Me gustaría compartir mi historia sobre la aplicación de monolitos de migración en microservicios. Por favor, tenga en cuenta que fue durante 2012 - 2014. Es la transcripción de mi presentación en dotnetconf (RU) . Voy a compartir una historia sobre cómo cambiar cada parte de la infraestructura.
Descripción del proyecto

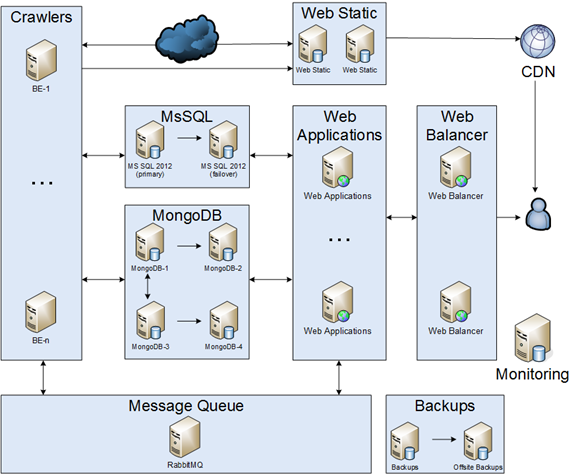
La idea principal del proyecto era rastrear artículos de Internet, analizarlos, guardar y crear feed de usuarios. Por un lado, nuestra infraestructura tenía que ser confiable, pero por otro lado, teníamos un presupuesto limitado. Como resultado, acordamos que:
- Se permite la degradación del rendimiento del sistema.
- Algunas partes de nuestra infraestructura pueden estar inactivas durante 30 minutos.
- En caso de desastre, el tiempo de inactividad puede ser de algunos días.
Rastreadores
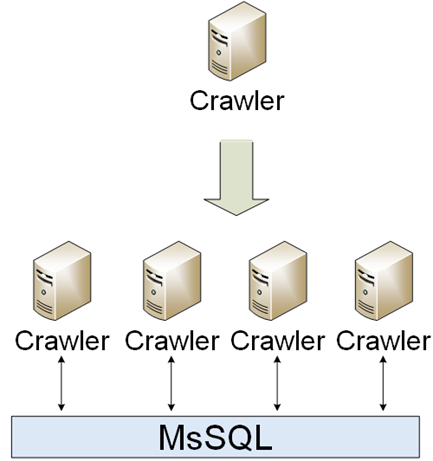
Era una parte simple de la infraestructura. Los rastreadores deben descargar, analizar y guardar. La primera implementación fue un solo rastreador, sin embargo, el mundo estaba cambiando y aparecieron muchos rastreadores diferentes. Los rastreadores se comunicaban entre sí mediante MsSQL.
El tiempo de inactividad no fue un problema para los rastreadores, por lo que fue muy fácil escalarlos:
- Automatizar provisión.
- Agregar métricas de negocios.
- Recoge errores.
Msql
Nuestra base de datos era de aproximadamente 1 TB.
Clúster MsSQL
Había diferentes formas de crear un clúster:
- SQL reflejado.
- Clúster de conmutación por error de Windows: no fue un caso porque no había san / Nas.
- AlwaysOn: era completamente nuevo para nosotros y no tenía experiencia, por lo que no era un caso para nosotros.
Como resultado, decidimos usar el 1er. Me gustaría notar que no usamos testigos debido al modo asíncrono, por lo que creamos scripts para el cambio automático maestro -> esclavo y esclavo manual -> maestro.
Rendimiento MsSQL

El reloj avanzaba, una actuación degradante, estábamos buscando cuellos de botella. A veces, no fue fácil, es decir, estábamos optimizando las consultas SQL por disco io, cuando descubrimos que el rendimiento era bajo debido a la falta de RAM. Sin embargo, no fue suficiente, como solución temporal, migramos de HDD a SSD. Por un lado, aumentó drásticamente el rendimiento, pero por otro lado, no fue una solución a largo plazo.
Cola de mensajes
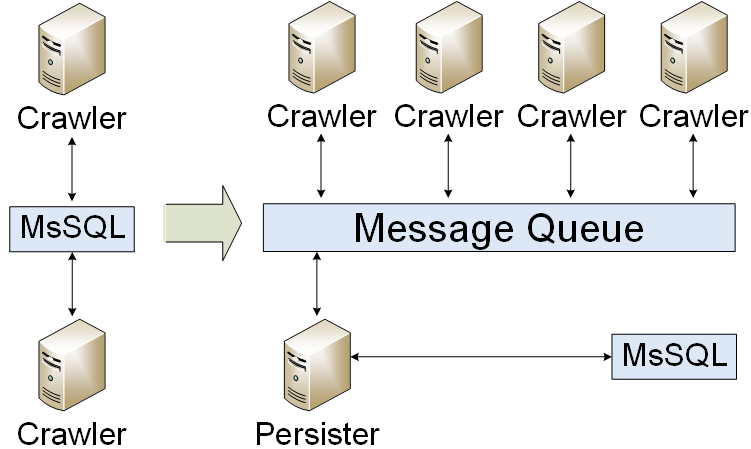
Nuestra aplicación había sido migrada a una cola de mensajes. Solo escribíamos resultados en la base de datos. Como resultado, redujimos la carga de la base de datos. Pero nos enfrentamos a un problema: ¿cómo organizar un clúster de colas de mensajes? Al principio, creamos un modo de espera frío.
WEB

Un elemento web constaba de dos partes: contenido estático y contenido dinámico del usuario.
WEB estática

La parte WEB estática de la infraestructura era de aproximadamente 2 TB, tenía que:
- Almacenar imágenes.
- Convierte imágenes.
- Arrastre la imagen de origen y recorte si es necesario.

Hubo 2 problemas principales: cómo sincronizar archivos y cómo crear un clúster web. Había algunas formas de sincronizar archivos: comprar un almacenamiento, usar DFS y guardar archivos en cada servidor. Fue una decisión difícil, sin embargo, decidimos elegir la tercera forma. Para el clúster web, decidimos usar NLB y CDN.
Balanceador WEB

No es una buena idea usar un solo servidor para un proyecto de alta carga, de alguna manera debe equilibrar el tráfico. Había 4 formas en nuestro caso:
- Equilibrador de hardware: era demasiado costoso para nosotros.
- IIS y ARR: era demasiado complicado de soportar.
- Nginx: fue lo suficientemente bueno, sin embargo, enfrentamos algunos problemas con los controles de salud.
- Haproxy: era una solución con uno de los gastos generales más pequeños.
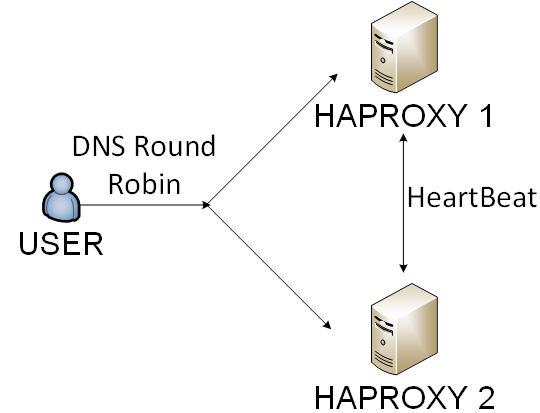
Elegimos el cuarto camino. Estábamos equilibrando haproxy por DNS round robin y usuarios por cookie.
Mongodb

Unos meses más tarde, nos enfrentamos a que el rendimiento de SQL no era lo suficientemente bueno nuevamente. Era un tema sofisticado, sin embargo, después de largas conversaciones, decidimos elegir Disponibilidad y tolerancia de partición del teorema CAP . Como resultado, implementamos un clúster MongoDB (fragmentación y réplica). Hubo una experiencia interesante: cómo crear una copia de seguridad de MongoDB, cómo actualizar y muchos errores de MongoDB.
Copias de seguridad y monitoreo
Implementamos la regla 3-2-1:
- Al menos 3 copias.
- Al menos 2 tipos de almacenamiento diferentes.
- Al menos 1 copia debe almacenarse en algún lugar fuera.
Además, creamos y probamos un plan de recuperación ante desastres. Puedes leer sobre monitoreo aquí .
Actualizaciones de aplicaciones
Como puede ver, la infraestructura no era tan fácil como el pastel. Tuvimos que actualizarlo de alguna manera. La actualización casual se parecía a:
- Haz algo de preparación.
- Corrió la migración.
- Actualización de aplicaciones web.
- Actualización de aplicaciones de back-end.
Todos los pasos lógicos fueron idénticos para los entornos de puesta en escena / preprod / producciones, sin embargo, fue ligeramente diferente en los detalles. Entonces, creamos scripts de PowerShell con magia OOP. Fue un proceso continuo de mejora de nuestra infraestructura de CI / CD.
Conclusión
| 2012 | 2014 |
|---|
| Servidores | 3 | 60 60 |
| RAM GB | 72 | 800 |
| SSD GB | 200 | 10,000 |
| MsSQL gb | 150 | 700 |
| MongoDB GB | 0 0 | 700 |
| Artículos por día | 10,000 | 150,000 |
Fue una historia increíble sobre cómo mover 3 PC de escritorio a una infraestructura confiable. Sé paciente y haz planes.
PS