Esta es la primera parte del artículo en el que hablaré sobre cómo construimos el proceso de trabajar en un gran proyecto de migración de base de datos: sobre experimentos seguros, planificación de equipos e interacción entre equipos. En los siguientes artículos, hablaré con más detalle sobre los problemas técnicos que resolvimos: sobre el escalado y la tolerancia a fallas de PostgreSQL y las pruebas de carga.
Durante mucho tiempo, la base de datos principal en Miro (ex-RealtimeBoard) fue Redis. Almacenamos en él toda la información básica: datos sobre usuarios, cuentas, juntas, etc. Todo funcionó rápidamente, pero nos encontramos con una serie de problemas.
Problemas con Redis- Dependencia de la latencia de la red. Ahora en nuestra nube es aproximadamente 20 hora de Moscú, pero cuando lo aumente, la aplicación comenzará a funcionar muy lentamente.
- La falta de índices que necesitamos a nivel de lógica empresarial. Su implementación independiente puede complicar la lógica del negocio y generar inconsistencias en los datos.
- La complejidad del código también dificulta mantener la consistencia de los datos.
- Intensidad de recursos de consultas con selecciones.
Estos problemas, junto con un aumento en la cantidad de datos en los servidores, sirvieron como la razón para la migración de la base de datos.
Declaración del problema.
Se ha tomado la decisión sobre la migración. El siguiente paso es comprender qué base de datos es adecuada para nuestro modelo de datos.
Realizamos un estudio para seleccionar la base de datos óptima para nosotros y nos decidimos por PostgreSQL. Nuestro modelo de datos encaja bien con una base de datos relacional: PostgreSQL tiene herramientas integradas para garantizar la coherencia de los datos, hay un tipo JSONB y la capacidad de indexar ciertos campos en JSONB. Nos queda bien.
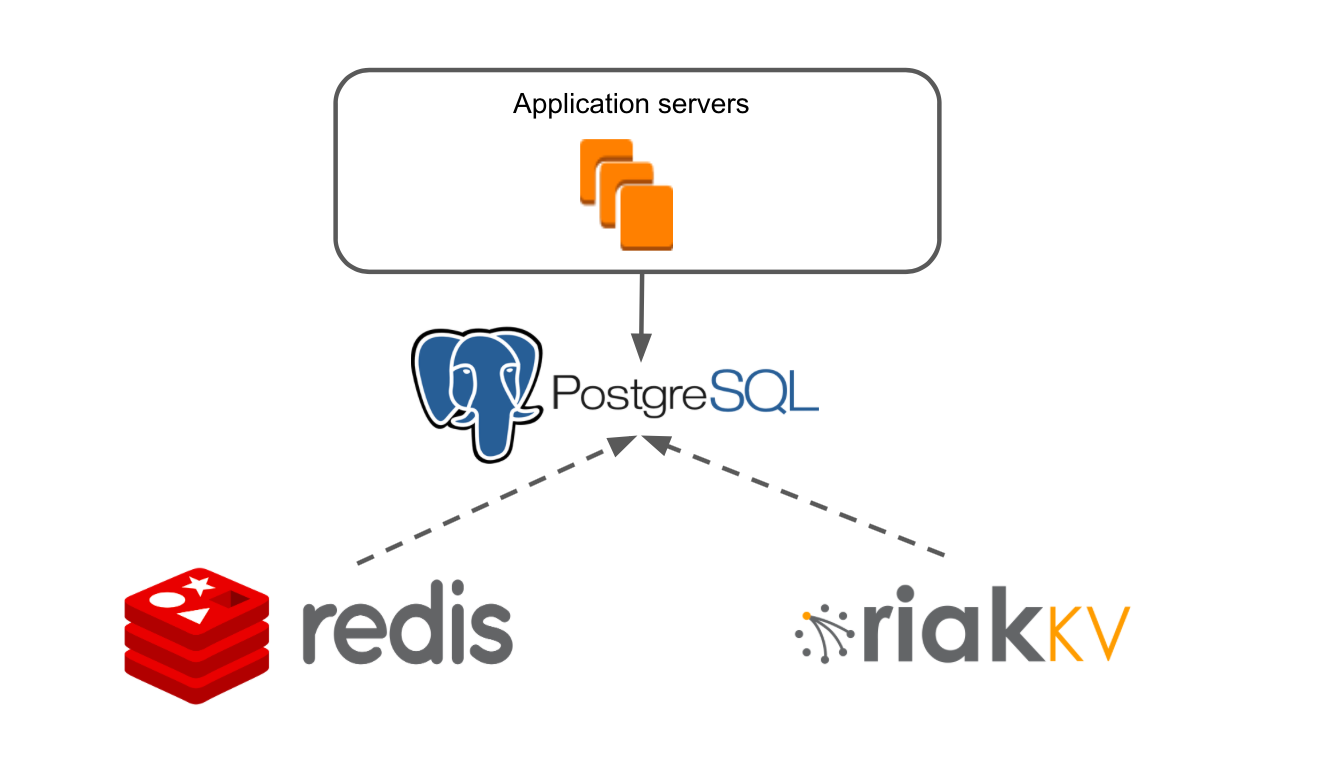
La arquitectura simplificada de nuestra aplicación se veía así: hay servidores de aplicaciones que acceden a Redis y RiakKV a través de la capa de datos.
Nuestro servidor de aplicaciones es una aplicación Java monolítica. La lógica de negocios está escrita en un marco adaptado para NoSQL. La aplicación tiene su propio sistema transaccional, que le permite proporcionar múltiples usuarios en cualquiera de nuestros foros.
Utilizamos RiakKV para almacenar datos de tableros de archivo que no se abrieron durante 7 días.
Agregue PostgreSQL a este esquema. Hacemos que los servidores de aplicaciones funcionen con la nueva base de datos. Copie datos de Redis y RiakKV a PostgreSQL. ¡El problema está resuelto!
Nada complicado, pero hay matices:- Tenemos 2,2 millones de usuarios registrados. Todos los días, Miro emplea a 50 mil usuarios, la carga máxima es de hasta 14 mil a la vez. Los usuarios no deben encontrar errores debido a nuestro trabajo, generalmente no deben notar el momento de mudarse a una nueva base.
- 1 TB de datos en la base de datos o 410 millones de objetos.
- Lanzamiento continuo de nuevas características por otros equipos, cuyo trabajo no debería interferir.
Opciones para resolver el problema.
Nos enfrentamos a dos opciones para la migración de datos:
- Detenga el desarrollo del servicio → vuelva a escribir el código en el servidor → pruebe la funcionalidad → inicie una nueva versión.
- Realice una migración sin problemas: transfiera gradualmente partes del producto a una nueva base de datos, admitiendo tanto PostgreSQL como Redis y sin interrumpir el desarrollo de nuevas características.
Detener el desarrollo de un servicio es una pérdida de tiempo que podríamos utilizar para el crecimiento, lo que significa una pérdida de usuarios y cuota de mercado. Esto es crítico para nosotros, por lo que elegimos la opción con migración fluida. A pesar de que, en complejidad, este proceso se puede comparar con el reemplazo de las ruedas de un automóvil mientras se conduce.
Al evaluar el trabajo, dividimos nuestro producto en bloques principales: usuarios, cuentas, juntas, etc. Por separado, se trabajó para crear la infraestructura de PostgreSQL. Y ponen riesgos en la evaluación en caso de que algo salga mal (como sucedió).
Sprints y objetivos
El siguiente paso es formar un equipo de cinco personas para que todos se muevan a la velocidad correcta hacia un objetivo común.
Tenemos dos puntos: el comienzo del trabajo en la tarea y el objetivo final. Ideal cuando nos movemos hacia la meta de manera directa. Pero a menudo sucede que queremos ir por el camino recto, pero resulta así:
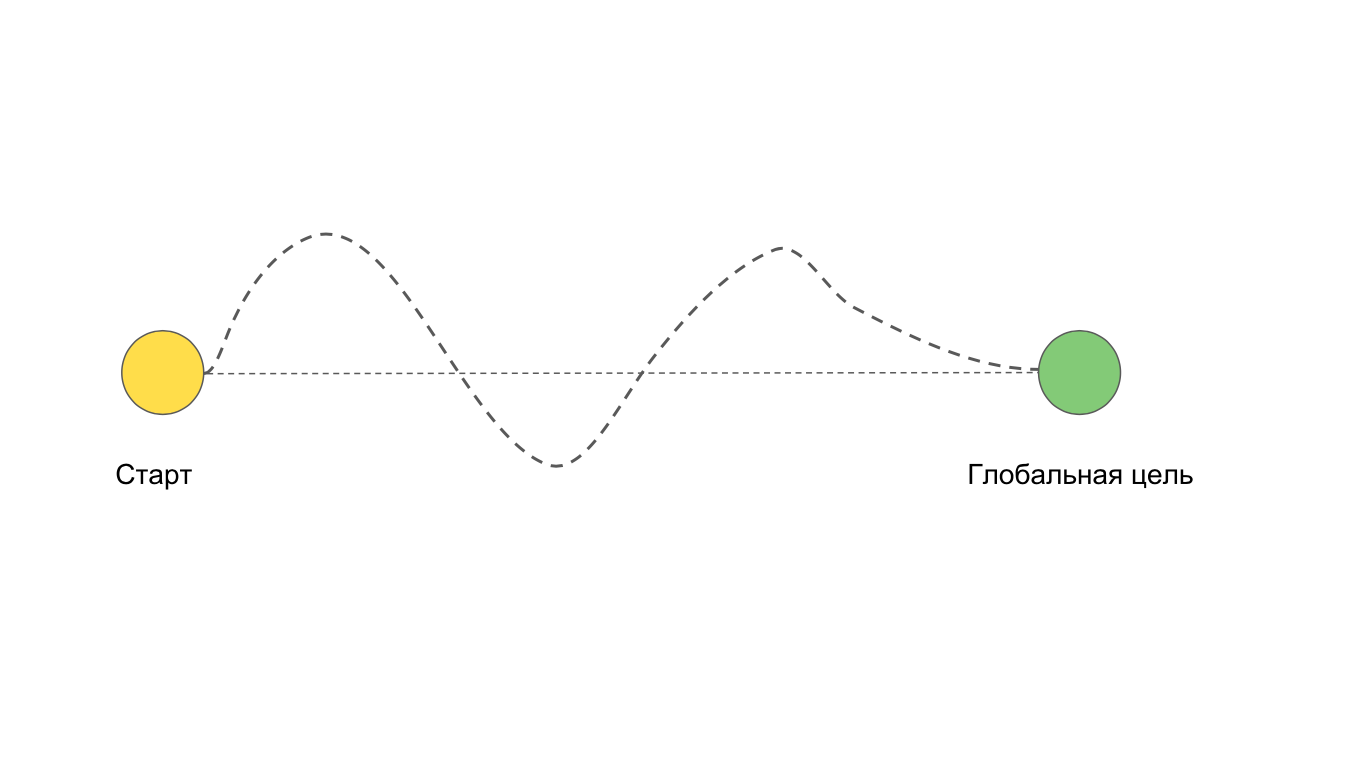
Por ejemplo, debido a dificultades y problemas que no podían preverse de antemano.
Es posible una situación en la que no alcanzaremos la meta en absoluto. Por ejemplo, si entramos en una refactorización profunda o reescribimos toda la aplicación.
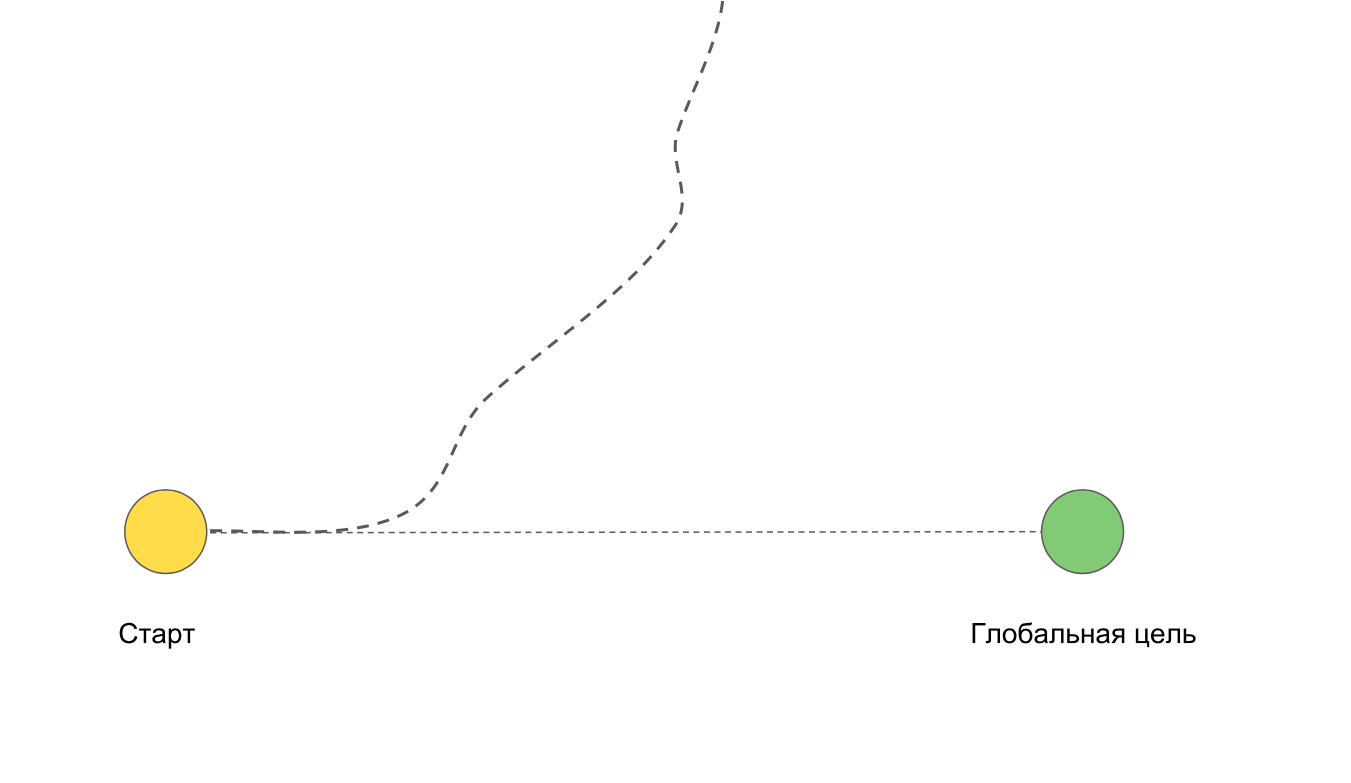
Dividimos la tarea en sprints semanales para minimizar las dificultades descritas anteriormente. Si el equipo se retira repentinamente a un lado, puede regresar rápidamente con pérdidas mínimas para el proyecto, ya que las iteraciones cortas no le permiten ir demasiado lejos "al revés".
Cada iteración tiene su propio objetivo, que mueve al equipo al gran resultado final.

Si aparece una nueva tarea durante el sprint, evaluamos si su implementación nos acerca al objetivo. Sí, tome el próximo sprint o cambie las prioridades en el actual, si no, no lo tome. Si aparecen errores, les damos alta prioridad y los corregimos rápidamente.
Sucede que los desarrolladores dentro de un sprint deben realizar tareas en una secuencia estrictamente definida. O, por ejemplo, el desarrollador entrega la tarea finalizada al ingeniero de control de calidad para realizar pruebas urgentes. En la etapa de planificación, intentamos construir relaciones similares entre tareas para cada miembro del equipo. Esto permite que todo el equipo vea quién hará qué y cuándo, sin olvidar la dependencia de los demás.
El equipo tiene sincronizaciones diarias y semanales. Todas las mañanas, discutimos quién, qué y qué prioridad hará hoy. Después de cada sprint, nos sincronizamos entre nosotros para asegurarnos de que todos se muevan en la dirección correcta. Asegúrese de planificar lanzamientos grandes o complejos. Nombramos desarrolladores en servicio que, si es necesario, están presentes durante el lanzamiento y supervisan que todo esté en orden.
La planificación y la sincronización dentro del equipo permiten involucrar a todos los participantes en todas las etapas del proyecto. Los planes y evaluaciones no nos llegan desde arriba, los hacemos nosotros mismos. Esto aumenta la responsabilidad e interés del equipo en completar las tareas.
Este es uno de nuestros sprints. Llevamos todo en el tablero de Miro:

Modos y experimentos seguros
Durante la migración, tuvimos que garantizar el funcionamiento estable del servicio en condiciones de combate. Para hacer esto, debe asegurarse de que todo esté probado y de que no haya errores en ningún lado. Para lograr este objetivo, decidimos hacer que nuestra migración sea más fluida.
La idea era cambiar gradualmente los bloques de productos a una nueva base de datos. Para hacer esto, se nos ocurrió una secuencia de modos.
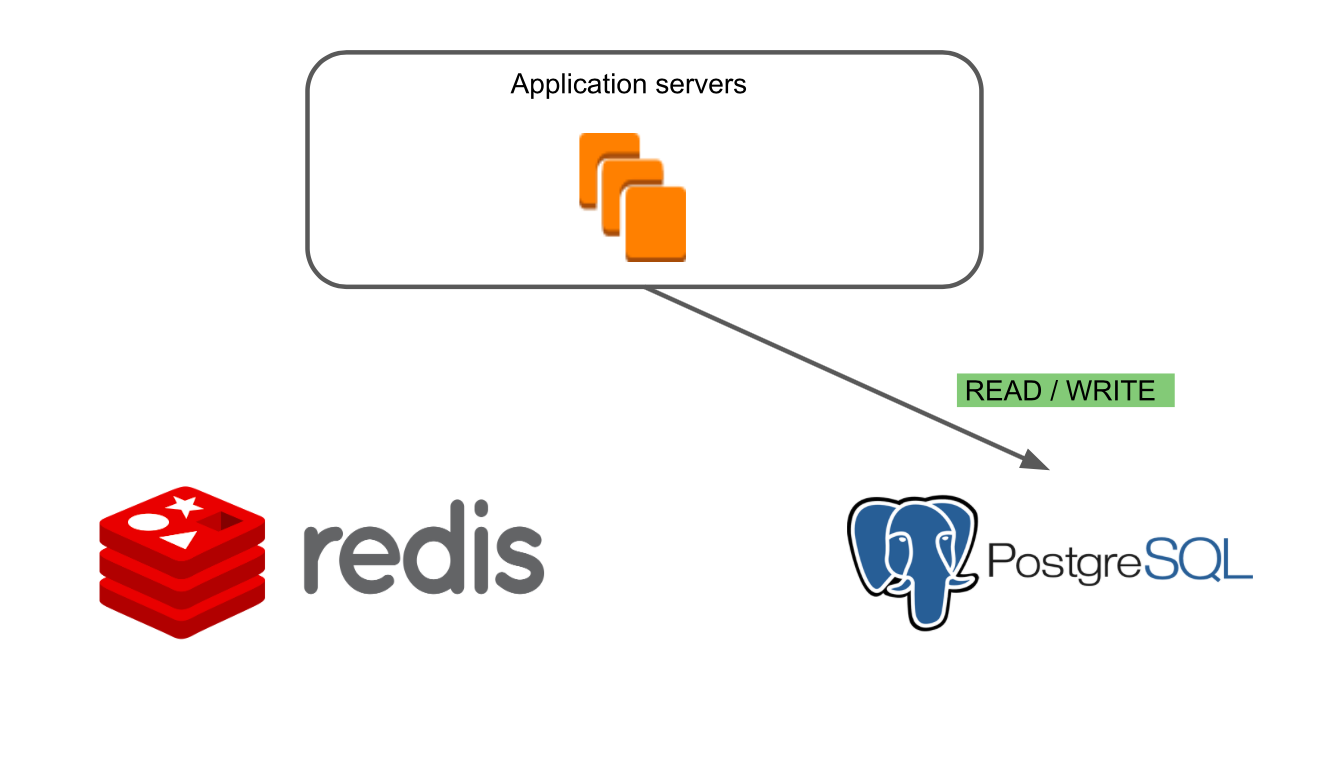
En el primer modo “Redis Read / Write”, solo funciona la base de datos anterior, Redis.
 En el segundo modo “Escritura pasiva PostgreSQL”,
En el segundo modo “Escritura pasiva PostgreSQL”, podemos asegurarnos de que la escritura en la nueva base de datos sea correcta y las bases de datos sean consistentes.
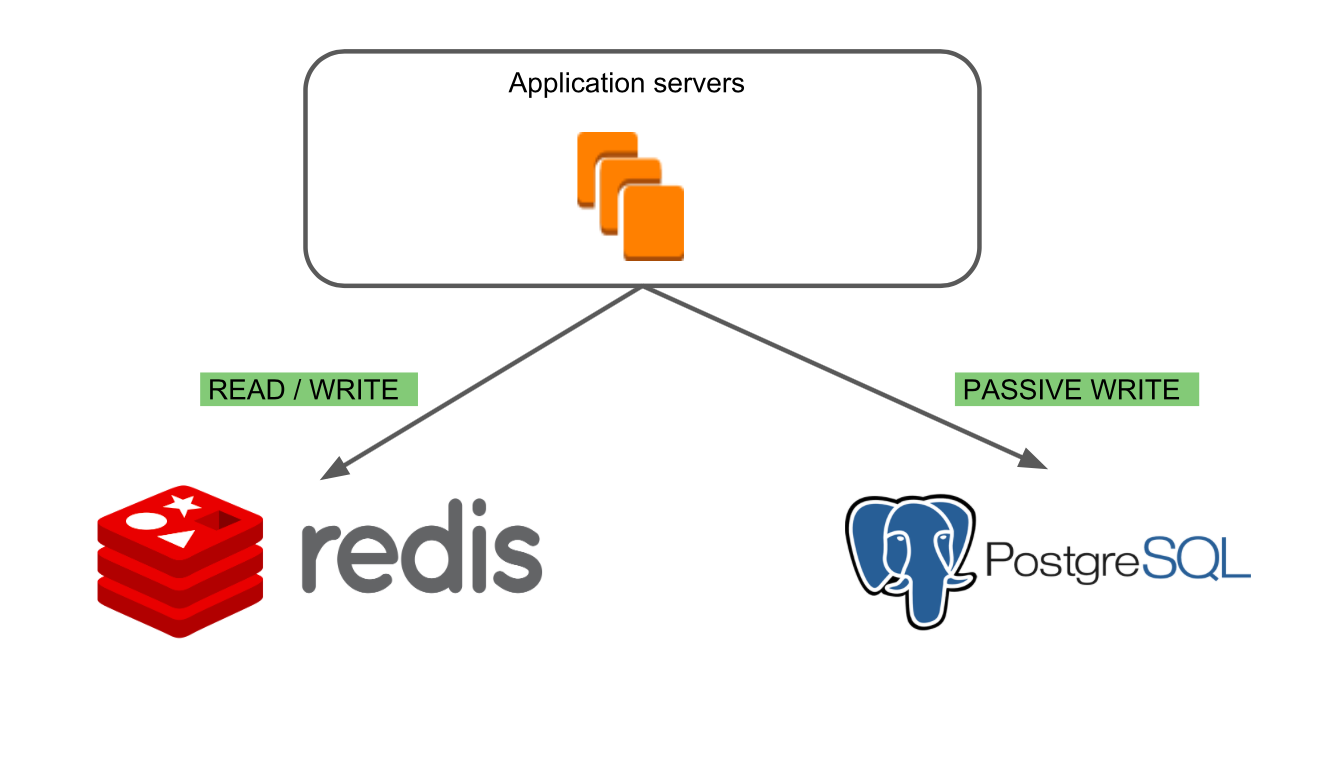 El tercer modo "PostgreSQL Read / Write, Redis Passive Write" le
El tercer modo "PostgreSQL Read / Write, Redis Passive Write" le permite verificar la exactitud de la lectura de datos de PostgreSQL y ver cómo se comporta la nueva base de datos en condiciones de combate. Al mismo tiempo, Redis sigue siendo la base principal, lo que nos permitió encontrar casos específicos de trabajo con tableros que podrían conducir a errores.
 En el último modo "PostgreSQL Read / Write",
En el último modo "PostgreSQL Read / Write", solo se ejecuta la nueva base de datos.
El trabajo de migración podría afectar las funciones principales del producto, por lo que teníamos que estar 100% seguros de que no romperemos nada y que la nueva base de datos funciona al menos tan lentamente como la anterior. Por lo tanto, comenzamos a realizar experimentos seguros con modos de conmutación.
Comenzamos a cambiar de modo en nuestra cuenta corporativa, que usamos diariamente en el trabajo. Después de asegurarnos de que no hubiera errores, comenzamos a cambiar de modo en una pequeña selección de usuarios externos.
La línea de tiempo de los experimentos de lanzamiento con los modos es la siguiente:
- Enero-febrero: Redis leer / escribir
- Marzo-abril: escritura pasiva PostgreSQL
- Mayo-junio: lectura / escritura de PostgreSQL, base de datos principal - Redis
- Julio-agosto: lectura / escritura de PostgreSQL
- Septiembre-diciembre: migración completa.
Si ocurrieran errores, tuvimos la oportunidad de corregirlos rápidamente, porque nosotros mismos podríamos hacer lanzamientos en los servidores donde trabajaban los usuarios que participaron en el experimento. No dependíamos de la versión principal, por lo que reparamos los errores rápidamente y en cualquier momento.
Colaboración entre equipos
Durante la migración, a menudo nos cruzamos con equipos que lanzaron nuevas funciones. Tenemos una única base de código y, como parte de su trabajo, los equipos podrían cambiar las estructuras existentes en una nueva base de datos o crear otras nuevas. Al mismo tiempo, podrían ocurrir intersecciones de equipos para el desarrollo y retiro de nuevas características. Por ejemplo, uno de los equipos de productos prometió al equipo de marketing lanzar una nueva función en una fecha específica; el equipo de marketing ha planeado una campaña publicitaria para este período; Un equipo de ventas está esperando que una función y una campaña comiencen a comunicarse con nuevos clientes. Resulta que todos dependen unos de otros, y retrasar los plazos de un equipo interrumpe los planes del otro.
Para evitar tales situaciones, nosotros, junto con otros equipos, compilamos una sola hoja de ruta de comestibles, que se sincronizó varias veces por trimestre, y con algunos equipos semanalmente.
Conclusiones
Lo que aprendimos durante este proyecto:
- No tengas miedo de asumir proyectos complejos. Después de la descomposición, evaluación y desarrollo de enfoques de trabajo, los proyectos complejos dejan de parecer imposibles.
- No pierda tiempo y esfuerzo en estimaciones preliminares, descomposición y planificación. Esto ayuda a comprender el problema más profundamente antes de comenzar a trabajar en él y a comprender el volumen y la complejidad del trabajo.
- Poner riesgos en proyectos técnicos y organizativos difíciles. En el proceso de trabajo, seguramente encontrará un problema que no se tuvo en cuenta al planificar.
- No migre a menos que sea necesario.
En los siguientes artículos hablaré más sobre los problemas técnicos que resolvimos durante la migración.