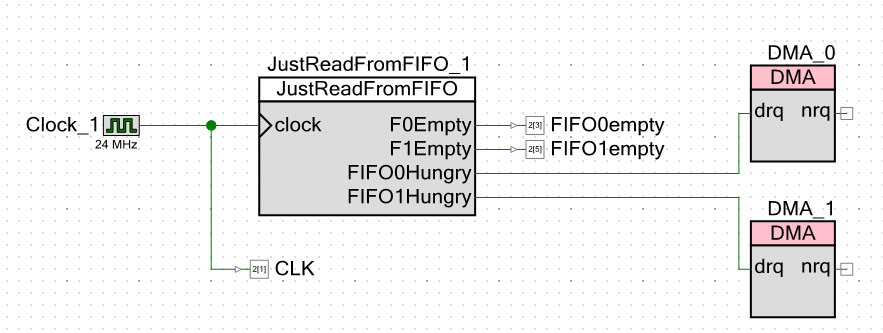
Aparentemente, hice 24 megahercios de velocidad de reloj. La frecuencia central del procesador es exactamente la misma. Cuanto más baja es la frecuencia, menos interferencia hay en un osciloscopio chino (oficialmente tiene una banda de 250 MHz, pero luego megahercios chinos), y todas las mediciones se realizarán con respecto a los pulsos de reloj. Cualquiera sea la frecuencia, el sistema seguirá funcionando con respecto a ellos. Hubiera establecido un megahercio, pero el entorno de desarrollo me prohibió ingresar un valor de frecuencia central del procesador de menos de 24 MHz.
Ahora las cosas de prueba. Para escribir a FIFO0, hice esta función:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
La palabra ROM en el nombre de la función se debe al hecho de que la matriz que se enviará se almacena en el área ROM, y el Cortex M3 tiene una arquitectura de Harvard. La velocidad de acceso al bus RAM y al bus ROM puede variar, quería comprobarlo, por lo que tengo una función similar para enviar una matriz desde RAM (la matriz de
pasos no tiene un modificador de
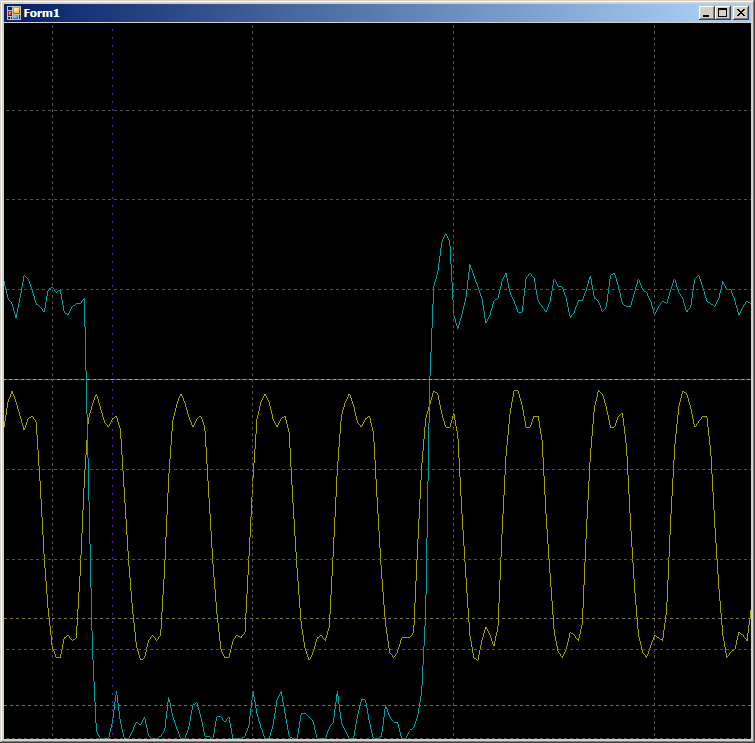
constante estático en su cuerpo). Bueno, hay el mismo par de funciones para enviar a FIFO1, el registro del receptor es diferente allí: no F0, sino F1. De lo contrario, todas las funciones son idénticas. Como no noté mucha diferencia en los resultados, consideraré los resultados de invocar exactamente la función anterior. Un rayo amarillo - pulsos de reloj, salida azul
FIFO0 vacío .

Primero, verifique la plausibilidad de por qué el FIFO se completa en dos ciclos de reloj. Veamos este sitio con más detalle:
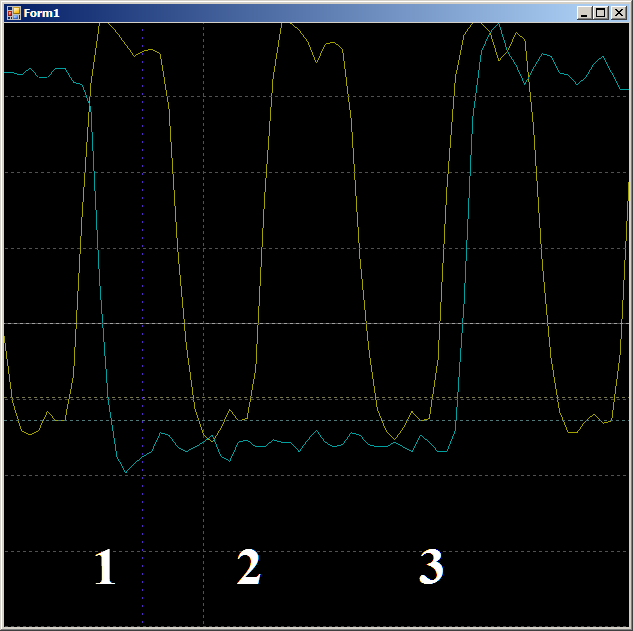
En el borde 1, los datos caen en FIFO, el indicador de
FIFO0enmpty cae. En el borde 2, el autómata ingresa al estado
GetDataFromFifo1 . En el borde 3, en este estado, los datos de FIFO se copian en el registro ALU, se vacía FIFO, se vuelve a
levantar el indicador de
vacío FIFO0 . Es decir, la forma de onda se comporta de manera plausible, puede contar con ella durante el ciclo del reloj. Obtenemos 9 piezas.
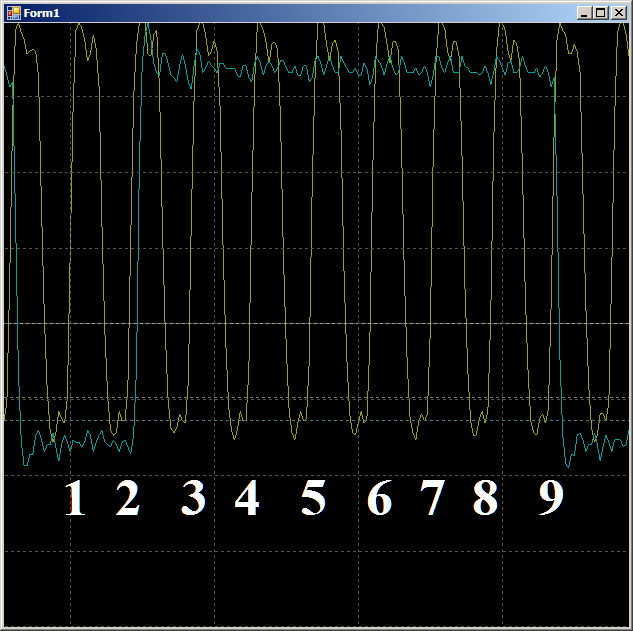 En total, en el área inspeccionada, se necesitan 9 ciclos de reloj para copiar una palabra de datos de RAM a UDB usando DMA.
En total, en el área inspeccionada, se necesitan 9 ciclos de reloj para copiar una palabra de datos de RAM a UDB usando DMA.Y ahora lo mismo, pero con la ayuda del núcleo del procesador. Primero, un código ideal que difícilmente se puede lograr en la vida real:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
lo que se convertirá en código de ensamblaje:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
Sin descansos, sin ciclos adicionales. Dos pares de medidas seguidas ...
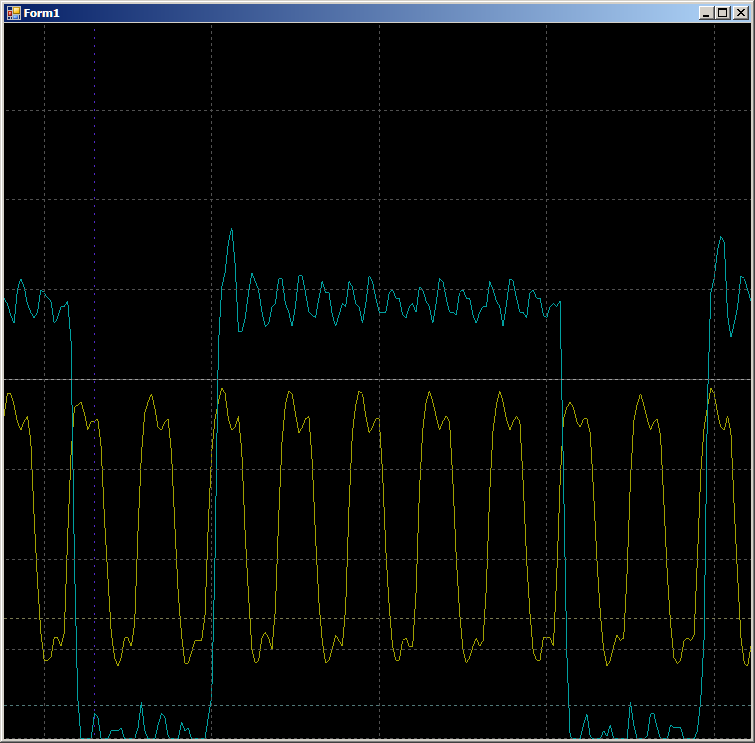
Hagamos que el código sea un poco más real (con la sobrecarga de organizar el ciclo, obtener datos e incrementar los punteros):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
código de ensamblador recibido:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
En el oscilograma vemos solo 7 ciclos por ciclo versus nueve en el caso de DMA:
Un poco sobre el mito
Para ser sincero, para mí fue originalmente un shock. De alguna manera, estoy acostumbrado a creer que el mecanismo DMA le permite transferir datos de manera rápida y eficiente. 1/9 de la frecuencia del bus no es tan rápida. Pero resultó que nadie lo estaba ocultando. El documento TRM para PSoC 5LP incluso contiene una serie de consideraciones teóricas, y el documento "AN84810 - Temas avanzados de DMA de PSoC 3 y PSoC 5LP" describe en detalle el proceso de acceso a DMA. La latencia es la culpable. El ciclo de intercambio con el autobús requiere un cierto número de ticks. En realidad, son estas medidas las que juegan un papel decisivo en la aparición de un retraso. En general, nadie esconde nada, pero debes saberlo.
Si el famoso GPIF utilizado en FX2LP (otra arquitectura fabricada por Cypress) no limita nada, entonces el límite de velocidad se debe a las latencias que se producen al acceder al bus.Verificación DMA en STM32
Estaba tan impresionado que decidí realizar un experimento en STM32. Un STM32F103 que tiene el mismo núcleo de procesador Cortex M3 se tomó como un conejo experimental. No tiene UDB de donde se puedan derivar las señales de servicio, pero es muy posible verificar DMA. ¿Qué es un GPIO? Este es un conjunto de registros en un espacio de direcciones común. Eso es genial Configuramos DMA en el modo de copia “memoria-memoria”, especificando la memoria real (ROM o RAM) como la fuente, y el registro de datos GPIO sin el incremento de dirección como receptor. Enviaremos allí alternativamente 0 o 1, y arreglaremos el resultado con un osciloscopio. Para comenzar, elegí el puerto B, fue más fácil conectarme a él en el tablero.

Realmente disfruté contar medidas con un dedo, no con cursores. ¿Es posible hacer lo mismo en este controlador? Bastante! Tome la frecuencia de reloj de referencia para el osciloscopio del tramo MCO, que está conectado al puerto PA8 en el STM32F10C8T6. La elección de las fuentes para este cristal barato no es excelente (el mismo STM32F103, pero más impresionante, ofrece muchas más opciones), enviaremos la señal SYSCLK a esta salida. Dado que la frecuencia en la MCO no puede ser superior a 50 MHz, reduciremos la velocidad general del reloj del sistema a 48 MHz. Multiplicaremos la frecuencia de cuarzo 8 MHz no por 9, sino por 6 (ya que 6 * 8 = 48):

Mismo texto: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
Programaremos la MCO utilizando la biblioteca
mcucpp de Konstantin Chizhov (de ahora en adelante, conduciré todas las llamadas al equipo a través de esta maravillosa biblioteca):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Bueno, ahora configuramos la salida de la matriz de datos en el GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
La forma de onda resultante es muy similar a la del PSoC.

En el medio hay una gran joroba azul. Este es el proceso de inicialización de DMA. Los pulsos azules de la izquierda fueron recibidos únicamente por software en PB1. Estíralos más:

2 medidas por pulso. El funcionamiento del sistema es el esperado. Pero ahora veamos el área más grande marcada en la forma de onda principal con un fondo azul oscuro. En este punto, el bloque DMA ya se está ejecutando.
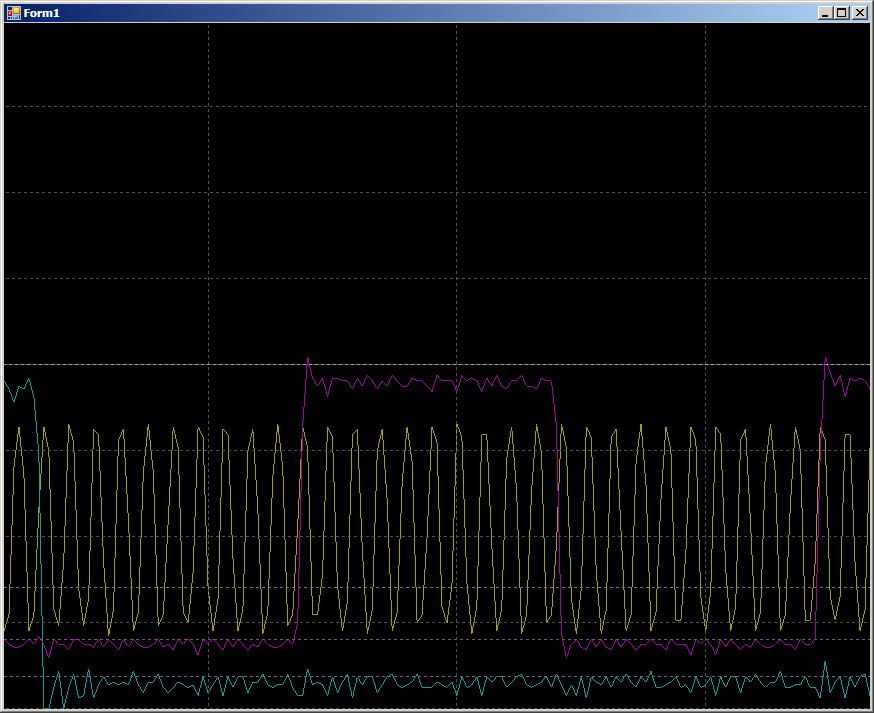
10 ciclos por cambio de línea GPIO. En realidad, el trabajo va con RAM, y el programa se repite en un ciclo constante. No hay llamadas a RAM desde el núcleo del procesador. El bus está completamente a disposición de la unidad DMA, pero 10 ciclos. Pero, de hecho, los resultados no son muy diferentes de los que se ven en el PSoC, así que simplemente comience a buscar Notas de aplicación relacionadas con DMA en STM32. Había varios de ellos. Hay AN2548 en F0 / F1, hay AN3117 en L0 / L1 / L3, hay AN4031 en F2 / F4 / F77. Quizás hay algunos más ...
Pero, sin embargo, de ellos vemos que también aquí, la latencia es la culpable. Además, el acceso por lotes F103 al bus con DMA es imposible. Son posibles para F4, pero no más de cuatro palabras. Entonces nuevamente surgirá el problema de latencia.
Intentemos realizar las mismas acciones, pero con la ayuda de un registro de programa. Arriba, vimos que la grabación directa en los puertos se realiza instantáneamente. Pero había más bien un registro perfecto. Filas:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
sujeto a dicha configuración de optimización (debe especificar la optimización por tiempo):

convertido en el siguiente código de ensamblador:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
En la copia real, habrá una llamada a la fuente, al receptor, un cambio en la variable del bucle, ramificación ... En general, mucha sobrecarga (que, como se cree, simplemente elimina el DMA). ¿Cuál será la velocidad de los cambios en el puerto? Entonces, escribimos:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Este código C ++ se convierte en dicho código de ensamblaje:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
Y obtenemos:
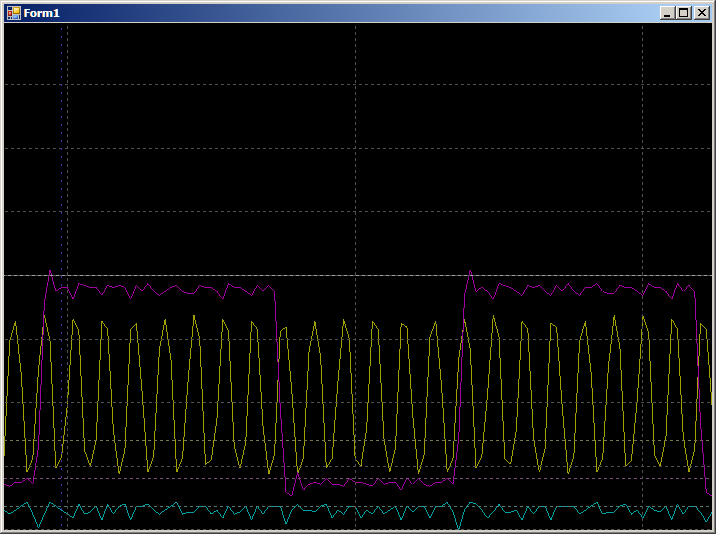
8 medidas en el medio ciclo superior y 6 en la mitad inferior (lo comprobé, el resultado se repite para todos los medios períodos). La diferencia surgió porque el optimizador hizo 2 copias por iteración. Por lo tanto, se agregan 2 medidas en uno de los medios períodos a la operación de sucursal.
En términos generales, con la copia de software, se gastan 14 medidas en copiar dos palabras contra 20 medidas en la misma, pero por DMA. El resultado está bastante documentado, pero es muy inesperado para aquellos que aún no han leído la literatura extendida.Bueno Pero, ¿qué sucede si comienza a escribir datos en dos flujos DMA a la vez? ¿Cuánta velocidad caerá? Conecte el rayo azul a PA0 y vuelva a escribir el programa de la siguiente manera:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Primero, examinemos la naturaleza de los pulsos:
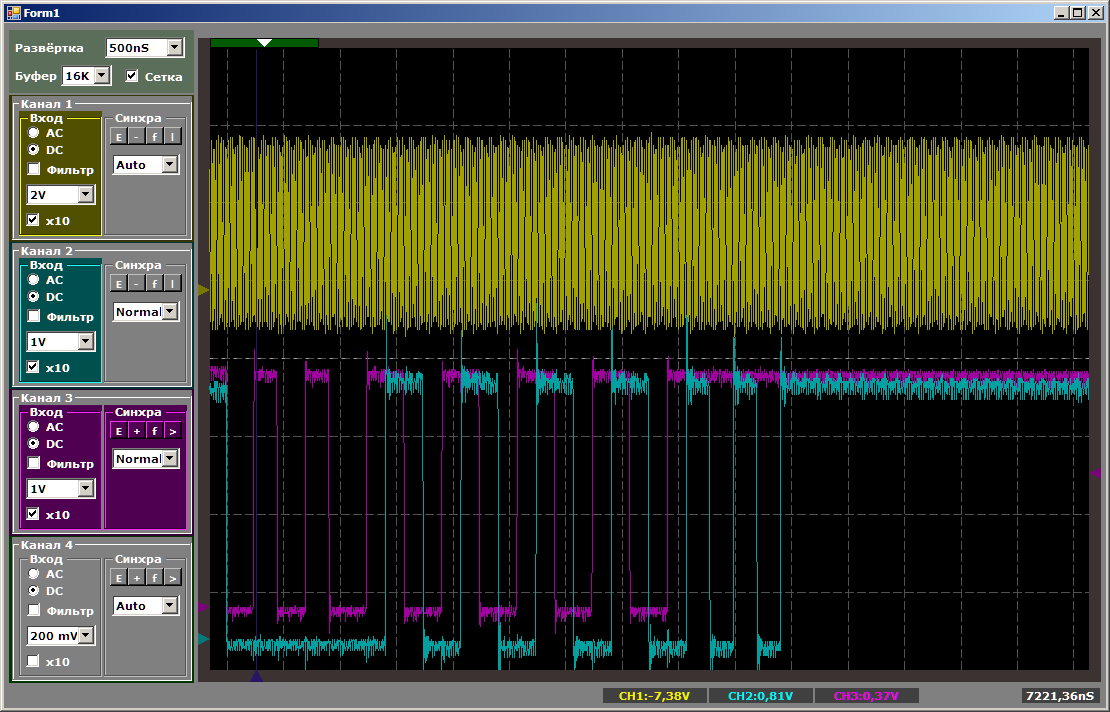
Mientras se sintoniza el segundo canal, la velocidad de copia para el primero es mayor. Luego, al copiar en pares, la velocidad disminuye. Cuando finaliza el primer canal, el segundo comienza a funcionar más rápido. Todo es lógico, solo queda descubrir exactamente cuánto cae la velocidad.
Si bien solo hay un canal, la grabación toma de 10 a 12 compases (los dígitos están flotando).

Durante la colaboración, obtenemos 16 ciclos por registro en cada puerto:
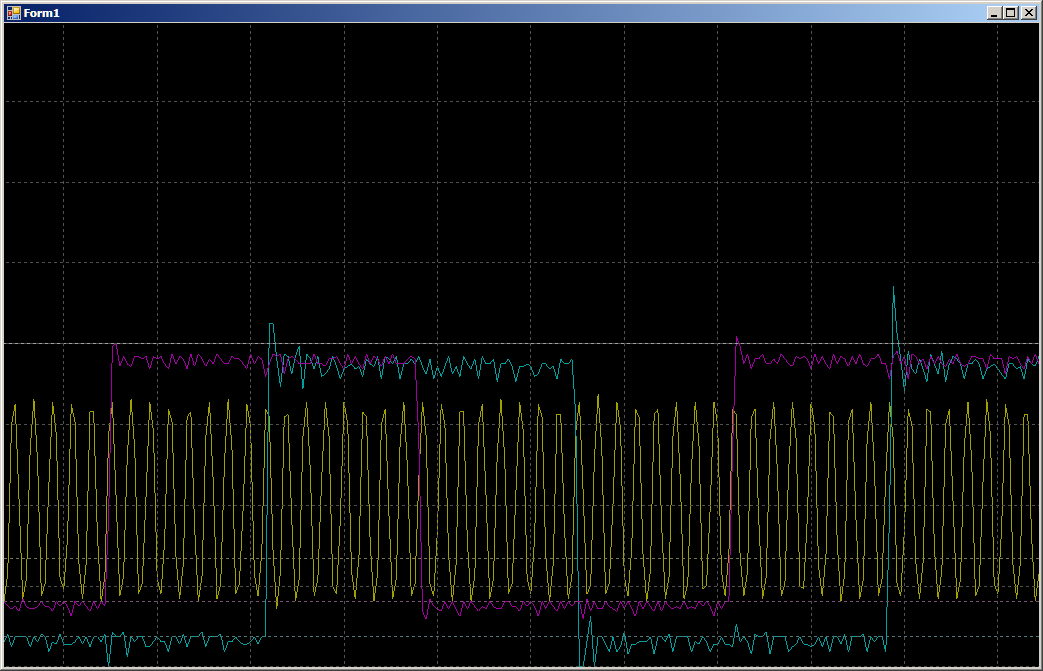
Es decir, la velocidad no se reduce a la mitad. Pero, ¿qué pasa si comienzas a escribir en tres hilos a la vez? Agregamos trabajo con PC15, ya que PC0 no se emite (es por eso que no se emiten 0, 1, 0, 1 ..., sino 0x0000,0x8001, 0x0000, 0x8001 ... en la matriz).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Aquí el resultado es tan inesperado que apago el haz que muestra la frecuencia del reloj. No tenemos tiempo para mediciones. Nos fijamos en la lógica del trabajo.

Hasta que el primer canal terminó el trabajo, el tercero no comenzó a funcionar. ¡Tres canales al mismo tiempo no funcionan! Algo sobre este tema se puede deducir de AppNote a DMA, dice que F103 tiene solo dos motores en un bloque (y copiamos usando un bloque de DMA, el segundo está inactivo ahora, y el volumen del artículo ya es tal que puedo usarlo No lo haré) Reescribimos el programa de muestra para que el tercer canal comience antes que todos los demás:

Mismo texto: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
La imagen cambiará de la siguiente manera:

Se lanzó el tercer canal, incluso funcionó junto con el primero, pero cuando el segundo ingresó al negocio, el tercero fue suplantado hasta que se completó el primer canal.
Un poco sobre prioridades
En realidad, la imagen anterior está relacionada con las prioridades de DMA, hay algunas. Si todos los canales en funcionamiento tienen la misma prioridad, sus números entran en juego. Dentro de una prioridad dada, quien tiene un número menor es el que tiene prioridad. Probemos con el tercer canal para indicar una prioridad global diferente, elevándola por encima de todas las demás (en el camino, también aumentaremos la prioridad del segundo canal):

Mismo texto: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Ahora el primero que solía ser el más cool estará en desventaja.
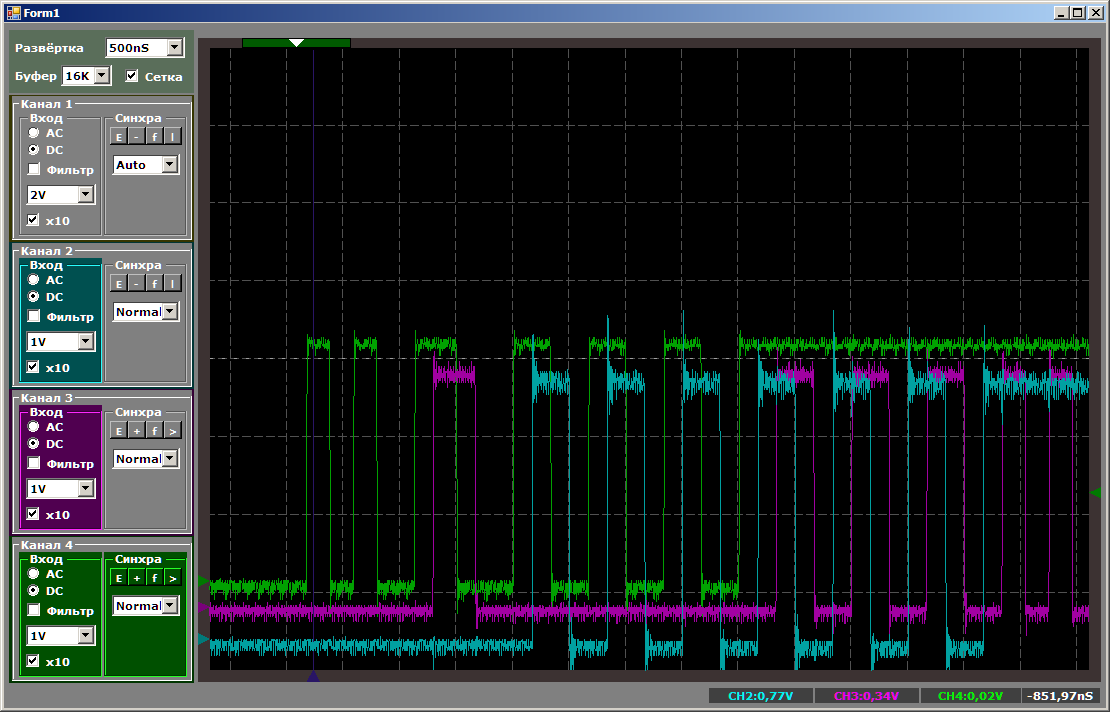
En total, vemos que incluso jugando en prioridades, STM32F103 no puede lanzar más de dos hilos en un bloque DMA. En principio, el tercer hilo se puede ejecutar en el núcleo del procesador. Esto nos permitirá comparar el rendimiento.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Primero, la imagen general, que muestra que todo funciona en paralelo y que el núcleo del procesador tiene la velocidad de copia más alta:
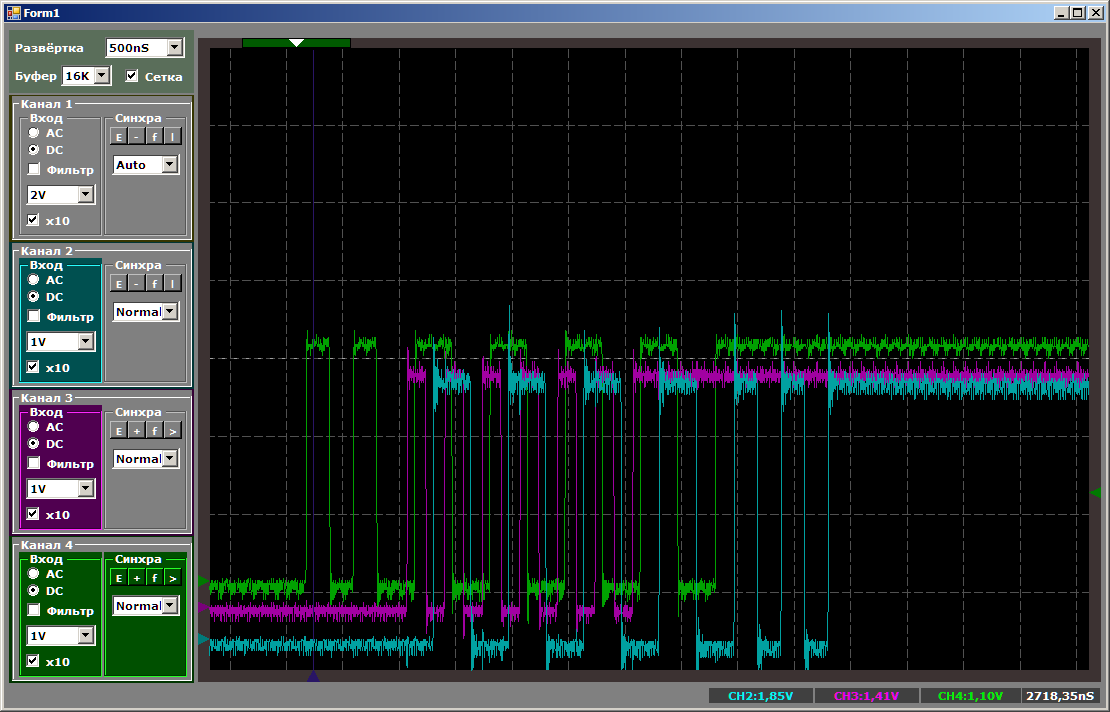
Y ahora les daré a todos la oportunidad de contar las medidas en un momento en que todas las secuencias de copia estén activas:
El núcleo del procesador prioriza todos
Ahora volvamos al hecho de que durante la operación de dos subprocesos, mientras el segundo canal estaba sintonizado, el primero proporcionó datos para un número diferente de ciclos de reloj. Este hecho también está bien documentado en AppNote en DMA. El hecho es que durante la configuración del segundo canal, las solicitudes a RAM se enviaban periódicamente, y el núcleo del procesador tiene mayor prioridad al acceder a la RAM que el núcleo DMA. Cuando el procesador solicitó algunos datos, DMA eliminó los ciclos de reloj, recibió datos con un retraso, por lo tanto, se copió más lentamente. Hagamos el último experimento de hoy. Llevemos el trabajo a uno más real. Después de iniciar DMA, no entraremos en un ciclo vacío (cuando definitivamente no hay acceso a RAM), sino que realizaremos una operación de copia de RAM a RAM, pero esta operación no estará relacionada con la operación de los núcleos de DMA:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

En algunos lugares, el ciclo se extendió de 16 a 17 medidas. Tenía miedo de que fuera peor.
Comienza a sacar conclusiones
En realidad, pasamos a lo que quería decir.
Comenzaré desde lejos. Hace unos años, comenzando a estudiar STM32, estudié las versiones de MiddleWare para USB que existían en ese momento y me pregunté por qué los desarrolladores eliminaron la transferencia de datos a través de DMA. Era evidente que inicialmente tal opción estaba a la vista, luego fue llevada a los patios traseros, y al final solo quedaban rudimentos. Ahora estoy empezando a sospechar que entiendo a los desarrolladores.
En el
primer artículo sobre UDB, dije que aunque UDB puede trabajar con datos paralelos, es poco probable que pueda reemplazar GPIF consigo mismo, ya que el bus USB PSoC funciona a velocidad máxima versus alta velocidad para FX2LP. Resulta que hay un factor limitante más serio. DMA simplemente no tiene tiempo para entregar datos a la misma velocidad que GPIF, incluso dentro del controlador, sin tener en cuenta el bus USB.
Como puede ver, no hay una sola entidad DMA. En primer lugar, cada fabricante lo hace a su manera. No solo eso, incluso un fabricante para diferentes familias puede variar el enfoque para construir DMA. Si planea cargar seriamente esta unidad, debe considerar cuidadosamente si se satisfarán las necesidades.
Probablemente, es necesario diluir el flujo pesimista con un comentario optimista. Incluso la destacaré.
Los controladores DMA de Cortex M le permiten aumentar el rendimiento del sistema según el principio de las famosas jabalinas: "Lanzar y olvidar". Sí, el software que copia datos es un poco más rápido. Pero si necesita copiar varios subprocesos, ningún optimizador puede hacer que el procesador los controle a todos sin la sobrecarga de la recarga del registro y los bucles giratorios. Además, para puertos lentos, el procesador aún debe esperar la disponibilidad, y DMA lo hace a nivel de hardware.Pero incluso aquí son posibles varios matices. Si el puerto es relativamente lento ... Bueno, digamos, un SPI que funciona a la frecuencia más alta posible, entonces hay situaciones teóricamente posibles cuando el DMA no tiene tiempo para recopilar datos del búfer y se produce un desbordamiento. O viceversa: coloque los datos en el registro del búfer. Cuando el flujo de datos es único, es poco probable que esto suceda, pero cuando hay muchos de ellos, vimos qué superposiciones sorprendentes pueden ocurrir. Para lidiar con esto, debe desarrollar tareas no por separado, sino en combinación. Y los probadores intentan provocar tales problemas (un trabajo tan destructivo para los probadores).
Una vez más, nadie oculta estos datos. Pero por alguna razón, todo esto generalmente no está contenido en el documento principal, sino en las Notas de aplicación. Entonces, mi tarea era llamar la atención de los programadores sobre el hecho de que DMA no es una panacea, sino solo una herramienta conveniente.
Pero, por supuesto, no solo los programadores, sino también los desarrolladores de hardware. Digamos que, en nuestra organización, se está desarrollando un gran complejo de software y hardware para la depuración remota de sistemas integrados. La idea es que alguien está desarrollando un dispositivo, pero quiere pedir el "firmware" en el lateral. Y por alguna razón, no puede proporcionar equipos a un lado. Puede ser voluminoso, puede ser costoso, puede ser único y "necesitarlo usted mismo", diferentes grupos pueden trabajar con él en diferentes zonas horarias, proporcionando una especie de trabajo de varios turnos, siempre se lo puede recordar ... En general, puede encontrar razones mucho, nuestro grupo simplemente defraudó esta tarea.
En consecuencia, el complejo de depuración debe poder simular tantos dispositivos externos como sea posible, desde la simulación trivial de presionar botones hasta varios protocolos SPI, I2C, CAN, 4-20 mA y otras cosas más, de modo que a través de ellos los emuladores puedan recrear diferentes comportamientos externos bloques conectados al equipo que se está desarrollando (personalmente, en un momento realicé muchos simuladores para la depuración en tierra de accesorios para helicópteros, en nuestro
sitio web se buscan los casos correspondientes con la palabra Cassel Aero ).
Y así, en los requisitos técnicos para el desarrollo de ciertos requisitos. Tanto SPI, tanto I2C, tanto GPIO. Deben operar a frecuencias tan extremas. Todo parece estar claro. Ponemos STM32F4 y ULPI para trabajar con USB en modo HS. La tecnología está probada. Pero aquí llega un largo fin de semana con las vacaciones de noviembre, que descubrí con UDB. Al ver que algo estaba mal, por las noches obtuve los resultados prácticos que se dan al comienzo de este artículo. Y me di cuenta de que todo, por supuesto, es genial, pero no para este proyecto. Como ya señalé, cuando el posible rendimiento máximo del sistema se acerca al límite superior, todo debe diseñarse no por separado, sino en un complejo.
Pero aquí el diseño integrado de tareas no puede ser en principio. , — . . , FTDI. -- , USB . Por desgracia DMA. , , , , – , .
. DMA (, 10: 1 , , 1 , 10 ) .