Continuamos hablando sobre proyectos de investigación conjuntos entre nuestros estudiantes y JetBrains Research. En este artículo, hablaremos sobre algoritmos de aprendizaje profundo de refuerzo que se utilizan para simular el aparato motor humano.
Simular todos los movimientos humanos posibles y describir todos los escenarios de comportamiento es una tarea bastante difícil. Si aprendemos a comprender cómo se mueve una persona y puede reproducir sus movimientos "a imagen y semejanza", esto facilitará en gran medida la introducción de robots en muchas áreas. Solo para que los robots aprendan a repetir y analizar los movimientos, y se aplique el aprendizaje automático.

Sobre mi
Mi nombre es Alexandra Malysheva, me gradué de la licenciatura en Matemática Aplicada y Ciencias de la Computación en la Universidad Académica de San Petersburgo, y desde el otoño de este año, soy un estudiante graduado de primer año en el Programa de HSE de San Petersburgo en Programación y Análisis de Datos. Además, trabajo en el laboratorio de Sistemas de Agentes y Aprendizaje Reforzado, JetBrains Research, y también doy clases - conferencias y prácticas - en el programa de pregrado de St. Petersburg HSE.
En este momento estoy trabajando en varios proyectos en el campo del aprendizaje profundo con refuerzo (comenzamos a hablar de lo que se trata en el artículo anterior). Y hoy quiero mostrar mi primer proyecto, que fluyó sin problemas de mi tesis.
Descripción de la tarea

Para simular el aparato motor humano, se crean entornos especiales que intentan simular el mundo físico con la mayor precisión posible para resolver un problema específico. Por ejemplo, la competencia
NIPS 2017 se centró en crear un robot humanoide que simule el caminar humano.
Para resolver este problema, generalmente se utilizan métodos de aprendizaje profundo con refuerzo, que conducen a una buena estrategia, pero no óptima. Además, en la mayoría de los casos, el tiempo de entrenamiento es demasiado largo.
Como se señaló correctamente en el
artículo anterior , el principal problema en la transición de tareas ficticias / simples a tareas reales / prácticas es que las recompensas en tales problemas suelen ser muy raras. Por ejemplo, podemos evaluar el paso de una larga distancia solo cuando el agente ha llegado a la línea de meta. Para hacer esto, necesita realizar una secuencia de acciones compleja y correcta, lo cual no siempre es el caso. Este problema se puede resolver dando al agente al principio ejemplos de cómo "jugar", las llamadas demostraciones de expertos.
Usé este enfoque para resolver este problema. Resultó mejorar significativamente la calidad del entrenamiento, podemos usar videos que muestran los movimientos de una persona mientras corre. En particular, puede intentar usar las coordenadas del movimiento de partes específicas del cuerpo (por ejemplo, pies) tomadas de un video en YouTube.
El medio ambiente
En las tareas de aprendizaje de refuerzo, se considera la interacción del agente y el entorno. Uno de los entornos modernos para modelar el aparato motor humano es el entorno de simulación OpenSim que utiliza el motor de física Simbody.
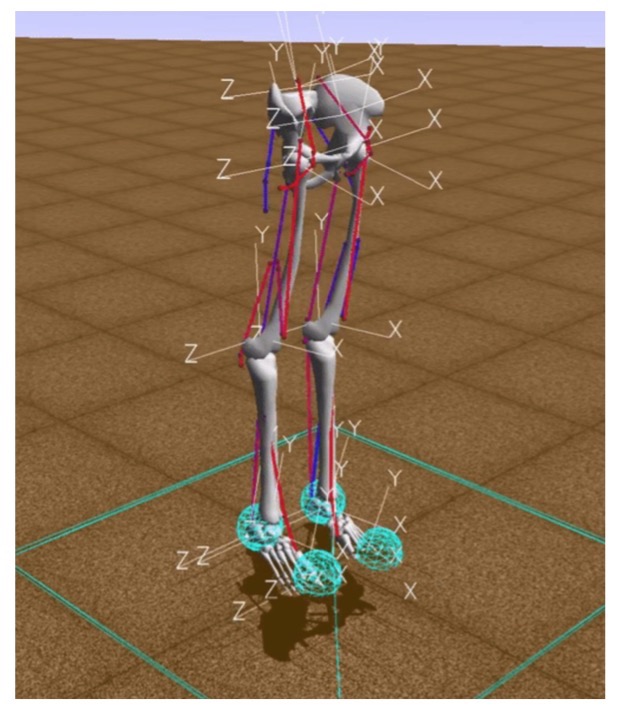
En este entorno, "entorno" es un mundo tridimensional con obstáculos, "agente" es un robot humanoide con seis articulaciones (tobillo, rodillas y caderas en dos piernas) y músculos que simulan el comportamiento muscular humano, y la "acción del agente" es valores reales de 0 a 1, que especifican la tensión de los músculos existentes.
La recompensa se calcula como el cambio en la posición de la pelvis a lo largo del eje x menos la penalización por usar ligamentos. Por lo tanto, por un lado, debe ir lo más lejos posible en un momento determinado y, por otro lado, hacer que sus músculos trabajen lo menos posible. El episodio de entrenamiento finaliza si se logran 1000 iteraciones o si la altura de la pelvis es inferior a 0,65 metros, lo que significa que el modelo de la persona cae.
Implementación base
El objetivo principal del entrenamiento de refuerzo es enseñar al robot a moverse de manera rápida y eficiente en el entorno.
Para probar la hipótesis sobre si el entrenamiento en demostraciones ayuda, fue necesario implementar un algoritmo básico que aprendiera a correr rápido, pero subóptimo, como muchos ejemplos existentes.
Para hacer esto, aplicamos algunos trucos:
- Para empezar, era necesario adaptar el entorno OpenSim para poder utilizar efectivamente los algoritmos de aprendizaje de refuerzo. En particular, en la descripción del entorno, agregamos coordenadas bidimensionales de las posiciones de las partes del cuerpo con respecto a la pelvis.
- Se aumentó el número de ejemplos de pasar la distancia debido a la simetría del medio. En la posición inicial, el agente se para absolutamente simétrico con respecto a los lados izquierdo y derecho del cuerpo. Por lo tanto, después de una distancia, puede agregar dos ejemplos a la vez: el que ocurrió y el espejo simétrico en relación con el lado izquierdo o derecho del cuerpo del agente.
- Para aumentar la velocidad del algoritmo, se omitieron los marcos: el algoritmo para seleccionar la siguiente acción del agente se lanzó solo cada tercera iteración, en otros casos, se repitió la última acción seleccionada. Por lo tanto, el número de iteraciones del lanzamiento del algoritmo de selección de acción del agente se redujo de 1000 a 333, lo que redujo el número de cálculos requeridos.
- Las modificaciones anteriores aceleraron notablemente el aprendizaje, pero el proceso de aprendizaje aún fue lento. Por lo tanto, se implementó adicionalmente un método de aceleración, asociado con una disminución en la precisión de los cálculos: el tipo de valores utilizados en el vector de estado del agente se cambió de doble a flotante.

Este gráfico muestra la mejora después de cada una de las optimizaciones descritas anteriormente, muestra la recompensa recibida por una era desde el momento del entrenamiento.
Entonces, ¿qué tiene que ver YouTube con eso?
Después de desarrollar el modelo base, agregamos la generación de recompensas en función de la función potencial. Se introduce una función potencial para dar al robot información útil sobre el mundo que nos rodea: decimos que algunas posiciones corporales que tomó el personaje que corre en el video son más "rentables" (es decir, recibe una recompensa mayor por ellas) que otras.
Desarrollamos la función sobre la base de datos de video tomados de videos de YouTube que representan el funcionamiento de personas reales y personajes humanos de dibujos animados y juegos de computadora. La función potencial total se definió como la suma de las funciones potenciales para cada parte del cuerpo: la pelvis, dos rodillas y dos pies. Siguiendo el enfoque basado en el potencial para la formación de la remuneración, en cada iteración del algoritmo, el agente recibe una remuneración adicional correspondiente a un cambio en los potenciales del estado anterior y actual. Las funciones potenciales de partes individuales del cuerpo se construyeron usando las distancias inversas entre la coordenada correspondiente de la parte del cuerpo en los datos generados por video y el robot humanoide.
Examinamos tres fuentes de datos:
 Becker Alan. Animating Walk Cycles - 2010
Becker Alan. Animating Walk Cycles - 2010 ProcrastinatorPro. QWOP Speedrun - 2010
ProcrastinatorPro. QWOP Speedrun - 2010 ShvetsovLeonid.HumanSpeedrun - 2015
ShvetsovLeonid.HumanSpeedrun - 2015... y tres funciones de distancia diferentes:
Aquí dx (dy) es la diferencia absoluta entre la coordenada x (y) de las partes del cuerpo correspondientes tomadas de los datos de video y la coordenada x (y) del agente.
Los siguientes son los resultados obtenidos al comparar varias fuentes de datos para una función potencial basada en PF2:

Resultados
Comparación de la productividad entre el nivel base y el enfoque para la formación de la remuneración:

Resultó que la formación de la remuneración acelera significativamente el aprendizaje, alcanzando el doble de velocidad en 12 horas de capacitación. El resultado final después de 24 horas todavía muestra una ventaja significativa del enfoque que utiliza el método de funciones potenciales.
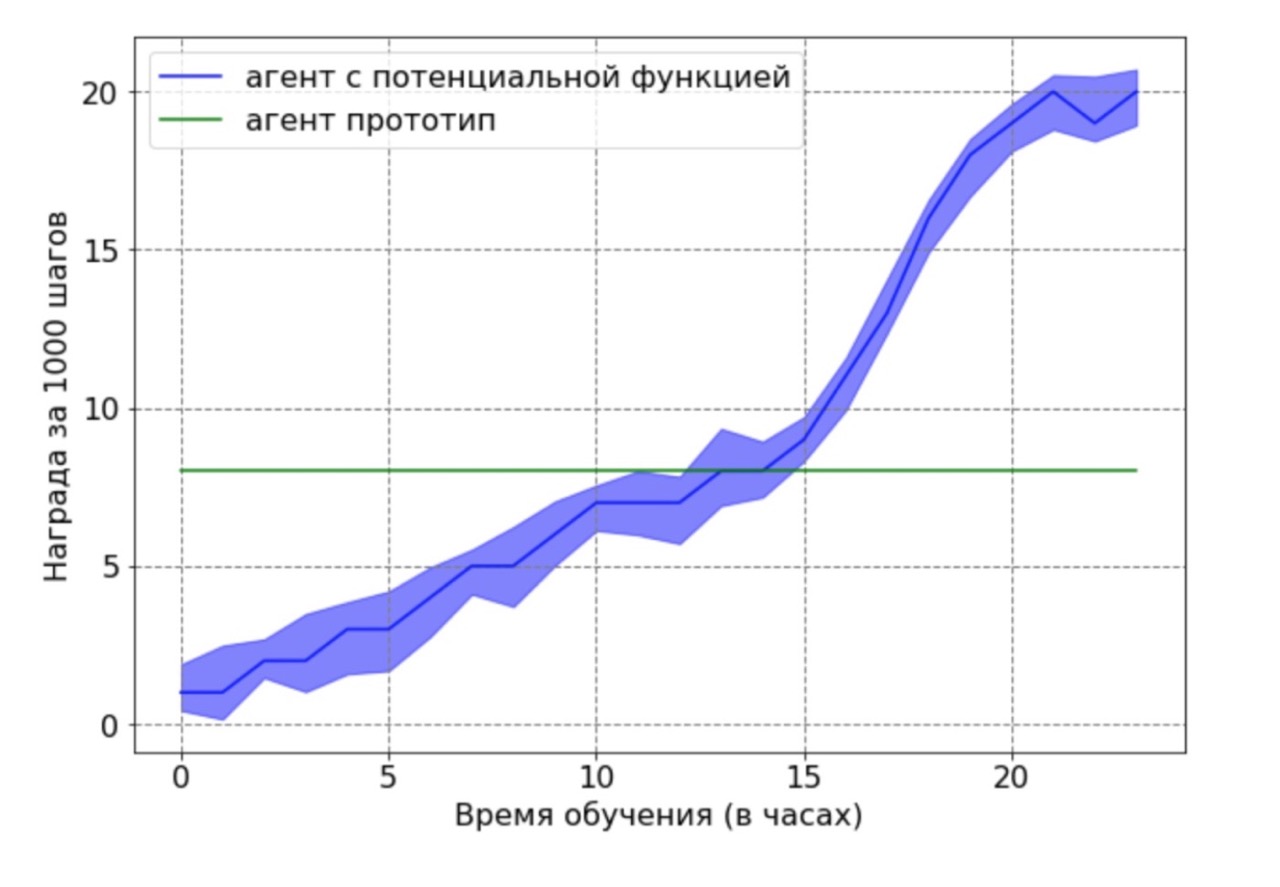
Por separado, quiero señalar el siguiente resultado importante: pudimos demostrar teóricamente que la remuneración basada en una función potencial no empeora una política óptima. Para demostrar esta ventaja en este contexto, utilizamos un agente subóptimo generado por el agente base después de 12 horas de entrenamiento. El prototipo de agente resultante se utilizó como fuente de datos para una función potencial. Obviamente, el agente obtenido con este enfoque no funcionará de manera óptima, y las posiciones de los pies y las rodillas en la mayoría de los casos no estarán en las posiciones óptimas. Luego, el agente entrenado por el algoritmo DDPG usando la función potencial fue entrenado en los datos obtenidos. A continuación, se realizó una comparación de los resultados de aprendizaje de un agente con una función potencial con un agente prototipo. El cronograma de capacitación del agente demuestra que el agente RL puede superar el rendimiento subóptimo de la fuente de datos.
Primeros pasos en la ciencia
Terminé el proyecto de graduación bastante temprano. Me gustaría señalar que tenemos un enfoque muy responsable para proteger un diploma. Desde septiembre, los estudiantes conocen el tema, los criterios de evaluación, qué y cuándo hacer. Cuando todo está tan claro, es muy conveniente trabajar, no hay sensación de "Tengo todo un año por delante, puedo comenzar a hacerlo la próxima semana / mes / seis meses". Como resultado, si trabaja de manera eficiente, puede obtener los resultados finales de la tesis para el Año Nuevo y dedicar el tiempo restante a configurar el modelo, recopilar resultados estadísticamente significativos y escribir el texto del diploma. Eso es exactamente lo que me pasó.
Dos meses antes de que se defendiera el diploma, ya tenía listo el texto del trabajo, y mi asesor científico, Aleksey Aleksandrovich Shpilman, sugirió escribir un artículo sobre
Taller sobre agentes adaptativos y de aprendizaje (ALA) en ICML-AAMAS. Lo único que tenía que hacer era traducir y reempacar mi tesis. Como resultado, enviamos un artículo a la conferencia y ... ¡fue aceptado! Esta fue mi primera publicación y me sentí extremadamente feliz cuando vi una carta con la palabra "Aceptado" en mi correo. Lamentablemente, al mismo tiempo, me formé en Corea del Sur y no pude asistir personalmente a la conferencia.
Además de
publicar y reconocer el trabajo realizado, la primera conferencia me trajo otro resultado agradable. Alexey Alexandrovich comenzó a atraerme para escribir una reseña del trabajo de otras personas. Me parece que esto es muy útil para adquirir experiencia en la evaluación de nuevas ideas: de esta manera puede aprender a analizar el trabajo existente, verificar la originalidad y relevancia de la idea.
Escribir un artículo sobre el taller es bueno, pero en la pista principal es mejor
Después de Corea, obtuve una pasantía en JetBrains Research y continué trabajando en el proyecto. Fue en este punto que probamos tres fórmulas diferentes para una función potencial e hicimos una comparación. Realmente queríamos compartir los resultados de nuestro trabajo, por lo que decidimos escribir un artículo completo en la
conferencia principal de
ICARCV en Singapur.
Escribir un artículo en un taller es bueno, pero en una pista principal es mejor. Y, por supuesto, ¡me alegré mucho cuando descubrí que el artículo fue aceptado! Además, nuestros colegas y patrocinadores de JetBrains acordaron pagar mi viaje a la conferencia. Una gran ventaja fue la oportunidad de familiarizarse con Singapur.
Cuando ya se compraron los boletos, se reservó el hotel y solo pude obtener una visa, recibí una carta por correo:

¡No obtuve una visa a pesar de que tenía documentos que confirmaban mi discurso en la conferencia! Resulta que la Embajada de Singapur no acepta solicitudes de niñas solteras y desempleadas menores de 35 años. E incluso si la niña trabaja, pero no está casada, la posibilidad de obtener un rechazo sigue siendo muy grande.
Afortunadamente, aprendí que los ciudadanos de la Federación de Rusia que viajan en tránsito pueden permanecer en Singapur hasta 96 horas. Como resultado, volé a Malasia a través de Singapur, en el que pasé casi ocho días en total. La conferencia en sí duró seis días. Debido a restricciones, asistí a los primeros cuatro, luego tuve que irme para regresar para el cierre. Después de la conferencia, decidí sentirme como un turista y simplemente caminé por la ciudad durante dos días y visité museos.
Preparé un discurso en ICARCV por adelantado, de regreso en San Petersburgo. Lo ensayé en un taller de entrenamiento de refuerzo. Por lo tanto, hablar en la conferencia fue emocionante, pero no aterrador. La presentación en sí duró 15 minutos, pero después hubo una sección de preguntas, que me pareció muy útil.
Me hicieron algunas preguntas bastante interesantes que provocaron nuevas ideas. Por ejemplo, sobre cómo marcamos los datos. En nuestro trabajo, marcamos los datos manualmente y nos ofrecieron usar una biblioteca que comprende automáticamente dónde están las partes del cuerpo humano. Ahora acabamos de comenzar a implementar esta idea. Puedes leer todo el trabajo
aquí .
En ICARCV, disfruté comunicarme con los científicos y aprendí muchas ideas nuevas. La cantidad de artículos interesantes que conocí en estos días fue mayor que en los cuatro años anteriores. Ahora hay una "exageración" para el aprendizaje automático en el mundo, y todos los días aparecen docenas de artículos nuevos en Internet, entre los cuales es muy difícil encontrar algo que valga la pena. Es por esto, me parece, que vale la pena ir a conferencias: para encontrar comunidades que discutan nuevos temas interesantes, aprendan sobre nuevas ideas y compartan las suyas. ¡Y haz amigos!