Hola de nuevo
Colegas, el último día de enero, estamos lanzando el curso
"MS SQL Server Developer" , en relación con el cual hemos tenido una lección temática abierta. En él hablamos sobre cómo MS SQL Server ejecuta una consulta SELECT, discutimos en qué orden y qué se analiza, y también nos sumergimos un poco en la lectura del plan de consulta.
Profesora:
Kristina Kucherova , arquitecta del modelo de datos en Sberbank de Rusia.
Objetivos y ruta del seminario web.Los siguientes objetivos se establecieron al comienzo del seminario web:
- Vea cómo el servidor ejecuta la solicitud y por qué sucede esto de esta manera.
- Aprendiendo a leer un plan de consulta.
Para lograrlos, el maestro preparó una ruta simple pero efectiva:
 ¿Por qué necesito un plan de consulta?
¿Por qué necesito un plan de consulta?El plan de consulta es una herramienta muy útil que, desafortunadamente, muchos desarrolladores no usan. A primera vista, puede parecer que no es necesario conocer la mecánica de la solicitud. Sin embargo, si comprende lo que sucede dentro de SQL Server, puede escribir una consulta más eficiente. Y ayudará mucho, por ejemplo, durante la optimización.
¿Cómo vemos una consulta SELECT?Veamos cómo se ve la consulta SELECT:
SELECCIONAR [campo1], [campo2] ...
| ¿Qué campos elegimos?
|
DE [tabla]
| De donde
|
DONDE [condiciones]
| Donde estan las condiciones
|
GRUPO POR [campo1]
| Agrupar por campos
|
Teniendo [condiciones]
| Tener tales y tales condiciones
|
ORDENAR POR [campo1]
| Ordenar (ordenar)
|
¿Cómo entender a dónde ir para obtener datos?Lo primero que el servidor intenta entender cuando llega una solicitud es a dónde ir para obtener los datos. El comando FROM responde a esta pregunta, porque es aquí donde tendremos una lista de tablas (o el nombre de una tabla).
Para mayor claridad, imaginemos que nuestro servidor es una especie de mayordomo, a quien ordenamos que nos recoja de vacaciones. En consecuencia, el mayordomo comienza a pensar, pero ¿en qué armario están las cosas necesarias (en qué tabla necesita tomar los datos)? Y para que nuestro mayordomo pueda completar fácilmente su tarea, usamos FROM.
 ¿Cómo entender qué datos tomar?
¿Cómo entender qué datos tomar?Digamos que el mayordomo encontró el armario correcto y lo abrió. ¿Pero qué cosas llevar? Tal vez vamos a una estación de esquí? ¿O tal vez en una playa cálida y soleada? Para que nuestras cosas coincidan con el clima, el comando WHERE es útil para nosotros, que define las condiciones, es decir, nos permite filtrar los datos. Si hace calor, llevamos pizarras, camisas y trajes de baño, si hace frío: guantes, calcetines de punto, suéteres).
El siguiente paso es adjuntar estos datos a los grupos, lo que sucede con GROUP BY (camisetas por separado, calcetines por separado). De acuerdo con los resultados de la agrupación, se puede imponer una condición más usando HAVING (por ejemplo, eliminar cosas no emparejadas). Al final, agregamos todo usando ORDER BY, obteniendo la maleta terminada de cosas en la salida, o más bien, un bloque de datos ordenado.

Por cierto, hay un matiz, pero consiste en el hecho de que hay una diferencia sobre qué condiciones deben escribirse en DONDE y en TENER. Pero esto es mejor ver en el video.
Continuamos La ruta de ejecución de la solicitud se guarda
como un plan de solicitud en la memoria caché, es decir, nuestro mayordomo escribe todo, porque es un buen mayordomo, ¿qué pasa si desea repetir su orden el próximo año? Y tales planes, en principio, pueden ser muchos.
Tipos de conexiones en el plan de consultaHay tres conexiones que puede encontrar en términos de consulta:
- Bucle anidado.
- Fusionar unirse.
- Hash únete.
Antes de analizar cada uno de ellos con más detalle, resumamos por qué deberíamos incluso leer el plan de consulta. Esto es realmente muy útil ya que aprenderás:
- qué índice se utiliza;
- en qué orden se unen;
- lo que se selecciona del búfer;
- cuánto gasta el servidor recursos en la operación;
- ¿Cuál es la diferencia entre un plan hipotético y un plan real?
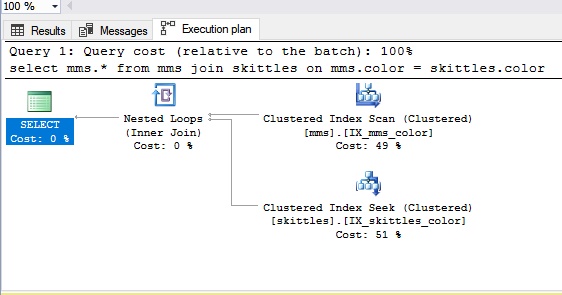
Bucle anidadoDigamos que necesitamos unir datos de diferentes tablas. Presentemos estas tablas como ... una pequeña cantidad de bombones Skittles y el empaque completo de M&M.

Cuando conectamos un tipo de Nested Loop, tomamos los dulces Skittles y luego obtenemos los dulces ciegos del paquete de M&M. Si no nos encontramos con un dulce del mismo color (esta es nuestra condición), obtenemos el siguiente, es decir, ocurre un busto normal. Como resultado, podemos decir que la conexión Nested Loop es más adecuada para pequeñas cantidades de datos. Obviamente, si hay muchos datos, el arresto no es la mejor opción.

Veamos cómo se ve en el panel SQL:
 Fusionar unirse
Fusionar unirseSe utiliza una conexión para grandes cantidades de datos. Cuando tiene una combinación Merge, ambas tablas tienen un índice por el cual se pueden unir. En el caso de los dulces, es como si los hubiéramos organizado de antemano por color.
Se ve así:

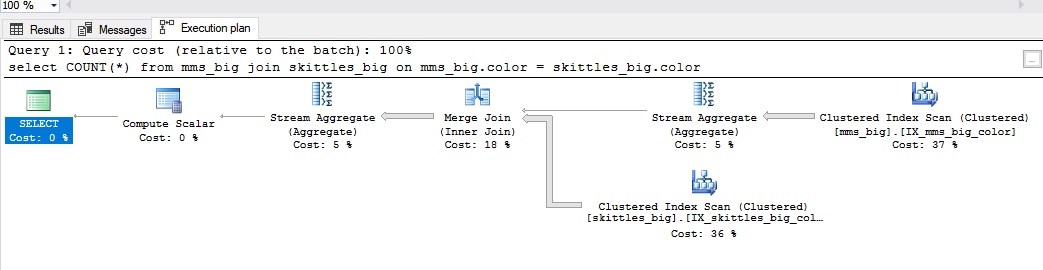
La combinación de combinación es buena en los siguientes casos:
- grandes conjuntos de datos;
- los mismos campos de conexión del mismo tipo;
- Los campos de conexión tienen índices.
Hash unirseHash join se usa para grandes cantidades de datos sin clasificar. Para unir las tablas en este caso, debe crear algo que imite el índice.
Ejemplo de combinación de hash:
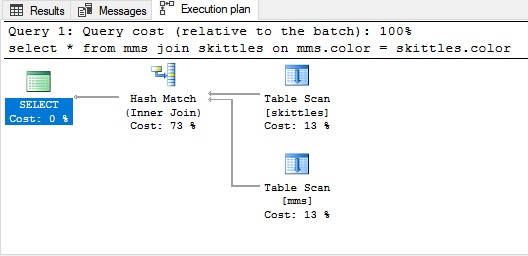
Para mayor claridad, recordamos nuestros dulces:

El uso de Hash join implica 2 fases de acción:
- Build: se crea una tabla hash en la tabla más pequeña. Para cada valor en la tabla No. 1, se considera un hash. El valor se almacena en una tabla hash y el hash calculado se usa como clave.
- Sonda Para cada fila de la tabla No. 2, el valor hash se calcula para los campos especificados en join (operator =). Se busca un hash en la tabla de hash, se verifican los valores de campo.
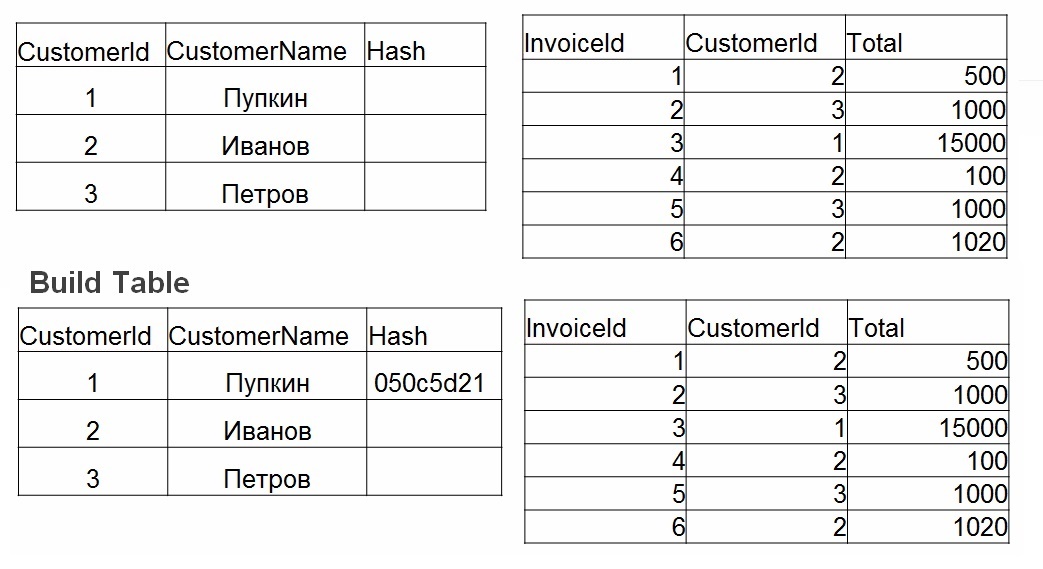
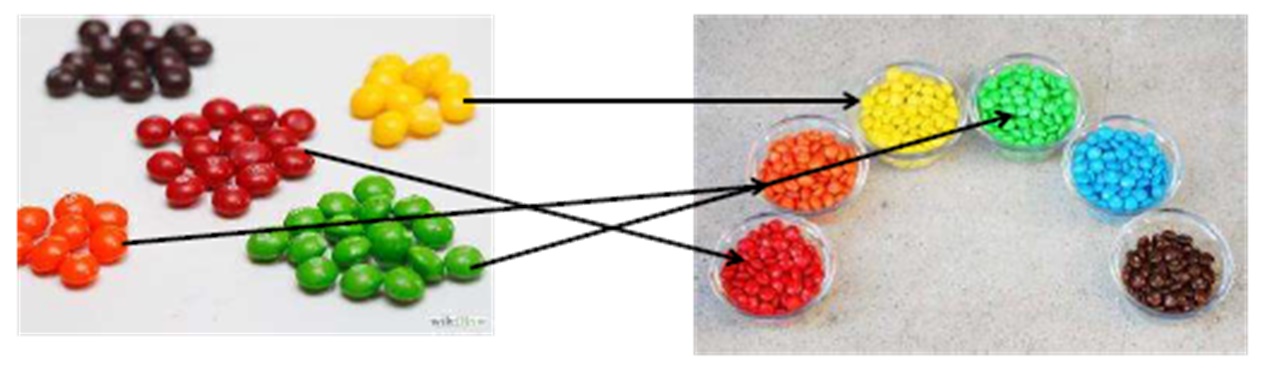
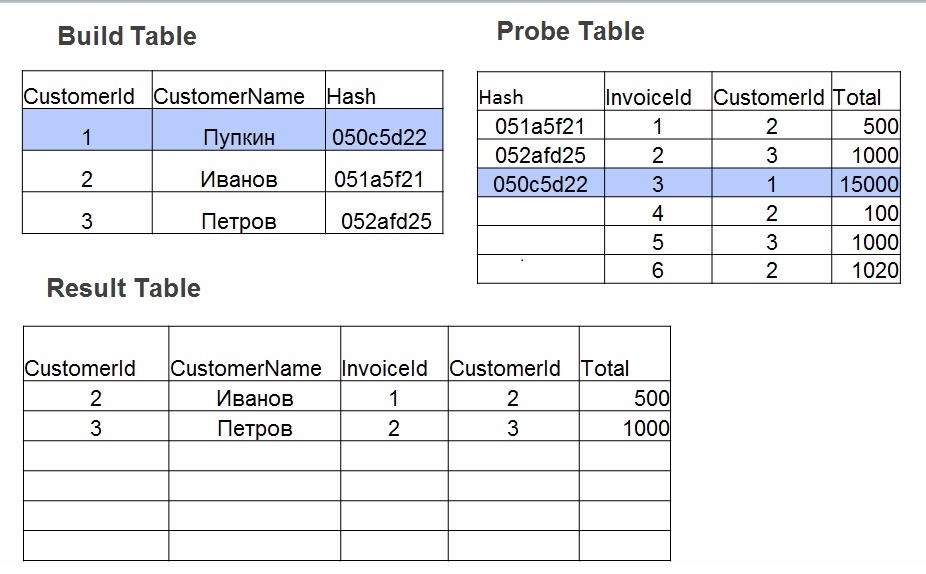
Cuando hash join es bueno:
- gran conjunto de datos;
- sin índices marginales.
Un punto importante: si no hay suficiente memoria, la grabación irá a tempdb - al disco.
Amigos, además de lo anterior, la lección abierta también incluyó otros puntos interesantes, que se ven mejor viendo el video. Sugerimos visitar la
Jornada de Puertas Abiertas del curso "MS SQL Server Developer", donde puede hacerle al profesor todas sus preguntas.
La maestra de PS
Kristina Kucherova agradece a Jes Schultz Borland por su
presentación con los Planes de ejecución de PASS Summitt: El secreto para el éxito del ajuste de consultas, que se utilizó en la preparación de la lección abierta.