Los juegos se han utilizado durante décadas como una de las principales formas de probar y evaluar el éxito de los sistemas de inteligencia artificial. A medida que crecían las oportunidades, los investigadores buscaron juegos con una complejidad cada vez mayor, que reflejaran los diversos elementos de pensamiento necesarios para resolver problemas científicos o aplicados del mundo real. En los últimos años, StarCraft se considera una de las estrategias en tiempo real más versátiles y complejas y una de las más populares en la escena de los deportes electrónicos en la historia, y ahora StarCraft también se ha convertido en el principal desafío para la investigación de IA.
AlphaStar es el primer sistema de inteligencia artificial capaz de derrotar a los mejores jugadores profesionales. En una serie de partidos que tuvieron lugar el 19 de diciembre, AlphaStar obtuvo una victoria aplastante sobre Grzegorz Komincz (MaNa) de
Liquid , uno de los
jugadores más fuertes del mundo , con un puntaje de 5: 0. Antes de eso, también se jugó un exitoso partido de demostración contra su compañero de equipo Dario Wünsch (
TLO ). Los partidos se llevaron a cabo de acuerdo con todas las reglas profesionales en una
tarjeta de torneo especial y sin restricciones.
A pesar de los éxitos significativos en juegos como
Atari ,
Mario ,
Quake III Arena y
Dota 2 , los técnicos de IA lucharon sin éxito contra la complejidad de StarCraft. Los mejores
resultados se lograron al construir manualmente los elementos básicos del sistema, al imponer varias restricciones a las reglas del juego, al proporcionar al sistema habilidades sobrehumanas o al jugar en mapas simplificados. Pero incluso estos matices hicieron imposible acercarse al nivel de los jugadores profesionales. Contrariamente a esto, AlphaStar juega un juego completo utilizando redes neuronales profundas, que se entrenan sobre la base de datos sin procesar del juego, utilizando métodos de
enseñanza con un maestro y
aprendizaje con refuerzo .
Desafío principal
StarCraft II es un universo de fantasía ficticio con un juego rico y de varios niveles. Junto con la edición original, este es el juego más grande y exitoso de todos los tiempos, que ha estado luchando en torneos durante más de 20 años.

Hay muchas formas de jugar, pero la más común en los deportes electrónicos son los torneos uno a uno que consisten en 5 partidos. Para comenzar, el jugador debe elegir una de las tres razas: zergs, protoss o terrans, cada una de las cuales tiene sus propias características y capacidades. Por lo tanto, los jugadores profesionales se especializan con mayor frecuencia en una carrera. Cada jugador comienza con varias unidades de trabajo que extraen recursos para construir edificios, otras unidades o desarrollar tecnología. Esto permite al jugador aprovechar otros recursos, construir bases más sofisticadas y desarrollar nuevas habilidades para burlar al oponente. Para ganar, el jugador debe equilibrar muy delicadamente la imagen de la economía general, llamada "macro", y el control de bajo nivel de las unidades individuales, llamado "micro".
La necesidad de equilibrar los objetivos a corto y largo plazo y adaptarse a situaciones imprevistas plantea un gran desafío para los sistemas que, de hecho, a menudo resultan ser completamente inflexibles. Resolver este problema requiere un gran avance en varias áreas de la IA:
Teoría del juego : StarCraft es un juego en el que, como en "Piedra, tijera, papel", no existe una estrategia ganadora única. Por lo tanto, en el proceso de aprendizaje, la IA debe explorar y expandir constantemente los horizontes de su conocimiento estratégico.
Información incompleta : a diferencia del ajedrez o ir, donde los jugadores ven todo lo que sucede, en StarCraft la información importante a menudo se oculta y debe extraerse activamente a través de la inteligencia.
Planificación a largo plazo : como en las tareas del mundo real, las relaciones causa-efecto pueden no ser instantáneas. Un juego también puede durar una hora o más, por lo tanto, las acciones realizadas al comienzo de un juego pueden no tener absolutamente ningún significado a largo plazo.
Tiempo real : a diferencia de los juegos de mesa tradicionales, donde los participantes se turnan por turnos, en StarCraft, los jugadores realizan acciones continuamente, junto con el paso del tiempo.
Gran espacio de acción : Cientos de diferentes unidades y edificios deben ser monitoreados simultáneamente, en tiempo real, lo que brinda un enorme espacio combinatorio de oportunidades. Además de esto, muchas acciones son jerárquicas y pueden cambiar y complementarse en el camino. Nuestra parametrización del juego proporciona un promedio de aproximadamente 10 a 26 acciones por unidad de tiempo.
En vista de estos desafíos, StarCraft se ha convertido en un gran desafío para los investigadores de IA. Las competencias actuales de StarCraft y StarCraft II tienen sus raíces en el lanzamiento de
BroodWar API en 2009. Entre ellos se encuentran
AIIDE StarCraft AI Competition ,
CIG StarCraft Competition ,
Student StarCraft AI Tournament y
Starcraft II AI Ladder .
Nota : En 2017, PatientZero publicó en Habré una excelente traducción de " La historia de las competiciones de IA en Starcraft ".Para ayudar a la comunidad a explorar más estos problemas, nosotros,
trabajando con Blizzard en 2016 y 2017,
publicamos el kit de herramientas PySC2 , que incluye la mayor variedad de repeticiones anonimizadas que se haya publicado. En base a este trabajo, combinamos nuestros logros de ingeniería y algoritmos para crear AlphaStar.
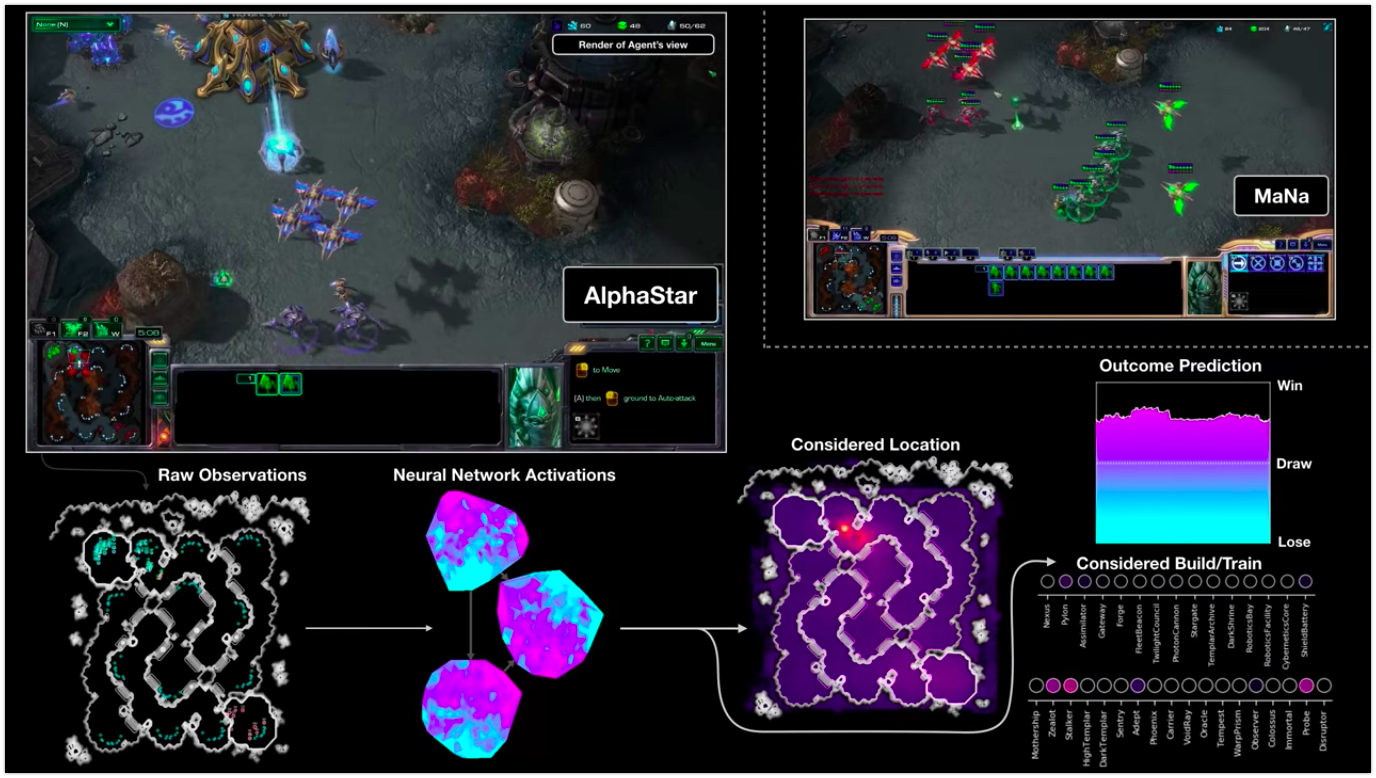
 La visualización de AlphaStar durante la lucha contra MaNa demuestra el juego en nombre del agente: los datos iniciales observados, la actividad de la red neuronal, algunas de las acciones propuestas y las coordenadas requeridas, así como el resultado estimado del partido. También se muestra la vista del reproductor MaNa, pero, por supuesto, el agente no puede acceder a ella.
La visualización de AlphaStar durante la lucha contra MaNa demuestra el juego en nombre del agente: los datos iniciales observados, la actividad de la red neuronal, algunas de las acciones propuestas y las coordenadas requeridas, así como el resultado estimado del partido. También se muestra la vista del reproductor MaNa, pero, por supuesto, el agente no puede acceder a ella.Como es el entrenamiento
El comportamiento AlphaStar es generado
por una red neuronal de aprendizaje profundo, que recibe datos sin procesar a través de la interfaz (una lista de unidades y sus propiedades) y proporciona una secuencia de instrucciones que son acciones en el juego. Más específicamente, la arquitectura de la red neuronal adopta el enfoque de "torso
transformador para las unidades, combinado con un
núcleo LSTM profundo , un
jefe de política autorregresivo con una
red de puntero y una
línea de base de valor centralizada "
( no traducida ) . Creemos que estos modelos ayudarán aún más a hacer frente a otras tareas importantes de aprendizaje automático, incluido el modelado de secuencias a largo plazo y los grandes espacios de salida, como la traducción, el modelado del lenguaje y las representaciones visuales.
AlphaStar también utiliza el nuevo algoritmo de aprendizaje multiagente. Esta red neuronal se entrenó originalmente utilizando un método de aprendizaje basado en el maestro basado en repeticiones anónimas
disponibles a través de Blizzard. Esto permitió a AlphaStar estudiar y simular las micro y macro estrategias básicas utilizadas por los jugadores en los torneos. Este agente derrotó el nivel de inteligencia artificial incorporado "Elite", que es equivalente al nivel de un jugador en la liga de oro en el 95% de los juegos de prueba.
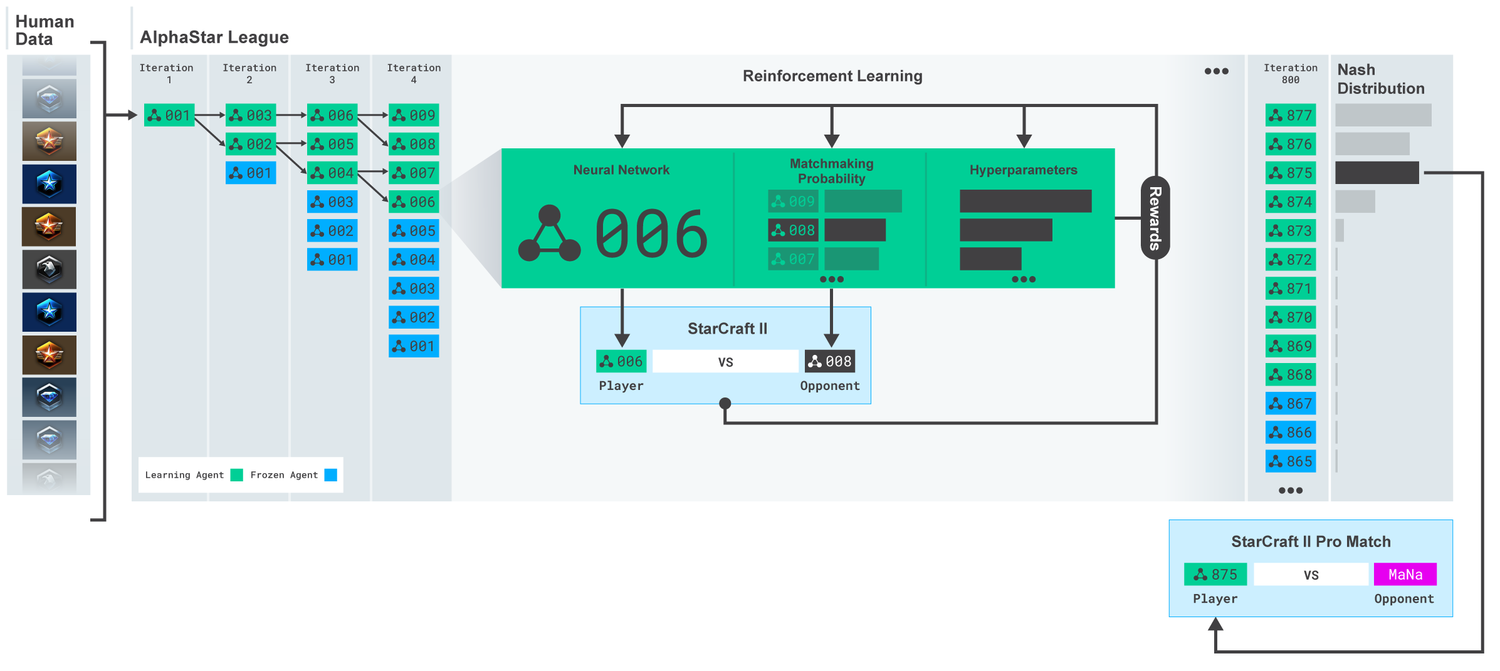 League AlphaStar. Los agentes fueron entrenados inicialmente sobre la base de repeticiones de partidos humanos, y luego sobre la base de partidos competitivos entre ellos. En cada iteración, los nuevos oponentes se ramifican y los originales se congelan. La probabilidad de encontrarse con otros oponentes e hiperparámetros determina los objetivos de aprendizaje para cada agente, lo que aumenta la complejidad y conserva la diversidad. Los parámetros del agente se actualizan con entrenamiento de refuerzo basado en el resultado del juego contra oponentes. El agente final se selecciona (sin reemplazo) en función de la distribución de Nash.
League AlphaStar. Los agentes fueron entrenados inicialmente sobre la base de repeticiones de partidos humanos, y luego sobre la base de partidos competitivos entre ellos. En cada iteración, los nuevos oponentes se ramifican y los originales se congelan. La probabilidad de encontrarse con otros oponentes e hiperparámetros determina los objetivos de aprendizaje para cada agente, lo que aumenta la complejidad y conserva la diversidad. Los parámetros del agente se actualizan con entrenamiento de refuerzo basado en el resultado del juego contra oponentes. El agente final se selecciona (sin reemplazo) en función de la distribución de Nash.Estos resultados se utilizan para iniciar un proceso de aprendizaje de refuerzo de múltiples agentes. Para esto, se creó una liga donde los agentes oponentes juegan unos contra otros, al igual que las personas ganan experiencia jugando torneos. Se agregaron nuevos rivales a la liga, por duplicación de los agentes actuales. Esta nueva forma de aprendizaje, que toma prestadas algunas ideas del método de aprendizaje por refuerzo con elementos de algoritmos
basados en la población (
basados en la población ), le permite crear un proceso continuo de exploración del vasto espacio estratégico del juego de StarCraft y asegurarse de que los agentes puedan resistir las estrategias más poderosas, no olvidando los viejos.
 Score MMR (Match Making Rating): un indicador aproximado de la habilidad del jugador. Para los rivales en la liga AlphaStar durante el entrenamiento, en comparación con las ligas en línea de Blizzard.
Score MMR (Match Making Rating): un indicador aproximado de la habilidad del jugador. Para los rivales en la liga AlphaStar durante el entrenamiento, en comparación con las ligas en línea de Blizzard.A medida que la liga se desarrolló y se crearon nuevos agentes, aparecieron estrategias contrarias que pudieron derrotar a las anteriores. Mientras que algunos agentes solo mejoraron las estrategias que habían encontrado anteriormente, otros agentes crearon estrategias completamente nuevas, incluidas nuevas órdenes de construcción inusuales, composición de unidades y administración de macros. Por ejemplo, desde el principio, los "quesos" florecieron: una carrera rápida con la ayuda de pistolas de
cañones de
fotones o
templarios oscuros . Pero a medida que avanzaba el proceso de aprendizaje, estas estrategias arriesgadas fueron descartadas, dando paso a otras. Por ejemplo, la producción de un número excesivo de trabajadores para obtener una afluencia adicional de recursos o la donación de dos
Oráculos para atacar a los trabajadores del enemigo y socavar su economía. Este proceso es similar a cómo los jugadores regulares descubrieron nuevas estrategias y derrotaron viejos enfoques populares, durante los muchos años transcurridos desde el lanzamiento de StarCraft.
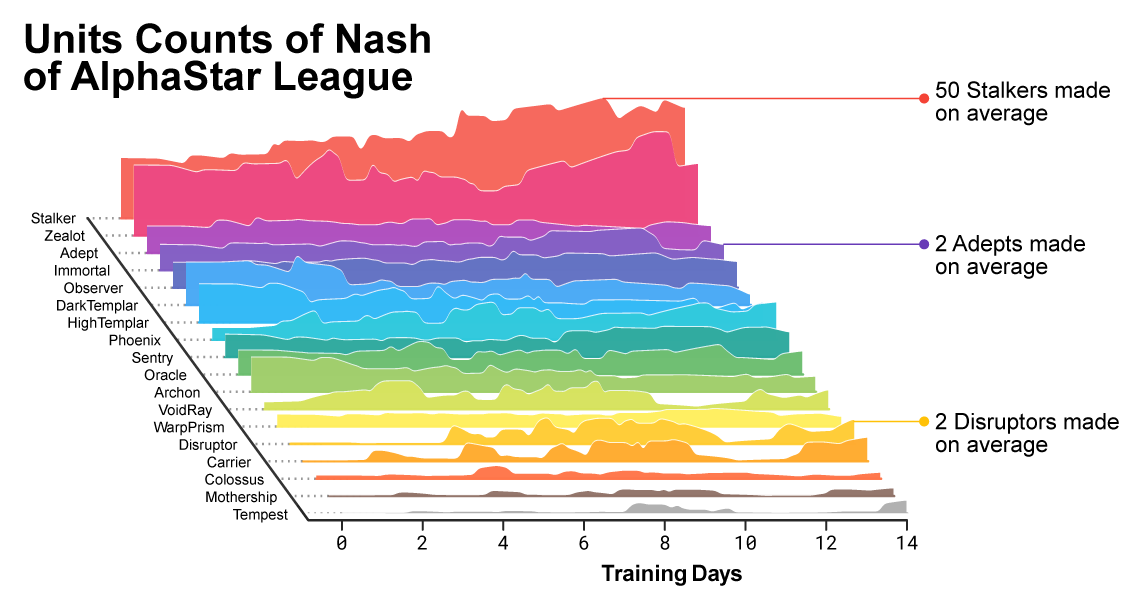 A medida que avanzaba el entrenamiento, se notó cómo estaba cambiando la composición de las unidades utilizadas por los agentes.
A medida que avanzaba el entrenamiento, se notó cómo estaba cambiando la composición de las unidades utilizadas por los agentes.Para garantizar la diversidad, cada agente estaba dotado de su propio objetivo de aprendizaje. Por ejemplo, a qué oponentes debería vencer este agente, o cualquier otra motivación intrínseca que determine el juego del agente. Un determinado agente puede tener el objetivo de derrotar a un oponente específico y al otro una selección completa de oponentes, pero solo unidades específicas. Estas metas han cambiado a lo largo del proceso de aprendizaje.
 Visualización interactiva (las características interactivas están disponibles en el artículo original ), que muestra rivales con la Liga AlphaStar. El agente que jugó contra TLO y MaNa se marca por separado.
Visualización interactiva (las características interactivas están disponibles en el artículo original ), que muestra rivales con la Liga AlphaStar. El agente que jugó contra TLO y MaNa se marca por separado.Los coeficientes (pesos) de la red neuronal de cada agente se actualizaron mediante el entrenamiento de refuerzo basado en juegos con oponentes para optimizar sus objetivos de aprendizaje específicos. La regla para actualizar el peso es un nuevo algoritmo de aprendizaje eficaz "algoritmo de aprendizaje de refuerzo
actor-crítico fuera de política con
repetición de experiencia ,
aprendizaje de imitación propia y
destilación de políticas "
(para la precisión de los términos que quedan sin traducción) .
 La imagen muestra cómo un agente (punto negro), que fue seleccionado como resultado del juego contra MaNa, desarrolló su estrategia en comparación con los oponentes (puntos de colores) en el proceso de entrenamiento. Cada punto representa un oponente en la liga. La posición del punto muestra la estrategia y el tamaño: la frecuencia con la que se elige como oponente del agente MaNa en el proceso de aprendizaje.
La imagen muestra cómo un agente (punto negro), que fue seleccionado como resultado del juego contra MaNa, desarrolló su estrategia en comparación con los oponentes (puntos de colores) en el proceso de entrenamiento. Cada punto representa un oponente en la liga. La posición del punto muestra la estrategia y el tamaño: la frecuencia con la que se elige como oponente del agente MaNa en el proceso de aprendizaje.Para capacitar a AlphaStar, creamos un sistema distribuido escalable basado en
Google TPU 3, que proporciona el proceso de capacitación paralela de toda una población de agentes con miles de copias de StarCraft II. AlphaStar League duró 14 días con 16 TPU para cada agente. Durante el entrenamiento, cada agente experimentó hasta 200 años de experiencia jugando StarCraft en tiempo real. La versión final de AlphaStar Agent contiene todos los componentes de
distribución de la Liga
Nash . En otras palabras, la combinación más efectiva de estrategias que se descubrieron durante los juegos. Y esta configuración se puede ejecutar en una GPU de escritorio estándar. Se está preparando una descripción técnica completa para su publicación en una revista científica revisada por pares.
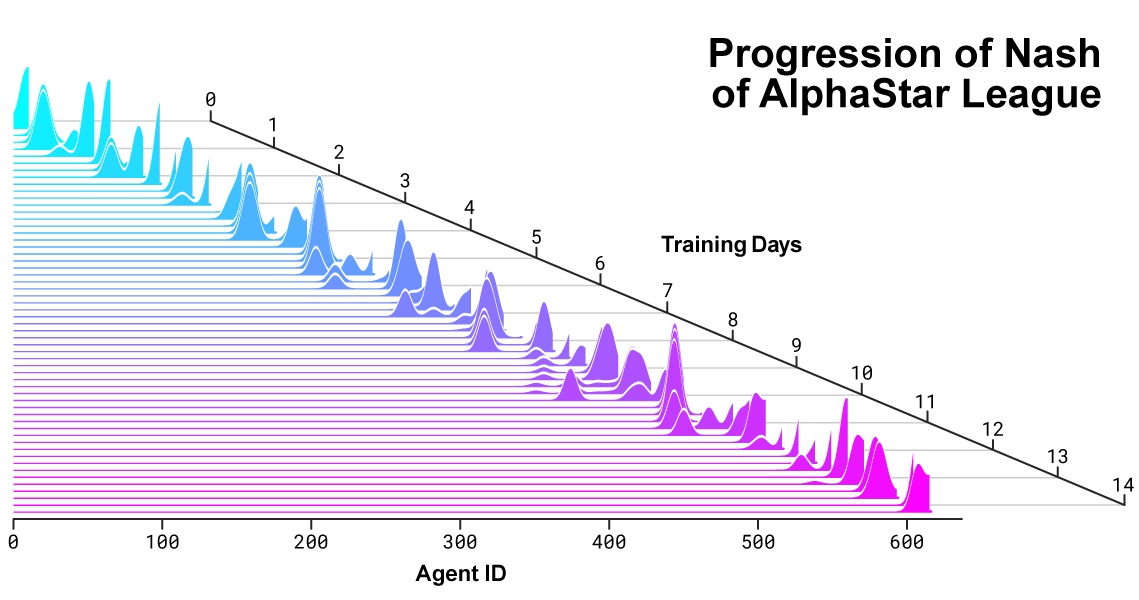 Distribución de Nash entre rivales durante el desarrollo de la liga y la creación de nuevos oponentes. La distribución de Nash, que es el conjunto de competidores complementarios menos explotable, aprecia a los nuevos jugadores, lo que demuestra un progreso continuo sobre todos los competidores anteriores.
Distribución de Nash entre rivales durante el desarrollo de la liga y la creación de nuevos oponentes. La distribución de Nash, que es el conjunto de competidores complementarios menos explotable, aprecia a los nuevos jugadores, lo que demuestra un progreso continuo sobre todos los competidores anteriores.Cómo actúa AlphaStar y ve el juego
Los jugadores profesionales como TLO o MaNa pueden realizar cientos de acciones por minuto (
APM ). Pero esto es mucho menos que la mayoría de
los bots existentes que controlan de forma independiente cada unidad y generan miles, si no decenas de miles de acciones.
En nuestros juegos contra TLO y MaNa, AlphaStar mantuvo el APM en un promedio de 280, que es mucho menor que el de los jugadores profesionales, aunque sus acciones pueden ser más precisas. Un APM tan bajo se debe en particular al hecho de que AlphaStar comenzó a estudiar sobre la base de repeticiones de jugadores comunes y trató de imitar la forma del juego humano. Además de esto, AlphaStar reacciona con un retraso entre la observación y la acción de un promedio de aproximadamente 350 ms.
 Distribución de APM AlphaStar en partidos contra MaNa y TLO, y el retraso general entre observación y acción.
Distribución de APM AlphaStar en partidos contra MaNa y TLO, y el retraso general entre observación y acción.Durante los partidos contra TLO y MaNa, AlphaStar interactuó con el motor del juego StarCraft a través de la interfaz en bruto, es decir, podía ver los atributos de sus unidades enemigas visibles en el mapa directamente, sin tener que mover la cámara: juega de manera efectiva con una vista reducida de todo el territorio . Contrariamente a esto, las personas vivas deben gestionar claramente la "economía de la atención" para decidir constantemente dónde enfocar la cámara. Sin embargo, un análisis de los juegos AlphaStar revela que controla implícitamente el enfoque. En promedio, un agente cambia su contexto de atención aproximadamente 30 veces por minuto, como MaNa y TLO.
Además, desarrollamos la segunda versión de AlphaStar. Como jugadores humanos, esta versión de AlphaStar elige claramente cuándo y dónde mover la cámara. En esta realización, su percepción se limita a la información en la pantalla, y las acciones también se permiten solo en el área visible de la pantalla.
 Rendimiento de AlphaStar cuando se usa la interfaz base y la interfaz de la cámara. El gráfico muestra que el nuevo agente que trabaja con la cámara está alcanzando rápidamente un rendimiento comparable para el agente que utiliza la interfaz base.
Rendimiento de AlphaStar cuando se usa la interfaz base y la interfaz de la cámara. El gráfico muestra que el nuevo agente que trabaja con la cámara está alcanzando rápidamente un rendimiento comparable para el agente que utiliza la interfaz base.Entrenamos a dos agentes nuevos, uno usando la interfaz base y otro que debía aprender a controlar la cámara, jugando contra la liga AlphaStar. Cada agente al principio fue entrenado con un maestro basado en partidos humanos, seguido de entrenamiento con el refuerzo descrito anteriormente. La versión AlphaStar, que utiliza la interfaz de la cámara, logró casi los mismos resultados que la versión con la interfaz base, superando la marca de 7000 MMR en nuestra tabla de clasificación interna. En una partida de demostración, MaNa derrotó al prototipo AlphaStar con una cámara. Entrenamos esta versión solo 7 días. Esperamos poder evaluar una versión totalmente entrenada con una cámara en el futuro cercano.
Estos resultados muestran que el éxito de AlphaStar en los partidos contra MaNa y TLO es principalmente el resultado de una buena gestión de macro y micro, y no solo una gran tasa de clics, reacción rápida o acceso a la información en la interfaz básica.
Resultados del juego AlphaStar vs jugadores profesionales
StarCraft permite a los jugadores elegir una de las tres razas: terranos, zerg o protoss. Decidimos que AlphaStar se especializaría actualmente en una carrera en particular, los protoss, para reducir el tiempo de entrenamiento y las variaciones en la evaluación de los resultados de nuestra liga nacional. Pero debe tenerse en cuenta que un proceso de aprendizaje similar se puede aplicar a cualquier raza. Nuestros agentes fueron entrenados para jugar StarCraft II versión 4.6.2 en modo protoss versus protoss en el mapa CatalystLE. Para evaluar el rendimiento de AlphaStar, inicialmente probamos a nuestros agentes en partidos contra TLO, un jugador profesional para zerg y un jugador para el nivel protoss "GrandMaster". AlphaStar ganó partidos con un puntaje de 5: 0, utilizando una amplia gama de unidades y órdenes de construcción. "Me sorprendió lo fuerte que era el agente", dijo. “AlphaStar toma estrategias bien conocidas y las pone patas arriba. El agente mostró estrategias en las que nunca pensé. Y esto muestra que todavía puede haber formas de jugar que todavía no se comprenden completamente ".
Después de una semana adicional de entrenamiento, jugamos contra MaNa, uno de los jugadores de StarCraft II más poderosos del mundo, y uno de los 10 mejores jugadores protoss. AlphaStar esta vez ganó 5-0, demostrando fuertes habilidades de microgestión y macroestrategia. "Me sorprendió ver a AlphaStar usando los enfoques más avanzados y las diferentes estrategias en cada juego, mostrando un estilo de juego muy humano que nunca esperé ver", dijo. “Me di cuenta de cuán fuerte depende mi estilo de juego del uso de errores basados en reacciones humanas. Y eso pone el juego en un nivel completamente nuevo. Todos esperamos con entusiasmo ver qué pasa después ".
AlphaStar y otros problemas difíciles
A pesar de que StarCraft es solo un juego, incluso si es muy difícil, creemos que las técnicas subyacentes de AlphaStar pueden ser útiles para resolver otros problemas. Por ejemplo, este tipo de arquitectura de red neuronal es capaz de simular secuencias muy largas de acciones probables, en juegos que a menudo duran hasta una hora y contienen decenas de miles de acciones basadas en información incompleta. Cada cuadro en StarCraft se usa como un paso de entrada. En este caso, la red neuronal en cada paso predice la secuencia de acciones esperada para todo el juego restante. La tarea fundamental de hacer pronósticos complejos para secuencias de datos muy largas se encuentra en muchos problemas del mundo real, como el pronóstico del tiempo, el modelado del clima, la comprensión del idioma, etc. Nos complace reconocer el enorme potencial que se puede aplicar en estas áreas, utilizando la experiencia que hemos adquirido. en el proyecto AlphaStar.
También creemos que algunos de nuestros métodos de enseñanza pueden ser útiles para estudiar la seguridad y la fiabilidad de la IA. Uno de los problemas más difíciles en el campo de la IA es la cantidad de opciones en las que el sistema puede estar equivocado.
Y los jugadores profesionales en el pasado rápidamente encontraron formas de evitar la IA, usando sus errores de la manera original. El innovador enfoque AlphaStar, basado en el entrenamiento en la liga, encuentra dichos enfoques y hace que el proceso general sea más confiable y esté protegido contra tales errores. Nos complace que el potencial de este enfoque pueda ayudar a mejorar la seguridad y la confiabilidad de los sistemas de IA en general. Especialmente en áreas críticas como la energía, donde es extremadamente importante reaccionar correctamente en situaciones difíciles.Lograr un nivel de juego tan alto en StarCraft representa un gran avance en uno de los videojuegos más desafiantes jamás creados. Creemos que estos logros, junto con los éxitos en otros proyectos, ya sea AlphaZero o AlphaFold , representan un paso adelante en la implementación de nuestra misión de crear sistemas inteligentes que algún día nos ayudarán a encontrar soluciones a los problemas científicos más complejos y fundamentales.
11 repeticiones de todos los partidosVideo del partido de demostración contra MaNaVideo con visualización AlphaStar del segundo partido completo contra MaNa