Hola Mi nombre es Ivan Davydov, me dedico a la investigación de desempeño en Yandex.Money.
Imagine que tiene servidores potentes, cada uno de los cuales aloja una serie de aplicaciones. Si no hay muchos de estos últimos, no interfieren con el trabajo del otro, son cómodos y acogedores. Una vez que llegue a microservicios y saque parte de la funcionalidad "pesada" en aplicaciones separadas.
Aquí puede dejarse llevar, y habrá demasiados microservicios, por lo que será difícil administrarlos y garantizar su tolerancia a fallas. Como resultado, una docena de aplicaciones que luchan por los recursos compartidos serán "agrupadas" en cada servidor. Resultará ser una "gran familia", ¡pero en una gran familia no hagas clic con el pico!
Una vez que también nos enfrentamos a esto. Mi historia será sobre noches pesadas e insomnes, cuando me senté debajo de una lámpara en la noche y disparé a la picadura. Todo comenzó con el hecho de que comenzamos a notar problemas de red en los servidores de batalla.
Influyeron mucho en el rendimiento e hicieron importantes reducciones. Al mismo tiempo, resultó que se producen los mismos errores con una transmisión de usuario normal, pero en un grado mucho menor.
El problema radica en la utilización de sockets TCP en más del 100%. Esto sucede cuando todos los sockets de los servidores se abren y cierran constantemente. Debido a esto, existen problemas de red de interacción entre aplicaciones y aparecen varios tipos de errores: el host remoto no está disponible, la conexión HTTP / HTTPS (conexión / tiempo de espera de lectura, el par SSL se cerró incorrectamente) y otros.
Incluso si no tiene su propio servicio de pago electrónico, no es muy difícil evaluar el alcance del dolor durante una venta regular: el tráfico aumenta varias veces y la degradación del rendimiento puede ocasionar pérdidas significativas. Así que llegamos a dos conclusiones: necesitamos evaluar cómo se utilizan las capacidades actuales y aislar las aplicaciones entre sí.
Para aislar las aplicaciones, decidimos recurrir a la contenedorización. Para hacer esto, utilizamos un hipervisor que contiene muchos contenedores separados con aplicaciones. Esto le permite aislar los recursos del procesador, memoria, dispositivos de entrada / salida, redes, así como árboles de proceso, usuarios, sistemas de archivos, etc.
Con este enfoque, cada aplicación tiene su propio entorno, que proporciona flexibilidad, aislamiento, confiabilidad y mejora el rendimiento general del sistema. Esta es una solución hermosa y elegante, pero antes de eso debe responder una serie de preguntas:
- ¿Qué margen de rendimiento tiene actualmente una instancia de aplicación?
- ¿Cómo se escala la aplicación y hay redundancia de recursos en la configuración actual?
- ¿Es posible mejorar el rendimiento de una instancia y cuál es el cuello de botella?
Con tales preguntas, nuestros colegas acudieron a nosotros, un equipo de investigadores de desempeño.
Que estamos haciendo
Hacemos todo lo posible para garantizar el rendimiento de nuestro servicio y, en primer lugar, lo investigamos y lo mejoramos para los procesos comerciales de nuestra producción. Cada proceso de negocio, ya sea pagar productos en una tienda con una billetera o transferir dinero entre usuarios, en esencia, representa para nosotros una cadena de solicitudes en el sistema.
Realizamos experimentos y preparamos informes para evaluar el rendimiento del sistema a alta intensidad de las solicitudes entrantes. Los informes contienen métricas de rendimiento y una descripción detallada de los problemas y cuellos de botella identificados. Con la ayuda de esta información, mejoramos y optimizamos nuestro sistema.
Evaluar el potencial de cada aplicación es complicado por el hecho de que varios microservicios que utilizan el poder de todas las instancias involucradas participan en la organización de la secuencia de solicitudes de procesos de negocios.
Hablando metafóricamente, conocemos el poder de nuestro ejército, pero no sabemos el potencial de cada uno de los combatientes. Por lo tanto, además de la investigación en curso, es necesario evaluar los recursos utilizados como parte del proceso de gestión de la capacidad. Este proceso se llama Gestión de capacidad.
Nuestra investigación ayuda a identificar y prevenir la falta de recursos, pronosticar las compras de hierro y tener datos precisos sobre las capacidades actuales y potenciales del sistema. Como parte de este proceso, se supervisa el rendimiento real de la aplicación (mediana y máxima) y se proporcionan datos sobre el stock actual.
La esencia de la gestión de la capacidad es encontrar un equilibrio entre los recursos consumidos y la productividad.
Pros:
- En cualquier momento se sabe qué sucede con el rendimiento de cada aplicación.
- Menos riesgo al agregar nuevos microservicios.
- Menores costos para la compra de nuevos equipos.
- Esas capacidades que ya existen se utilizan de manera más inteligente.
Cómo funciona la gestión de capacidad
Volvamos a nuestra situación con muchas aplicaciones. Realizamos un estudio cuyo propósito era evaluar cómo se utilizan las capacidades en los servidores de producción.
En resumen, el plan de acción es el siguiente:
- Definir la intensidad del usuario en aplicaciones específicas.
- Haz un perfil de disparo.
- Evaluar el rendimiento de cada instancia de aplicación.
- Tasa de escalabilidad.
- Recopile informes y conclusiones sobre el número mínimo requerido de instancias para cada aplicación en un entorno de combate.
Y ahora con más detalle.
Las herramientas
Utilizamos Heka y Zabbix para recopilar métricas de intensidad personalizadas. Grafana se utiliza para visualizar las métricas recopiladas.
Se necesita Zabbix para monitorear los recursos del servidor, tales como: CPU, Memoria, Conexiones de red, DB y otros. Heka proporciona datos sobre el número y el tiempo de ejecución de las solicitudes entrantes / salientes, la recopilación de métricas en las colas de aplicaciones internas y una cantidad infinita de otros datos. Grafana es una herramienta de visualización flexible utilizada por diferentes equipos de Yandex.Money. No somos la excepción.
Grafana puede mostrar, por ejemplo, tales cosas
Apache JMeter se utiliza como generador de tráfico. Con su ayuda, se compila un escenario de disparo, que incluye la implementación de solicitudes, el monitoreo de la validez de la respuesta, el control flexible del flujo de alimentación y mucho más. Esta herramienta tiene sus ventajas y desventajas, pero para profundizar "¿por qué este producto en particular?" No lo haré
Además de JMeter, se utiliza el marco yandex-tank , una herramienta para pruebas de estrés y análisis del rendimiento de servicios y aplicaciones web. Le permite conectar sus módulos para obtener las funciones deseadas y mostrar los resultados en la consola o en forma de gráficos. Los resultados de nuestros disparos se muestran en Lunapark (análogo a https://overload.yandex.net ), donde podemos observarlos en detalle en tiempo real, hasta segundos picos, proporcionando la discreción necesaria y suficiente y, por lo tanto, responder más rápidamente a las explosiones, derivado de disparos. En grafano, también se puede ajustar la discreción, pero esta solución es más costosa en términos de recursos físicos y lógicos. Y a veces incluso cargamos datos sin procesar y los visualizamos a través del GUI Jmeter. Pero solo ... ¡shhh!
Hablando de degradación. Casi todos los bloqueos que ocurren en la aplicación bajo un gran flujo de tráfico se analizan rápidamente con Kibana . Pero esto tampoco es una panacea: algunos problemas de red solo pueden analizarse eliminando y analizando el tráfico.
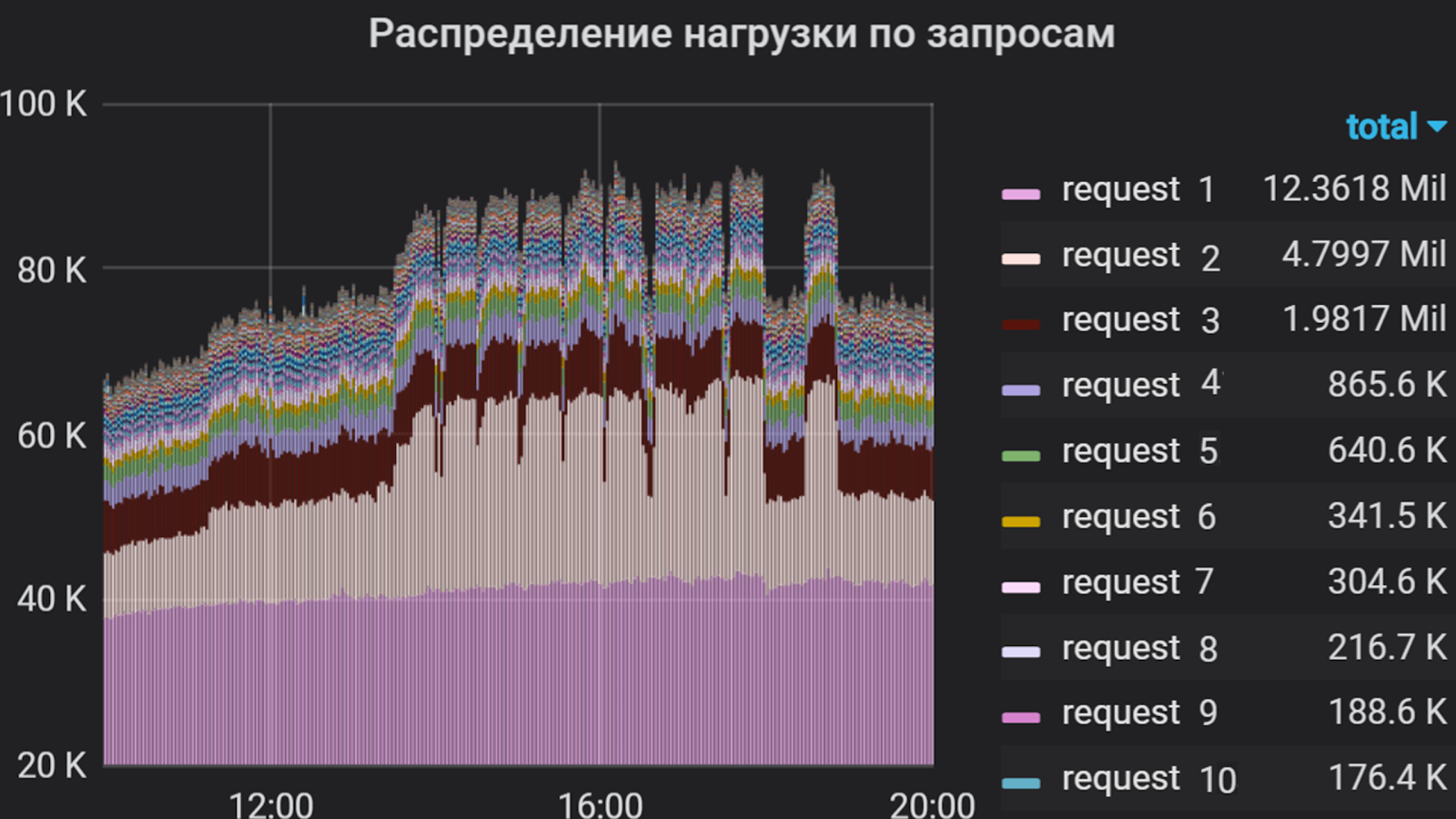
Usando Grafana, analizamos la intensidad del usuario en la aplicación durante varios meses. Decidimos tomar el tiempo total del procesador para ejecutar solicitudes como una unidad de medida, es decir, se tuvo en cuenta el número de solicitudes y el tiempo de ejecución. Así que compilamos una lista de las solicitudes más "pesadas", que constituyen la mayor parte del flujo a la aplicación. Fue esta lista la que formó la base del perfil de disparo.

Intensidad del usuario por aplicación durante varios meses.
Perfil de tiro y avistamiento
Llamamos disparar un lanzamiento de script como parte de un experimento. El perfil se compone de dos partes.
La primera parte es escribir un script de consulta. Durante la implementación, es necesario analizar la intensidad del usuario para cada solicitud de aplicación entrante y establecer una proporción porcentual entre ellas para identificar las más solicitadas y las de mayor duración. La segunda parte es la selección de parámetros de crecimiento del flujo: con qué intensidad y durante cuánto tiempo cargar.
Para mayor claridad, la metodología para compilar un perfil se demuestra mejor con un ejemplo.
Grafana crea un gráfico que refleja la intensidad del usuario y la parte de cada solicitud en el flujo total. En función de este tiempo de distribución y respuesta para cada solicitud, se crean grupos en JMeter, cada uno de los cuales es un generador de tráfico independiente. El escenario se basa solo en las solicitudes más "difíciles", ya que es difícil implementar todo (en algunas aplicaciones hay más de cien), y esto no siempre es necesario debido a su intensidad relativamente baja.

Porcentaje de consultas
Este estudio examina la intensidad del usuario en un flujo constante, y las "ráfagas" que ocurren periódicamente se consideran con mayor frecuencia en privado.
En nuestro ejemplo, se consideran dos grupos. El primer grupo incluyó "solicitud 1" y "solicitud 2" en la proporción de 1 a 2. Del mismo modo, el segundo grupo incluyó solicitudes 3 y 4. Las solicitudes restantes para el componente son mucho menos intensas, por lo que no las incluimos en el script.

Agrupación de consultas en Jmeter
Según la mediana del tiempo de respuesta para cada grupo, el rendimiento se estima mediante la fórmula:
x = 1000 / t, donde t es la mediana del tiempo, ms
Obtenemos el resultado del cálculo y estimamos la intensidad aproximada con un número creciente de hilos:
TPS = x * p, donde p es el número de subprocesos, TPS es la transacción por segundo y x es el resultado del cálculo anterior.
Si la solicitud se procesa en 500 ms, entonces con una secuencia tenemos 2 Tps, y con 100 subprocesos idealmente debería tener 200 Tps. En base a los resultados obtenidos, se pueden seleccionar los parámetros iniciales de crecimiento. Después de la primera iteración de la investigación, estos parámetros generalmente se ajustan.
Cuando el escenario de disparo está listo, comenzamos a disparar, disparando durante un minuto en una secuencia. Esto se hace para verificar la operatividad del script con un flujo constante, para evaluar el tiempo de respuesta a las solicitudes en cada grupo y para obtener un porcentaje de solicitudes.
Al ejecutar este perfil, encontramos que con la misma intensidad, se conserva el porcentaje de solicitudes, ya que el tiempo de respuesta promedio en el segundo grupo es más largo que en el primero. Por lo tanto, establecemos la misma velocidad de flujo para ambos grupos. En otros casos, sería necesario seleccionar experimentalmente los parámetros para cada grupo por separado.
En este ejemplo, la intensidad se aplicó por etapas, es decir, se agregó un cierto número de flujos durante un intervalo determinado.

Opciones de crecimiento de intensidad
Los parámetros de crecimiento de intensidad fueron los siguientes:
- El número objetivo de hilos es 100 (determinado durante el avistamiento).
- Crecimiento durante 1000 segundos (~ 16 min.).
- 100 pasos
Por lo tanto, cada 10 segundos agregamos una secuencia. El intervalo entre agregar subprocesos y la cantidad de subprocesos agregados varía según el comportamiento del sistema en un paso particular. A menudo, la intensidad se suministra con un crecimiento suave, para que pueda seguir el estado del sistema en cada etapa.
Disparando
Por lo general, el disparo comienza de noche desde servidores remotos. En este momento, el tráfico de usuarios es mínimo, esto significa que el disparo difícilmente afectará a los usuarios, y el error en los resultados será menor.
Según los resultados del primer disparo en una instancia, ajustamos el número de hilos y el tiempo de crecimiento, analizamos el comportamiento del sistema en su conjunto y encontramos desviaciones en el trabajo. Después de todos los ajustes, comienza el disparo repetido en una instancia. En esta etapa, determinamos el rendimiento máximo y supervisamos el uso de los recursos de hardware tanto del servidor con la aplicación como de todo lo que está detrás.
Según los resultados del tiroteo, el rendimiento de una instancia de nuestra aplicación fue de aproximadamente 1000 Tps. Al mismo tiempo, se registró un aumento en el tiempo de respuesta para todas las solicitudes sin aumentar la productividad, es decir, logramos la saturación, pero no la degradación.
En la siguiente etapa, comparamos los resultados obtenidos de otras instancias. Esto es importante, ya que el hardware puede diferir, lo que significa que diferentes instancias pueden dar indicadores muy diferentes. Así fue con nosotros: algunos de los servidores resultaron ser un orden de magnitud más productivos debido a la generación y las características. Por lo tanto, identificamos un grupo de servidores con los mejores resultados e investigamos la escalabilidad en ellos.
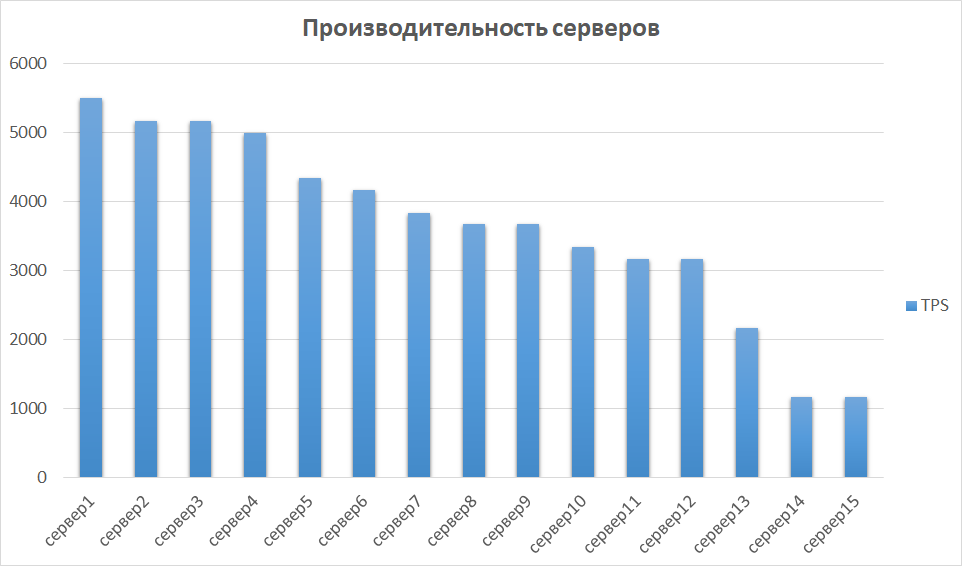
Comparación de rendimiento del servidor
Escalabilidad y cuello de botella
El siguiente paso es investigar el rendimiento en las instancias 2, 3 y 4. En teoría, el rendimiento debería crecer linealmente con un número creciente de instancias. En la práctica, este no suele ser el caso.
En nuestro ejemplo, resultó ser una opción casi perfecta.

La razón para saturar el crecimiento de la productividad fue el agotamiento de los grupos de conectores antes del posterior backend. Esto se resuelve controlando el tamaño de los grupos en el lado saliente y entrante y conduce a un aumento en el rendimiento de la aplicación.
En otros estudios, encontramos cosas más interesantes. Los experimentos han demostrado que, junto con el rendimiento, la utilización de conexiones de CPU y bases de datos está creciendo rápidamente. En nuestro caso, esto sucedió porque en la configuración con una instancia nos encontramos con nuestra propia configuración para grupos de aplicaciones, y con dos instancias duplicamos este número, duplicando así la transmisión saliente. La base de datos no estaba lista para tal volumen. Debido a esto, los grupos de la base de datos comenzaron a obstruirse, el porcentaje de CPU consumida alcanzó una marca crítica del 99%, y el tiempo de procesamiento de consultas aumentó, y parte del tráfico se redujo por completo. ¡Y ya obtuvimos esos resultados en dos instancias!
Para finalmente convencernos de nuestros miedos, disparamos a 3 instancias. Los resultados fueron aproximadamente los mismos que en los dos primeros, excepto que rápidamente llegaron a un trastorno.
Hay otro ejemplo de "enchufes", que, en mi opinión, es el más doloroso: este es un código mal escrito. Puede haber cualquier cosa que desee, comenzando con consultas a la base de datos que se ejecutan en minutos y terminando con un código que asigna mal la memoria de una máquina Java.
Resumen
Como resultado, el margen de aplicación investigado en nuestra aplicación de ejemplo tiene un margen de rendimiento de más de 5 veces.
Para aumentar la productividad, es necesario calcular un número suficiente de grupos de procesadores en la configuración de la aplicación. Dos instancias para una aplicación específica son suficientes, y el uso de los 15 disponibles es redundante.
Después del estudio, se obtuvieron los siguientes resultados:
- La intensidad del usuario durante 1 mes fue determinada y monitoreada.
- Se ha identificado el margen de rendimiento de una instancia de la aplicación.
- Los resultados se obtienen sobre errores que ocurren bajo una secuencia grande.
- Se han identificado cuellos de botella para seguir trabajando en aumentar la productividad.
- Se ha identificado el número mínimo suficiente de instancias para el correcto funcionamiento de la aplicación. Y, como resultado, se reveló el uso excesivo de capacidades.
Los resultados del estudio formaron la base del proyecto para la transferencia de componentes a contenedores, que discutiremos en los siguientes artículos. Ahora podemos decir con certeza cuántos contenedores y con qué características es necesario tener, cómo usar sus capacidades racionalmente y en qué se debe trabajar para garantizar un rendimiento adecuado.
Venga a nuestra acogedora sala de chat de telegramas donde siempre puede pedir consejos, ayudar a colegas y simplemente hablar sobre la investigación de productividad.
Eso es todo por hoy. Haga preguntas en los comentarios y suscríbase al blog Yandex.Money. Pronto hablaremos sobre el phishing y cómo evitarlo.