Breve conocimiento de kubernetes para desarrolladores mediante el ejemplo de implementar un sitio de plantilla simple, configurarlo para monitoreo, realizar trabajos programados y verificaciones de estado (se adjuntan todos los códigos fuente)
-
Instalar Kubernetes-
Instalar interfaz de usuario-
Inicie su aplicación en el clúster-
Agregar métricas personalizadas a la aplicación-
Colección de métricas a través de Prometeo-
Mostrar métricas en Grafana-
Tareas programadas-
Tolerancia a fallos-
Conclusiones-
Notas-
referenciasInstalar Kubernetes
no apto para usuarios de Linux, debes usar minikube- ¿Tiene un escritorio acoplable?
- En él, debe buscar y habilitar el clúster de nodo único de Kubernetes
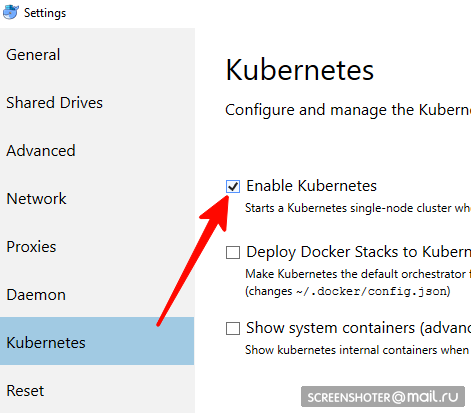
- Ahora tiene api http: // localhost: 8001 / para trabajar con kubernetis
- La comunicación con él ocurre a través de una conveniente utilidad kubectl
Verifique su versión con el comando> kubectl version
Lo último relevante está escrito aquí https://storage.googleapis.com/kubernetes-release/release/stable.txt
Puede descargarlo en el enlace apropiado https://storage.googleapis.com/kubernetes-release/release/v1.13.2/bin/windows/amd64/kubectl.exe kubectl cluster-info que el clúster funcione> kubectl cluster-info
Instalación de la interfaz de usuario
- La interfaz se implementa en el mismo clúster.
kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
- Obtenga un token para acceder a la interfaz
kubectl describe secret
Y copia
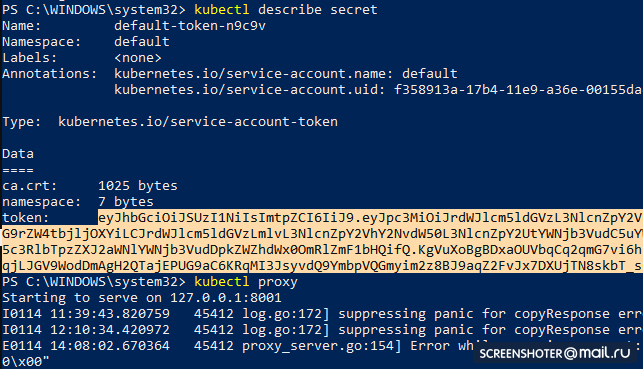
- Ahora inicia el proxy
kubectl proxy
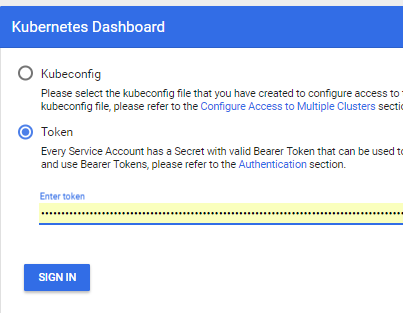
- Y puede usar http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy /
Ejecutando su aplicación en un clúster
- Hice una aplicación estándar mvc netcoreapp2.1 a través del estudio https://github.com/SanSYS/kuberfirst
- Dockerfile:
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base WORKDIR /app EXPOSE 80 FROM microsoft/dotnet:2.1-sdk AS build WORKDIR /src COPY ./MetricsDemo.csproj . RUN ls RUN dotnet restore "MetricsDemo.csproj" COPY . . RUN dotnet build "MetricsDemo.csproj" -c Release -o /app FROM build AS publish RUN dotnet publish "MetricsDemo.csproj" -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MetricsDemo.dll"]
- Reuní esto con la etiqueta metricsdemo3
docker build -t metricsdemo3 .
- Pero! Coober por defecto extrae imágenes del hub, así que levanto el registro local
- nota: no intenté ejecutar en kubernetis
docker create -p 5000:5000 --restart always --name registry registry:2
- Y lo prescribo como inseguro autorizado:
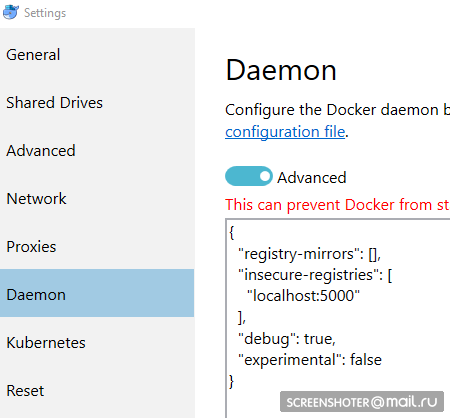
{ "registry-mirrors": [], "insecure-registries": [ "localhost:5000" ], "debug": true, "experimental": false }
- Antes de ingresar al registro un par de gestos más
docker start registry docker tag metricsdemo3 localhost:5000/sansys/metricsdemo3 docker push localhost:5000/sansys/metricsdemo3
- Se verá más o menos así:

Lanzamiento a través de la interfaz de usuario
Si comienza, entonces todo está bien y puede comenzar a operar
Crear un archivo de implementación
1-implementación-app.yaml kind: Deployment apiVersion: apps/v1 metadata: name: metricsdemo labels: app: web spec: replicas: 2
Pequeña descripción
- Tipo: indica qué tipo de entidad se describe a través del archivo yaml
- apiVersion: a qué api se transfiere el objeto
- etiquetas: esencialmente solo etiquetas (las teclas de la izquierda y los valores pueden ser pensados por usted mismo)
- selector: le permite asociar servicios con la implementación, por ejemplo, a través de etiquetas
Siguiente:
kubectl create -f .\1-deployment-app.yaml
Y debería ver su implementación en la interfaz
http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy / #! / Deployment? Namespace = defaultDentro de la cual hay un conjunto de réplica, que muestra que la aplicación se está ejecutando en dos instancias (Pods) y hay un servicio relacionado con una dirección desde el exterior para abrir una aplicación doblada en el navegador
Agregar métricas personalizadas a la aplicación
Se agregó el paquete
https://www.app-metrics.io/ a la aplicación
No describiré en detalle cómo los agregaré, por ahora brevemente: registro el middleware para incrementar los contadores de llamadas a los métodos de la API
Aquí está el middleware private static void AutoDiscoverRoutes(HttpContext context) { if (context.Request.Path.Value == "/favicon.ico") return; List<string> keys = new List<string>(); List<string> vals = new List<string>(); var routeData = context.GetRouteData(); if (routeData != null) { keys.AddRange(routeData.Values.Keys); vals.AddRange(routeData.Values.Values.Select(p => p.ToString())); } keys.Add("method"); vals.Add(context.Request.Method); keys.Add("response"); vals.Add(context.Response.StatusCode.ToString()); keys.Add("url"); vals.Add(context.Request.Path.Value); Program.Metrics.Measure.Counter.Increment(new CounterOptions { Name = "api",
Y las métricas recopiladas están disponibles en
http: // localhost: 9376 / metrics
* IMetricRoot o su abstracción pueden registrarse fácilmente en los servicios y utilizarse en la aplicación (
services.AddMetrics (Program.Metrics); )
Colección de métricas a través de Prometeo
La configuración más básica de prometheus: agregue un nuevo trabajo a su configuración (prometheus.yml) y alimente un nuevo objetivo:
global: scrape_interval: 15s evaluation_interval: 15s rule_files:
Pero prometheus tiene soporte nativo para recopilar métricas de kubernetis
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_configQuiero monitorear cada servicio filtrando individualmente por tipo de aplicación: etiqueta comercial
Habiéndose familiarizado con el muelle, el trabajo es el siguiente:
- job_name: business-metrics
En kubernetis hay un lugar especial para almacenar archivos de configuración:
ConfigMapGuardo esta configuración allí:
2-prometheus-configmap.yaml apiVersion: v1 kind: ConfigMap
Salida hacia kubernetis.
kubectl create -f .\2-prometheus-configmap.yaml
Ahora necesita implementar prometheus con este archivo de configuración
kubectl create -f. \ 3-implementación-prometheus.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: prometheus namespace: default spec: replicas: 1 template: metadata: labels: app: prometheus-server spec: containers: - name: prometheus image: prom/prometheus args: - "--config.file=/etc/config/prometheus.yml" - "--web.enable-lifecycle" ports: - containerPort: 9090 volumeMounts: - name: prometheus-config-volume
Presta atención: el archivo prometheus.yml no se especifica en ningún lado
Todos los archivos que se especificaron en el mapa de configuración se convierten en archivos en la sección prometheus-config-volume, que está montada en el directorio / etc / config /
Además, el contenedor tiene argumentos de inicio con la ruta a la configuración
--web.enable-lifecycle - dice que puede extraer POST / - / reload, que aplicará nuevas configuraciones (útil si la configuración cambia "sobre la marcha" y no desea reiniciar el contenedor)
Despliegue real
kubectl create -f .\3-deployment-prometheus.yaml
Siga los pequeños pasos y vaya a la dirección
http: // localhost: 9090 / targets , debería ver los puntos finales de su servicio allí
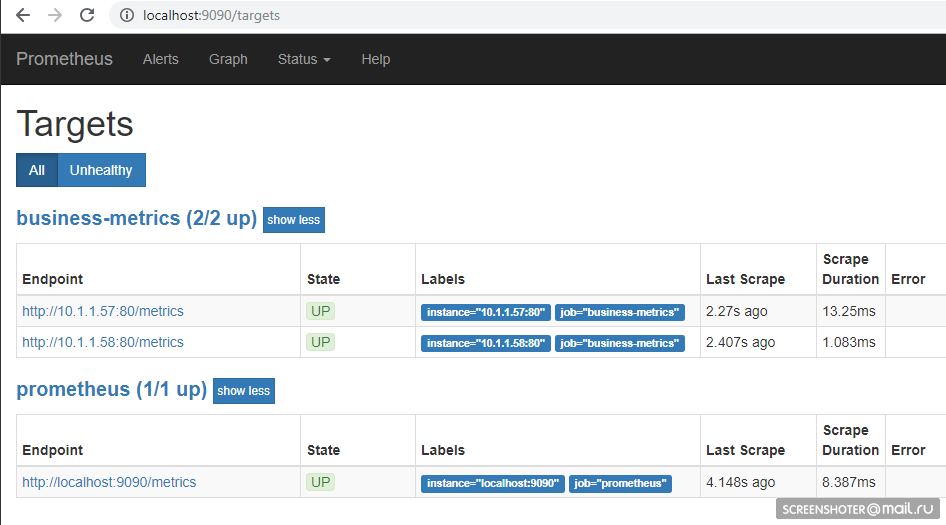
Y en la página principal puedes escribir solicitudes al prometeo
sum by (response, action, url, app) (delta(application_api[15s]))
Siempre que alguien visitara el sitio, resultará así Idioma de consulta:
https://prometheus.io/docs/prometheus/latest/querying/basics/Mostrar métricas en Grafana
Tuvimos suerte: hasta la versión 5, las configuraciones del tablero solo podían deslizarse a través de la API HTTP, pero ahora puedes hacer el mismo truco que con Prometeus
Grafana por defecto en el inicio
puede abrir configuraciones de fuente de datos y paneles
/etc/grafana/provisioning/datasources/ - configuraciones de origen (configuraciones para el acceso a prometeus, postgres, zabbiks, elástico, etc.)/etc/grafana/provisioning/dashboards/ - configuración de acceso al /etc/grafana/provisioning/dashboards//var/lib/grafana/dashboards/ - aquí almacenaré los paneles en forma de archivos json
Resultó así apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-datasources namespace: default data: all.yml: | datasources: - name: 'Prometheus' type: 'prometheus' access: 'proxy' org_id: 1 url: 'http://prometheus:9090' is_default: true version: 1 editable: true --- apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-dashboards namespace: default data: all.yml: | apiVersion: 1 providers: - name: 'default' orgId: 1 folder: '' type: file disableDeletion: false updateIntervalSeconds: 10
Despliegue en sí, nada nuevo apiVersion: extensions/v1beta1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana component: core spec: replicas: 1 template: metadata: labels: app: grafana component: core spec: containers: - image: grafana/grafana name: grafana imagePullPolicy: IfNotPresent resources: limits: cpu: 100m memory: 100Mi requests: cpu: 100m memory: 100Mi env: - name: GF_AUTH_BASIC_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin readinessProbe: httpGet: path: /login port: 3000
Expandir
kubectl create -f .\4-grafana-configmap.yaml kubectl create -f .\5-deployment-grafana.yaml
Recuerde que el grafano no se eleva inmediatamente, está un poco amortiguado por las migraciones de sqlite, que puede
ver en los registrosAhora vaya a
http: // localhost: 3000 /Y haz clic en el tablero
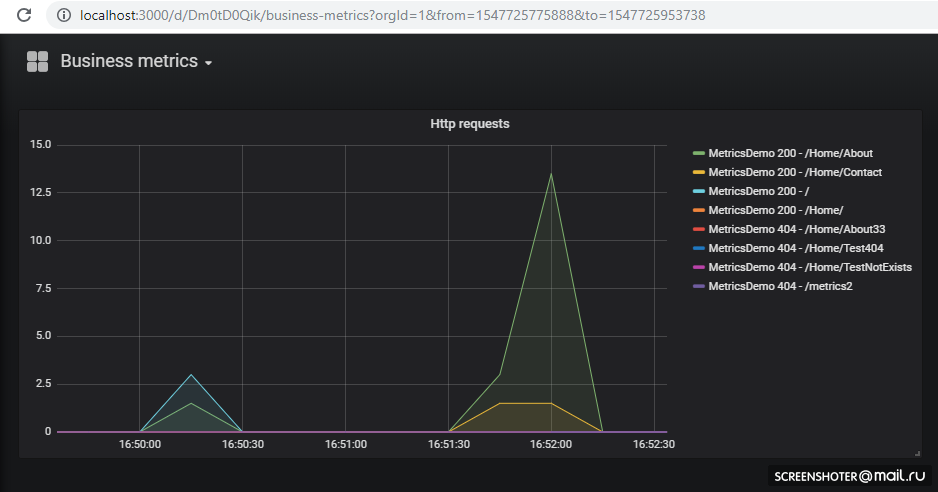
Si desea agregar una nueva vista o cambiar una existente, cámbiela directamente en la interfaz y luego haga clic en Guardar, obtendrá una ventana modal con json, que debe colocar en el mapa de configuración
Todo se implementa y funciona muy bien. Tareas programadas
Para realizar tareas en la corona en el cubo, existe el concepto de CronJob
Con CronJob, puede establecer un horario para cualquier tarea, el ejemplo más simple:
La sección de programación establece la regla clásica para la corona.
El desencadenador inicia el pod del contenedor (busybox) en el que extraigo el método de la API del servicio metricsdemo
Puede usar el comando para rastrear el trabajo.
kubectl.exe get cronjob runapijob --watch
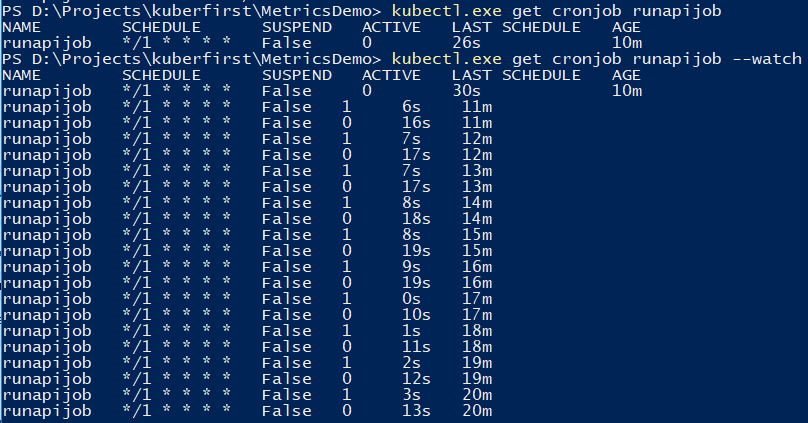
El servicio principal que se sacude del trabajo se inicia en varios casos, porque la llamada al servicio se dirige a uno de los hogares con una extensión aproximadamente uniforme.
Para depurar el trabajo, puede disparar manualmente Una pequeña demostración sobre el ejemplo de cálculo de la cantidad de π, sobre la diferencia en los lanzamientos desde la consola
Tolerancia a fallos
Si la aplicación finaliza inesperadamente, el clúster reinicia el pod
Por ejemplo, hice un método que deja caer la API
[HttpGet("kill/me")] public async void Kill() { throw new Exception("Selfkill"); }
* La excepción que se produjo en la API en el método de vacío asíncrono se considera una excepción no controlada, que bloquea completamente la aplicaciónApelo a
http: // localhost: 9376 / api / job / kill / meLa lista de hogares muestra que uno de los hogares del servicio se ha reiniciado.
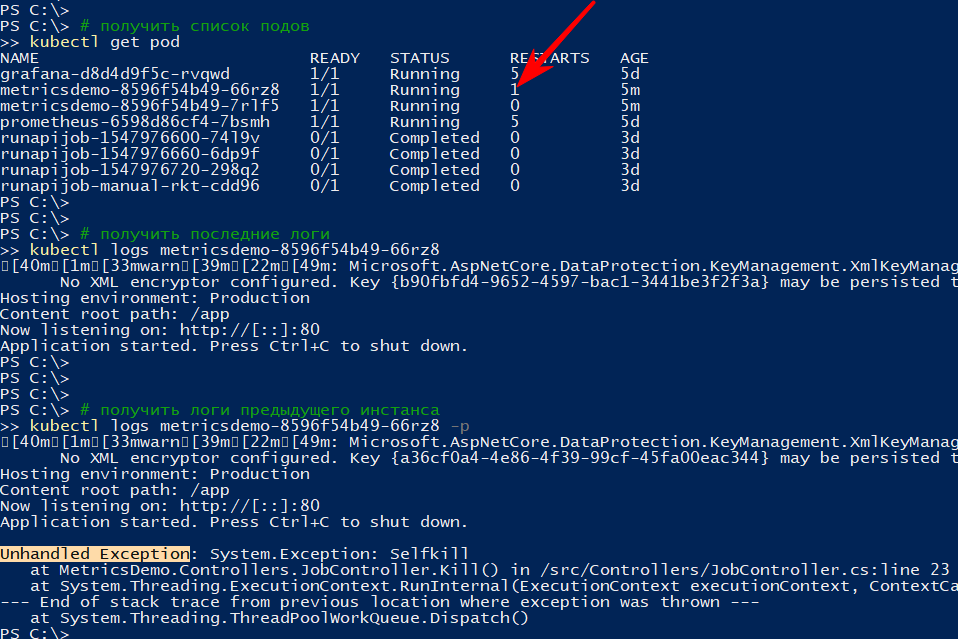
El comando logs muestra la salida actual, y con la opción -p mostrará los registros de la instancia anterior. De esta manera, puede averiguar el motivo del reinicio.
Creo que con una simple caída, todo está claro: cayó - rosa
Pero la aplicación puede ser condicionalmente activa, es decir no caído, pero no haciendo nada, o haciendo su trabajo, pero lentamente
Según la
documentación, existen al menos dos tipos de comprobaciones de "supervivencia" de las aplicaciones en pods
- preparación: este tipo de verificación se utiliza para comprender si es posible iniciar el tráfico en este pod. Si no, la cápsula se desregula hasta que vuelve a la normalidad.
- vitalidad - verifique la aplicación "para sobrevivir". En particular, si no hay acceso a un recurso vital o si la aplicación no responde (por ejemplo, un punto muerto y, por lo tanto, un tiempo de espera), el contenedor se reiniciará. Todos los códigos http entre 200 y 400 se consideran exitosos, el resto son fallidos
Comprobaré el reinicio por tiempo de espera, para esto agregaré un nuevo método de API, que de acuerdo con cierto comando comenzará a ralentizar el método de verificación de supervivencia durante 123 segundos
static bool deadlock; [HttpGet("alive/{cmd}")] public string Kill(string cmd) { if (cmd == "deadlock") { deadlock = true; return "Deadlocked"; } if (deadlock) Thread.Sleep(123 * 1000); return deadlock ? "Deadlocked!!!" : "Alive"; }
Agrego un par de secciones al archivo 1-implementación-app.yaml en el contenedor:
containers: - name: metricsdemo image: localhost:5000/sansys/metricsdemo3:6 ports: - containerPort: 80 readinessProbe:
Volver a aplicar, estoy seguro de que la aplicación se ha iniciado y suscribirse a eventos
kubectl get events --watch
Presiono el menú Deadlock me (
http: // localhost: 9376 / api / job / alive / deadlock )

Y en cinco segundos empiezo a observar el problema y su solución.
1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Readiness probe failed: Get http://10.1.0.137:80/health: dial tcp 10.1.0.137:80: connect: connection refused 0s Normal Killing Pod Killing container with id docker://metricsdemo:Container failed liveness probe.. Container will be killed and recreated. 0s Normal Pulled Pod Container image "localhost:5000/sansys/metricsdemo3:6" already present on machine 0s Normal Created Pod Created container 0s Normal Started Pod Started container
Conclusiones
- Por un lado, el umbral de entrada resultó ser mucho más bajo de lo que pensaba, por otro lado, no es un verdadero grupo de kubernetes, sino solo la computadora de un desarrollador. Y no se consideraron los límites de recursos, aplicaciones con estado, pruebas a / b, etc.
- Prometeus lo intentó por primera vez, pero al leer varios documentos y ejemplos durante la revisión del cubo dejó en claro que es muy bueno para recopilar métricas del clúster y las aplicaciones.
- Es tan bueno que permite que el desarrollador implemente una función en su computadora y adjunte, además de la información a la implementación, la implementación del cronograma al graphan. Como resultado, nuevas métricas automáticamente sin adicional. los esfuerzos comenzarán a mostrarse en el escenario y en la producción. Conveniente
Notas
- Las aplicaciones pueden contactarse entre sí por el
: , que es lo que se hizo con grafana → prometeus. Para aquellos familiarizados con Docker-compose, no hay nada nuevo kubectl create -f file.yml - crea una entidadkubectl delete -f file.yml - elimina una entidadkubectl get pod : obtenga una lista de todos los hogares (servicio, puntos finales ...)--namespace=kube-system - filtrado por espacio de nombres-n kube-system - de manera similar
kubectl -it exec grafana-d8d4d9f5c-cvnkh -- /bin/bash - accesorio en la parte inferiorkubectl delete service grafana : elimina un servicio, pod. despliegue (--todos - eliminar todo)kubectl describe : describe la entidad (puede hacerlo todo de una vez)kubectl edit service metricsdemo : edite todos los yamls sobre la marcha mediante el lanzamiento del bloc de notaskubectl --help - gran ayuda)- Un problema típico es que hay un pod (considere la imagen en ejecución), algo salió mal y no hay opciones, excepto que no hay forma de depurar el interior (a través de tcpdump / nc, etc.). - Yuzai kubectl-debug habr.com/en/company/flant/blog/436112
Referencias
- ¿Qué son las métricas de la aplicación?
- Kubernetes
- Prometeo
- Configuración de grafana preparada previamente
- Para ver cómo lo hacen las personas (pero ya hay algunas cosas desactualizadas), allí, en principio, también se trata de registros, alertas, etc.
- Helm : el administrador de paquetes de Kubernetes; a través de él fue más fácil organizar prometeus + grafana, pero manualmente, aparece una mayor comprensión
- Cubos para Prometeo de Coober
- Historias de fracaso de Kubernetes
- Kubernetes-HA. Implemente el clúster de conmutación por error de Kubernetes con 5 asistentes
 Código fuente y atascos disponibles en github
Código fuente y atascos disponibles en github