Números de latencia que todo programador debe saber : una tabla de "demoras que todo programador debe saber". Contiene los valores promedio de tiempo para realizar operaciones informáticas básicas en 2012. Hay varias vistas alternativas para esta tabla, y aquí está una de ellas.
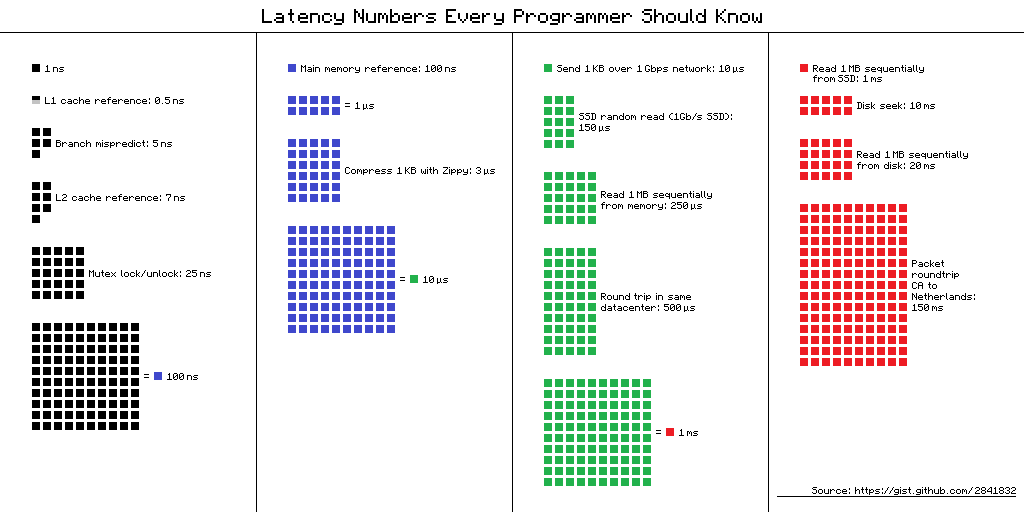 Enlace al origen del esquema
Enlace al origen del esquema¿Pero cuál es el beneficio para los desarrolladores móviles de esta información en 2019? Parece que no, pero
Dmitry Kurkin (
SClown ) del equipo Yandex.Navigator pensó: "¿Cómo sería la mesa para un iPhone moderno?" Lo que surgió de esto, en una versión de texto revisada del informe de Dmitry en
AppsConf .
¿Para qué es esto?
¿Por qué los programadores deben saber estos números? ¿Y son relevantes para los desarrolladores móviles? Hay dos tareas principales que se pueden resolver con la ayuda de estos números.
Comprender la escala de tiempo de una computadora
Tome una situación simple: una conversación telefónica. Podemos decir fácilmente cuándo este proceso es rápido y cuándo es largo: un par de segundos es muy rápido, unos minutos es una conversación promedio y una hora o más es muy largo. Con la carga de páginas, es similar: en menos de un segundo, rápidamente, unos segundos, soportable, y un minuto es un desastre, el usuario puede no esperar la descarga.
Pero, ¿qué pasa con operaciones como agregar un número a una matriz, la "inserción rápida" de la que a veces a la gente le gusta hablar en las entrevistas? ¿Cuánto cuesta en un teléfono inteligente? ¿Nanosegundos, microsegundos o milisegundos? He conocido a pocas personas que podrían decir que 1 milisegundo es mucho tiempo, pero en nuestro caso es así.
La relación de la velocidad de varios componentes de la computadora
El tiempo de ejecución de las operaciones en varios dispositivos puede variar decenas o cientos de veces. Por ejemplo, el tiempo de acceso a la memoria principal es 100 veces diferente al acceso al caché L1. Esta es una gran diferencia, pero no infinita. Si tenemos un significado específico para esto, entonces, al optimizar nuestras aplicaciones, podemos evaluar si habrá una ganancia de tiempo o no.

"Números de latencia" en la vida real
Cuando vi estos números, me interesó la diferencia entre el acceso a la memoria caché y la memoria. Si pongo cuidadosamente mis datos en 64 Kbytes, que no es tan pequeño, entonces mi código funcionará 100 veces más rápido: ¡es rápido, todo volará!

Inmediatamente quise comprobarlo todo, mostrárselo a mis colegas y aplicarlo siempre que sea posible. Decidí comenzar con la herramienta estándar que ofrece Apple: XCTest con measureBlock. La prueba se organizó de la siguiente manera: asignó una matriz, la llenó de números, su XOR'il y repitió el algoritmo 10 veces, seguro. Después de eso, miré cuánto tiempo lleva un elemento.
| Tampón | Tiempo total | Tiempo para la cirugía |
| 50 kb | 1,5 ms | 30 ns |
| 500 kb | 12 ms | 24 ns |
| 5000 kb | 85 ms | 17 ns |
El tamaño del búfer aumentó 100 veces, y el tiempo para la operación no solo no aumentó 100 veces, sino que disminuyó casi 2 veces.
Señores, oficiales, ¿nos traicionaron?Después de tal resultado, surgieron grandes dudas en mí de que estos números se pueden ver en la vida real. Puede que no sea posible que una aplicación regular detecte esta diferencia. O tal vez en la plataforma móvil todo es diferente.
Comencé a buscar una manera de ver la diferencia en el rendimiento entre cachés y memoria principal. Durante la búsqueda, me encontré con un artículo en el que el autor se quejaba de que tenía un punto de referencia en su Mac y iPhone y no mostraba estos retrasos. Tomé esta herramienta y obtuve el resultado, al igual que en una farmacia. El tiempo de acceso a la memoria aumentó claramente cuando el tamaño del búfer excedió el tamaño de la caché correspondiente.
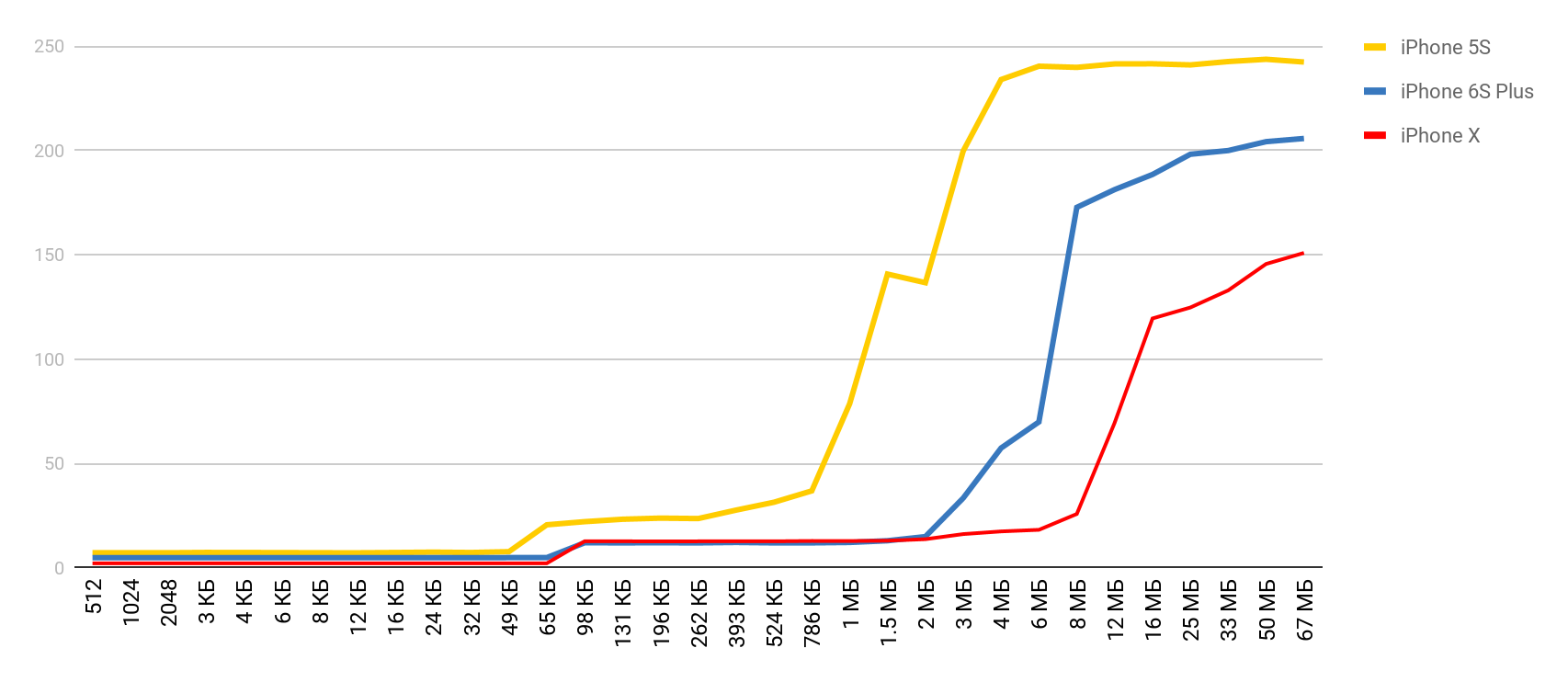 LMbench
LMbench me ayudó a obtener estos resultados. Este es un punto de referencia creado por Larry McVoy, uno de los desarrolladores del kernel de Linux, que le permite medir el tiempo de acceso a la memoria, el costo de cambiar los hilos y las operaciones del sistema de archivos, e incluso el tiempo que toman las operaciones del procesador principal: suma, resta, etc. De acuerdo con este punto de referencia Texas Instruments presentó
datos de medición
interesantes para sus procesadores. LMBench está escrito en C, por lo que no fue difícil ejecutarlo en iOS.
Costos de memoria
Armado con una herramienta tan maravillosa, decidí hacer mediciones similares, pero para un dispositivo móvil real, para el iPhone. Las mediciones principales se realizaron en el 5S, y luego obtuve los resultados cuando otros dispositivos cayeron en mis manos. Por lo tanto, si el dispositivo no se especifica, entonces es 5S.
Acceso a la memoria
Para esta prueba, se utiliza una matriz especial, que se llena con elementos que se refieren entre sí. Cada uno de los elementos es un puntero a otro elemento. La matriz no está atravesada por índice, sino por transiciones de un nodo a otro. Estos elementos están dispersos en la matriz para que, al acceder a un nuevo elemento, con la mayor frecuencia posible no esté en la memoria caché, sino que se descargue de la RAM. Esta disposición interfiere con los cachés tanto como sea posible.
Ya has visto el resultado preliminar. En el caso de la caché L1, es inferior a 10 nanosegundos, para L2 es un par de decenas de nanosegundos, y en el caso de la memoria principal, el tiempo aumenta a cientos de nanosegundos.
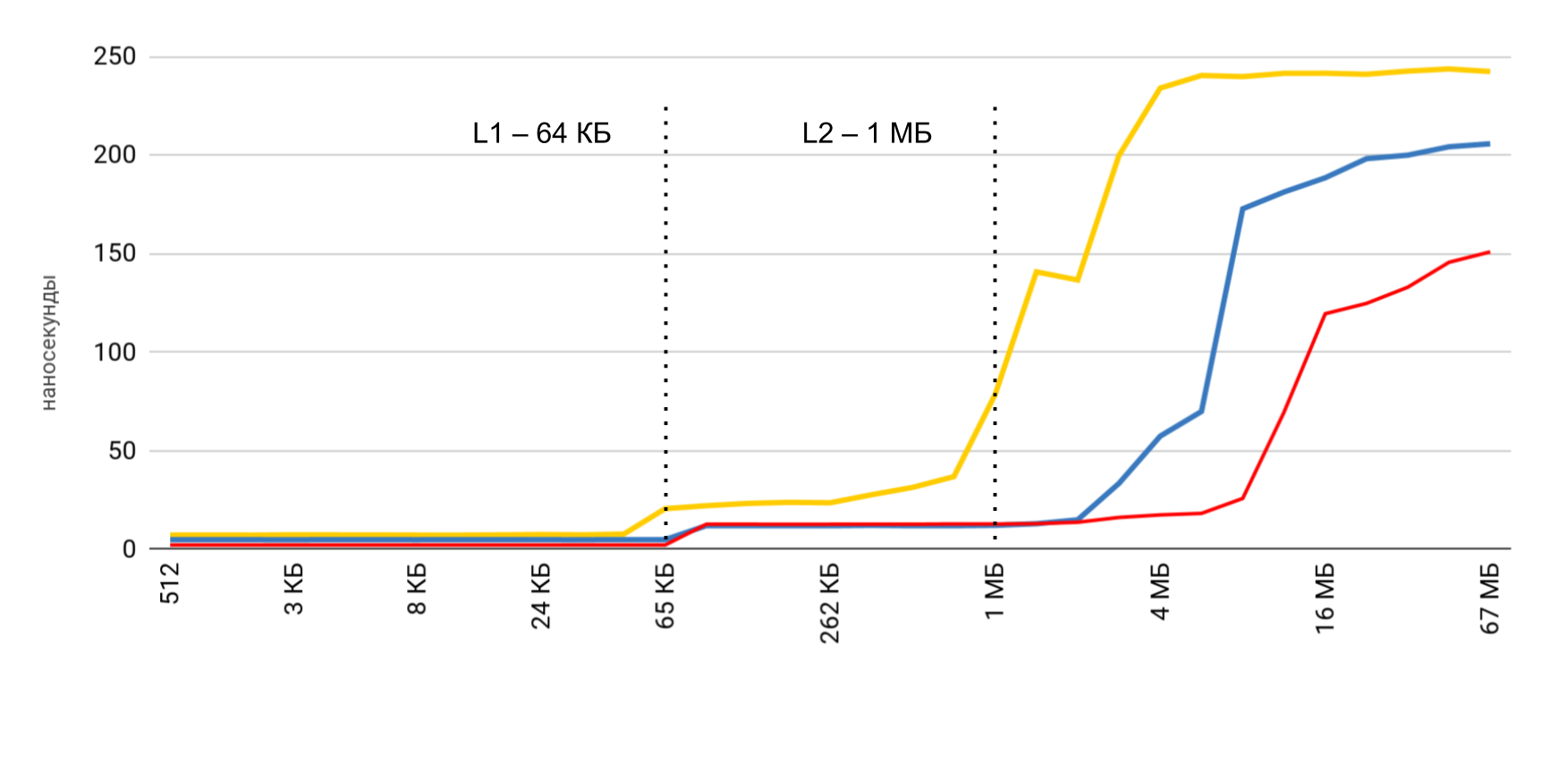
Leer y escribir velocidad
Se miden tres operaciones principales:
- lectura ( p [i] + ): leemos los elementos y los sumamos a la cantidad total;
- record ( p [i] = 1 ): se escribe un número constante en cada elemento;
- lectura y escritura ( p [i] = p [i] * 2 ): sacamos el elemento, lo cambiamos y escribimos el nuevo valor.
Cuando se trabaja con el búfer, se usan 2 enfoques: en el primer caso, solo se usa cada cuarto elemento, y en el segundo, todos los elementos son secuencialmente.
La velocidad más alta se obtiene con un tamaño de búfer pequeño, y luego hay pasos claros, de acuerdo con los tamaños de los cachés L1 y L2. Lo más interesante es que cuando los datos se leen secuencialmente, no se produce una reducción de la velocidad. Pero en el caso de los pases, los pasos claros son visibles.
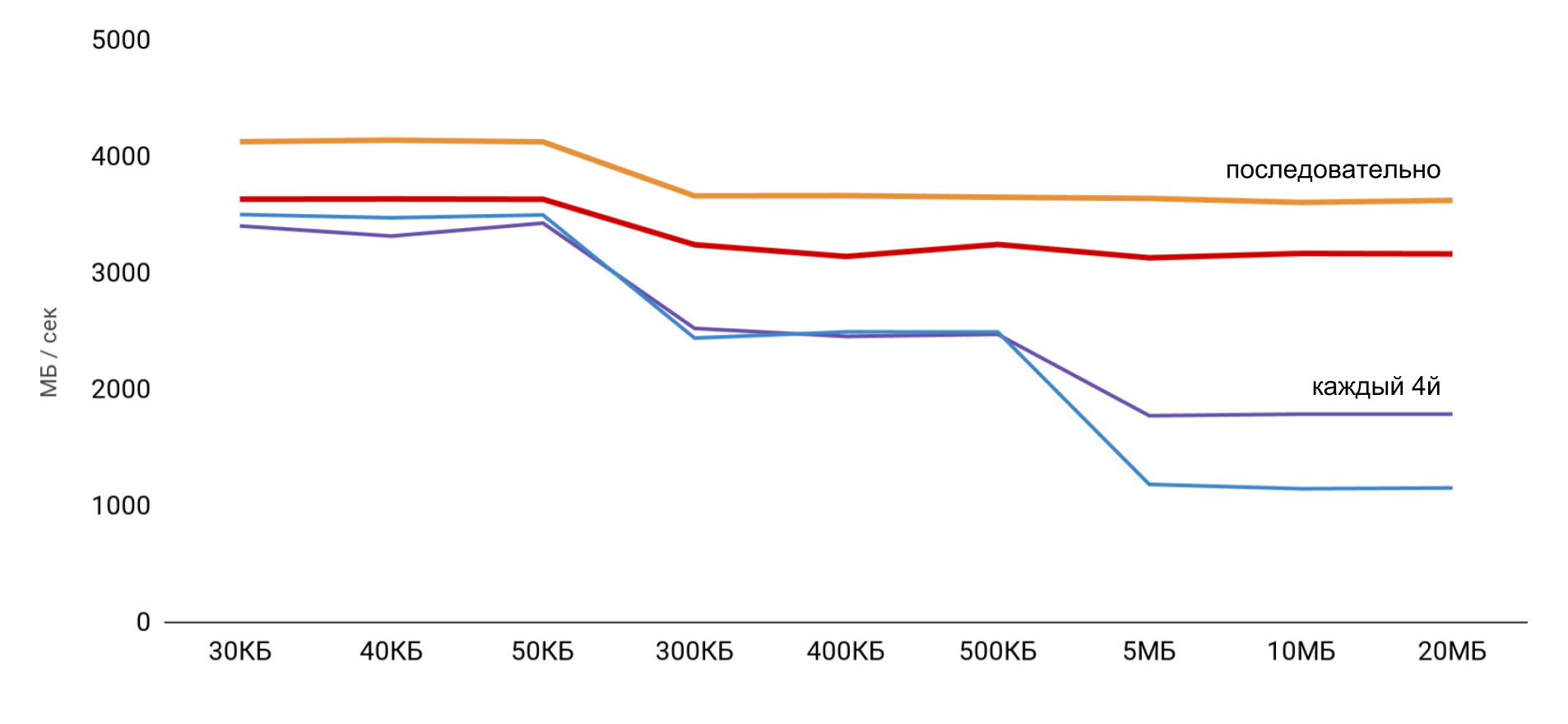
Durante la lectura secuencial, el sistema operativo logra cargar los datos necesarios en la memoria caché, por lo que para cualquier tamaño de búfer no necesito acceder a la memoria: todos los datos necesarios se obtienen de la memoria caché. Esto explica por qué no vi la diferencia horaria en mi prueba básica.
Los resultados de las mediciones de las operaciones de lectura y escritura mostraron que en una aplicación normal es bastante difícil obtener la aceleración estimada de 100 veces. Por un lado, el sistema en sí almacena en caché los datos bastante bien, e incluso con matrices grandes es muy probable que encontremos datos en el caché. Y, por otro lado, trabajar con varias variables puede requerir fácilmente acceso a la memoria y la pérdida de cientos de nanosegundos ganados.
| L1 | L2 | Memoria |
| Números de latencia | 1 ns | 7 ns | 100 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns |
| iPhone X | 2 ns | 12 ns | 146 ns |
Costes de subprocesos
A continuación, quería obtener datos similares para trabajar con subprocesos para
comprender el costo del uso de subprocesos múltiples : cuánto cuesta crear un subproceso y cambiar de un subproceso a otro. Para nosotros, estas son operaciones frecuentes, y quiero entender la pérdida.
Instrumentos Sistema de seguimiento
System Trace ayuda mucho a rastrear el trabajo de los hilos en la aplicación. Esta herramienta se describió con cierto detalle en
WWDC 2016 . La herramienta ayuda a ver las transiciones por condiciones de flujo y presenta datos en flujos en tres categorías principales: llamadas al sistema, trabajo con memoria y condiciones de flujo.
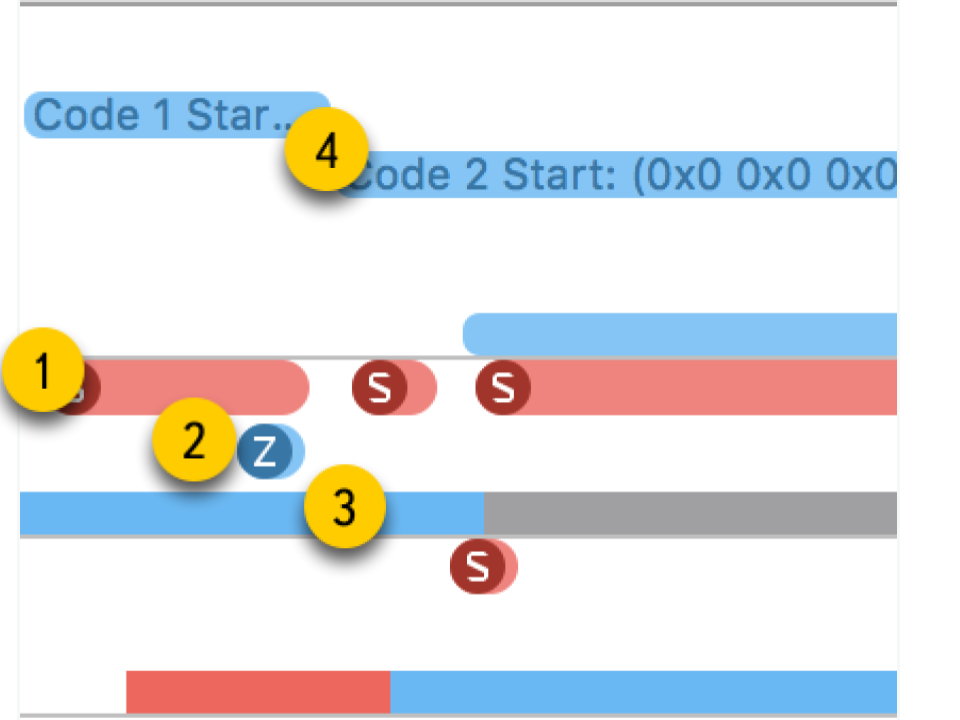
- Sistema de llamadas Se presentan en forma de "salchichas" rojas. Cuando los señala, puede ver el nombre del método del sistema y la duración de la ejecución. A menudo, en aplicaciones de aplicaciones, tal llamada al sistema no ocurre directamente: usamos algo, que a su vez ya llama al método del sistema. No debe confiar en el hecho de que aquí los métodos de su código serán visibles.
- Operaciones de memoria . Se presentan en forma de "salchichas" azules. Esto incluye operaciones como asignación de memoria, liberación, puesta a cero, etc.
- El estado de la corriente . Color azul: se está ejecutando un subproceso, algunos procesadores están ejecutando código de este subproceso. Gris: el subproceso está bloqueado por algún motivo y no puede continuar la ejecución. Rojo: el hilo está listo para funcionar, pero en este momento no hay un núcleo libre para ejecutar su código. Color naranja: el flujo se interrumpe para trabajos de mayor prioridad.
- Puntos de interes . Estas son etiquetas especiales que se pueden organizar por código llamando a
kdebug_signpost . Las etiquetas pueden ser simples (un lugar específico en el código) o como un rango (para resaltar todo el procedimiento). Usando tales etiquetas, es mucho más fácil correlacionar microsegundos y llamadas del sistema con su aplicación.
Costos de creación de flujo
La primera prueba es la
ejecución de una tarea en un nuevo hilo . Creamos un hilo con un determinado procedimiento y esperamos a que complete su trabajo. Comparando el tiempo total con el tiempo del procedimiento en sí, obtenemos la pérdida total para comenzar el procedimiento en un nuevo hilo.
En System Trace puede ver claramente cómo sucede todo:
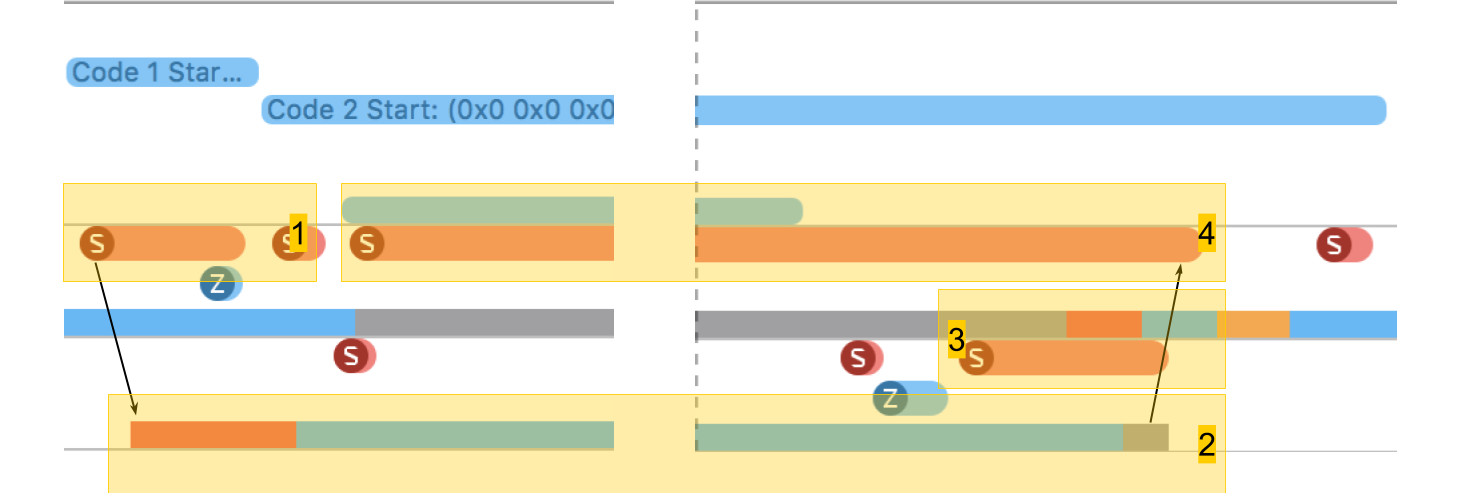
- Crear secuencia
- El nuevo hilo en el que se ejecuta nuestro procedimiento. La zona roja al principio dice que el hilo fue creado, pero durante algún tiempo no se pudo ejecutar, ya que no había núcleo libre.
- La finalización de la secuencia. Curiosamente, el procedimiento de finalización de subproceso en sí es incluso más grande que su creación. Aunque parece que eliminar siempre es más rápido.
- Esperando la finalización del procedimiento, que estaba en el esquema original, y termina después de que finaliza la secuencia, durante un tiempo el método se da cuenta de esto y, después de eso, informa. Este tiempo es un poco más largo que la finalización de la transmisión.
Como resultado, crear una transmisión requiere costos bastante significativos: iPhone 5S - 230 microsegundos, 6S - 50 microsegundos.
La finalización de la transmisión lleva casi 2 veces más tiempo que la creación , la unión también lleva un tiempo tangible. Cuando trabajamos con memoria, obtuvimos cientos de nanosegundos, que es 100 veces menos que decenas de microsegundos.
| gastos generales | crear | fin | unirse |
| iPhone 5s | 230 μs | 40 μs | 70 μs | 30 μs |
| iPhone 6s Plus | 50 μs | 12 μs | 20 μs | 7 μs |
Tiempo de cambio de semáforo
La siguiente prueba son
mediciones del trabajo del semáforo . Tenemos 2 hilos pre-creados, y para cada uno de ellos hay un semáforo. Las corrientes señalan alternativamente el semáforo del vecino y esperan el suyo. Transmitiéndose señales entre sí, las transmisiones juegan ping-pong, se reviven entre sí. Esta iteración doble proporciona un tiempo de cambio de semáforo doble.
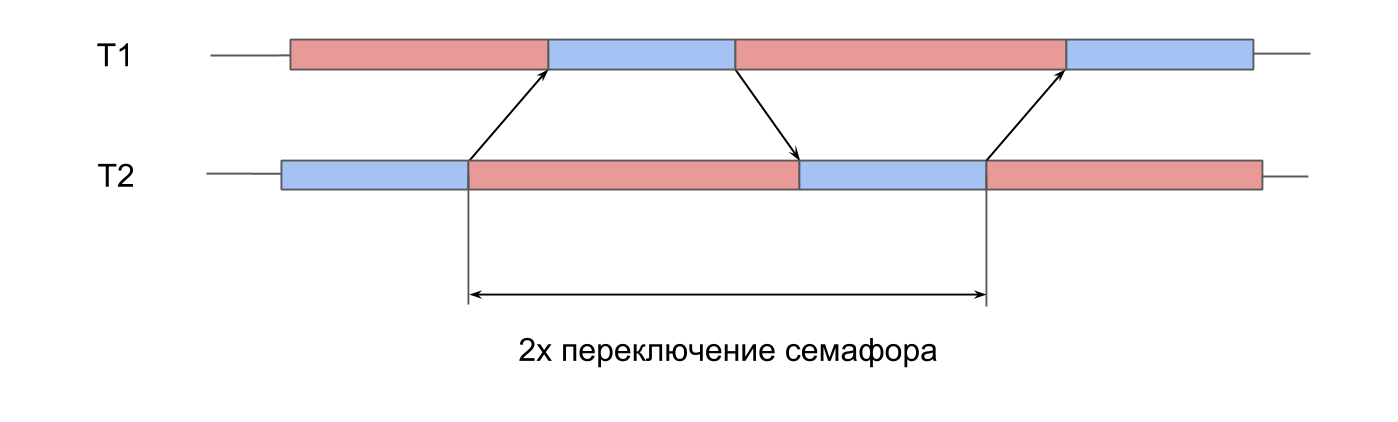
En System Trace, todo se ve similar:
- Se da una señal para el semáforo de la segunda secuencia. Se puede ver que esta operación es muy corta.
- El segundo hilo está desbloqueado, la espera en su semáforo termina.
- Se da una señal para el semáforo de la primera secuencia.
- El primer hilo se desbloquea, la espera en su semáforo termina.
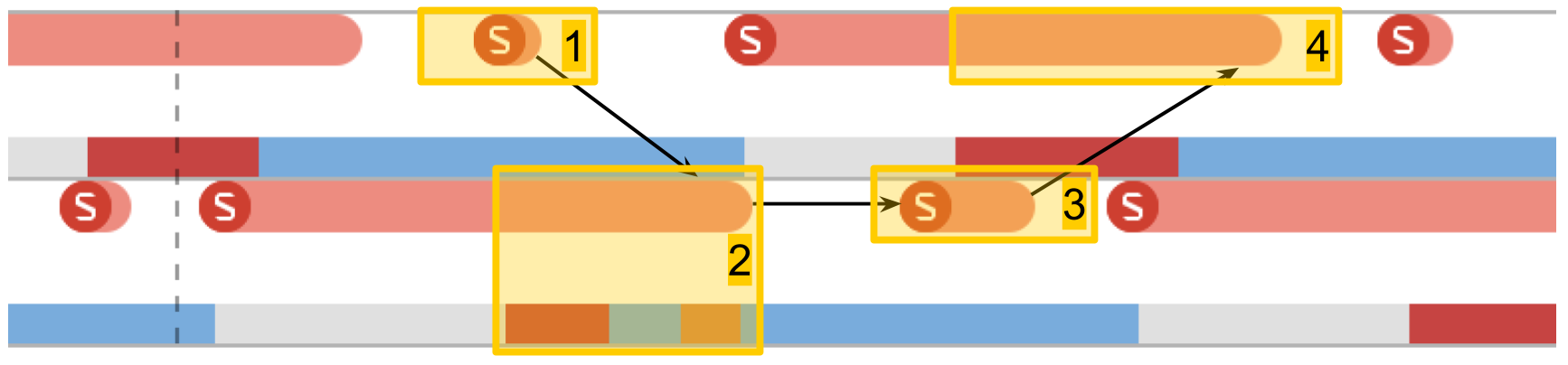
El tiempo de cambio fue de 10 microsegundos. La diferencia con la creación de un subproceso por 50 veces es exactamente la razón por la cual se crean grupos de subprocesos, y no un nuevo subproceso para cada procedimiento.
Pérdidas en el cambio de contexto del hilo del sistema
En las dos pruebas anteriores, la transferencia de control entre subprocesos estaba completamente controlada: entendimos claramente dónde y dónde debería ocurrir la transición. Sin embargo, a menudo sucede que el sistema mismo cambia de un hilo a otro. Cuando ejecutamos más tareas en paralelo que los núcleos en el dispositivo, el sistema operativo debe poder cambiarse para proporcionar a todos tiempo de procesador.
En esta prueba, quería medir la pérdida de iniciar demasiados hilos. Para hacer esto, se crea un grupo de 16 subprocesos, cada uno de los cuales espera un semáforo, y, tan pronto como recibe una señal, realiza un cierto procedimiento y envía la señal al semáforo. El subproceso principal inicia todo el grupo, dando 16 señales, y luego espera 16 señales en respuesta.
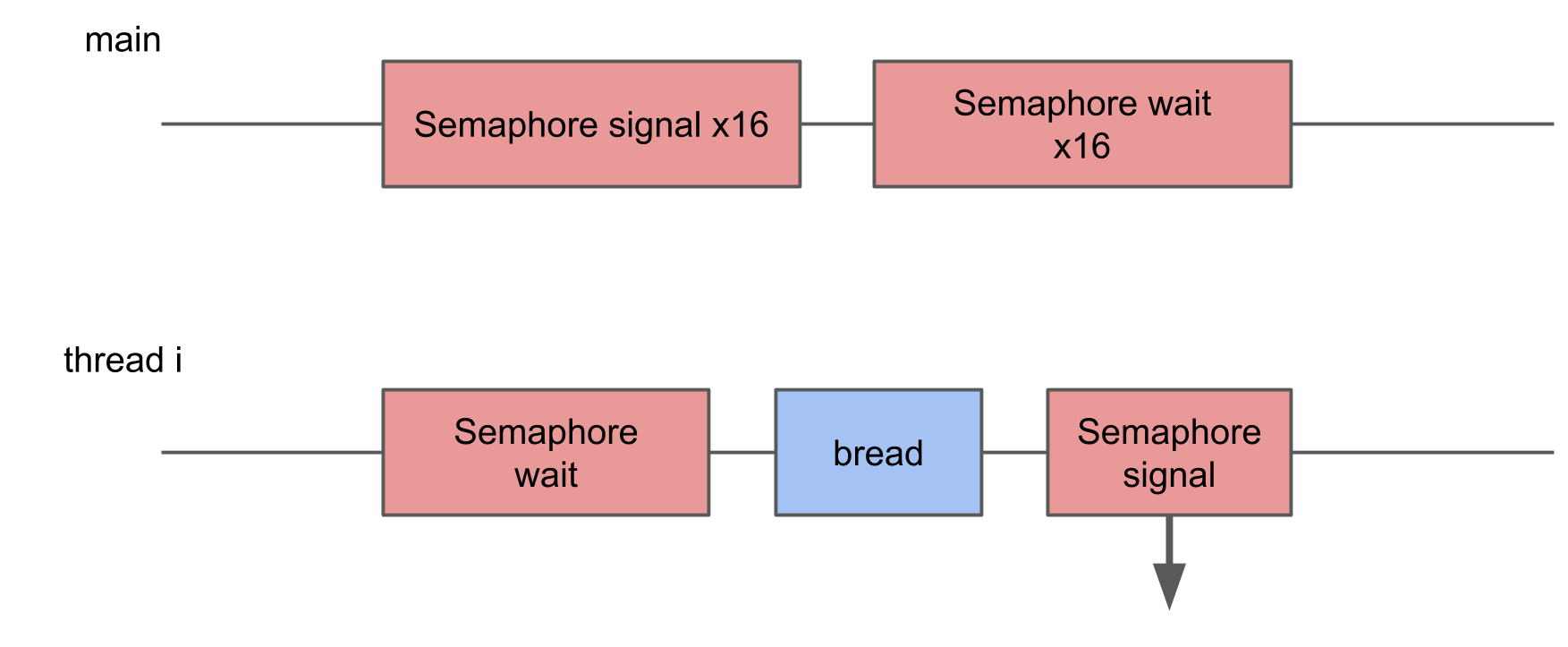
En System Trace puede ver que los bloques están dispersos al azar, algunos de ellos son mucho más largos que el resto. Si la conmutación múltiple conduce a un aumento en el tiempo de ejecución de la operación, entonces el tiempo promedio de ejecución debería aumentar como resultado.
Sin embargo, con un aumento en el número de subprocesos, el tiempo de operación promedio no aumenta.En teoría, el tiempo promedio debe mantenerse siempre que la carga corresponda a la potencia de procesamiento. Es decir, el número de tareas corresponde al número de núcleos.
Si ejecuta muchas tareas en paralelo, el sistema operativo, al cambiar de una tarea a otra, introducirá demoras adicionales. Esto debería reflejarse en el resultado.
En la práctica, no solo nuestra aplicación funciona en el dispositivo, sino que también tiene muchos procesos paralelos y del sistema. Incluso el único hilo en nuestra aplicación se verá afectado por el cambio, lo que conduce a interrupciones y demoras. Por lo tanto, en todas las situaciones hay demoras y no hay diferencia entre construir tareas en serie o ejecutarlas en paralelo.

A continuación se muestra nuestra tabla de números de latencia con datos sobre flujos y semáforos.
| L1 | L2 | Memoria | Semáforo |
| Números de latencia | 1 ns | 7 ns | 100 ns | 25 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs |
Costos de archivo
Ya tenemos memoria y subprocesos; para completar, solo necesitamos operaciones del sistema de archivos.
Leer archivo
La primera prueba es
la velocidad de lectura : cuánto cuesta leer un archivo. La prueba consta de dos partes. En el primero,
medimos la velocidad de lectura teniendo en cuenta la apertura, lectura y cierre del archivo. En el segundo,
suponemos que el archivo está constantemente abierto : nos posicionamos en algún lugar y leemos todo lo que queremos.
Los resultados se ven correctamente desde dos puntos de vista.
Cuando el archivo es pequeño , hay un tiempo mínimo para leer los datos del archivo. Hasta un kilobyte son 5.3 microsegundos, no importa: 1 byte, 2 o 1 KB, para todos los 5.3 μs. Por lo tanto, puede hablar de velocidad solo en el caso de archivos grandes, cuando el tiempo fijo ya puede ser descuidado. La operación para abrir y cerrar el archivo tarda aproximadamente el mismo tiempo para cualquier tamaño de archivo, en el caso de 5S, aproximadamente 50 microsegundos.
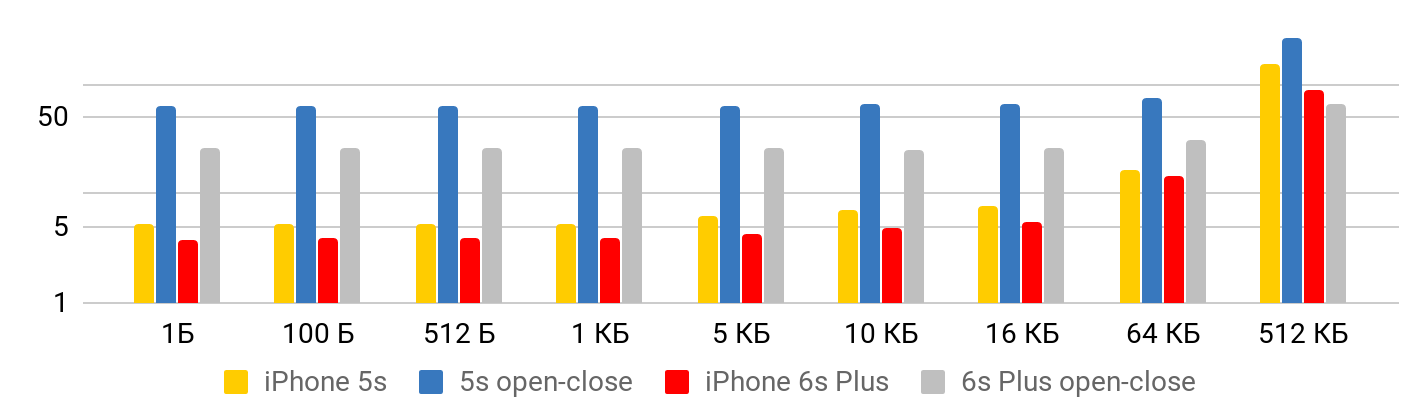
Para la velocidad de lectura, se obtienen tales gráficos.
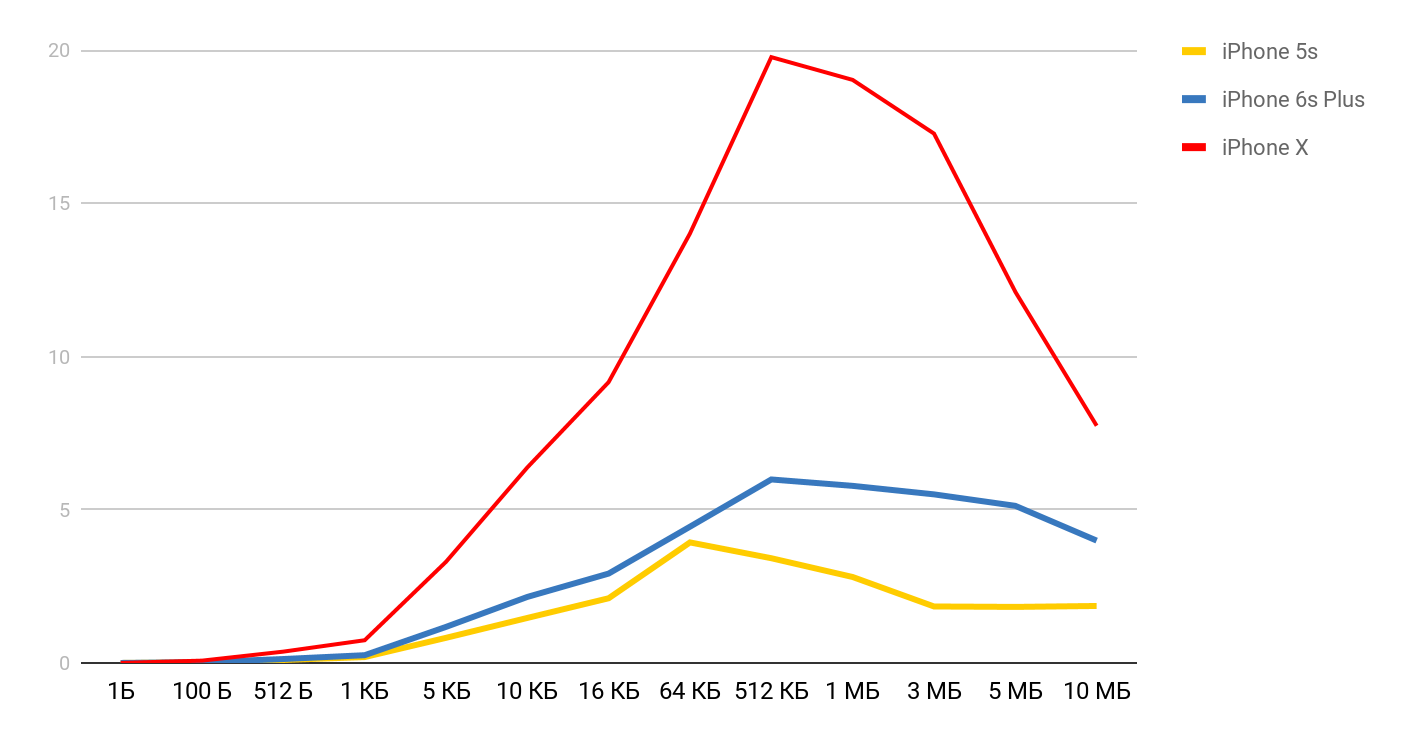
Para iPhone X y un archivo de 1 MB, la velocidad puede alcanzar los 20 MB / s. Curiosamente, leer un archivo de 1 MB es más eficiente. Con tamaños de archivo grandes, los tamaños de caché parecen verse afectados. Es por eso que la velocidad baja aún más y se iguala en la región de 10 Mb.
Crea y elimina archivos
La prueba consiste en el paso de
crear un archivo y escribir datos , y
eliminar los archivos creados. El resultado es paso a paso: en tamaños pequeños, el tiempo es estable: alrededor de 7 μs y sigue creciendo. La escala es logarítmica.
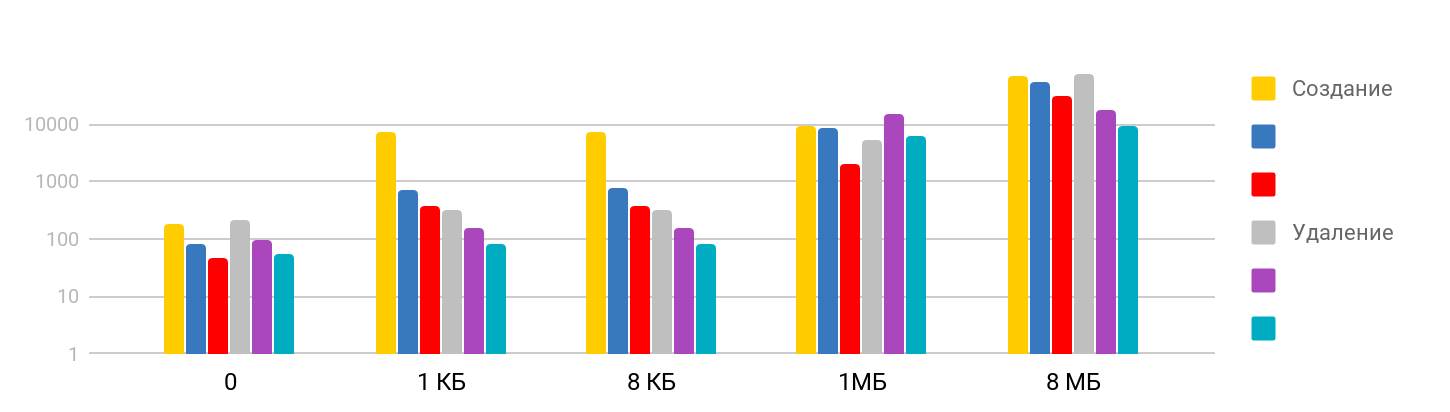
Me sorprendió que el tiempo que lleva eliminar un archivo grande es proporcional al tiempo que llevó crear, ya que supuse que eliminar es una operación rápida. Resulta que no, para iPhone, eliminar a tiempo es comparable a crear un archivo. La tabla resumen se ve así.
| L1 | L2 | Memoria | Semáforo | Disco |
| Números de latencia | 1 ns | 7 ns | 100 ns | 25 ns | 150 μs |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs | 5 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs | 4 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs | 1.3 μs |
Conclusión
En base a estas mediciones, ahora tenemos una idea de cuánto tiempo requieren las operaciones básicas de iOS: acceder a la memoria es de nanosegundos, trabajar con archivos es de microsegundos, crear una secuencia de decenas de microsegundos, y el cambio es de solo unos pocos microsegundos.
Para obtener un bloqueo físicamente notable en la aplicación, el tiempo de ejecución del procedimiento debe superar los 15 milisegundos (el tiempo que lleva actualizar la pantalla a 60 fps). Esto es casi mil veces mayor que la mayoría de las medidas tomadas en el artículo. En tal escala, un milisegundo es bastante, y un segundo ya es "para siempre".
Las pruebas mostraron que, a pesar de la gran diferencia en el tiempo de acceso a la memoria y las memorias caché, el uso directo de esta relación es bastante difícil. Antes de compilar todos sus datos en L1, debe asegurarse de que en su caso realmente dará un resultado.
Según las pruebas de operaciones con subprocesos, pudimos asegurarnos de que crear y destruir subprocesos requiere una cantidad considerable de tiempo, pero realizar una gran cantidad de operaciones paralelas no conlleva costos adicionales.
Bueno, en conclusión, me gustaría recordarle la regla más importante cuando trabaje en el rendimiento: ¡
primero mediciones y solo luego optimización !
Perfil del orador Dmitry Kurkin en
GitHub .
La conversión y transformación de los informes de AppsConf 2018 en artículos va en paralelo con la preparación de la nueva conferencia de 2019. Hasta el momento, solo hay 7 temas en la lista de informes aceptados , pero esta lista se ampliará todo el tiempo para que tenga lugar una conferencia genial para desarrolladores móviles del 22 al 23 de abril .
Siga las publicaciones, suscríbase al canal de YouTube y al boletín informativo y esta vez volará rápidamente.