Este artículo fue escrito en conjunción con ananaskelly .
Introduccion
Hola a todos, Habr! Trabajando en el Centro de Tecnología del Habla en San Petersburgo, hemos adquirido un poco de experiencia en la solución de problemas de clasificación y detección de eventos acústicos y decidimos que estamos listos para compartirlo con usted. El propósito de este artículo es presentarle algunas tareas y hablar sobre el concurso de procesamiento automático de sonido DCASE 2018 . Al contarle sobre el concurso, lo haremos sin fórmulas y definiciones complejas relacionadas con el aprendizaje automático, por lo que el público entenderá el significado general del artículo.
Para aquellos que se sintieron atraídos por el ensamblaje del clasificador , preparamos un pequeño código de Python, y desde el enlace en el github puedes encontrar un cuaderno donde, usando la segunda pista del concurso DCASE como ejemplo, creamos una red convolucional simple en keras para clasificar archivos de audio. Allí hablamos un poco sobre la red y las características utilizadas para la capacitación, y cómo usar una arquitectura simple para obtener un resultado cercano a la línea de base ( MAP @ 3 = 0.6).
Además, aquí se describirán los enfoques básicos para resolver problemas (línea de base) propuestos por los organizadores. También en el futuro habrá varios artículos donde hablaremos con más detalle y en detalle tanto sobre nuestra experiencia en participar en la competencia como sobre las soluciones propuestas por otros participantes en la competencia. Los enlaces a estos artículos aparecerán gradualmente aquí.
Seguramente, muchas personas no tienen absolutamente ninguna idea sobre algún tipo de "DCASE" , así que averigüemos qué tipo de fruta es y con qué se come. La competencia " DCASE " se celebra anualmente, y cada año se dedican varias tareas a resolver problemas en el campo de la clasificación de grabaciones de audio y la detección de eventos acústicos. Cualquiera puede participar en la competencia, es gratis, para esto es suficiente simplemente registrarse en el sitio como participante. Como resultado de la competencia, se lleva a cabo una conferencia sobre los mismos temas, pero, a diferencia de la competencia en sí, la participación en ella ya está pagada, y ya no hablaremos más al respecto. Por lo general, no se confía en las recompensas por las mejores decisiones, pero hay excepciones (por ejemplo, la tercera tarea en 2018). Este año, los organizadores propusieron las siguientes 5 tareas:
- Clasificación de escenas acústicas (subdivididas en 3 subtareas)
A. Conjuntos de datos de entrenamiento y prueba registrados en el mismo dispositivo
B. conjuntos de datos de entrenamiento y prueba grabados en diferentes dispositivos
C. La capacitación se permite utilizando datos no proporcionados por los organizadores. - Clasificación de eventos acústicos
- Detección de canto de pájaros
- Detección de eventos acústicos en el hogar utilizando un conjunto de datos con etiquetas débiles.
- Clasificación de la actividad del hogar en la sala según grabación multicanal
Sobre detección y clasificación
Como podemos ver, los nombres de todas las tareas contienen una de dos palabras: "detección" o "clasificación". Aclaremos cuál es la diferencia entre estos conceptos para que no haya confusión.
Imagine que tenemos una grabación de audio en la que un perro ladra en un momento, y un gato maúlla en otro, y simplemente no hay otros eventos allí. Entonces, si queremos entender exactamente cuándo ocurren estos eventos, entonces tenemos que resolver el problema de detectar un evento acústico. Es decir, necesitamos averiguar los tiempos de inicio y finalización de cada evento. Una vez resuelto el problema de detección, descubrimos exactamente cuándo ocurren los eventos, pero no sabemos quién hace exactamente los sonidos encontrados, entonces necesitamos resolver el problema de clasificación, es decir, determinar qué sucedió exactamente en un período de tiempo determinado.
Para comprender la descripción de las tareas de la competencia, estos ejemplos serán suficientes, lo que significa que la parte introductoria está completa, y podemos proceder a una descripción detallada de las tareas mismas.
Pista 1. Clasificación de escenas acústicas
La primera tarea es determinar el entorno (escena acústica) en el que se grabó el audio, por ejemplo, "Estación de Metro", "Aeropuerto" o "Calle peatonal". La solución a este problema puede ser útil para evaluar el entorno con un sistema de inteligencia artificial, por ejemplo, en automóviles con piloto automático.
En esta tarea, los conjuntos de datos móviles TUT Urban Acoustic Scenes 2018 y TUT Urban Acoustic Scenes 2018 Mobile, que fueron preparados por la Universidad Tecnológica de Tampere (Finlandia), se presentaron para capacitación. En el artículo se describe una descripción detallada de la preparación del conjunto de datos, así como la solución básica.
En total, se presentaron 10 escenas acústicas para la competencia, que los participantes tuvieron que predecir.
Subtarea A
Como ya dijimos, la tarea se divide en 3 subtareas, cada una de las cuales difiere en la calidad de las grabaciones de audio. Por ejemplo, en la subtarea A, se utilizaron micrófonos especiales para la grabación, que se ubicaron en los oídos humanos. Por lo tanto, la grabación estéreo se hizo más cercana a la percepción humana del sonido. Los participantes tuvieron la oportunidad de utilizar este enfoque de grabación para mejorar la calidad del reconocimiento de la escena acústica.
Subtarea B
En la subtarea B, también se utilizaron otros dispositivos (por ejemplo, teléfonos móviles) para la grabación. Los datos de la subtarea A se convirtieron a un formato mono, la frecuencia de muestreo se redujo, no hay simulación de la "audibilidad" del sonido por parte de una persona en el conjunto de datos para esta tarea, pero hay más datos para la capacitación.
Subtarea C
El conjunto de datos para la subtarea C es el mismo que en la subtarea A, pero al resolver este problema se permite usar cualquier dato externo que el participante pueda encontrar. El objetivo de resolver este problema es descubrir si es posible mejorar el resultado obtenido en la subtarea A utilizando datos de terceros.
La calidad de las decisiones en esta pista fue evaluada por la métrica de precisión .
La línea de base para esta tarea es una red neuronal convolucional de dos capas que aprende de los logaritmos de pequeños espectrogramas de los datos de audio originales. La arquitectura propuesta utiliza las técnicas estándar de BatchNormalization y Dropout. El código en GitHub se puede ver aquí .
Pista 2. Clasificación de eventos acústicos
En esta tarea, se propone crear un sistema que clasifique los eventos acústicos. Tal sistema puede ser una adición a hogares inteligentes, aumentar la seguridad en lugares concurridos o facilitar la vida de las personas con discapacidad auditiva.
El conjunto de datos para esta tarea consiste en archivos tomados del conjunto de datos Freesound y etiquetados con etiquetas del AudioSet de Google. Más detalladamente, el proceso de preparación del conjunto de datos se describe en un artículo preparado por los organizadores del concurso.
Volvamos a la tarea en sí, que tiene varias características.
En primer lugar, los participantes tuvieron que crear un modelo capaz de identificar diferencias entre eventos acústicos de una naturaleza muy diferente. El conjunto de datos se divide en la clase 41, presenta varios instrumentos musicales, sonidos hechos por humanos, animales, sonidos domésticos y más.
En segundo lugar, además del marcado habitual de datos, también hay información adicional sobre cómo verificar la etiqueta manualmente. Es decir, los participantes saben qué archivos del conjunto de datos fueron verificados por la persona para verificar el cumplimiento de la etiqueta, y cuáles no. Como lo ha demostrado la práctica, los participantes que de alguna manera usaron esta información adicional se llevaron premios para resolver este problema.
Además, debe decirse que la duración de los registros en el conjunto de datos varía mucho: de 0.3 segundos a 30 segundos. En este problema, la cantidad de datos por clase, sobre la cual el modelo necesita ser entrenado, también varía mucho. Esto se representa mejor como un histograma, el código para construir que se toma de aquí .
Como puede ver en el histograma, el marcado manual para las clases presentadas también está desequilibrado, lo que agrega dificultad si desea utilizar esta información al entrenar modelos.
Los resultados en esta pista se evaluaron utilizando la métrica de precisión promedio (Precisión media promedio, MAP @ 3), una demostración bastante simple de calcular esta métrica con ejemplos y código se puede encontrar aquí .
Pista 3. Detección de canto de pájaros
La siguiente pista es la detección del canto de los pájaros. Un problema similar surge, por ejemplo, en varios sistemas de monitoreo automático de la vida silvestre: este es el primer paso en el procesamiento de datos antes, por ejemplo, de la clasificación. Dichos sistemas a menudo necesitan ajuste, son inestables a las nuevas condiciones acústicas, por lo tanto, el propósito de esta pista es recurrir al poder del aprendizaje automático para resolver tales problemas.
Esta pista es una versión extendida del concurso "Desafío de detección de audio de aves" organizado por la Universidad de Santa María de Londres en 2017/2018. Para aquellos interesados , puede leer el artículo de los autores de la competencia, que proporciona detalles sobre la formación de datos, la organización de la competencia y un análisis de las decisiones tomadas.
Sin embargo, volvamos a la tarea DCASE. Los organizadores proporcionaron seis conjuntos de datos, tres para entrenamiento, tres para prueba, todos son muy diferentes, grabados en diferentes condiciones acústicas, usando varios dispositivos de grabación, y hay varios ruidos en el fondo. Por lo tanto, el mensaje principal es que el modelo no debe depender del entorno ni ser capaz de adaptarse a él. A pesar de que el nombre significa "detección", la tarea no es determinar los límites del evento, sino en una clasificación simple: la solución final es un tipo de clasificador binario que recibe una breve entrada de audio y decide si hay un pájaro cantando o no. . La métrica de AUC se utilizó para evaluar la precisión.
En su mayoría, los participantes trataron de lograr la generalización y adaptación a través de varios aumentos de datos. Uno de los comandos describe la aplicación de varias técnicas: cambiar la resolución de frecuencia en las características extraídas, reducción de ruido preliminar, un método de adaptación basado en la alineación de estadísticas de segundo orden para diferentes conjuntos de datos. Sin embargo, tales métodos, así como los diferentes tipos de aumento, dan un aumento muy pequeño sobre la solución básica, como señalan muchos participantes.
Como solución básica, los autores prepararon una modificación de la solución más exitosa de la competencia original "Bird Audio Detection Challenge". El código, como de costumbre, está disponible en el github .
Pista 4. Detección de eventos acústicos en el hogar utilizando un conjunto de datos débilmente etiquetado.
En la cuarta pista, el problema de detección ya está resuelto directamente. Los participantes recibieron un conjunto de datos relativamente pequeño de datos etiquetados: un total de 1578 grabaciones de audio de 10 segundos cada una, con solo marcado de clase: se sabe que el archivo contiene uno o más eventos de estas clases, pero no hay marcado temporal. Además, se proporcionaron dos grandes conjuntos de datos de datos no asignados: 14412 archivos que contienen eventos objetivo de las mismas clases que en las muestras de entrenamiento y prueba, así como 39999 archivos que contienen eventos arbitrarios que no se incluyeron en los objetivos. Todos los datos son un subconjunto del enorme conjunto de datos de audioset compilado por google .
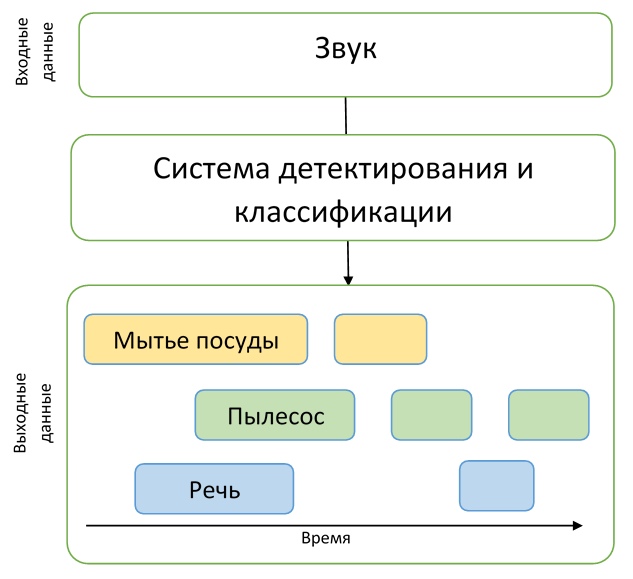
Por lo tanto, los participantes debían crear un modelo capaz de aprender de datos con etiquetas débiles para encontrar marcas de tiempo del comienzo y el final de los eventos (los eventos pueden superponerse) e intentar mejorarlo con una gran cantidad de datos adicionales sin marcar. Además, vale la pena señalar que se utilizó una métrica bastante rígida en esta pista: era necesario predecir las etiquetas de tiempo de los eventos con una precisión de 200 ms. En general, los participantes tuvieron que resolver una tarea bastante difícil de crear un modelo adecuado, mientras prácticamente no tenían buenos datos para la capacitación.
La mayoría de las soluciones se basaron en redes de recurrencia convolucional, una arquitectura bastante popular en el campo de la detección de eventos acústicos en los últimos tiempos (un ejemplo se puede encontrar aquí ).
La solución básica de los autores, también en redes recursivas convolucionales, se basa en dos modelos. Los modelos tienen casi la misma arquitectura: tres capas convolucionales y una recursiva. La única diferencia son las redes de salida. El primer modelo está entrenado para marcar datos no asignados para expandir el conjunto de datos original, por lo tanto, en la salida tenemos clases presentes en el archivo de eventos. El segundo es para resolver el problema de detección directamente, es decir, en la salida obtenemos una marca temporal para el archivo. Código para el enlace .
Pista 5. Clasificación de la actividad del hogar en la sala según la grabación multicanal.
La última pista difería de las otras principalmente en que a los participantes se les ofrecieron grabaciones multicanal. La tarea en sí estaba en la clasificación: es necesario predecir la clase de eventos que ocurrieron en el registro. A diferencia de la pista anterior, la tarea es algo más simple: se sabe que solo hay un evento en el registro.
El conjunto de datos está representado por aproximadamente 200 horas de grabaciones en una matriz lineal de 4 micrófonos. Los eventos son todo tipo de actividades cotidianas: cocinar, lavar platos, actividades sociales (hablar por teléfono, visitas y conversaciones personales), etc., también se destaca la clase de ausencia de eventos.
Los autores de la pista enfatizan que las condiciones de la tarea son relativamente simples, de modo que los participantes se centran directamente en el uso de información espacial de grabaciones multicanal. Los participantes también tuvieron la oportunidad de utilizar datos adicionales y modelos previamente entrenados. La calidad se evaluó de acuerdo con la medida F1.
Como solución básica, los autores de la pista propusieron una red convolucional simple con dos capas convolucionales. En su solución, no se utilizó la información espacial: los datos de cuatro micrófonos se utilizaron para el entrenamiento de forma independiente, y las predicciones se promediaron durante las pruebas. La descripción y el código están disponibles en el enlace .
Conclusión
En el artículo, tratamos de hablar brevemente sobre la detección de eventos acústicos y sobre una competencia como DCASE. Tal vez pudieron interesar a alguien para participar en 2019: la competencia comienza en marzo.