
Mi nombre es Elena Rastorgueva, soy responsable del producto Factor en
HFLabs . El Factor es una empresa algorítmica muy compleja; procesa datos a escala industrial.
En el artículo, le contaré cómo comenzamos a probar el "Factor", cómo se desarrollaron las pruebas automáticas y por qué llegamos a los marcos autoescritos.
¿Qué tipo de producto es este?
"Factor" limpia datos en bases de datos con millones de clientes: elimina errores tipográficos en el nombre, teléfono y correo electrónico, revisa pasaportes, hace mucho más. Lo más difícil es corregir las direcciones de correo.
 Las direcciones se escriben de cientos de maneras, por lo que el Factor tiene un fuerte aparato algorítmico bajo el capó
Las direcciones se escriben de cientos de maneras, por lo que el Factor tiene un fuerte aparato algorítmico bajo el capó"Factor" funciona como un servicio: datos de entrada - datos de salida.
Este es un sistema sin estado donde cada llamada es independiente de las anteriores. Sin estado simplifica enormemente la vida del probador. Es mucho más difícil probar un sistema con estado cuando una secuencia de acciones es importante.
El producto debe ser confiable como ISS, ya que es utilizado por bancos, operadores móviles, seguros y minoristas del nivel Lenta. Respondemos por errores con la cabeza en la medida en que la ausencia de errores sea parte del SLA en el contrato con el cliente.
Debido a los requisitos de confiabilidad de las pruebas automáticas, escribimos desde el comienzo del desarrollo. Uno de los criterios para la preparación de la tarea es "Pruebas automáticas agregadas".
Comenzó con comprobaciones manuales y pruebas automáticas
Lanzamos el Factor en 2005 y primero lo probamos con nuestras manos. Por la mañana, el probador realizó pruebas automáticas en un archivo con casos y comparó el resultado del procesamiento de datos con el resultado del día anterior: lo que cambió después de la confirmación del código de ayer.
El proceso podría tomar medio día, esta alineación no fue buena. Por lo tanto, tomamos el conjunto mínimo de pruebas para la funcionalidad clave y las incluimos en pruebas unitarias. Estas pruebas son rápidas, y el desarrollador mismo las ejecutó antes de comprometerse.
Las pruebas unitarias son tan convenientes y tan rápidas que agregamos miles de ellas. Y luego nos topamos con él: cuando las pruebas parecen una hoja de miles de piezas de código, no es fácil incluso desplazarse al lugar correcto. Sin mencionar agregar o actualizar.
 Prueba unitaria para verificar el formato SNILS
Prueba unitaria para verificar el formato SNILSAdemás, algo inesperado aparece repentinamente en los datos industriales que no cubre las pruebas unitarias. Por ejemplo, un nuevo cliente vino con nuevas funciones en las direcciones, las pruebas unitarias no cubren estas funciones. Debe sentarse y ver qué pruebas agregar para obtener nuevos datos. Aún lo hicimos manualmente.
Crea tu propio marco
En las pruebas unitarias tradicionales, los datos y el código se mezclan; es difícil encontrar las partes correctas.
Por lo tanto, probamos las
pruebas automáticas en el paradigma de
Pruebas controladas por
datos (DDT) . DDT es cuando los datos para la prueba se almacenan por separado del código para la prueba.
Los casos se cargaron desde un archivo de Excel, estaban en las columnas "Datos sin procesar" y "Resultado esperado". El DDT fue un gran avance: la actualización de casos en el "exelnik" es inexpresablemente más simple.
Poco a poco, desarrollamos un enfoque y desarrollamos nuestro propio marco de prueba. Recibe archivos de texto como entrada, dentro de ellos están los datos de origen y el resultado esperado.
 Nos negamos a los archivos de Excel como almacenamiento: los archivos de texto se abren más rápido, no cambian los contenidos, es más fácil recolectar datos
Nos negamos a los archivos de Excel como almacenamiento: los archivos de texto se abren más rápido, no cambian los contenidos, es más fácil recolectar datosEl marco es ayudado por herramientas estándar:
- TeamCity ejecuta pruebas automáticamente todas las noches;
- testNG compara los resultados esperados y reales.
 Si el resultado es diferente al esperado, en TeamCity la prueba se sonroja. Si todo está como debería, la prueba es verde
Si el resultado es diferente al esperado, en TeamCity la prueba se sonroja. Si todo está como debería, la prueba es verdeModificó el marco para usted
Han pasado 12 años desde entonces. Durante este tiempo, el marco se ha cubierto de capacidades que no están en las soluciones estándar.
Contabilización del estado de la tarea en Jira. HFLabs se adhiere a
Test Driven Development : primero escribimos una prueba o agregamos casos de prueba para un nuevo comportamiento, y solo luego cambiamos la funcionalidad.
Apagamos nuevos casos comentando la línea. De lo contrario, primero cayeron e interfirieron, porque los casos agregaron características o correcciones de errores antes.
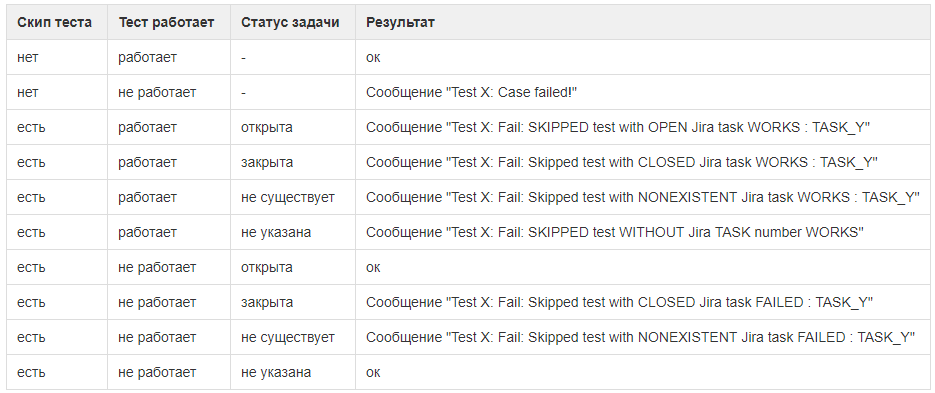
Pero es posible que la tarea no pueda completar el caso de prueba correspondiente: el error resultará ser extremadamente raro o el cliente traerá algo más importante. Algunas tareas se suspendieron durante meses con baja prioridad y se acumularon casos desconectados. Al mismo tiempo, no está claro a qué tarea pertenece cada caso, si este caso se puede eliminar.
Por lo tanto, agregamos un número de tarea a los casos desconectados y arruinamos un poco la automatización. Ahora todo funciona así:
- el caso de prueba se deshabilita al combinarlo con una tarea abierta en Jira;

Para adjuntar un caso a una tarea, escriba delante de él # y número de tarea
- el marco ejecuta pruebas incluso en casos deshabilitados. Pero ignora los bloqueos mientras la tarea está abierta en Jira;
- Tan pronto como se cierra la tarea, la prueba comienza a recaer en los casos adjuntos. Esta es una señal: aprobaron la tarea, pero olvidaron encender los casos;
- Si de repente la prueba para el caso desconectado comenzó a pasar con una tarea abierta, el marco también informará sobre esto. Quizás sea hora de encender el caso o cerrar la tarea adjunta (además de actualizar las notas de la versión e informar a los clientes).

El marco dice que el caso desconectado está pasando. Quizás alguien corrigió el código como parte de otra tarea, y ahora todo funciona
Así que ahorramos TDD y derrotamos el olvido al gestionar casos de prueba.
 Documentamos todas las opciones con el estado de los casos de prueba y tareas relacionadas, para no olvidarActualización de casos de prueba en modo semiautomático.
Documentamos todas las opciones con el estado de los casos de prueba y tareas relacionadas, para no olvidarActualización de casos de prueba en modo semiautomático. Parece que si la prueba falla, busque un error en el código. Pero para nosotros este no es siempre el caso. A veces sucede que los casos de prueba deben actualizarse, porque los requisitos para el resultado han cambiado.
Por ejemplo, antes de que el cliente en la dirección autorizada quisiera "g. Moscú "en un campo. Ahora que ha cambiado la arquitectura de la base de datos, quiere la "ciudad" en un campo, "Moscú" en otro. Es hora de cambiar los casos de prueba.
Para la prueba caída, TeamCity muestra la diferencia entre los resultados esperados y reales. Anteriormente, copiamos esta diferencia y actualizamos los casos de prueba con nuestras manos. Para cambios masivos, un evento muy costoso.
 Un ejemplo vivo: enseñamos "Factor" para determinar un país por número de teléfono, las pruebas en TeamCity cayeron. Se puede tomar un nuevo punto de referencia del resultado real, pero lleva mucho tiempo
Un ejemplo vivo: enseñamos "Factor" para determinar un país por número de teléfono, las pruebas en TeamCity cayeron. Se puede tomar un nuevo punto de referencia del resultado real, pero lleva mucho tiempoHicimos que el marco actualizara el punto de referencia en sí. Para hacer esto, después de ejecutar las pruebas, reemplaza los resultados de limpieza esperados en el estándar con los resultados reales donde no coincidían. El resultado se guarda en artefactos como un archivo de actualización de caso.
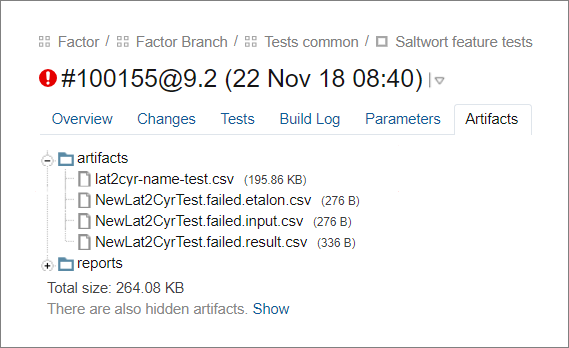 El primer archivo es un nuevo punto de referencia en el que el marco ha actualizado los resultados esperados. Los archivos restantes son los datos de entrada, el estándar anterior y los datos reales de los casos descartados.
El primer archivo es un nuevo punto de referencia en el que el marco ha actualizado los resultados esperados. Los archivos restantes son los datos de entrada, el estándar anterior y los datos reales de los casos descartados.Con el nuevo punto de referencia, el probador actualiza los casos en tres pasos.
- Descargue el archivo generado.
- Comprueba a través de cualquier herramienta de fusión qué cambios hay en el nuevo punto de referencia. Deja solo lo necesario.
- Comprometerse
 El probador verifica si las actualizaciones en el nuevo estándar son correctas y las confirma
El probador verifica si las actualizaciones en el nuevo estándar son correctas y las confirmaSí, si se actualiza sin pensar, nada bueno saldrá de eso. Pero existe el riesgo de una actualización irreflexiva cuando se trabaja manualmente.
Estabilización de datos de prueba con stubs. "Factor" devuelve datos procesados en docenas de campos. Hay un montón de componentes en una sola dirección: índice, región, tipo de región, tipo de ciudad, ciudad, tipo de calle, casa, edificio, edificio, apartamento. Para ellos, el "Factor" atrapa IFTS, OKATO, OKTMO e incluso las pequeñas cosas. Entonces, de una línea en la entrada se obtienen docenas de valores.
No todos los campos del resultado deben verificarse con casos de prueba. Por ejemplo, el reconocimiento de la misma dirección depende directamente del directorio de estado: FIAS. Y en él los campos cambian regularmente, para nuestras tareas son completamente extraños. La actualización de algunos códigos CLADR para casas dejó caer cientos de casos de prueba.
Agregamos talones al resultado esperado cuando nos dimos cuenta de que estábamos perdiendo el tiempo analizando caídas sin importancia.
Cuando no es necesario verificar el campo, el probador escribe un símbolo en el resultado esperado:
$$ DNV $$ . Cuándo debe rellenarse el campo, pero el valor en sí mismo no es importante:
$$ NE $$ .
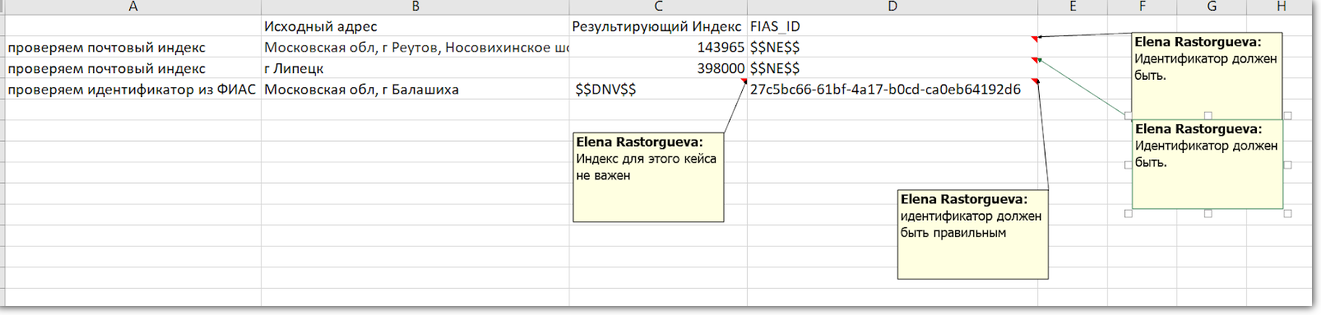 El ID de FIAS siempre está en la dirección, por lo que lo verificamos en todas las pruebas. Si el campo está vacío, algo está mal. Pero el índice puede no ser, por lo tanto, al verificar la ID de FIAS, ignoramos el índice
El ID de FIAS siempre está en la dirección, por lo que lo verificamos en todas las pruebas. Si el campo está vacío, algo está mal. Pero el índice puede no ser, por lo tanto, al verificar la ID de FIAS, ignoramos el índicePodría ir hacia otro lado y separar las pruebas: cada campo tiene el suyo. Pero es difícil, porque no todo puede aislarse. Por ejemplo, "ciudad" y "calle" son partes de una dirección y sin la otra no tienen sentido.
Un marco auto escrito es más conveniente
Por lo tanto, no considero en absoluto crear mi propio marco como una tarea estúpida. Si no hubiéramos creado nuestra propia herramienta, no habríamos recibido tantas oportunidades nuevas y tanta flexibilidad.
Desactivar el caso de texto por estado de la tarea, generar un nuevo punto de referencia y resguardos para el resultado son las cosas que nuestros evaluadores ahora piden en otros marcos. Si tomáramos soluciones estándar, nunca podríamos hacerlo.
Si te gusta hacer cosas complejas en la empresa, ven a nosotros. Ahora estamos buscando un desarrollador de Java , salario de 135 000 ₽ sin impuesto sobre la renta personal.