Este es un nuevo artículo de una
discusión de tareas de entrevistas en Google . Cuando trabajaba allí, ofrecía a los candidatos tales tareas. Luego hubo una fuga, y fueron prohibidos. Pero la moneda tiene otro lado: ahora puedo explicar libremente la solución.
Buenas noticias para comenzar: ¡dejé Google! ¡Me complace informarle que ahora estoy trabajando como gerente técnico para Reddit en Nueva York! Pero esta serie de artículos aún continuará.
Descargo de responsabilidad: aunque entrevistar a los candidatos es una de mis tareas profesionales, en este blog comparto observaciones personales, historias y opiniones personales. No considere esto como una declaración oficial de Google, Alphabet, Reddit, ninguna otra persona u organización.Pregunta
Después de los
últimos dos artículos sobre el progreso del caballo en marcar un número de teléfono, recibí críticas de que este no es un problema realista. No importa cuán útil sea estudiar las habilidades de pensamiento del candidato, debo admitir que la tarea es realmente poco realista. Aunque tengo algunas ideas sobre la correlación entre las preguntas de la entrevista y la realidad, las dejaré para mí por ahora. Asegúrese de leer los comentarios en todas partes y tengo algo que responder, pero no ahora.
Pero cuando la tarea de pasar el caballo fue prohibida hace unos años, tomé en serio las críticas e intenté reemplazarla con una pregunta que es un poco más relevante para el alcance de Google. ¿Y qué puede ser más relevante para Google que la mecánica de las consultas de búsqueda? Así que encontré esta pregunta y la usé durante mucho tiempo antes de que también se hiciera pública y fuera prohibida. Como antes, formularé la pregunta, profundizaré en su explicación y luego contaré cómo la usé en las entrevistas y por qué me gusta.
Entonces la pregunta es.
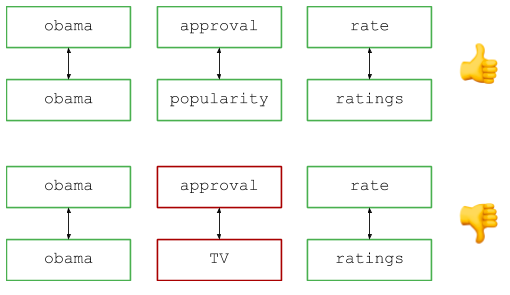
Imagine que administra un motor de búsqueda popular y ve dos solicitudes en los registros: diga "calificaciones de aprobación de Obama" y "nivel de popularidad de Obama" (si no recuerdo mal, estos son ejemplos reales de la base de preguntas, aunque ahora están un poco desactualizados ...) . Vemos consultas diferentes, pero todos estarán de acuerdo: los usuarios buscan esencialmente la misma información, por lo que las consultas deben considerarse equivalentes al contar el número de consultas, mostrar resultados, etc.
¿Cómo se determina si dos consultas son sinónimos?Formalicemos la tarea. Supongamos que hay dos conjuntos de pares de cadenas: pares de sinónimos y pares de consulta.
Específicamente, aquí hay un ejemplo de entrada para ilustrar:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
Es necesario producir una lista de valores lógicos: son las consultas en cada par.
Todas las preguntas nuevas ...
A primera vista, esta es una tarea simple. Pero cuanto más piensas, más difícil se vuelve. ¿Puede una palabra tener varios sinónimos? ¿Importa el orden de las palabras? ¿Son transitivas las relaciones de sinónimos, es decir, si A es sinónimo de B y B es sinónimo de C, A es sinónimo de C? ¿Pueden los sinónimos abarcar algunas palabras? ¿Cómo es "EE.UU." un sinónimo de las frases "Estados Unidos de América" o "Estados Unidos"?
Tal ambigüedad inmediatamente hace posible demostrar que eres un buen candidato. Lo primero que hace es buscar tales ambigüedades e intentar resolverlas. Todos hacen esto de diferentes maneras: algunos se acercan al tablero e intentan resolver manualmente casos específicos, mientras que otros miran la pregunta e inmediatamente ven los vacíos. En cualquier caso, identificar estos problemas en una etapa temprana es crucial.
La fase de "comprender el problema" es de gran importancia. Me gusta llamar a la ingeniería de software una disciplina fractal. Al igual que los fractales, la aproximación revela una complejidad adicional. Cree que comprende el problema, luego eche un vistazo más de cerca, y ve que se perdió alguna sutileza o detalle de la implementación que puede mejorarse. O un enfoque diferente del problema.
 Conjunto MandelbrotEl calibre de un ingeniero está determinado en gran medida por cuán profundamente puede entender el problema.
Conjunto MandelbrotEl calibre de un ingeniero está determinado en gran medida por cuán profundamente puede entender el problema. Transformar una declaración vaga del problema en un conjunto detallado de requisitos es el primer paso en este proceso, y la subestimación deliberada hace posible evaluar qué tan bien el candidato aborda nuevas situaciones.
Dejamos de lado preguntas triviales, como “¿Importan las letras mayúsculas?” Que no afectan el algoritmo principal. Siempre doy la respuesta más simple a estas preguntas (en este caso, "Suponga que todas las letras ya están preprocesadas y se convierten en minúsculas")Parte 1. (No del todo) un caso simple
Si los candidatos hacen preguntas, siempre comienzo con el caso más simple: una palabra puede tener varios sinónimos, el orden de las palabras es importante, los sinónimos no son transitivos. Esto le da al motor de búsqueda una funcionalidad bastante limitada, pero tiene suficientes sutilezas para una entrevista interesante.
Una descripción general de alto nivel es la siguiente: divida la consulta en palabras (por ejemplo, por espacios) y compare los pares correspondientes para buscar palabras y sinónimos idénticos. Visualmente, se ve así:
En código:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
Fácil, verdad? Algorítmicamente, es bastante simple. Sin programación dinámica, recursión, estructuras complejas, etc. Manipulación simple de la biblioteca estándar y un algoritmo que funciona en tiempo lineal, ¿verdad?
Pero hay más matices de lo que parece a primera vista. Por supuesto, el componente más difícil es la comparación de sinónimos. Aunque el componente es fácil de entender y describir, hay muchas formas de cometer un error. Te contaré sobre los errores más comunes.
Para mayor claridad: ningún error descalificará a un candidato; si eso, solo señalo un error en la implementación, lo arregla y seguimos adelante. Sin embargo, una entrevista es, en primer lugar, una lucha contra el tiempo. Cometerá, notará y corregirá errores, pero lleva tiempo que puede dedicarse a otro, por ejemplo, para crear una solución más óptima. Casi todos cometen errores, esto es normal, pero los candidatos que los hacen más pequeños muestran mejores resultados simplemente porque pasan menos tiempo corrigiéndolos.
Por eso me gusta este problema. Si el movimiento de un caballero requiere una comprensión de la comprensión del algoritmo, y luego (espero) una implementación simple, entonces la solución aquí son muchos pasos en la dirección correcta. Cada paso representa un pequeño obstáculo a través del cual el candidato puede saltar con gracia o tropezar y levantarse. Gracias a la experiencia y la intuición, los buenos candidatos evitan estos pequeños inconvenientes y obtienen una solución más detallada y correcta, mientras que los más débiles gastan tiempo y energía en errores y generalmente se quedan con el código incorrecto.
En cada entrevista, vi una combinación diferente de éxito y fracaso, estos son los errores más comunes.
Asesinos de rendimiento aleatorio
Primero, algunos candidatos han implementado la detección de sinónimos simplemente recorriendo la lista de sinónimos:
... elif (w1, w2) in synonym_words: continue ...
A primera vista, esto parece razonable. Pero después de una inspección más cercana, la idea es muy, muy mala. Para aquellos de ustedes que no conocen Python, la palabra clave in es azúcar sintáctica para el método
contiene y funciona en todos los contenedores estándar de Python. Esto es un problema porque las
synonym_words es una lista que implementa la palabra clave in mediante la búsqueda lineal. Los usuarios de Python son especialmente sensibles a este error porque el lenguaje oculta los tipos, pero los usuarios de C ++ y Java a veces también cometieron errores similares.
A lo largo de mi carrera, solo he escrito algunas veces con código de búsqueda lineal, y cada una en una lista de no más de dos docenas de elementos. E incluso en este caso, escribió un largo comentario explicando por qué eligió un enfoque aparentemente tan subóptimo. Sospecho que algunos candidatos lo usaron simplemente porque no sabían cómo funciona la palabra clave in en las listas de la biblioteca estándar de Python. Este es un simple error, no fatal, pero el conocimiento deficiente de su idioma favorito no es muy bueno.
En la práctica, este error se evita fácilmente. Primero, ¡nunca olvides tus tipos de objetos, incluso si usas un lenguaje sin tipo como Python! En segundo lugar, recuerde que cuando usa la palabra clave
in en la lista, comienza una búsqueda lineal. Si no hay garantía de que esta lista siempre sea muy pequeña, matará el rendimiento.
Para que el candidato vuelva a sus cabales, generalmente es suficiente recordarle que la estructura de entrada es una lista. Es muy importante observar cómo responde el candidato a la solicitud. Los mejores candidatos inmediatamente intentan de alguna manera preprocesar los sinónimos, lo cual es un buen comienzo. Sin embargo, este enfoque no está exento de dificultades ...
Use la estructura de datos correcta
Del código anterior, queda claro de inmediato que para implementar este algoritmo en tiempo lineal, es necesario encontrar rápidamente sinónimos. Y cuando hablamos de búsquedas rápidas, siempre es un mapa o una matriz de hashes.
No me importa si el candidato elige un mapa o una matriz de hashes. Lo importante es que lo pondrá allí (por cierto, nunca use dict / hashmap con la transición a
True o
False ). La mayoría de los candidatos eligen algún tipo de dict / hashmap. El error más común es la suposición subconsciente de que cada palabra no tiene más de un sinónimo:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
No castigo a los candidatos por este error. La tarea está especialmente formulada para no centrarse en el hecho de que las palabras pueden tener varios sinónimos, y algunos candidatos simplemente no se encontraron con tal situación. Lo más rápido soluciona un error cuando lo señalo. Los buenos candidatos lo notan en una etapa temprana y generalmente no pasan mucho tiempo.
Un problema un poco más grave es la falta de conciencia de que la relación de sinónimos se extiende en ambas direcciones. Tenga en cuenta que en el código anterior esto se tiene en cuenta. Pero hay implementaciones con un error:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
¿Por qué hacer dos inserciones y usar el doble de memoria?
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
Conclusión: ¡
siempre piense cómo optimizar el código ! En retrospectiva, la permutación de las funciones de búsqueda es una optimización obvia, de lo contrario, podemos concluir que el candidato no pensó en las opciones de optimización. Una vez más, me complace dar una pista, pero es mejor adivinarlo.
Ordenar?
Algunos candidatos inteligentes quieren ordenar la lista de sinónimos y luego usar la búsqueda binaria. De hecho, este enfoque tiene una ventaja importante: no requiere espacio adicional, a excepción de la lista de sinónimos (siempre que se permita modificar la lista).
Desafortunadamente, la complejidad del tiempo interfiere: ordenar una lista de sinónimos requiere tiempo
Nlog(N) , y luego otro
log(N) para buscar cada par de sinónimos, mientras que la solución de preprocesamiento descrita ocurre en tiempo lineal y luego constante. Además, estoy categóricamente en contra de obligar al candidato a implementar la clasificación y la búsqueda binaria en el tablero, porque: 1) los algoritmos de clasificación son bien conocidos, por lo tanto, hasta donde sé, el candidato puede emitirlo sin pensar; 2) estos algoritmos son endiabladamente difíciles de implementar correctamente y, a menudo, incluso los mejores candidatos cometerán errores que no dicen nada sobre sus habilidades de programación.
Cada vez que un candidato propuso tal solución, estaba interesado en el tiempo de ejecución del programa y le pregunté si había una mejor opción. Para información: si el entrevistador le pregunta si hay una mejor opción, la respuesta es casi siempre sí. Si alguna vez te hago esta pregunta, la respuesta será esa.
Finalmente solucion
Al final, el candidato ofrece algo correcto y razonablemente óptimo. Aquí hay una implementación en tiempo lineal y espacio lineal para condiciones dadas:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
Algunas notas rápidas:
- Tenga en cuenta el uso de
dict.get() . Puede implementar una verificación para ver si la clave está en el dict, y luego obtenerla, pero este es un enfoque complicado, aunque de esta manera mostrará su conocimiento de la biblioteca estándar. - Personalmente, no soy un fanático del código con frecuencia
continue , y algunas guías de estilo lo prohíben o no lo recomiendan . Yo mismo en la primera edición de este código olvidé la declaración de continue después de verificar la longitud de la solicitud. Este no es un mal enfoque, solo sepa que es propenso a errores.
Parte 2: ¡Cada vez más difícil!
Los buenos candidatos, después de resolver el problema, aún tienen de diez a quince minutos restantes. Afortunadamente, hay un montón de preguntas adicionales, aunque es poco probable que escribamos mucho código durante este tiempo. Sin embargo, esto no es necesario. Quiero saber dos cosas sobre el candidato: ¿es capaz de desarrollar algoritmos y puede codificar? El problema con el movimiento del caballero primero responde a la pregunta sobre el desarrollo del algoritmo, y luego verifica la codificación, y aquí obtenemos las respuestas en el orden inverso.
Cuando el candidato completó la primera parte de la pregunta, ya había resuelto el problema con la codificación (sorprendentemente no trivial). En esta etapa, puedo hablar con confianza sobre su capacidad para desarrollar algoritmos rudimentarios y traducir ideas en código, así como su conocimiento de su idioma favorito y biblioteca estándar. Ahora la conversación se está volviendo mucho más interesante, porque los requisitos de programación se pueden relajar y profundizaremos en los algoritmos.
Para este propósito, volvemos a los postulados principales de la primera parte: el orden de las palabras es importante, los sinónimos no son transitivos y para cada palabra puede haber varios sinónimos. A medida que avanza la entrevista, cambio cada una de estas restricciones, y en esta nueva fase, el candidato y yo tenemos una discusión puramente algorítmica. Aquí daré ejemplos de código para ilustrar mi punto de vista, pero en una entrevista real solo estamos hablando de algoritmos.
Antes de comenzar, explicaré mi posición: todas las acciones posteriores en esta etapa de la entrevista son principalmente "puntos de bonificación". Mi enfoque personal es identificar candidatos que pasen exactamente por la primera etapa y sean aptos para el trabajo. La segunda etapa es necesaria para resaltar lo mejor. La primera calificación ya es muy sólida y significa que el candidato es lo suficientemente bueno para la compañía, y la segunda calificación dice que el candidato es excelente y su contratación será una gran victoria para nosotros.
Transitividad: enfoques ingenuos
Primero, me gusta eliminar la restricción de transitividad, por lo que si los pares A - B y B - C son sinónimos, entonces las palabras A y C también son sinónimos. Los candidatos inteligentes comprenderán rápidamente cómo adaptar su solución anterior, aunque con la eliminación de otras restricciones, la lógica básica del algoritmo dejará de funcionar.
Sin embargo, ¿cómo adaptarlo? Un enfoque común es mantener un conjunto completo de sinónimos para cada palabra basado en relaciones transitivas. Cada vez que insertamos una palabra en un conjunto de sinónimos, también la agregamos a los conjuntos correspondientes para todas las palabras en este conjunto:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
Tenga en cuenta que al crear el código, ya hemos profundizado en esta solución.Esta solución funciona, pero lejos de ser óptima. Para comprender las razones, estimamos la complejidad espacial de esta solución. Cada sinónimo debe agregarse no solo al conjunto de la palabra inicial, sino también a los conjuntos de todos sus sinónimos. Si hay un sinónimo, se agrega una entrada. Pero si tenemos 50 sinónimos, debe agregar 50 entradas. En la figura, se ve así:
Observe que pasamos de tres claves y seis registros a cuatro claves y doce registros. Una palabra con 50 sinónimos requerirá 50 claves y casi 2500 entradas. El espacio necesario para representar una palabra crece de forma cuadrática con un aumento en el conjunto de sinónimos, lo cual es bastante derrochador.
Hay otras soluciones, pero no profundizaré demasiado para no inflar el artículo. El más interesante de ellos es el uso de la estructura de datos de sinónimos para construir un gráfico dirigido, y luego una búsqueda amplia para encontrar el camino entre dos palabras. Esta es una gran solución, pero la búsqueda se vuelve lineal en tamaño del conjunto de sinónimos de la palabra. Dado que realizamos esta búsqueda para cada solicitud varias veces, este enfoque no es óptimo.
Transitividad: uso de conjuntos disjuntos
Resulta que la búsqueda de sinónimos es posible durante un tiempo (casi) constante gracias a una estructura de datos llamada conjuntos disjuntos. Esta estructura ofrece posibilidades ligeramente diferentes que un conjunto de datos normal.
La estructura de conjunto habitual (hashset, treeset) es un contenedor que le permite determinar rápidamente si un objeto está dentro o fuera de él. Los conjuntos disjuntos resuelven un problema completamente diferente: en lugar de definir un elemento específico, le permiten determinar
si dos elementos pertenecen al mismo conjunto . Además, la estructura hace esto durante un tiempo cegadoramente rápido
O(a(n)) , donde
a(n) es la función inversa de Ackerman. Si no ha estudiado algoritmos avanzados, es posible que no conozca esta función, que para todas las entradas razonables se ejecuta en tiempo constante.
En un nivel alto, el algoritmo funciona de la siguiente manera. Los conjuntos están representados por árboles con padres para cada elemento. Como cada árbol tiene una raíz (un elemento que es su propio padre), podemos determinar si dos elementos pertenecen al mismo conjunto al rastrear a sus padres hasta la raíz. Si dos elementos tienen una raíz, pertenecen a un conjunto. Combinar conjuntos también es fácil: solo encuentre los elementos raíz y haga que uno de ellos sea la raíz del otro.
Hasta ahora todo bien, pero hasta ahora no se ha visto una velocidad deslumbrante. El genio de esta estructura está en un procedimiento llamado
compresión . Supongamos que tiene el siguiente árbol:
Imagina que quieres saber si
rápido y
apresurado son sinónimos. Repase cada uno de los padres y encuentre la misma raíz
rápida . Ahora supongamos que realizamos una verificación similar para las palabras
rápido y
rápido . Nuevamente, subimos a la raíz, y desde
speedy vamos por la misma ruta. ¿Se puede evitar la duplicación de trabajo?
Resulta que puedes. En cierto sentido, todos los elementos de este árbol están destinados a llegar
rápido . En lugar de recorrer todo el árbol cada vez, ¿por qué no cambiar el padre de todos
los descendientes
rápidos para acortar la ruta a la raíz? Este proceso se llama compresión, y en conjuntos disjuntos está incrustado en la operación de búsqueda raíz. Por ejemplo, después de la primera operación que compara
rápido y
apresurado, la estructura comprenderá que son sinónimos y comprimirá el árbol de la siguiente manera:
Para todas las palabras entre rápido y rápido, el padre se actualizó, lo mismo sucedió con apresuradoAhora todas las llamadas posteriores ocurrirán en tiempo constante, porque cada nodo en este árbol apunta a
rápido . No es muy fácil evaluar la complejidad temporal de las operaciones: de hecho, no es constante, porque depende de la profundidad de los árboles, pero es casi constante, porque la estructura se optimiza rápidamente. Por simplicidad, suponemos que el tiempo es constante.
Con este concepto, implementamos conjuntos no relacionados para nuestro problema:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
Con esta estructura, puede preprocesar sinónimos y resolver el problema en tiempo lineal.Calificación y notas
En este momento, hemos alcanzado el límite de lo que un candidato puede mostrar en 40-45 minutos de una entrevista. A todos los candidatos que hicieron frente a la parte introductoria e hicieron un progreso significativo en la descripción (no implementación) de conjuntos no relacionados, les asigné una calificación de "Altamente recomendado para contratar" y les permití hacer cualquier pregunta. Nunca he visto a un candidato llegar tan lejos y me queda mucho tiempo.En principio, todavía hay variantes del problema con la transitividad: por ejemplo, elimine la restricción en el orden de las palabras o en varios sinónimos de una palabra. Cada decisión será difícil y deliciosa, pero las dejaré para más adelante.El mérito de esta tarea es que permite que los candidatos cometan errores. El desarrollo diario de software consiste en ciclos interminables de análisis, ejecución y refinamiento. Este problema hace posible que los candidatos demuestren sus habilidades en cada etapa. Considere las habilidades necesarias para obtener el puntaje máximo en este tema:- Analice el enunciado del problema y determine dónde no está claramente formulado , desarrolle una formulación inequívoca. Continúe haciendo esto mientras resuelve y surgen nuevas preguntas. Para obtener la máxima eficacia, realice estas operaciones lo antes posible, ya que cuanto más avance el trabajo, más tiempo llevará corregir el error.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
Ninguna de estas habilidades se puede aprender de los libros de texto (con la posible excepción de estructuras de datos y algoritmos). La única forma de adquirirlos es la práctica regular y extensa, que está en buen acuerdo con lo que el empleador necesita: candidatos con experiencia que puedan aplicar sus conocimientos de manera efectiva. El objetivo de las entrevistas fue encontrar a esas personas, y la tarea de este artículo me ayudó mucho durante mucho tiempo.Planes futuros
Como puede comprender, la tarea finalmente se hizo pública . Desde entonces, he usado varias otras preguntas, dependiendo de lo que preguntaron los entrevistadores anteriores y de mi estado de ánimo (hacer una pregunta es aburrido todo el tiempo). Todavía uso algunas preguntas, así que las guardaré en secreto, ¡pero algunas no lo son! Puedes encontrarlos en los siguientes artículos.En un futuro próximo planeo dos artículos. Primero, como se prometió anteriormente, explicaré la solución a los dos problemas restantes para esta tarea. Nunca les pregunté en las entrevistas, pero son interesantes en sí mismos. Además, compartiré mis pensamientos y opiniones personales sobre el procedimiento para encontrar empleados en TI, lo cual es especialmente interesante para mí ahora, porque estoy buscando ingenieros para mi equipo en Reddit.Como siempre, si quieres saber sobre el lanzamiento de nuevos artículos, sígueme en Twitter o en Medium . Si te gustó este artículo, no olvides votarlo o dejar un comentario.Gracias por leer!PS: Usted puede examinar el código de todos los artículos en el repositorio GitHub o jugar con ellos en directo gracias a mis buenos amigos de repl.it .