El mercado de servicios en la nube está creciendo rápidamente tanto en el mundo como en Rusia. Cada vez más empresas están trasladando sus aplicaciones y datos, incluidos los críticos para el negocio, a la nube. Según los especialistas en marketing, esto permite a las empresas utilizar las soluciones de nube innovadoras más avanzadas, reduciendo los costos de capital (convirtiendo CAPEX a OPEX), más rápido para traer nuevos productos al mercado y lanzar nuevos servicios. Y tales argumentos no dejan indiferentes a los clientes potenciales. No es casualidad que las tasas de crecimiento del mercado de la nube de Rusia estén significativamente por delante del crecimiento del mercado de la infraestructura de TI tradicional y clásica.
Poco a poco, se disipan las dudas sobre la fiabilidad y la seguridad de las nubes. Como lo demostró un
estudio reciente de
iKS-Consulting , casi el 40% de las compañías rusas encuestadas ven el uso de nubes públicas como una oportunidad para mejorar la seguridad de sus sistemas de TI. El servicio en la nube de infraestructura más popular es el alquiler de servidores virtuales. En segundo lugar en popularidad está el servicio de respaldo en la nube (Backup-as-a-Service). Alrededor de un tercio de los encuestados utilizan servicios en la nube para alojar el almacenamiento y la infraestructura de recuperación ante desastres.
Mientras tanto, con la creciente dependencia de las empresas de TI, los requisitos para la confiabilidad de los servicios de TI, incluidos los servicios en la nube, están creciendo. Y a menudo es necesario proporcionar no solo confiabilidad de hardware, sino también tolerancia a desastres.
Según la investigación , casi las tres cuartas partes de las organizaciones en el mundo no están completamente seguras de que podrán restaurar sus sistemas y datos. El tiempo de inactividad no planificado y la pérdida de datos cuestan a las organizaciones de todo el mundo anualmente más de $ 1.7 mil millones. Según la
investigación de Acronis , en Rusia, solo el 2% de las empresas encuestadas están absolutamente seguras de que su infraestructura de TI resistirá cualquier prueba. La mitad de los especialistas rusos esperan largas interrupciones en su trabajo en caso de un desastre natural o accidente. Según las estadísticas mundiales, el 93% de las empresas que han perdido su centro de datos durante solo 10 días quiebran en un año.
En cualquier sistema técnicamente complejo, los accidentes son inevitables, pero pueden hacerse no críticos para los negocios. Para evitar tales situaciones, se crean sistemas de clúster resistentes a desastres que prácticamente eliminan el tiempo de inactividad en caso de accidentes y fallas.
Otro punto importante que no debe olvidarse al diseñar una infraestructura de TI resistente a desastres son las estaciones de trabajo de los usuarios. Es necesario reanudar los procesos comerciales, y no solo cambiar al servidor de respaldo o elevar la base de datos. La tolerancia a desastres comienza en la oficina del cliente. Incluso una oficina de respaldo con trabajos de empleados no es la mejor opción. Las estaciones de trabajo virtuales (VDI) u otras formas de lugar de trabajo en la nube pueden ser una buena solución. El acceso a dicha estación de trabajo en una máquina virtual en el centro de datos es fácil de organizar desde cualquier computadora en la red de sucursales.
Innovación en la nube
El operador ruso de telecomunicaciones
MasterTel y Lenovo han preparado e implementado conjuntamente un proyecto de nube
resistente a desastres llamado
Innovate Cloud Technology . En base a esta nube, se proporcionan servicios de IaaS altamente confiables a una amplia gama de clientes que desean implementar una infraestructura de TI crítica en la nube. La nube se basó en el clúster de metro espaciado entre dos sitios: los centros de datos DataPro y IXellerate en Moscú.
Al elegir un socio para este proyecto, la compañía MasterTel se guió, en primer lugar, por la capacidad del proveedor de proporcionar rápidamente la solución más completa a un precio razonable. Para implementar la nube, lanzada en octubre de 2018, participó un equipo de especialistas en servicios profesionales de Lenovo. MasterTel actúa como un proveedor de servicios en la nube y un operador de telecomunicaciones que organiza canales de comunicación seguros y proporciona líneas directas de fibra óptica, es responsable del funcionamiento de la nube y su soporte.
Innovate Cloud Technology es una nube privada para clientes corporativos, que ofrece servicios en la nube en tiempo real altamente confiables y escalables IaaS, BaaS, DRaaS, VDS, etc. ¿Qué proporciona el uso de los servicios de Innovate Cloud Technology?
Alta fiabilidad
Actualmente, la mayoría de los proyectos en la nube, de hecho, ofrecen capacidad de alquiler. Como regla, esta es la creación de servidores virtuales (el servicio de centro de datos comercial más común en Rusia) y el acceso a un grupo de recursos ya formado. En el caso de Innovate Cloud Technology, el cliente puede realizar todas las configuraciones en línea, los recursos se asignan y liberan dinámicamente y se pagan después del hecho, exclusivamente por los recursos utilizados, como corresponde a un servicio en la nube clásico.
Pero quizás la característica más importante de Innovate Cloud Technology es su alta confiabilidad. Los clientes pueden aprovechar la infraestructura de nube de alta disponibilidad y almacenar datos muy críticos en centros de datos DataPro y IXcellelle geográficamente dispersos. Estos sitios por sí solos garantizan confiabilidad y un alto nivel de seguridad física y de información. MasterTel proporciona canales confiables de comunicación de alta velocidad y acceso a ambos centros de datos.
Innovate Cloud Technology es un recurso en la nube con 99.99% de disponibilidad garantizada de SLA. Sin embargo, esta nube no solo se distingue por su alta confiabilidad, sino también por la tolerancia a desastres, porque es un clúster de virtualización geográficamente disperso en dos sitios de nivel Tier III.
Data Center DataPro
Este centro de datos de nivel III en la calle. Aviamotornaya en Moscú es uno de los pocos centros de datos comerciales rusos que ha recibido la certificación Uptime Design and Facility. Todas las tecnologías y soluciones utilizadas en el centro de datos están certificadas, lo que significa máxima tolerancia a fallas, disponibilidad garantizada de recursos y es un seguro contra situaciones inesperadas.
Centro de gestión del centro de datos DataPro. La certificación internacional de Uptime Design and Facility significa que está diseñado y construido de acuerdo con todos los estándares aplicables para la categoría de confiabilidad Tier III.
La seguridad es responsable de la seguridad del centro de datos y del área circundante. El sistema de seguridad incluye más de 350 cámaras de red. Para una fuente de alimentación ininterrumpida y garantizada, se utilizan fuentes de alimentación ininterrumpida (UPS), se utilizan grupos electrógenos diesel (DGU) que respaldan la operación del centro de datos durante un accidente prolongado en la red de suministro de energía.
En el centro de datos DataPro, hay dos entradas independientes de 10 kV desde la subestación Mosenergo, y los cables se colocan en diferentes colectores, proporcionando la energía eléctrica necesaria para la instalación. La fuente de alimentación del centro de datos está reservada según el esquema 2N.
IXcellerate Moscow One
El centro de datos Moscow One de IXcellerate también posee una certificación de Nivel III Uptime Institute en la categoría Diseño. La instalación también cumple con el nivel de confiabilidad del Nivel 3 en las categorías "proyecto", "construcción" y "operación" de acuerdo con la metodología del Sistema de Clasificación de Confiabilidad de IBM. IXcellerate Moscow One está técnicamente implementado y garantizado a nivel de SLA con un indicador de disponibilidad del 99.999%. El área total del centro de datos IXcellerate Moscow One en Degunino es de 15,741 metros cuadrados. m. La capacidad de diseño de la instalación alcanza 13.7 MW. Los clientes del centro de datos incluyen alrededor de un centenar de empresas internacionales y rusas.
La aprobación de las pruebas de certificación del Uptime Institute demuestra que el complejo informático IXcellerate está diseñado de acuerdo con las prácticas modernas del mundo en la construcción de centros de datos.
Tolerancia al desastre
La distribución en dos sitios requiere la organización de canales de comunicación redundantes, la replicación de datos entre almacenamientos. Necesitamos un mecanismo de sincronización de datos para asegurar su relevancia en caso de falla de uno de los nodos y para soportar la operación de aquellos sistemas de información que requieren tal sincronización.
A menudo, en el corazón de un centro de datos resistente a desastres se encuentra una configuración de servidor de clúster distribuido geográficamente con una conexión a una red de área de almacenamiento común (SAN). Los nodos de este clúster espaciado se encuentran en los sitios principales y de reserva, formando un solo sistema. Esto garantiza la disponibilidad ininterrumpida del servicio incluso en caso de pérdida de uno de los centros de datos. Con la ayuda de la agrupación en clúster, es posible proporcionar una conmutación de carga automática entre los sitios de un centro de datos distribuido en caso de accidente.
Los sistemas de almacenamiento de datos en estos sitios pueden duplicarse completamente entre sí, y los sitios mismos están conectados por canales de comunicación redundantes de alta velocidad, lo que le permite implementar proyectos con los requisitos más altos para la confiabilidad de la transferencia de datos y su disponibilidad, incluida la replicación de datos sincrónica.

Ejemplo de configuración de Metrocluster basado en VMware vSphere. se basa en la duplicación de sistemas de almacenamiento en dos sitios separados geográficamente con replicación de datos y posible equilibrio de carga a nivel de red del centro de datos. Si uno de los centros de datos no está disponible, las máquinas virtuales se iniciarán automáticamente en la segunda plataforma. Un clúster metropolitano es un tiempo de inactividad casi nulo, el trabajo se interrumpe solo durante el inicio de máquinas virtuales, cuando VMware High Availability (HA) reinicia la VM en un sitio remoto con almacenamiento ubicado en el clúster.
Si utiliza mecanismos de equilibrio de carga DR (Global Server Load Balancing, GSLB), puede cambiar automáticamente a los usuarios al sitio de respaldo en caso de una falla primaria. Para los usuarios, este proceso será transparente.
A diferencia de DR con replicación de datos, en el caso de un clúster metropolitano, solo se usan los mismos tipos de discos para duplicación, se necesita una configuración idéntica en ambos sitios.
La nube Innovate Cloud Technology basada en VMware está construida de esta manera. Proporciona operación continua de aplicaciones y datos críticos en la nube. Todos los elementos del clúster de virtualización se duplican en dos sitios, alejados entre sí por casi 30 km. Entre ellos, la duplicación de datos se configura en el nivel del sistema de almacenamiento. Debido a esto, los datos y servicios estarán disponibles en caso de fallas en uno de los sitios: corte de energía, falla parcial de los sistemas de almacenamiento, controladores, canales de comunicación entre el centro de datos e incluso en el caso de una inoperancia completa de uno de los sitios.
Si uno de los centros de datos no está disponible, las máquinas virtuales se migran al sitio de respaldo. Iniciar una máquina virtual en un sitio de respaldo (Objetivo de tiempo de recuperación, RTO) tomará aproximadamente 3 minutos.
A los clientes se les ofrece un Acuerdo de Nivel de Servicio (SLA) detallado. Sus principales indicadores: disponibilidad del servicio al nivel del 99,99%; simple: no más de 4.38 minutos por mes, parámetros garantizados de rendimiento del procesador (MIPS / 1 vCPU), sistema de disco (IOPS, GB / s), demoras en el acceso a los sistemas de almacenamiento. Para su cumplimiento, el proveedor es financieramente responsable.
Metro Cluster Anatomy
La nube se construye de acuerdo con el modelo arquitectónico clásico, que implica la compra de todo el complejo de hardware y software necesarios: servidores con la organización de acceso físico y lógico, almacenamiento, componentes de red, software de virtualización, soluciones de seguridad.
Dos centros de datos en Moscú tienen zonas cerradas dedicadas para cuatro racks con computación y nodos de red. La solución se basa en componentes fabricados por Lenovo. Como sistemas de cómputo de hardware, se utilizan servidores Lenovo ThinkSystem SR530 / SR570 / SR630 de 1U con adaptadores HBA de doble puerto Emulex 16Gb Gen6 FC, los arreglos Lenovo Storage V3700 V2 XP se usan para el almacenamiento de datos, y se usan conmutadores de rack de 10 puertos Gigabit de 32 puertos para la transferencia de datos con Lenovo ThinkSystem NE1032 RackSwitch. El paquete incluye el software VMware ESXi 6.5 instalado de fábrica en los servidores. Los sitios están conectados por dos canales FC de 8 Gbit / s y dos canales Ethernet de 10 Gbit / s.
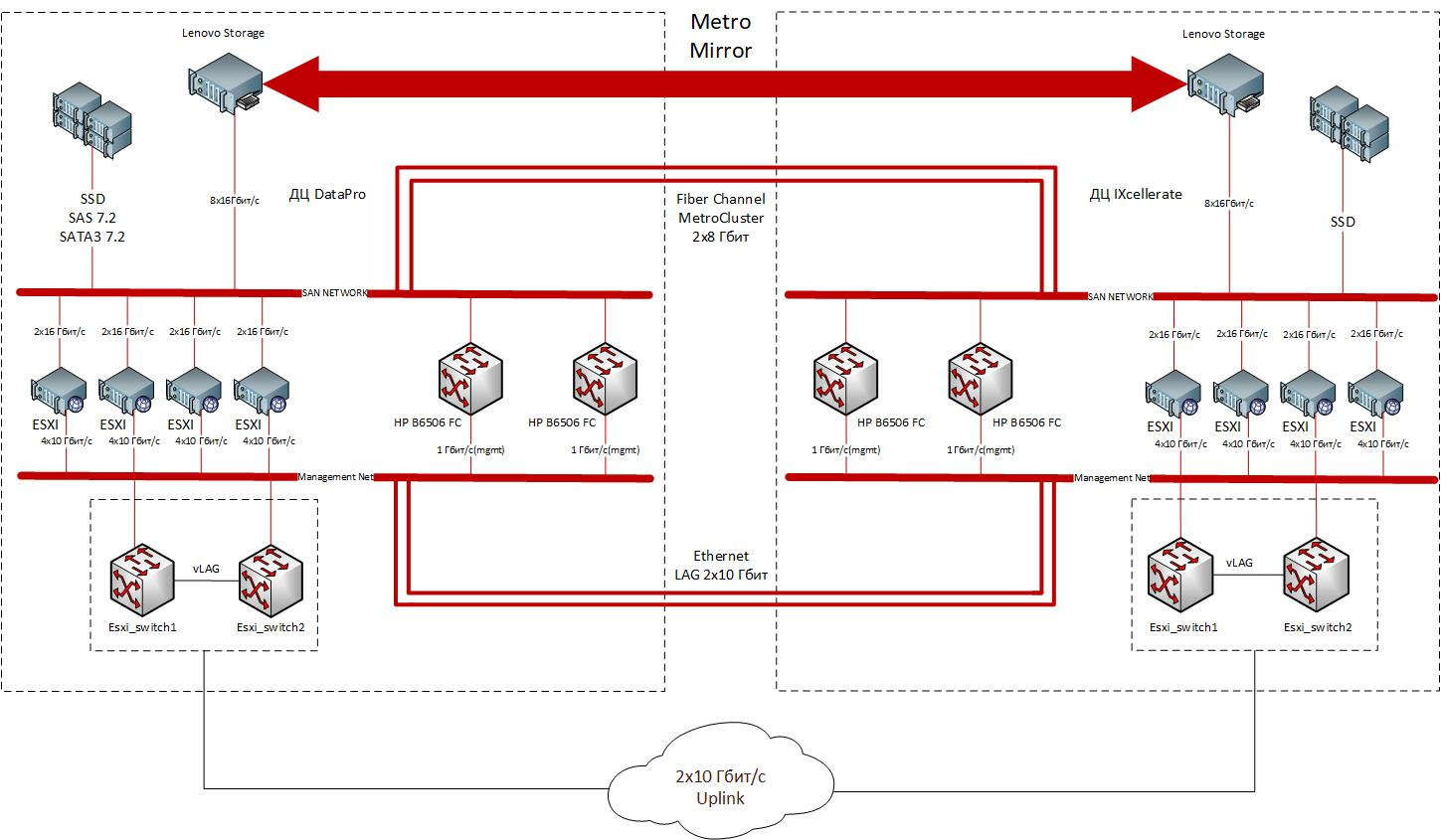
La estructura de un clúster distribuido geográficamente. Espaciado entre los dos sitios, el clúster metropolitano ofrece tolerancia a desastres y permite proporcionar servicios IaaS confiables a una amplia gama de clientes. Los sitios están conectados por Ethernet redundante (2x10 Gbit / s) y canales FC (2x8 Gbit / s).
Al adquirir componentes de infraestructura de un proveedor, se aumenta la confiabilidad y la resistencia de todo el complejo, se eliminan los conflictos entre elementos, estándares y protocolos.
Los esfuerzos conjuntos de los dos equipos llevaron a cabo el trabajo en la creación del proyecto, la preparación y el desarrollo de especificaciones técnicas, instalación de equipos, puesta en marcha, pruebas de estrés y puesta en marcha del grupo de metro.
Lenovo Metrocluster proporciona una copia de seguridad completa de todos sus elementos: servidores, almacenamiento, controladores, adaptadores FC, conmutadores ópticos. La replicación de datos síncronos a nivel de almacenamiento proporciona un objetivo de punto de recuperación cero (RPO).
Siempre se ha logrado una alta disponibilidad garantizando la redundancia; esto también es cierto en el caso de la preparación para situaciones extremas, cuando todo el centro de datos debe estar protegido contra cortes de energía o desastres naturales. Si uno de los sitios falla, un clúster disperso geográficamente automáticamente y sin interrumpir los procesos de trabajo cambia a un segundo centro de datos. De hecho, el clúster de metro es un clúster local con un sistema de almacenamiento en espejo, espaciado entre dos sitios.
Los grupos distribuidos geográficamente no tienen puntos críticos de falla. El clúster metro implementa la replicación de datos síncronos mutuos entre sitios. Si se produce un problema, el cambio a otro sitio es completamente transparente y sin intervención del administrador. La automatización de este proceso garantiza el funcionamiento continuo de todas las aplicaciones. Los clústeres de Metro tampoco necesitan detenerse para actualizar su hardware o software.
Por ejemplo, en caso de una falla completa del servidor, sus responsabilidades se transfieren a un segundo servidor ubicado en el mismo sitio en unos pocos segundos. La interrupción a corto plazo de la entrada-salida de datos que ocurre en este caso no afectará el funcionamiento de las aplicaciones, ya que los datos se reflejan sincrónicamente en la segunda plataforma. Si hay un problema en el funcionamiento del conmutador, el cable o el HBA Fibre Channel, no es necesario cambiar de respaldo al segundo centro de datos, y el usuario final no experimentará ninguna disminución en el rendimiento de la aplicación.
En caso de falla de todo el nodo de servicio, se produce una interrupción a corto plazo (varios segundos) de los flujos de E / S: los servicios se transfieren primero a los nodos vecinos, y la necesidad de cambiar a un nodo geográficamente remoto surge solo si el sitio está completamente interrumpido.
En esta situación, un clúster geográficamente disperso utiliza redundancia a nivel del centro de datos para superar la falla, y los sistemas ubicados en el segundo sitio se hacen cargo del soporte de todos los servicios. Por lo tanto, los servidores de aplicaciones conservan el acceso a todos los servicios, pero con un rendimiento limitado.
Cuando el sitio en el que ocurrió la falla ingresará nuevamente al modo de operación, será necesario transferirle solo los datos que se han cambiado durante el tiempo de inactividad, por lo tanto, después de eliminar los problemas locales, el centro de datos afectado puede volver rápidamente a la operación normal.
En caso de pérdida de host, VMware High Availability (HA) reinicia inmediatamente la VM en un sitio remoto. Si uno de los sistemas de almacenamiento falla, el sistema de almacenamiento en otro sitio anuncia rutas de disco a los hosts restantes. Las máquinas virtuales perdidas se reinician en ellas, todo sucede automáticamente.
Si se pierde la conexión entre los sitios, entonces todo continúa funcionando en su lugar y, tan pronto como se restablece la conexión, comienza el proceso de sincronización.
Composición de la solución
Ocho servidores Lenovo ThinkSystem SR630 con 2 procesadores Intel Xeon Gold 6132 14C 140W 2.6 GHz, 32 GB de memoria TruDDR4 2666 MHz (RDIMM), 10 bahías de unidades de 2.5 ", unidades SSD SATA M.2 de 32 GB y software VMware ESXi 6.5 instalado de fábrica.
| El servidor de doble procesador en el factor de forma 1U tiene la flexibilidad y el rendimiento debido al soporte de discos duros y unidades de estado sólido (HDD y SSD) con interfaces SAS o SATA (12 SFF o 4 LFF). Con la capacidad de conectar unidades NVMe, proporciona altas velocidades de lectura y escritura. El software Lenovo XClarity Administrator simplifica la gestión y el mantenimiento de la infraestructura. Esta solución de diseño se centra en un equilibrio entre rendimiento y precio para soportar una amplia gama de cargas de trabajo, diseñada para un funcionamiento continuo a una temperatura de 45 ° C.
|
Dos sistemas de almacenamiento Lenovo Storage V3700 V2 XP con 1.92 TB 2.5 "SAS SSD y 1.2 TB 2.5" 10K HDD, con software Easy Tier, FlashCopy y Remote Mirroring.
| .V3700 V2 XP , , . Intel SAS, , . Web- , , FlashCopy. 240 2,5 120 - 3,5 . .
|
Lenovo V3700 V2 20 2 2.5" 7.2K HDD
| , , . . Lenovo Storage V3700 V2 RAID-, — - 3.5", HDD SSD - 2.5". Virtualization of Internal Storage, Thin Provisioning, One-way Data Migration, FlashCopy (64 ). — FlashCopy (2048 ), Easy Tier, Remote Mirroring.
|
32- Ethernet 10 / Lenovo ThinkSystem NE1032 SFP+ SR.
| 24 10GBase-T 8 SFP+ 10 / . Lenovo Cloud NOS, . NE1032 . L2/L3 IP-, BGP, , Lenovo XClarity.
|
Fibre Channel Lenovo B6505 FC SAN c 12 SFP 16 /.
| Fibre Channel 5- -. - 16 /.
|
