
Una vez más, conduciendo un automóvil alrededor de mi ciudad natal y yendo alrededor de otro pozo, pensé: ¿existían carreteras tan "buenas" en todas partes de nuestro país y decidí que deberíamos evaluar objetivamente la situación con la calidad de las carreteras en nuestro país?
Formalización de tareas
En Rusia, los requisitos para la calidad de las carreteras se describen en GOST R 50597-2017 “Carreteras y carreteras. Requisitos para el estado operativo aceptable bajo las condiciones de garantizar la seguridad vial. Métodos de control ". Este documento define los requisitos para cubrir la calzada, los bordes de las carreteras, las franjas divisorias, las aceras, las pasarelas peatonales, etc., y también establece los tipos de daños.
Dado que la tarea de determinar todos los parámetros de las carreteras es bastante extensa, decidí reducirla y centrarme solo en el problema de determinar defectos en la cobertura de la carretera. En GOST R 50597-2017, se distinguen los siguientes defectos en el revestimiento de la carretera:
- baches
- rompe
- reducciones
- turnos
- peines
- rastrear
- carpeta de sudoración
Decidí abordar estos defectos.
Recolección de datos
¿Dónde puedo obtener fotografías que muestren secciones suficientemente grandes de la carretera, e incluso con referencia a la geolocalización? La respuesta vino en pedrería: panoramas en los mapas de Yandex (o Google), sin embargo, después de un poco de búsqueda, encontré varias opciones alternativas más:
- emitir motores de búsqueda de imágenes para solicitudes relevantes;
- fotos en sitios para recibir quejas (Rosyama, ciudadano enojado, Virtud, etc.)
- Opendatascience impulsó un proyecto para detectar defectos en la carretera con un conjunto de datos marcado - github.com/sekilab/RoadDamageDetector
Desafortunadamente, un análisis de estas opciones mostró que no son muy adecuadas para mí: emitir motores de búsqueda tiene mucho ruido (muchas fotos que no son carreteras, varios renders, etc.), las fotos de los sitios para recibir quejas contienen solo fotos con grandes violaciones de la superficie de asfalto , hay bastantes fotos con pequeñas violaciones de cobertura y sin violaciones en estos sitios, el conjunto de datos del proyecto RoadDamageDetector se recopila en Japón y no contiene muestras con grandes violaciones de cobertura, así como carreteras sin cobertura en absoluto.
Como las opciones alternativas no son adecuadas, utilizaremos panoramas de Yandex (excluí la opción de panorama de Google, ya que el servicio se presenta en menos ciudades de Rusia y se actualiza con menos frecuencia). Decidió recopilar datos en ciudades con una población de más de 100 mil personas, así como en centros federales. Hice una lista de nombres de ciudades: había 176 de ellos, más tarde resulta que solo 149 de ellos tienen panorámicas. No profundizaré en las características del análisis de mosaicos, diré que al final obtuve 149 carpetas (una para cada ciudad) en las que había un total de 1.7 millones de fotos. Por ejemplo, para Novokuznetsk, la carpeta se veía así:

Por el número de fotos descargadas, las ciudades se distribuyeron de la siguiente manera:
MesaCiudad
| Número de fotos, piezas
|
|---|
Moscú
| 86048
|
San petersburgo
| 41376
|
Saransk
| 18880
|
Podolsk
| 18560
|
Krasnogorsk
| 18208
|
Lyubertsy
| 17760
|
Kaliningrado
| 16928
|
Kolomna
| 16832
|
Mytishchi
| 16192
|
Vladivostok
| 16096
|
Balashikha
| 15968
|
Petrozavodsk
| 15968
|
Ekaterinburg
| 15808
|
Veliky Novgorod
| 15744
|
Naberezhnye Chelny
| 15680
|
Krasnodar
| 15520
|
Nizhny Novgorod
| 15488
|
Khimki
| 15296
|
Tula
| 15296
|
Novosibirsk
| 15264
|
Tver
| 15200
|
Miass
| 15104
|
Ivanovo
| 15072
|
Vologda
| 15008
|
Zhukovsky
| 14976
|
Kostroma
| 14912
|
Samara
| 14880
|
Korolev
| 14784
|
Kaluga
| 14720
|
Cherepovets
| 14720
|
Sebastopol
| 14688
|
Pushkino
| 14528
|
Yaroslavl
| 14464
|
Ulyanovsk
| 14400
|
Rostov del Don
| 14368
|
Domodedovo
| 14304
|
Kamensk-Uralsky
| 14208
|
Pskov
| 14144
|
Yoshkar-Ola
| 14080
|
Kerch
| 14080
|
Murmansk
| 13920
|
Togliatti
| 13920
|
Vladimir
| 13792
|
Águila
| 13792
|
Syktyvkar
| 13728
|
Dolgoprudny
| 13696
|
Khanty-Mansiysk
| 13664
|
Kazán
| 13600
|
Engels
| 13440
|
Arkhangelsk
| 13280
|
Bryansk
| 13216
|
Omsk
| 13120
|
Syzran
| 13088
|
Krasnoyarsk
| 13056
|
Shchelkovo
| 12928
|
Penza
| 12864
|
Cheliábinsk
| 12768
|
Cheboksary
| 12768
|
Nizhny Tagil
| 12672
|
Stavropol
| 12672
|
Ramenskoye
| 12640
|
Irkutsk
| 12608
|
Angarsk
| 12608
|
Tyumen
| 12512
|
Odintsovo
| 12512
|
Ufa
| 12512
|
Magadán
| 12512
|
Perm
| 12448
|
Kirov
| 12256
|
Nizhnekamsk
| 12224
|
Makhachkala
| 12096
|
Nizhnevartovsk
| 11936
|
Kursk
| 11904
|
Sochi
| 11872
|
Tambov
| 11840
|
Pyatigorsk
| 11808
|
Volgodonsk
| 11712
|
Riazán
| 11680
|
Saratov
| 11616
|
Dzerzhinsk
| 11456
|
Orenburg
| 11456
|
Montículo
| 11424
|
Volgogrado
| 11264
|
Izhevsk
| 11168
|
Crisóstomo
| 11136
|
Lipetsk
| 11072
|
Kislovodsk
| 11072
|
Surgut
| 11040
|
Magnitogorsk
| 10912
|
Smolensk
| 10784
|
Khabarovsk
| 10752
|
Kopeysk
| 10688
|
Maykop
| 10656
|
Petropavlovsk-Kamchatsky
| 10624
|
Taganrog
| 10560
|
Barnaul
| 10528
|
Sergiev Posad
| 10368
|
Elista
| 10304
|
Sterlitamak
| 9920
|
Simferopol
| 9824
|
Tomsk
| 9760
|
Orekhovo-Zuevo
| 9728
|
Astrakhan
| 9664
|
Evpatoria
| 9568
|
Noginsk
| 9344
|
Chita
| 9216
|
Belgorod
| 9120
|
Biysk
| 8928
|
Rybinsk
| 8896
|
Severodvinsk
| 8832
|
Vorónezh
| 8768
|
Blagoveshchensk
| 8672
|
Novorossiysk
| 8608
|
Ulan-Ude
| 8576
|
Serpukhov
| 8320
|
Komsomolsk-on-Amur
| 8192
|
Abakán
| 8128
|
Norilsk
| 8096
|
Yuzhno-Sakhalinsk
| 8032
|
Obninsk
| 7904
|
Essentuki
| 7712
|
Bataysk
| 7648
|
Volzhsky
| 7584
|
Novocherkassk
| 7488
|
Berdsk
| 7456
|
Arzamas
| 7424
|
Pervouralsk
| 7392
|
Kemerovo
| 7104
|
Elektrostal
| 6720
|
Derbent
| 6592
|
Yakutsk
| 6528
|
Murom
| 6240
|
Nefteyugansk
| 5792
|
Reutov
| 5696
|
Birobidzhan
| 5440
|
Novokuybyshevsk
| 5248
|
Salekhard
| 5184
|
Novokuznetsk
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
Novocheboksarsk
| 4352
|
Yelets
| 3968
|
Kaspiysk
| 3936
|
Stary Oskol
| 3840
|
Artyom
| 3744
|
Zheleznogorsk
| 3584
|
Salavat
| 3584
|
Prokopyevsk
| 2816
|
Gorno-Altaysk
| 2464
|
Preparando un conjunto de datos para el entrenamiento
Y entonces, el conjunto de datos está ensamblado, ¿cómo ahora, al tener una foto de la sección de la carretera y los objetos que lo rodean, descubrir la calidad del asfalto que se muestra en él? Decidí cortar una parte de la foto que mide 350 * 244 píxeles en el centro de la foto original, justo debajo del centro. Luego reduzca la pieza cortada horizontalmente a un tamaño de 244 píxeles. La imagen resultante (tamaño 244 * 244) será la entrada para el codificador convolucional:

Para comprender mejor con qué datos trato, las primeras 2000 fotos que marqué yo mismo, el resto de las fotos fueron marcadas por empleados de Yandex.Tolki. Ante ellos planteé una pregunta con la siguiente redacción.
Indique qué superficie de la carretera ve en la foto:
- Suelo / Escombros
- Adoquines, tejas, pavimento
- Rieles, vías férreas
- Agua, grandes charcos
- Asfalto
- No hay camino en la foto / Objetos extraños / La cobertura no es visible debido a los automóviles
Si el artista eligió "Asphalt", aparecerá un menú que ofrece evaluar su calidad:
- Excelente cobertura
- Grietas simples leves / baches simples poco profundos
- Grietas grandes / grietas de rejilla / baches menores simples
- Grandes baches / baches profundos / revestimiento destruido
Como mostraron las ejecuciones de prueba de las tareas, los ejecutantes de Y. Toloki no difieren en la integridad del trabajo: accidentalmente hacen clic en los campos con el mouse y consideran la tarea completada. Tuve que agregar preguntas de control (en la tarea había 46 fotografías, 12 de las cuales eran de control) y permitir la aceptación tardía. Como preguntas de control, utilicé esas imágenes que marqué yo mismo. Automaticé la aceptación tardía: Y. Toloka le permite cargar los resultados del trabajo en un archivo CSV y cargar los resultados de la verificación de las respuestas. La verificación de las respuestas funcionó de la siguiente manera: si la tarea contiene más del 5% de respuestas incorrectas para controlar las preguntas, entonces se considera incompleta. Además, si el contratista indicó una respuesta que es lógicamente cercana a verdadera, entonces su respuesta se considera correcta.
Como resultado, obtuve unas 30 mil fotos etiquetadas, que decidí distribuir en tres clases para capacitación:
- "Bueno": fotos etiquetadas como "Asfalto: revestimiento excelente" y "Asfalto: grietas simples menores"
- "Medio" - fotos con la etiqueta "Adoquines, azulejos, pavimento", "rieles, vías de ferrocarril" y "Asfalto: grietas grandes / grietas en la rejilla / baches menores"
- “Grande”: fotos etiquetadas como “Suelo / piedra triturada”, “Agua, charcos grandes” y “Asfalto: una gran cantidad de baches / baches profundos / pavimento destruido”
- Fotos etiquetadas "No hay camino en la foto / Objetos extraños / La cobertura no es visible debido a los automóviles" había muy pocos (22 piezas) y los excluí de trabajos posteriores
Desarrollo y formación de clasificadores.
Entonces, los datos se recopilan y etiquetan, procedemos al desarrollo del clasificador. Por lo general, para las tareas de clasificación de imágenes, especialmente cuando se entrena en conjuntos de datos pequeños, se usa un codificador convolucional listo para usar, a cuya salida se conecta un nuevo clasificador. Decidí usar un clasificador simple sin una capa oculta, una capa de entrada de tamaño 128 y una capa de salida de tamaño 3. Decidí usar varias opciones preparadas formadas en ImageNet como codificadores:
- Xception
- Resnet
- Inicio
- Vgg16
- Densenet121
- Mobilenet
Aquí está la función que crea el modelo Keras con el codificador dado:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Para el entrenamiento, utilicé un generador con aumento (dado que las capacidades del aumento incorporado en Keras me parecían insuficientes, utilicé la biblioteca
Augmentor ):
- Pendientes
- Distorsión aleatoria
- Vueltas
- Cambio de color
- Turnos
- Cambiar contraste y brillo
- Agregar ruido aleatorio
- Recortar
Después del aumento, las fotos se veían así:

Código generador:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
El código muestra que el aumento no se usa para los datos de prueba.
Con un generador sintonizado, puede comenzar a entrenar el modelo, lo llevaremos a cabo en dos etapas: primero, solo entrene nuestro clasificador, luego todo el modelo.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Llame a full_fit () y espere. Estamos esperando por mucho tiempo.
Como resultado, tendremos seis modelos entrenados, verificaremos la precisión de estos modelos en una parte separada de los datos etiquetados; Recibí lo siguiente:
Nombre del modelo
| Precisión%
|
Xception
| 87,3
|
Resnet
| 90,8
|
Inicio
| 90,2
|
Vgg16
| 89,2
|
Densenet121
| 90,6
|
Mobilenet
| 86,5
|
En general, no mucho, pero con una muestra de entrenamiento tan pequeña, uno no puede esperar más. Para aumentar ligeramente la precisión, combiné las salidas de los modelos promediando:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
La precisión resultante fue del 91,3%. En este resultado, decidí parar.
Usando clasificador
Finalmente, el clasificador está listo y se puede poner en acción. Preparo los datos de entrada y ejecuto el clasificador: se ha procesado un poco más de un día y 1,7 millones de fotos. Ahora la parte divertida son los resultados. Inmediatamente traiga las primeras y últimas diez ciudades en el número relativo de carreteras con buena cobertura:

Mesa completa (imagen en la que se puede hacer clic) Y aquí está la calificación de la calidad del camino por temas federales:
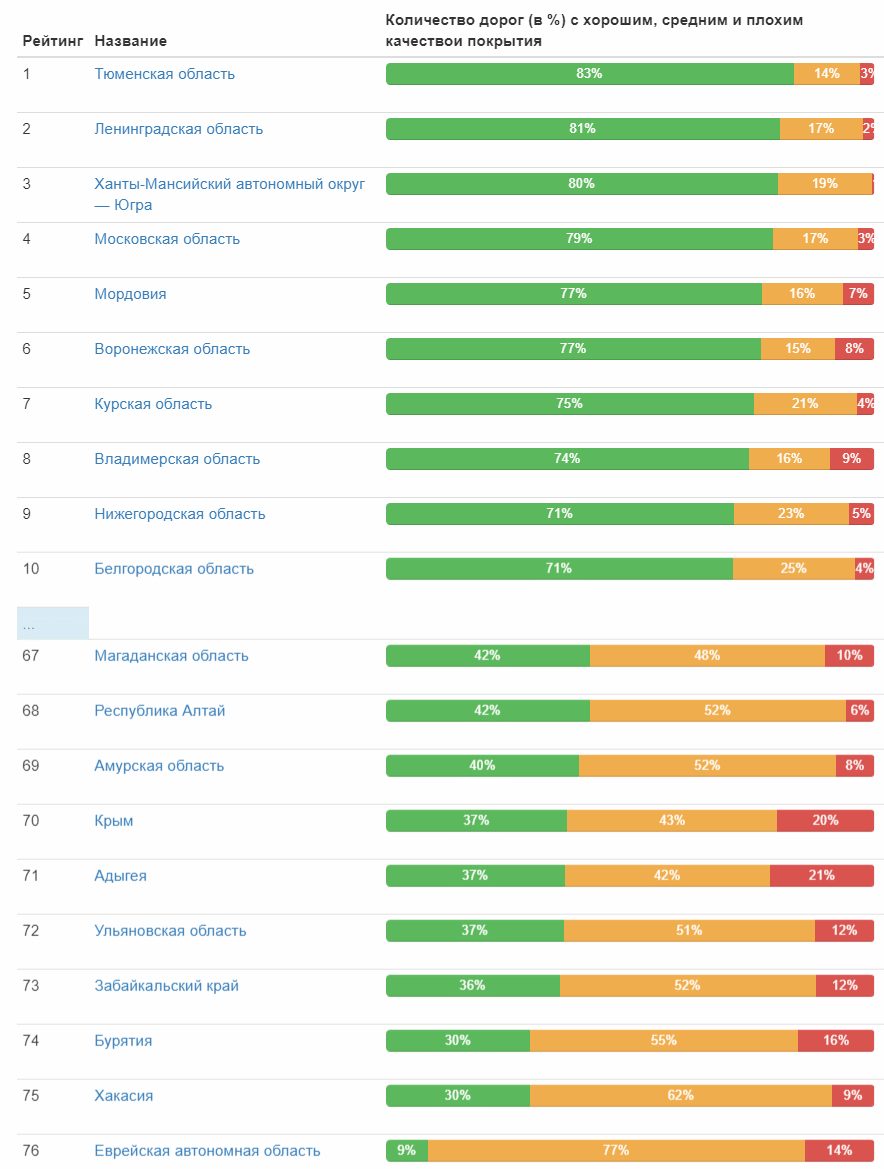
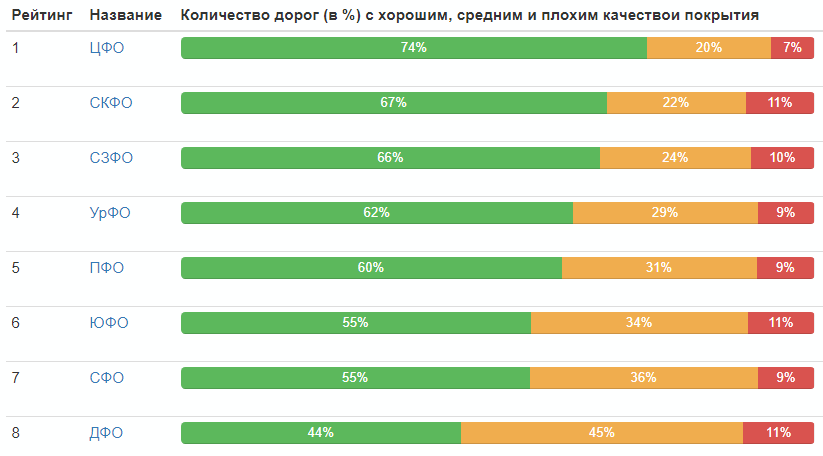
Calificación por distritos federales:
Distribución de la calidad de la carretera en Rusia en su conjunto:

Bueno, eso es todo, todos pueden sacar conclusiones por sí mismos.
Finalmente, daré las mejores fotos en cada categoría (que recibió el valor máximo en su clase):
PD: En los comentarios, con bastante razón señaló la falta de estadísticas sobre los años de recepción de las fotografías. Corrijo y doy una tabla:
Año
| Número de fotos, piezas
|
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148
|
| 2014 | 141021
|
| 2015 | 46143
|
| 2016 | 410385
|
| 2017 | 324279
|
| 2018 | 581961
|