
El tema de mejorar el rendimiento de los sistemas operativos y encontrar cuellos de botella está ganando una inmensa popularidad. En este artículo, hablaremos sobre una herramienta para encontrar estos lugares utilizando el ejemplo de la pila de bloques en Linux y un caso de resolución de problemas de un host.
Ejemplo 1. Prueba
Nada funciona
Las pruebas en nuestro departamento son sintéticas en el hardware del producto y, más tarde, pruebas de software de aplicación. Recibimos una unidad Intel Optane para realizar pruebas. Ya escribimos sobre probar las unidades Optane
en nuestro blog .
El disco se instaló en un servidor estándar construido durante un tiempo relativamente largo en uno de los proyectos en la nube.
Durante la prueba, el disco no se mostró de la mejor manera: durante la prueba con la profundidad de la cola de 1 solicitud por 1 flujo, en bloques de 4Kbytes aproximadamente ~ 70Kiops. Y esto significa que el tiempo de respuesta es enorme: ¡aproximadamente 13 microsegundos por solicitud!
Es extraño, porque la
especificación promete "Latencia - Leer 10 µs", y obtuvimos un 30% más, la diferencia es bastante significativa. El disco se reorganizó a otra plataforma, un ensamblaje más "nuevo" utilizado en otro proyecto.
Por que funciona
Es divertido, pero la unidad en la nueva plataforma funcionó como debería. Aumento del rendimiento, disminución de la latencia, CPU por estante, 1 transmisión por solicitud, bloques de 4 Kbytes, ~ 106Kiops a ~ 9 microsegundos por solicitud.
Y luego es hora de
comparar la configuración para obtener el
rendimiento de las
piernas anchas. Después de todo, nos preguntamos por qué. Con
perf, puedes:
- Tome las lecturas del contador de hardware: la cantidad de llamadas de instrucciones, errores de caché, ramas predichas incorrectamente, etc. (Eventos de PMU)
- Eliminar información de puntos comerciales estáticos, el número de ocurrencias
- Realizar rastreo dinámico
Para la verificación, usamos muestreo de CPU.
La conclusión es que
perf puede compilar todo el seguimiento de la pila de un programa en ejecución. Naturalmente, ejecutar
perf introducirá un retraso en la operación de todo el sistema. Pero tenemos la bandera
-F # , donde
# es la frecuencia de muestreo, medida en Hz.
Es importante comprender que cuanto mayor sea la frecuencia de muestreo, más probabilidades hay de capturar una llamada a una función en particular, pero más frenos trae el generador de perfiles al sistema. Cuanto menor es la frecuencia, mayor es la posibilidad de que no veamos parte de la pila.
Al elegir una frecuencia, debe guiarse por el sentido común y un truco: trate de no establecer una frecuencia uniforme, para no entrar en una situación en la que un trabajo que se ejecuta en un temporizador con esta frecuencia ingresa a las muestras.
Otro punto que es inicialmente engañoso: el software debe compilarse con el indicador
-fno-omit-frame-pointer , si esto es posible, por supuesto. De lo contrario, en la traza, en lugar de nombres de funciones, veremos valores sólidos
desconocidos . Para algunos programas, los símbolos de depuración vienen como un paquete separado, por ejemplo,
someutil-dbg . Se recomienda que los instale antes de ejecutar
perf .
Realizamos las siguientes acciones:
- Tomado de fio de git: //git.kernel.dk/fio.git, etiqueta fio-3.9
- Se agregó la opción -fno-omit-frame-pointer a CPPFLAGS en Makefile
- Lanzado make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
La opción -g es necesaria para capturar la pila de trazas.
Puede ver el resultado con el comando:
perf report -g fractal
La opción
fractal -g es necesaria para que los porcentajes que reflejan el número de muestras con esta función y se muestren por
perf sean relativos a la función de llamada, cuyo número de llamadas se toma como 100%.
Hacia el final de la larga pila de llamadas fio en la plataforma de "nueva construcción", veremos:
Y en la plataforma "old build":

Genial Pero quiero bellos flamegrafs.
Construyendo flamegramas
Para ser bella, hay dos herramientas:
- Relativamente más flamegraph estático
- Flamescope , que permite seleccionar un período específico de tiempo de las muestras recolectadas. Esto es muy útil cuando el código de búsqueda carga la CPU con ráfagas cortas.
Estas utilidades aceptan
perf script> result como entrada.
Descargue el
resultado y envíelo a través de tuberías a
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Abrir en un navegador y disfrutar de una imagen en la que se puede hacer clic
Puedes usar otro método:
- Añadir resultado a flamescope / example /
- Ejecute python ./run.py
- Pasamos por el navegador hasta el puerto 5000 del host local.
¿Qué vemos al final?
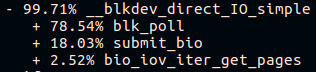
Un buen fio pasa mucho tiempo
encuestando :
Un fio malo pasa tiempo en cualquier parte, pero no en encuestas:
A primera vista, parece que el sondeo no funciona en el host anterior, pero en todas partes el núcleo 4.15 es del mismo ensamblaje y el sondeo está habilitado de forma predeterminada en los discos NVMe. Compruebe si el sondeo está habilitado en
sysfs :
Durante las pruebas, se
utilizan llamadas
preadv2 con el indicador
RWF_HIPRI , una condición necesaria para que el sondeo funcione. Y, si estudia cuidadosamente el gráfico de la llama (o la captura de pantalla anterior de la salida del
informe de rendimiento), puede encontrarlo, pero lleva una cantidad muy pequeña de tiempo.
La segunda cosa que es visible es la pila de llamadas diferente para la función submit_bio () y la falta de llamadas io_schedule (). Echemos un vistazo más de cerca a la diferencia dentro de submit_bio ().
Plataforma lenta "construcción anterior":
Plataforma rápida "fresca":
Parece que en una plataforma lenta, la solicitud llega muy lejos al dispositivo, al mismo tiempo que
ingresa al programador de Kyber . Puede leer más sobre los programadores de E / S en
nuestro artículo .
Una vez que
kyber se apagó, la misma prueba de fio mostró una latencia promedio de aproximadamente 10 microsegundos, tal como se indica en la especificación. Genial
Pero, ¿de dónde viene la diferencia en otro microsegundo?
¿Y si un poco más profundo?
Como ya se mencionó,
perf le permite recopilar estadísticas de contadores de hardware. Intentemos ver la cantidad de errores de caché e instrucciones por ciclo:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


De los resultados se puede ver que una plataforma rápida ejecuta más instrucciones para el ciclo de la CPU y tiene un menor porcentaje de errores de caché durante la ejecución. Por supuesto, no entraremos en detalles sobre el funcionamiento de diferentes plataformas de hardware en el marco de este artículo.
Ejemplo 2. Tienda de comestibles
Algo va mal
En el trabajo de un sistema de almacenamiento distribuido, se observó un aumento en la carga en la CPU en uno de los hosts con un aumento en el tráfico entrante. Los hosts son pares, pares y tienen hardware y software idénticos.
Veamos la carga de la CPU:
~
El problema surgió a las 09:23:46 y vemos que el proceso funcionó en el espacio del núcleo exclusivamente durante todo el segundo. Veamos lo que estaba sucediendo adentro.
¿Por qué tan lento?
En este caso, tomamos muestras de todo el sistema:
perf record -a -g -- sleep 22 perf script > perf.results
Aquí se necesita la opción
-a para que
perf elimine los rastros de todas las CPU.
Abra
perf.results con
flamescope para rastrear el momento de mayor carga de CPU.
Ante nosotros hay un "mapa de calor", cuyos dos ejes (X e Y) representan el tiempo.
En el eje X, el espacio se divide en segundos, y en el eje Y, en segmentos de 20 milisegundos en X segundos. El tiempo corre de abajo hacia arriba y de izquierda a derecha. Los cuadrados más brillantes tienen el mayor número de muestras. Es decir, la CPU en este momento trabajó más activamente.
En realidad, estamos interesados en la mancha roja en el medio. Selecciónelo con el mouse, haga clic y vea qué oculta:
En general, ya es evidente que el problema es la operación lenta
tcp_recvmsg y
skb_copy_datagram_iovec en él.
Para mayor claridad, compare con muestras de otro host en el que la misma cantidad de tráfico entrante no causa problemas:
Basado en el hecho de que tenemos la misma cantidad de tráfico entrante, plataformas idénticas que han estado funcionando durante mucho tiempo sin parar, podemos suponer que los problemas surgieron del lado del hierro. La función
skb_copy_datagram_iovec copia datos de la estructura del núcleo a la estructura en el espacio del usuario para pasar a la aplicación. Probablemente haya problemas con la memoria del host. Al mismo tiempo, no hay errores en los registros.
Reiniciamos la plataforma. Al cargar el BIOS, vemos un mensaje sobre una barra de memoria rota. Reemplazo, el host se inicia y el problema con una CPU sobrecargada ya no se reproduce.
Postdata
Rendimiento del sistema con perf
En términos generales, en un sistema ocupado, ejecutar
perf puede introducir un retraso en el procesamiento de solicitudes. El tamaño de estos retrasos también depende de la carga en el servidor.
Intentemos encontrar este retraso:
~
La diferencia no es muy notable, solo alrededor de ~ 8 nanosegundos.
Veamos qué sucede si aumenta la carga:
~
Aquí la diferencia ya se está haciendo notable. Se puede decir que el sistema se desaceleró en menos del 1%, pero esencialmente perder alrededor de 7 Kiops en un sistema muy cargado puede provocar problemas.
Está claro que este ejemplo es sintético, sin embargo es muy revelador.
Intentemos ejecutar otra prueba sintética que calcule números primos -
sysbench :
~
Aquí puede ver que incluso el tiempo mínimo de procesamiento aumentó en 270 microsegundos.
En lugar de una conclusión
Perf es una herramienta muy poderosa para analizar el rendimiento del sistema y la depuración. Sin embargo, como con cualquier otra herramienta, debe mantenerse en control y recordar que cualquier sistema cargado bajo estrecha supervisión funciona peor.
Enlaces relacionados: