Los autos no tripulados no pueden prescindir de comprender qué hay alrededor y dónde exactamente. En diciembre del año pasado, el desarrollador Victor Otliga
vitonka hizo una presentación sobre la detección de objetos 3D en
el árbol de Navidad de datos . Victor trabaja en la dirección de vehículos no tripulados Yandex, en el grupo que maneja la situación del tráfico (y también enseña en el ShAD). Explicó cómo resolvemos el problema de reconocer a otros usuarios de la carretera en una nube de puntos tridimensional, cómo este problema difiere del reconocimiento de objetos en una imagen y cómo beneficiarse de compartir diferentes tipos de sensores.
- Hola a todos! Mi nombre es Victor Otliga, trabajo en la oficina de Yandex en Minsk y estoy desarrollando vehículos no tripulados. Hoy hablaré sobre una tarea bastante importante para los drones: el reconocimiento de los objetos 3D que nos rodean.

Para montar, necesitas entender lo que hay alrededor. Te diré brevemente qué sensores y sensores se usan en vehículos no tripulados y cuáles usamos. Te diré cuál es la tarea de detectar objetos 3D y cómo medir la calidad de la detección. Luego te diré en qué se puede medir esta calidad. Y luego haré una breve revisión de buenos algoritmos modernos, incluidos aquellos en los que se basan nuestras soluciones. Y al final, pequeños resultados, una comparación de estos algoritmos, incluido el nuestro.

Así es como se ve nuestro prototipo funcional de un automóvil no tripulado ahora. Tal taxi puede ser alquilado por cualquier persona sin conductor en la ciudad de Innopolis en Rusia, así como en Skolkovo. Y si te fijas bien, hay un gran dado en la parte superior. ¿Qué hay adentro?

Dentro de un conjunto simple de sensores. Hay una antena GNSS y GSM para determinar dónde está el automóvil y para comunicarse con el mundo exterior. Donde sin un sensor tan clásico como una cámara. Pero hoy nos interesarán los lidares.


Lidar produce aproximadamente una nube de puntos a su alrededor, que tiene tres coordenadas. Y tienes que trabajar con ellos. Te diré cómo, usando una imagen de cámara y una nube lidar, reconocer cualquier objeto.
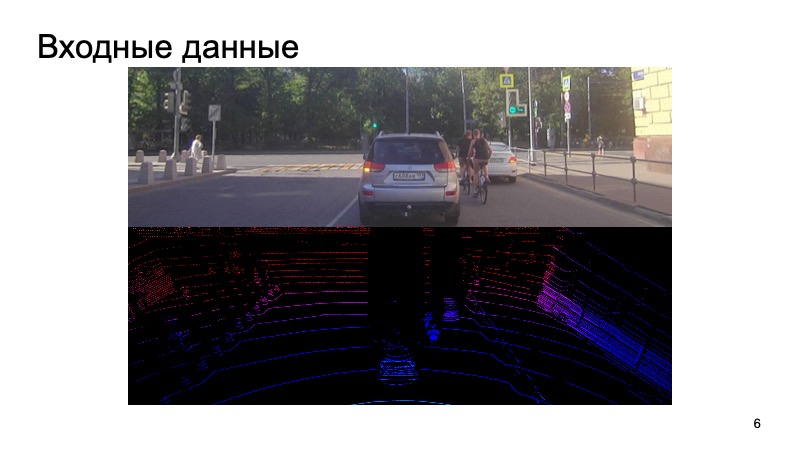
¿Cuál es el desafío? Se ingresa la imagen de la cámara, la cámara se sincroniza con el LIDAR. Sería extraño usar la imagen de la cámara hace un segundo, tomar la nube lidar desde un momento completamente diferente e intentar reconocer objetos en ella.

Sin embargo, de alguna manera sincronizamos cámaras y lidares, esta es una tarea difícil por separado, pero lo superamos con éxito. Dichos datos ingresan la entrada, y al final queremos obtener cuadros, cuadros delimitadores que limitan el objeto: peatones, ciclistas, automóviles y otros usuarios de la carretera y no solo.
La tarea fue establecida. ¿Cómo lo evaluaremos?

El problema del reconocimiento 2D de objetos en una imagen ha sido ampliamente estudiado.
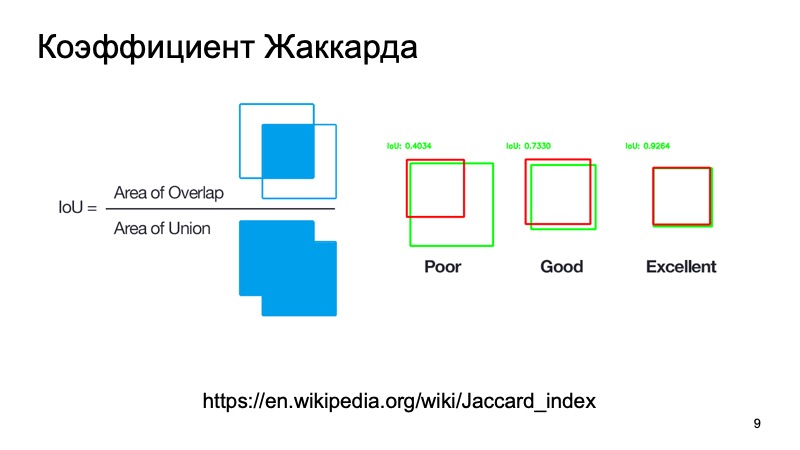
Puede usar métricas estándar o sus análogos. Hay un coeficiente Jacquard o una intersección sobre la unión, un coeficiente maravilloso que muestra qué tan bien detectamos un objeto. Podemos tomar un cuadro donde, como suponemos, se encuentra el objeto, y un cuadro donde se encuentra realmente. Cuenta esta métrica. Hay umbrales estándar; digamos que para los automóviles a menudo toman un umbral de 0.7. Si este valor es mayor que 0.7, creemos que hemos detectado con éxito el objeto, que el objeto está allí. Somos geniales, podemos ir más allá.
Además, para detectar un objeto y comprender que está en algún lugar, nos gustaría confiar en que realmente vemos el objeto allí y también medirlo. Puede medir simple, considerar la precisión promedio. Puede tomar la curva de recuperación de precisión y el área debajo de ella y decir: cuanto más grande sea, mejor.
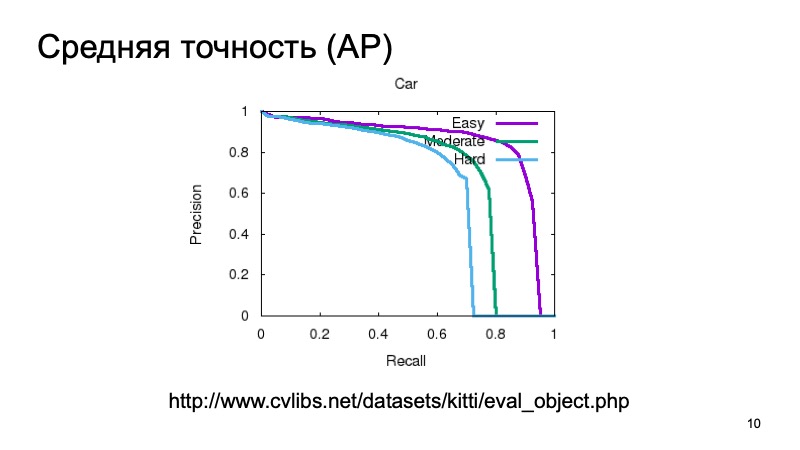
Por lo general, para medir la calidad de la detección 3D, toman un conjunto de datos y lo dividen en varias partes, ya que los objetos pueden estar cerca o más lejos, pueden estar parcialmente ocultos por otra cosa. Por lo tanto, la muestra de validación a menudo se divide en tres partes. Objetos que son fáciles de detectar, de complejidad media y complejos, distantes o que están muy oscurecidos. Y miden por separado en tres partes. Y en los resultados de la comparación, también tomaremos dicha partición.
Puede medir la calidad como en 3D, un análogo de intersección sobre unión, pero no la proporción de áreas, sino, por ejemplo, los volúmenes. Pero, por regla general, a un automóvil no tripulado no le importa lo que esté sucediendo en la coordenada Z. Podemos tomar una vista panorámica desde arriba y tomar algún tipo de métrica, como si lo estuviéramos viendo todo en 2D. El hombre se navega más o menos en 2D, y un vehículo no tripulado es el mismo. La altura de la caja no es muy importante.

¿Qué medir?

Probablemente todos los que al menos de alguna manera se enfrentaron a la tarea de detectar en 3D por la nube lidar escucharon sobre un conjunto de datos como KITTI.

En algunas ciudades de Alemania, se registró un conjunto de datos, un automóvil equipado con sensores fue, tenía sensores GPS, cámaras y lidares. Luego se marcó alrededor de 8000 escenas, y se dividió en dos partes. Una parte es la capacitación, en la cual todos pueden entrenar, y la segunda es la validación, para medir los resultados. La muestra de validación KITTI se considera una medida de calidad. En primer lugar, hay una tabla de líderes en el sitio del conjunto de datos de KITTI, puede enviar su decisión allí, sus resultados en el conjunto de datos de validación y comparar con las decisiones de otros actores o investigadores del mercado. Pero también este conjunto de datos está disponible públicamente, puede descargarlo, no decirle a nadie, verificar el suyo propio, compararlo con la competencia, pero no cargarlo públicamente.

Los conjuntos de datos externos son buenos, no tiene que gastar su tiempo y recursos en ellos, pero por regla general, un automóvil que viajó a Alemania puede estar equipado con sensores completamente diferentes. Y siempre es bueno tener su propio conjunto de datos interno. Además, es más difícil expandir un conjunto de datos externo a expensas de otros, pero es más fácil administrar el suyo propio. Por lo tanto, utilizamos el maravilloso servicio Yandex.Tolok.

Finalizamos nuestro sistema de tareas especiales. Para el usuario que quiere ayudar con el marcado y obtener una recompensa por esto, le damos una imagen de la cámara, le damos una nube lidar que puede rotar, acercar, alejar y pedirle que coloque cuadros que limiten nuestros cuadros delimitadores para que un automóvil o un peatón se meta en ellos. o algo más. Por lo tanto, recolectamos muestras internas para uso personal.
Supongamos que hemos decidido qué tarea resolveremos, cómo asumiremos que lo hicimos bien o mal. Llevamos a algún lado los datos.
¿Cuáles son los algoritmos? Comencemos con 2D. La tarea de detección 2D es muy conocida y estudiada.
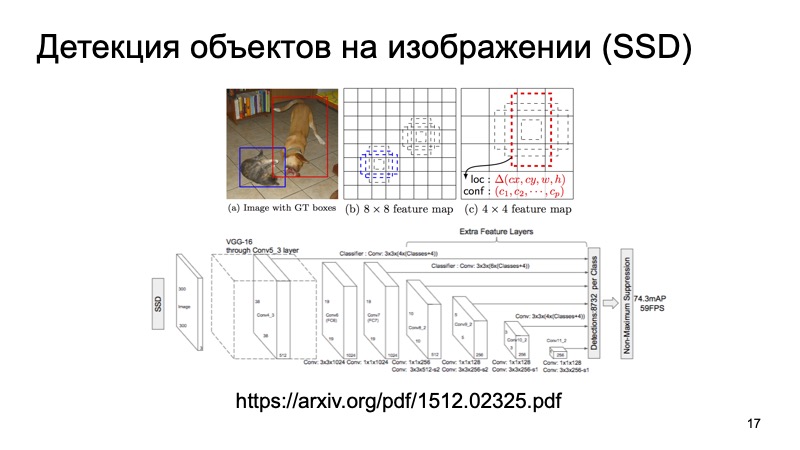
Seguramente, muchas personas conocen el algoritmo SSD, que es uno de los métodos más modernos para detectar objetos 2D y, en principio, podemos suponer que de alguna manera el problema de detectar objetos en la imagen está bastante bien resuelto. En todo caso, podemos usar estos resultados como algún tipo de información adicional.
Pero nuestra nube lidar tiene sus propias características que la distinguen en gran medida de la imagen. En primer lugar, es muy escaso. Si la imagen es una estructura densa, los píxeles están cerca, todo es denso, entonces la nube es muy delgada, no hay tantos puntos y no tiene una estructura regular. Puramente físicamente hay muchos más puntos cerca de allí que en la distancia, y cuanto más lejos vayas, menos puntos hay, menos precisión hay, más difícil es determinar algo.
Bueno, los puntos, en principio, de la nube vienen en un orden incomprensible. Nadie garantiza que un punto siempre será anterior a otro. Vienen en un orden relativamente aleatorio. De alguna manera, puede aceptar ordenarlos o reordenarlos por adelantado, y solo luego enviar modelos a la entrada, pero esto será bastante inconveniente, debe dedicar tiempo para cambiarlos, y así sucesivamente.
Nos gustaría crear un sistema que sea invariable para nuestros problemas, que resuelva todos estos problemas. Afortunadamente, el año pasado CVPR presentó dicho sistema. Había tal arquitectura: PointNet. Como trabaja ella?

Una nube de n puntos llega a la entrada, cada uno con tres coordenadas. Luego, cada punto está de alguna manera estandarizado por una pequeña transformación especial. Además, se conduce a través de una red totalmente conectada para enriquecer estos puntos con signos. Luego, nuevamente, se produce la transformación, y al final se enriquece adicionalmente. En algún momento, se obtienen n puntos, pero cada uno tiene aproximadamente 1024 características, de alguna manera están estandarizadas. Pero hasta ahora no hemos resuelto el problema con respecto a la invariancia de turnos, turnos, etc. Aquí se propone hacer una agrupación máxima, tomar el máximo entre los puntos en cada canal y obtener un vector de 1024 signos, que será un descriptor de nuestra nube, que contendrá información sobre toda la nube. Y luego con este descriptor puedes hacer muchas cosas diferentes.
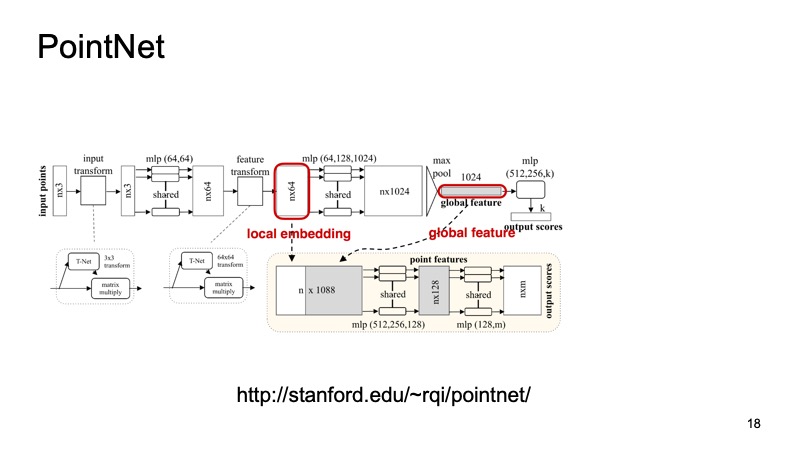
Por ejemplo, puede pegarlo a los descriptores de puntos individuales y resolver el problema de segmentación, para que cada punto determine a qué objeto pertenece. Es solo una carretera, una persona o un automóvil. Y aquí están los resultados del artículo.

Puede notar que este algoritmo hace un muy buen trabajo. En particular, me gusta mucho esa pequeña mesa en la que se arrojaron algunos de los datos sobre la encimera, y sin embargo determinó dónde están las patas y dónde está la encimera. Y este algoritmo, en particular, puede usarse como un ladrillo para construir más sistemas.
Un enfoque que utiliza esto es el enfoque Frustum PointNets o el enfoque de la pirámide truncada. La idea es algo como esto: reconozcamos los objetos en 2D, somos buenos para hacer esto.
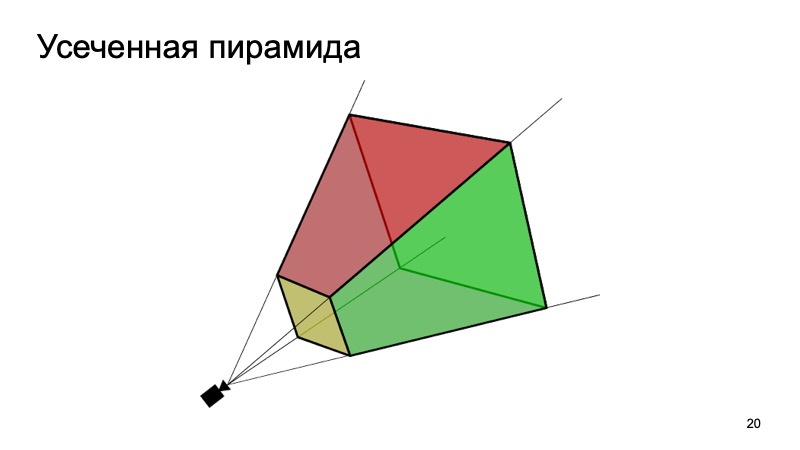
Luego, sabiendo cómo funciona la cámara, podemos estimar en qué área puede estar el objeto de interés para nosotros, la máquina. Para proyectar, corte solo esta área, y ya en ella resuelva el problema de encontrar un objeto interesante, por ejemplo, una máquina. Esto es mucho más fácil que buscar cualquier cantidad de automóviles en la nube. La búsqueda de un auto exactamente en la misma nube parece ser mucho más clara y eficiente.
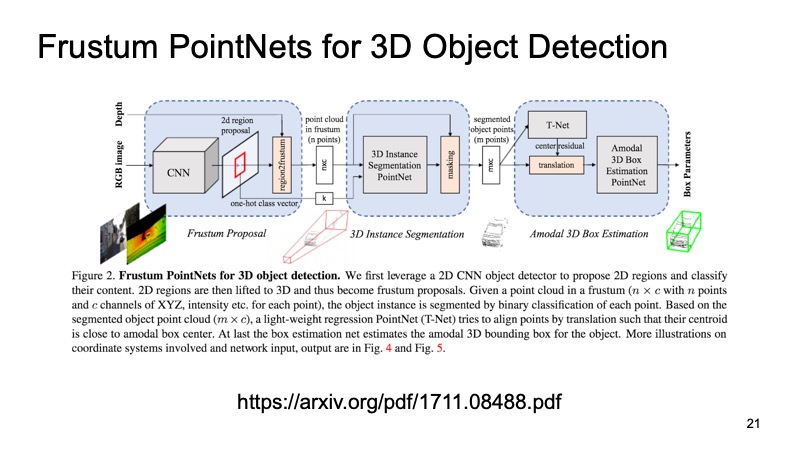
La arquitectura se parece a esto. Primero, de alguna manera seleccionamos las regiones que nos interesan, en cada región hacemos segmentación, y luego resolvemos el problema de encontrar un cuadro delimitador que limite el objeto que nos interesa.

El enfoque ha demostrado su eficacia. En las imágenes se puede ver que funciona bastante bien, pero también tiene inconvenientes. El enfoque es de dos niveles, por eso puede ser lento. Primero debemos aplicar redes y reconocer objetos 2D, luego cortar y luego resolver la segmentación y la asignación del cuadro delimitador en una parte de la nube, para que pueda funcionar un poco lentamente.
Otro enfoque ¿Por qué no convertimos nuestra nube en algún tipo de estructura que se parece a una imagen? La idea es esta: echemos un vistazo desde arriba y pruebe nuestra nube lidar. Obtenemos cubos de espacios.
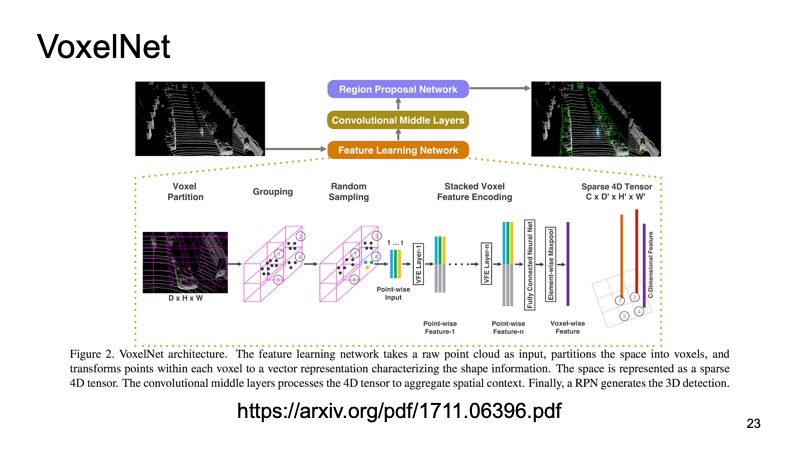
Dentro de cada cubo tenemos algunos puntos. Podemos contar algunas características en ellas, pero podemos usar PointNet, que para cada espacio contará algún tipo de descriptor. Obtendremos un vóxel, cada vóxel tiene una descripción característica, y se verá más o menos como una estructura densa, como una imagen. Ya podemos hacer diferentes arquitecturas, por ejemplo, arquitectura tipo SSD para detectar objetos.
El último enfoque, que fue uno de los primeros enfoques para combinar datos de múltiples sensores. Sería un pecado usar solo datos LIDAR cuando también tenemos datos de la cámara. Uno de estos enfoques se llama Red de detección de objetos 3D de vista múltiple. Su idea es esta: alimentar tres canales de datos de entrada a la entrada de una red grande.
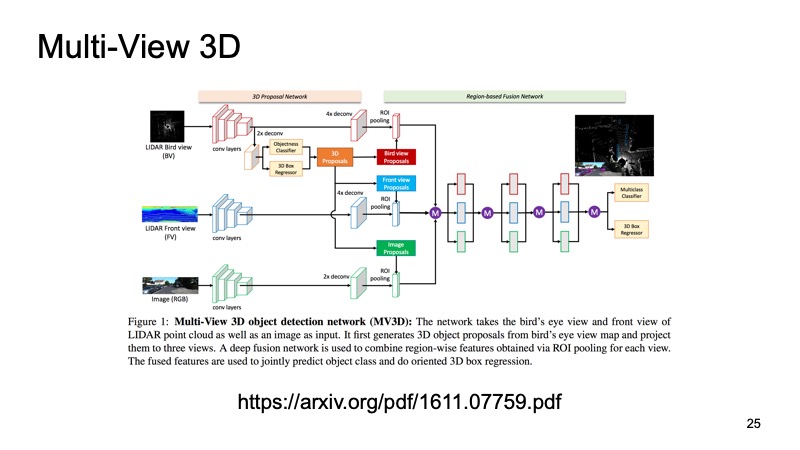
Esta es una imagen de la cámara y, en dos versiones, una nube lidar: desde arriba, con una vista de pájaro y algún tipo de vista frontal, lo que vemos frente a nosotros. Enviamos esto a la entrada de la neurona, y configurará todo dentro de sí mismo, nos dará el resultado final: el objeto.
Quiero comparar estos modelos. En el conjunto de datos KITTI, en las unidades de validación, la calidad se evalúa como un porcentaje en la precisión promedio.
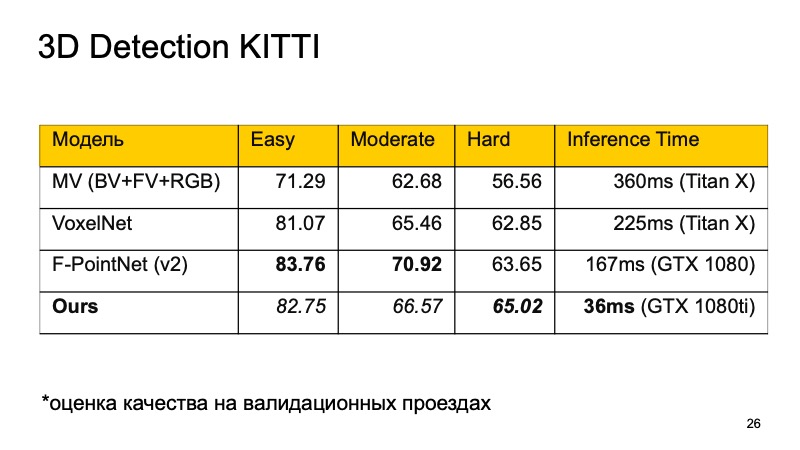
Puede notar que F-PointNet funciona bastante bien y lo suficientemente rápido, supera a todos los demás en diferentes áreas, al menos según los autores.
Nuestro enfoque se basa en más o menos todas las ideas que he enumerado. Si compara, obtiene la siguiente imagen. Si no ocupamos el primer lugar, al menos el segundo. Además, en aquellos objetos que son difíciles de detectar, nos separamos en los líderes. Y lo más importante, nuestro enfoque es lo suficientemente rápido. Esto significa que ya es bastante aplicable para sistemas en tiempo real, y es especialmente importante para un vehículo no tripulado monitorear lo que sucede en el camino y resaltar todos estos objetos.

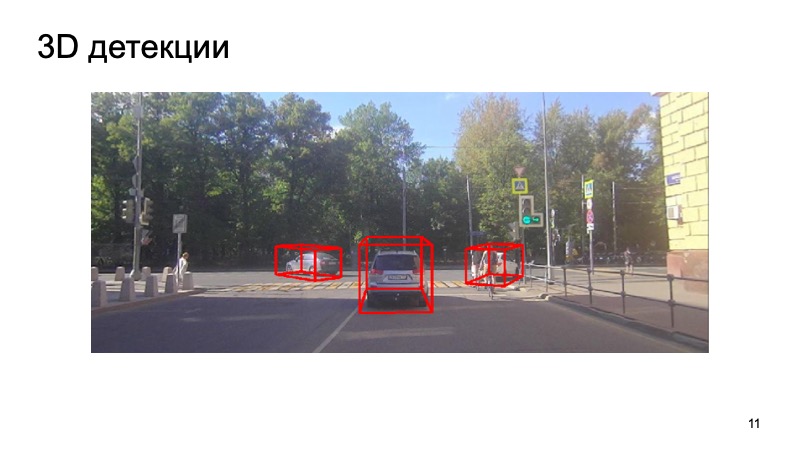
En conclusión, un ejemplo de nuestro detector:
Se puede ver que la situación es complicada: algunos de los objetos están cerrados y otros no son visibles para la cámara. Peatones, ciclistas. Pero el detector hace frente lo suficientemente bien. Gracias