Publicación preparada por: Alexander Virilin xscrew - autor, jefe del servicio de infraestructura de red, Leonid Klyuyev - editor
Continuamos familiarizándolo con la estructura interna de
Yandex.Cloud . Hoy hablaremos de redes: le diremos cómo funciona la infraestructura de red, por qué utiliza el paradigma MPLS impopular para los centros de datos, qué otras decisiones complejas tuvimos que tomar en el proceso de construcción de una red en la nube, cómo la administramos y qué tipo de monitoreo usamos.
La red en la nube consta de tres capas. La capa inferior es la infraestructura ya mencionada. Esta es una red física "de hierro" dentro de los centros de datos, entre centros de datos y en lugares de conexión a redes externas. Se construye una red virtual sobre la infraestructura de red y los servicios de red se construyen sobre la red virtual. Esta estructura no es monolítica: las capas se cruzan, la red virtual y los servicios de red interactúan directamente con la infraestructura de red. Dado que la red virtual a menudo se denomina superposición, generalmente llamamos a la infraestructura de red subyacente.

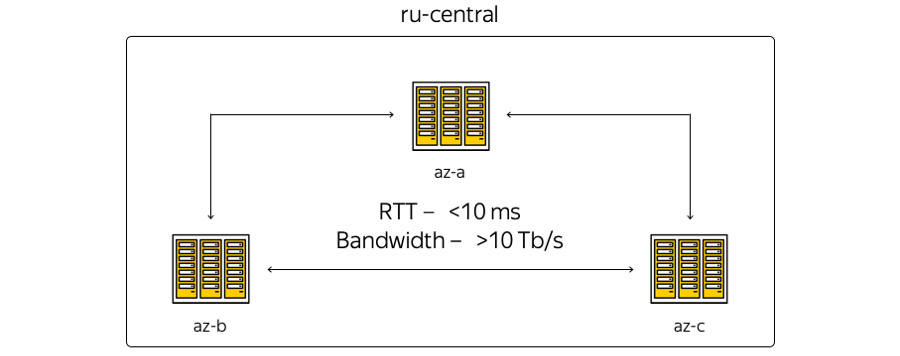
Ahora la infraestructura de la nube se basa en la región central de Rusia e incluye tres zonas de acceso, es decir, tres centros de datos independientes distribuidos geográficamente. Independiente: independiente entre sí en el contexto de redes, ingeniería y sistemas eléctricos, etc.
Sobre las características. La geografía de la ubicación de los centros de datos es tal que el tiempo de ida y vuelta (RTT) del tiempo de ida y vuelta entre ellos es siempre de 6 a 7 ms. La capacidad total de los canales ya ha excedido los 10 terabits y está en constante crecimiento, porque Yandex tiene su propia red de fibra óptica entre las zonas. Como no alquilamos canales de comunicación, podemos aumentar rápidamente la capacidad de la tira entre los DC: cada uno de ellos utiliza equipos de multiplexación espectral.
Aquí está la representación más esquemática de las zonas:
La realidad, a su vez, es ligeramente diferente:
Aquí está la red troncal actual de Yandex en la región. Todos los servicios de Yandex funcionan además, parte de la red es utilizada por la nube. (Esta es una imagen para uso interno, por lo tanto, la información del servicio se oculta deliberadamente. Sin embargo, es posible estimar el número de nodos y conexiones). La decisión de usar la red troncal fue lógica: no pudimos inventar nada, pero reutilizamos la infraestructura actual, "sufrió" durante los años de desarrollo.
¿Cuál es la diferencia entre la primera imagen y la segunda? En primer lugar, las zonas de acceso no están directamente relacionadas: los sitios técnicos se encuentran entre ellas. Los sitios no contienen equipos de servidor, solo dispositivos de red para garantizar que se les conecte. Los puntos de presencia donde Yandex y Cloud se conectan con el mundo exterior están conectados a sitios técnicos. Todos los puntos de presencia funcionan para toda la región. Por cierto, es importante tener en cuenta que desde el punto de vista del acceso externo desde Internet, todas las zonas de acceso a la nube son equivalentes. En otras palabras, proporcionan la misma conectividad, es decir, la misma velocidad y rendimiento, así como latencias igualmente bajas.
Además, hay equipos en los puntos de presencia, a los cuales, si hay recursos locales y un deseo de expandir la infraestructura local con instalaciones en la nube, los clientes pueden conectarse a través de un canal garantizado. Esto se puede hacer con la ayuda de socios o por su cuenta.
La red central es utilizada por la nube como un transporte MPLS.
MPLS
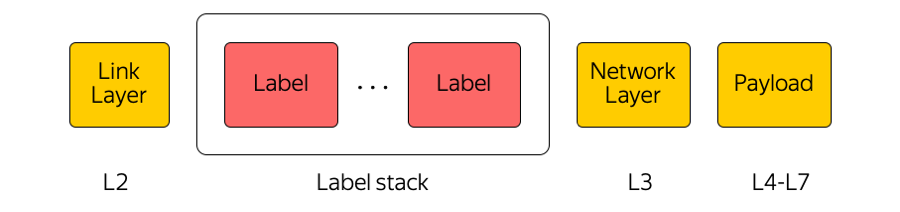
La conmutación de etiquetas multiprotocolo es una tecnología ampliamente utilizada en nuestra industria. Por ejemplo, cuando se transfiere un paquete entre zonas de acceso o entre una zona de acceso e Internet, el equipo de tránsito solo presta atención a la etiqueta superior, "sin pensar" en lo que hay debajo. De esta manera, MPLS le permite ocultar la complejidad de la nube de la capa de transporte. En general, nosotros en la nube somos muy aficionados a MPLS. Incluso lo hicimos parte del nivel inferior y lo usamos directamente en la fábrica de conmutación en el centro de datos:

(En realidad, hay muchos enlaces paralelos entre interruptores de hoja y espinas).
¿Por qué MPLS?
Es cierto que MPLS no se encuentra con frecuencia en las redes de centros de datos. A menudo se utilizan tecnologías completamente diferentes.
Usamos MPLS por varias razones. Primero, nos pareció conveniente unificar las tecnologías del plano de control y el plano de datos. Es decir, en lugar de algunos protocolos en la red del centro de datos, otros protocolos en la red central y la unión de estos protocolos: un solo MPLS. Por lo tanto, unificamos la pila tecnológica y redujimos la complejidad de la red.
En segundo lugar, en la nube, utilizamos varios dispositivos de red, como Cloud Gateway y Network Load Balancer. Necesitan comunicarse entre sí, enviar tráfico a Internet y viceversa. Estos dispositivos de red se pueden escalar horizontalmente con una carga creciente, y dado que la nube se construye de acuerdo con el modelo de hiperconvergencia, se pueden lanzar en cualquier lugar desde el punto de vista de la red en el centro de datos, es decir, en un grupo de recursos común.
Por lo tanto, estos dispositivos pueden comenzar detrás de cualquier puerto del conmutador de bastidor donde se encuentra el servidor y comenzar a comunicarse a través de MPLS con el resto de la infraestructura. El único problema en la construcción de tal arquitectura fue la alarma.
Alarma
La clásica pila de protocolos MPLS es bastante compleja. Esto, por cierto, es una de las razones de la no proliferación de MPLS en las redes de centros de datos.
Nosotros, a su vez, no utilizamos IGP (Protocolo de puerta de enlace interior) ni LDP (Protocolo de distribución de etiquetas) u otros protocolos de distribución de etiquetas. Solo se utiliza la etiqueta-unidifusión BGP (Border Gateway Protocol). Cada dispositivo, que se ejecuta, por ejemplo, como una máquina virtual, crea una sesión BGP antes del conmutador Leaf de montaje en bastidor.
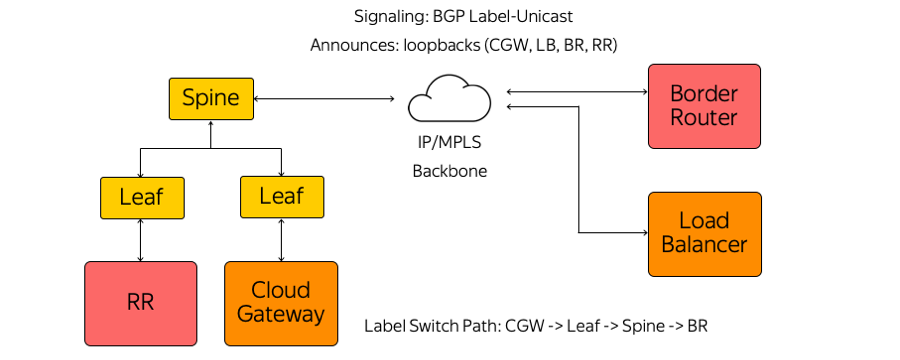
Una sesión BGP se construye en una dirección previamente conocida. No es necesario configurar automáticamente el conmutador para ejecutar cada dispositivo. Todos los interruptores están preconfigurados y son consistentes.
Dentro de una sesión de BGP, cada dispositivo envía su propio bucle de retorno y recibe bucles de retorno del resto de los dispositivos con los que necesitará intercambiar tráfico. Ejemplos de tales dispositivos son varios tipos de reflectores de ruta, enrutadores de borde y otros dispositivos. Como resultado, la información sobre cómo contactarse aparece en los dispositivos. Desde Cloud Gateway a través del conmutador Leaf, el conmutador Spine y la red hasta el enrutador de borde, se crea una ruta de conmutador de etiquetas. Los switches son L3 que se comportan como un Label Switch Router y no conocen la complejidad que los rodea.
MPLS en todos los niveles de nuestra red, entre otras cosas, nos ha permitido utilizar el concepto de Eat your own dogfood.
Come tu propia comida para perros
Desde el punto de vista de la red, este concepto implica que vivimos en la misma infraestructura que proporcionamos al usuario. Aquí hay diagramas de bastidores en áreas de accesibilidad:

Cloud host toma la carga del usuario, contiene sus máquinas virtuales. Y, literalmente, un host vecino en un bastidor puede transportar la carga de infraestructura desde el punto de vista de la red, incluidos los reflectores de ruta, la administración, los servidores de monitoreo, etc.
¿Por qué se hizo esto? Hubo la tentación de ejecutar reflectores de ruta y todos los elementos de infraestructura en un segmento separado tolerante a fallas. Luego, si el segmento de usuarios se hubiera desglosado en algún lugar del centro de datos, los servidores de infraestructura continuarían administrando toda la infraestructura de red. Pero este enfoque nos pareció cruel: si no confiamos en nuestra propia infraestructura, ¿cómo podemos proporcionarla a nuestros clientes? Después de todo, absolutamente toda la Nube, todas las redes virtuales, usuarios y servicios en la nube funcionan por encima.
Por lo tanto, abandonamos un segmento separado. Nuestros elementos de infraestructura se ejecutan en la misma topología de red y conectividad de red. Naturalmente, se ejecutan en una instancia triple, al igual que nuestros clientes lanzan sus servicios en la nube.
Fábrica de IP / MPLS
Aquí hay un diagrama de ejemplo de una de las zonas de disponibilidad:
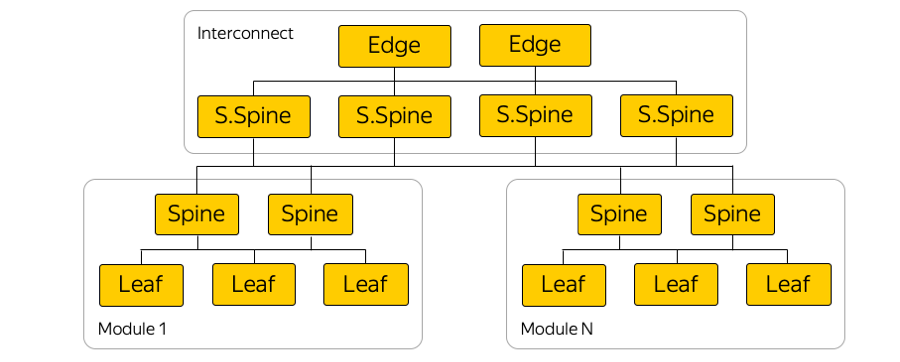
En cada zona de disponibilidad hay unos cinco módulos, y en cada módulo alrededor de cien bastidores. Interruptores montados en bastidor, están conectados dentro de su módulo por el nivel de la columna vertebral, y la conectividad entre módulos se proporciona a través de la interconexión de red. Este es el siguiente nivel, que incluye los llamados interruptores Super-Spines y Edge, que ya conectan las zonas de acceso. Abandonamos deliberadamente L2, solo estamos hablando de conectividad L3 IP / MPLS. BGP se utiliza para distribuir información de enrutamiento.
De hecho, hay muchas más conexiones paralelas que en la imagen. Un número tan grande de conexiones ECMP (ruta múltiple de igual costo) impone requisitos especiales de monitoreo. Además, a primera vista, hay límites inesperados en el equipo, por ejemplo, el número de grupos ECMP.
Conexión al servidor
Debido a las poderosas inversiones, Yandex crea servicios de tal manera que la falla de un servidor, rack de servidores, módulo o incluso un centro de datos completo nunca conduce a una parada completa del servicio. Si tenemos algún tipo de problema de red, supongamos que un interruptor de montaje en bastidor está roto, los usuarios externos nunca lo ven.
Yandex.Cloud es un caso especial. No podemos dictarle al cliente cómo construir sus propios servicios, y decidimos nivelar este posible único punto de falla. Por lo tanto, todos los servidores en la nube están conectados a dos conmutadores de montaje en bastidor.
Tampoco usamos ningún protocolo de redundancia en el nivel L2, pero inmediatamente comenzamos a usar solo L3 con BGP, nuevamente, por razones de unificación de protocolo. Esta conexión proporciona a cada servicio conectividad IPv4 e IPv6: algunos servicios funcionan sobre IPv4 y algunos servicios sobre IPv6.
Físicamente, cada servidor está conectado por dos interfaces de 25 gigabits. Aquí hay una foto del centro de datos:

Aquí puede ver dos conmutadores de montaje en bastidor con puertos de 100 gigabits. Los cables de ruptura divergentes son visibles, dividiendo el puerto de 100 gigabits del conmutador en 4 puertos de 25 gigabits por servidor. Llamamos a estos cables "hidra".
Gestión de infraestructuras
La infraestructura de red de la nube no contiene ninguna solución de gestión patentada: todos los sistemas son de código abierto con personalización para la nube o completamente autoescritas.
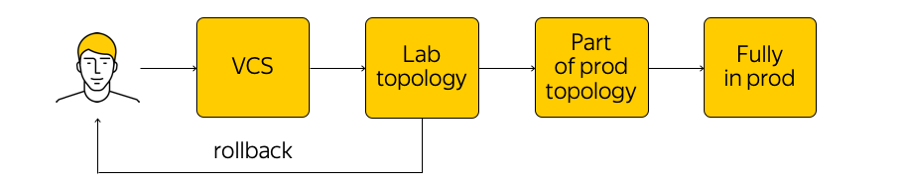
¿Cómo se gestiona esta infraestructura? No está tan prohibido en la nube, pero se desaconseja ir a un dispositivo de red y hacer cualquier ajuste. Existe el estado actual del sistema, y necesitamos aplicar los cambios: llegar a un nuevo estado objetivo. “Ejecute un script” en todas las glándulas, cambie algo en la configuración; no debe hacer esto. En cambio, hacemos cambios a las plantillas, a una sola fuente del sistema de verdad, y comprometemos nuestro cambio al sistema de control de versiones. Esto es muy conveniente, porque siempre puede hacer un retroceso, mirar el historial, averiguar quién es responsable del compromiso, etc.
Cuando realizamos los cambios, se generan configuraciones y las implementamos en la topología de prueba de laboratorio. Desde una perspectiva de red, esta es una pequeña nube que repite completamente toda la producción existente. Inmediatamente veremos si los cambios deseados rompen algo: en primer lugar, mediante monitoreo y, en segundo lugar, mediante comentarios de nuestros usuarios internos.
Si el monitoreo dice que todo está tranquilo, entonces continuamos implementando, pero aplicamos el cambio solo a una parte de la topología (dos o más accesibilidad "no tienen el derecho" de romper por la misma razón). Además, continuamos monitoreando de cerca el monitoreo. Este es un proceso bastante complicado, del que hablaremos a continuación.
Después de asegurarnos de que todo esté bien, aplicamos el cambio a toda la producción. En cualquier momento, puede retroceder y volver al estado anterior de la red, rastrear rápidamente y solucionar el problema.
Monitoreo
Necesitamos un monitoreo diferente. Uno de los más buscados es monitorear la conectividad de extremo a extremo. En cualquier momento, cada servidor debe poder comunicarse con cualquier otro servidor. El hecho es que si hay un problema en algún lugar, entonces queremos saber exactamente dónde lo antes posible (es decir, qué servidores tienen problemas para acceder entre sí). Asegurar la conectividad de extremo a extremo es nuestra principal preocupación.
Cada servidor enumera un conjunto de todos los servidores con los que debería poder comunicarse en un momento dado. El servidor toma un subconjunto aleatorio de este conjunto y envía paquetes ICMP, TCP y UDP a todas las máquinas seleccionadas. Esto verifica si hay pérdidas en la red, si la demora ha aumentado, etc. Se “llama” a toda la red dentro de una de las zonas de acceso y entre ellas. Los resultados se envían a un sistema centralizado que los visualiza para nosotros.
Así es como se ven los resultados cuando no todo es muy bueno:
Aquí puede ver qué segmentos de red hay un problema entre (en este caso, A y B) y dónde está todo bien (A y D). Aquí se pueden mostrar servidores específicos, conmutadores montados en bastidor, módulos y zonas de disponibilidad completas. Si alguno de los anteriores se convierte en la fuente del problema, lo veremos en tiempo real.
Además, hay monitoreo de eventos. Supervisamos de cerca todas las conexiones, los niveles de señal en los transceptores, las sesiones de BGP, etc. Supongamos que se construyen tres sesiones de BGP a partir de un segmento de red, una de las cuales se interrumpió por la noche. Si configuramos el monitoreo para que la caída de una sesión de BGP no sea crítica para nosotros y pueda esperar hasta la mañana, entonces el monitoreo no despertará a los ingenieros de red. Pero si cae la segunda de las tres sesiones, un ingeniero llama automáticamente.
Además del monitoreo de extremo a extremo y de eventos, utilizamos una colección centralizada de registros, su análisis en tiempo real y su posterior análisis. Puede ver las correlaciones, identificar problemas y descubrir qué estaba sucediendo en el equipo de red.
El tema de monitoreo es lo suficientemente amplio, hay un gran margen para mejoras. Quiero llevar el sistema a una mayor automatización y una verdadera autocuración.
Que sigue
Tenemos muchos planes Es necesario mejorar los sistemas de control, monitoreo, conmutación de fábricas IP / MPLS y mucho más.
También estamos buscando activamente interruptores de caja blanca. Este es un dispositivo de "hierro" listo para usar, un interruptor en el que puede mover su software. En primer lugar, si todo se hace correctamente, será posible "tratar" los conmutadores de la misma manera que a los servidores, crear un proceso de CI / CD realmente conveniente, implementar configuraciones de forma incremental, etc.
En segundo lugar, si hay algún problema, es mejor mantener un grupo de ingenieros y desarrolladores que solucionen estos problemas que esperar mucho tiempo por una solución del proveedor.
Para que todo funcione, el trabajo está en marcha en dos direcciones:
- Redujimos significativamente la complejidad de la fábrica de IP / MPLS. Por un lado, el nivel de la red virtual y las herramientas de automatización de esto, por el contrario, se han vuelto un poco más complicadas. Por otro lado, la red subyacente se ha vuelto más fácil. En otras palabras, hay una cierta "cantidad" de complejidad que no se puede guardar. Se puede "lanzar" de un nivel a otro, por ejemplo, entre niveles de red o desde el nivel de red al nivel de aplicación. Y puede distribuir correctamente esta complejidad, que estamos tratando de hacer.
- Y, por supuesto, estamos finalizando nuestro conjunto de herramientas para administrar toda la infraestructura.
Esto es todo lo que queríamos hablar sobre nuestra infraestructura de red.
Aquí hay un enlace al canal Cloud Telegram con noticias y consejos.