Hace mucho tiempo, en una galaxia muy, muy lejana, había una compañía que creció de una startup a algo mucho más grande, pero durante un tiempo el departamento de TI aún era compacto y muy eficiente. Esa empresa alojó
en prem cientos de servidores virtuales de Windows y, por supuesto, estos servidores fueron monitoreados. Incluso antes de unirme a la compañía, NetIQ había sido elegida como una solución de monitoreo.
Una de mis nuevas tareas fue apoyar NetIQ. La persona, que trabajó con NetIQ antes, dijo mucho sobre su experiencia con NetIQ, desafortunadamente, si trato de ponerlo aquí, sería solo una larga línea de caracteres '****'. Pronto me di cuenta por qué. Steve Jobs probablemente esté girando en su tumba mirando la interfaz así:
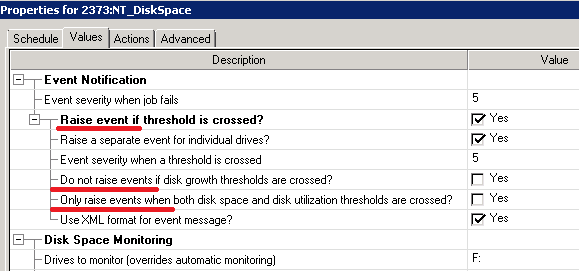
En la línea uno, la lógica de la casilla de verificación es positiva (
evento de aumento ), en la siguiente es negativa (
no evento de aumento ). Entonces, ¿cómo funciona '
Raise event only i f'? No tengo idea
Sin embargo, había algo mucho peor sobre NetIQ: su agente de monitoreo era muy frágil. Mucho más vulnerable que el propio Windows. Poca memoria? El agente está caído. CPU es 100%? El agente no responde. ¿Quedan 0 bytes libres en una unidad de disco? Bueno, para enviar un mensaje de alerta, un agente primero debe guardarlo en un archivo en un disco ... Entonces sí, no recibe ninguna alerta en ese caso.
Sin embargo, "no arregles lo que no está roto", y de alguna manera, vivimos con él hasta que nuestra empresa fue comprada por una mucho más grande. Cuando una gran empresa compra una pequeña, la pequeña se disipa como una gota de agua en el mar. Sin embargo, en nuestro caso nosotros (desde la perspectiva de TI) no éramos mucho más pequeños que la TI de una compañía más grande, y desde el principio era obvio que la fusión sería muy complicada. Tan complicado que por un tiempo nos quedamos solos como un departamento independiente y todos los procesos comerciales y de TI se mantuvieron igual, justo bajo el paraguas del nuevo nombre. Me recuerda el momento, cuando
EL ANILLO estaba sobre la lava pero aún no ha comenzado a derretirse.

Mientras tanto, había actualizado NetIQ de la versión 7 a la 8, y luego a la versión 9. Fue entonces cuando comenzaron todos nuestros problemas. Estábamos usando NetIQ para monitorear solo algunas cosas básicas: disponibilidad de un servidor, memoria, CPU, espacio en disco y lo más importante para nosotros: el estado de los servicios locales. Cuando cualquier tipo de inicio de servicio interno se estableció en "Automático", entonces debería estar siempre ejecutándose (de lo contrario, consideramos que se bloqueó). No debería haber casos como este:

Entonces, NetIQ dejó de monitorear el estado de los servicios. Después de una semana de experimentación y otra semana de llamadas con soporte de NetIQ, habíamos aprendido que "
no era un error, era una característica " y la alerta se activaba solo cuando un proceso salía con un código de salida específico. Y nuestros servicios fallaron con CUALQUIER código.
En ese momento ya era demasiado tarde para retroceder. Como comprenderá, tan pronto como descubrimos que nuestra infraestructura crítica no era monitoreada, inmediatamente ... eh ... no hicimos nada. Porque en ese momento el proceso de "fusión" de nuestra compañía en una más grande alcanzó una fase activa, y se veía así:
Escuché sonidos de truenos desde muy arriba, y parecía que los dioses en el Olimpo estaban decidiendo el destino del mundo, mientras trataba de distraerlos con mi pequeño problema técnico. Al mismo tiempo, no podía dormir sabiendo que nuestro sistema de monitoreo era medio ciego.
Después de darme cuenta de que no había nada que esperar, decidí crear una solución rápida y sucia: un pequeño escáner de servicio que debería revisar todos los servidores para verificar los servicios y enviar correos electrónicos para los servicios que estaban inactivos, exactamente como la versión anterior de NetIQ lo hizo. Puede pensar que el script de PowerShell es la mejor manera de hacerlo, pero ... Si todo lo que tiene es un martillo, todo parece un clavo. Si usted es un DBA que trabajó con SQL desde la versión 6.0, entonces ... Aquí hay un breve extracto del código, para que pueda entender de lo que estoy hablando:
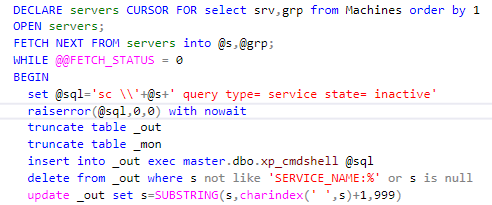
Me tomó solo unas pocas horas escribir la primera solución. Durante los próximos días agregué una auditoría, parámetros y otras cosas elegantes. Después de examinar lo que podía hacer el comando WMIC, no pude detenerme. No recuerdo exactamente lo que sucedió durante las próximas 2 semanas: todo estaba un poco borroso, pero cuando me desperté, todas las características de NetIQ se implementaron utilizando SQL puro.
No solo he copiado la funcionalidad de NetIQ "tal cual", he implementado todo lo que siempre soñé. En la alerta por correo electrónico de LOWDISK también obtienes un PDF adjunto con una tabla de crecimiento del uso del disco para que puedas entender instantáneamente si el crecimiento fue genuino o si algo salió mal. Poca memoria: y obtiene no solo el gráfico, sino también una distribución de memoria por proceso, además de w3wp.exe obtiene un nombre de grupo agregado. También había implementado recordatorios inteligentes con protección contra inundaciones y muchas otras cosas elegantes. Por cierto, la lista de servidores virtuales se extrajo automáticamente de los repositorios de VMware. Simplemente mirando los temas de alerta en un cliente móvil, puede decir instantáneamente lo que estaba sucediendo, incluso sin abrir los correos electrónicos:

Los desarrolladores modernos se acostumbraron a crear niveles de abstracción hasta el punto de perjudicar su capacidad de escribir un código simple y directo. No pueden crear un sistema de monitoreo sin decir: "Ok, entonces para cualquier servidor podemos ejecutar cualquier conjunto de scripts con reglas desde un repositorio ... Qué flexible ...". Pero el monitoreo de algunas cosas fundamentales como la memoria, la CPU, el disco y el estado de los servicios es único. Al implementar la verificación de estas condiciones básicas con un nivel de abstracción, terminan con un código que funciona igualmente mal para todos los casos. Este es un ejemplo del sistema SCOM. Estoy seguro de que fue implementado exactamente por las especificaciones:

Pero la principal ventaja del nuevo sistema era que no había ningún agente en absoluto. Sin agentes: nada que instalar, nada que romper. El sistema era simple y confiable como un hummer.
Pocos el mes que viene vine a trabajar y pasé una o dos horas trabajando en mi nueva creación, lentamente, sin plazos ni ETA, sin dejar casi ninguna deuda técnica. Después de un rato me obligué a parar.
NetIQ todavía estaba en producción, pero la gente definitivamente prefería las alertas del nuevo sistema, más confiables e informativas. Gradualmente, moví todos los "suscriptores" de alerta al nuevo sistema, manteniendo, sin embargo, el antiguo sistema con vida. Mientras tanto, el proceso de "fusión" de nuestra antigua compañía en una más grande había alcanzado su etapa final:

Bueno, todo tiene un final. Incluso me sorprendió tener la oportunidad de jugar con esas cosas en una gran empresa burocrática. Después de un mes de preparación, me dijeron que "está
bien, en una semana cerramos NetIQ y pasamos a SCOM como estándar corporativo ". Cerré NetIQ (tengo que admitirlo, lo odié tanto que fue uno de los momentos más felices de mi carrera) y comencé a esperar a que llegara SCOM. Pero no había ninguno. Nada desde una semana, un mes e incluso una cuarta parte.
Recibimos SCOM solo después de 6 meses completos: alguien se había olvidado del costo de las licencias para la gran cantidad de servidores que teníamos. En estos 6 meses, muchos departamentos se volvieron tan dependientes del nuevo sistema, que mantuvo no solo las alertas, sino también las métricas de rendimiento y los inventarios, por lo que era imposible cerrarlo. Se convirtió en un segundo sistema de respaldo. Para los auditores está SCOM, para las cosas realmente útiles, está mi creación.
De vez en cuando, los gerentes en diferentes niveles de jerarquía pasaban por alto las alertas de ese sistema y preguntaban: ¿qué es? Recientemente había explicado toda la historia detrás de este producto. Se rieron y dejaron que ese sistema viviera, y para mí fue una oportunidad de escribir un código como cuando era un estudiante, guiado no por especificaciones sino por mi propia comprensión, como un hobby. Fue muy divertido.
Artículo en ruso