Hola Habr!
En diciembre, nuestro colega de Advanced Analytics, Leonid Sherstyuk, ganó el primer lugar en la competencia de Aprendizaje automático y Big Data en el segundo campeonato de la industria DigitalSkills. Esta es una rama "digital" de reconocidos concursos profesionales organizados por WorldSkills Rusia. En total, más de 200 personas participaron en el campeonato, compitieron por el liderazgo en 25 competencias digitales: protección corporativa contra amenazas de seguridad interna, marketing en Internet, desarrollo de juegos de computadora y aplicaciones multimedia, tecnologías cuánticas, Internet de las cosas, diseño industrial, etc.

Como un caso para Machine Learning, se propuso la tarea de monitorear y detectar defectos en tuberías de plantas de energía nuclear, tuberías de petróleo y gas utilizando un sistema de control ultrasónico semiautomático.
Leonid contará sobre lo que hubo en la competencia y cómo logró ganar bajo el corte.
WorldSkills es una organización internacional que organiza concursos de habilidades profesionales en todo el mundo. Tradicionalmente, representantes de empresas industriales y estudiantes de universidades relevantes participaron en estas competencias, demostrando sus habilidades en especialidades de trabajo. Recientemente, las nominaciones digitales comenzaron a aparecer en la competencia, donde jóvenes especialistas compiten en las habilidades de robótica, desarrollo de aplicaciones, seguridad de la información y en otras profesiones a las que ni siquiera se puede llamar trabajadores. En una de estas nominaciones, en Machine Learning y trabajando con big data, competí en Kazán en el concurso DigitalSkills, celebrado bajo los auspicios de WS.
Como la competencia para la competencia es nueva, me fue difícil imaginar qué esperar. Por si acaso, repetí todo lo que sé sobre trabajar con bases de datos y algoritmos de cómputo, métricas y entrenamiento distribuidos, criterios estadísticos y métodos de preprocesamiento. Al estar familiarizado con los criterios de evaluación aproximados, no entendí cómo sería posible adaptar un trabajo completo con Hadoop y crear un bot de chat en 6 sesiones cortas.
Toda la competencia dura 3 días, más de 6 sesiones. Cada sesión es de 3 horas con un descanso, para lo cual debe completar varias tareas que están significativamente relacionadas entre sí. Al principio, puede parecer que el tiempo es suficiente, pero en realidad tomó un ritmo frenético para lograr hacer todo lo concebido.
En la competencia, se esperaba que no se esperara trabajar con grandes datos, y todo el conjunto de tareas se redujo al análisis de un conjunto de datos limitado.
De hecho, se nos pidió que repitiéramos el camino de uno de los organizadores, a los que llegaron los clientes con sus problemas y datos, y de quienes esperaban una oferta comercial en unas pocas semanas.
Trabajamos con los datos del PUZK (sistema de control ultrasónico semiautomático). El sistema está diseñado para verificar las uniones en la tubería en busca de grietas y defectos. La instalación misma viaja a lo largo de un riel montado en la tubería, y en cada paso realiza 16 mediciones. En condiciones ideales y en ausencia de defectos, algunos sensores deberían dar la señal máxima, otros: cero; en realidad, los datos eran muy ruidosos, y responder a la pregunta de si había un defecto en un lugar determinado se convirtió en una tarea no trivial.
 Instalación del sistema PUZK
Instalación del sistema PUZKEl primer día se dedicó a conocer los datos, limpiarlos y compilar estadísticas descriptivas. Se nos proporcionó información básica mínima sobre la instalación y los tipos de sensores montados en el dispositivo. Además del preprocesamiento de datos, tuvimos que establecer a qué tipo pertenecen los sensores y cómo están ubicados en el dispositivo.
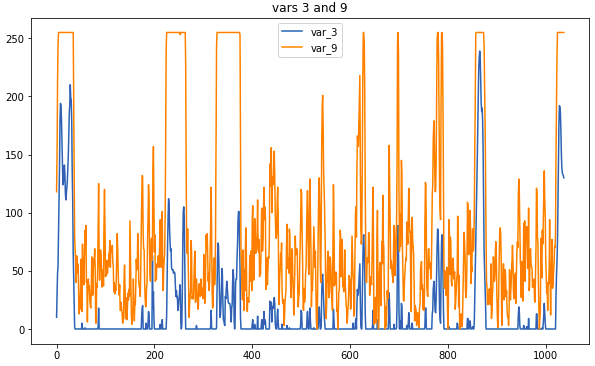 Datos de muestra: así es como se ven los sensores relacionados
Datos de muestra: así es como se ven los sensores relacionadosLa operación principal de preprocesamiento es reemplazar las mediciones con un promedio móvil. Si la ventana era demasiado grande, existía el riesgo de perder demasiada información, pero las correlaciones que ayudan a determinar el tipo serían más visuales. Algunas conexiones fueron notables sin preprocesamiento; Sin embargo, no hubo tiempo para examinar cuidadosamente los datos en bruto, por lo que el uso de correlogramas es indispensable.
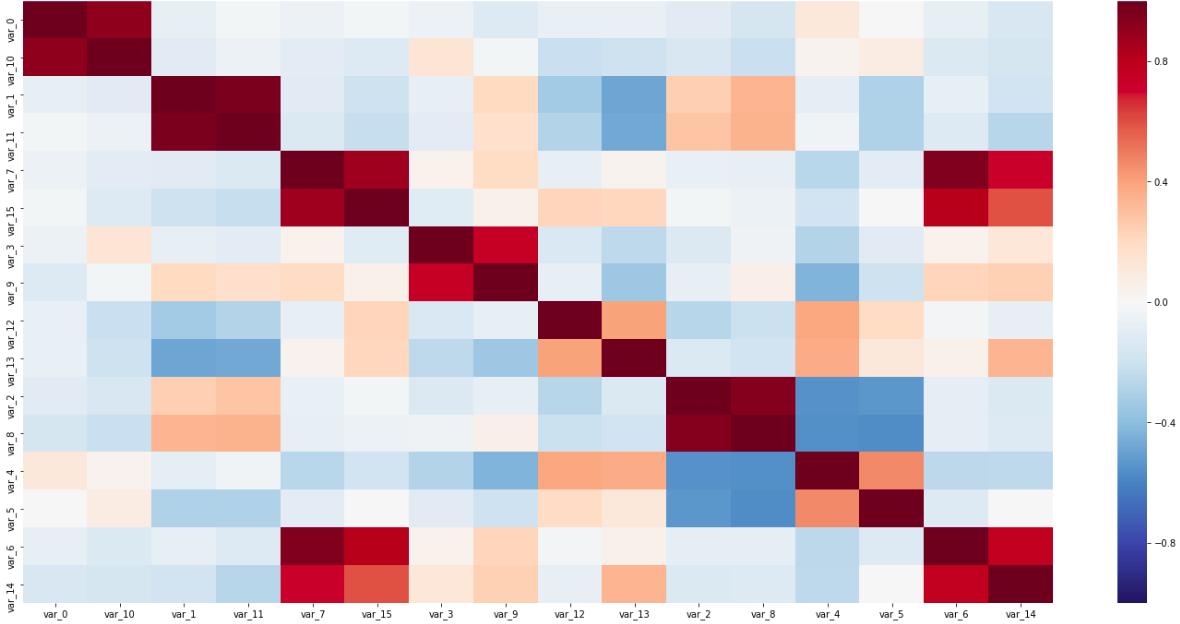 Matriz de correlación
Matriz de correlaciónEn esta matriz, son visibles los dos pares de sensores a lo largo de la diagonal, estrechamente conectados entre sí, y las variables de correlación inversa; Todo esto ayudó a determinar los tipos de sensores.
El último elemento obligatorio era reducir los sensores a una coordenada. Dado que el dispositivo de medición era significativamente más de un paso de medición, y los sensores estaban espaciados en todo el dispositivo, este era un paso obligatorio antes de seguir utilizando los datos para el entrenamiento.
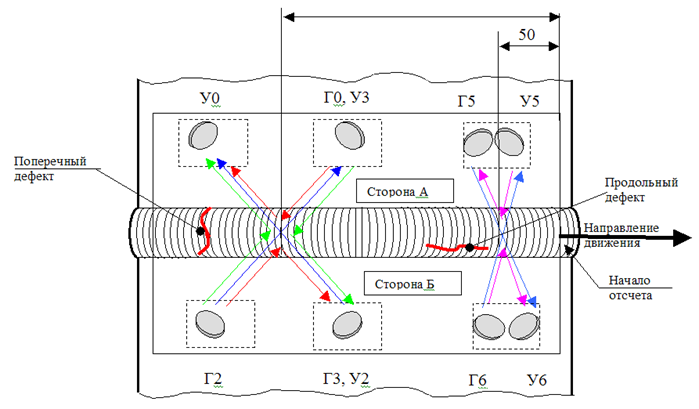
\
Diseño del sensorEl diagrama de la instalación de sensores en el dispositivo muestra que necesitamos encontrar las distancias entre los tres grupos de sensores. La forma más fácil y rápida aquí es establecer en qué segmento del dispositivo debe estar cada sensor, y luego buscar la correlación máxima, cambiando parte de las mediciones por un paso.
Esta etapa fue complicada por el hecho de que mis suposiciones sobre el tipo de sensores no estaban garantizadas, por lo que tuve que revisar todas las correlaciones, tipos, esquemas y vincularlos en un solo sistema consistente.
Para el segundo día, tuvimos que preparar los datos para el entrenamiento y realizar la agrupación en puntos, y luego construir un clasificador.
Durante la preparación de los datos, eliminé lecturas demasiado correlativas y, como característica sintética, agregué el promedio móvil, la derivada y la puntuación z. Indudablemente, la síntesis de nuevas variables podría desarrollarse bastante ampliamente, pero el tiempo impuso sus limitaciones.
La agrupación podría ayudar a separar los puntos defectuosos de todos los demás. Probé 3 métodos: k-means, Birch y DBScan, pero, desafortunadamente, ninguno de ellos dio un buen resultado.
Para el algoritmo predictivo, se nos dio total libertad; solo se especificó el formato que se debe obtener en la salida. Se suponía que el algoritmo debía proporcionar una tabla (o datos reducibles a ella), en la que una fila corresponde a una grieta, y a las columnas sus características (como longitud, ancho, tipo y lado). Me pareció la opción más simple, en la que hacemos una predicción para cada punto de la muestra de prueba, y luego combinamos los vecinos en una grieta. Como resultado, hice 3 clasificadores que respondieron las siguientes preguntas: de qué lado de la costura está el defecto, qué tan profundo va y a qué tipo pertenece (longitudinal o transversal).
Aquí, la profundidad que debería predecirse por la regresión es sorprendente; sin embargo, en la muestra marcada, encontré solo 5 profundidades únicas, por lo que esta simplificación me pareció aceptable.
 Métricas de evaluación de algoritmos
Métricas de evaluación de algoritmosDe todos los algoritmos (logré probar la regresión logística, el árbol decisivo y el aumento de gradiente), el aumento, como se esperaba, fue el mejor. Las métricas son indudablemente muy agradables, pero es bastante difícil evaluar el funcionamiento de los algoritmos sin tener como resultado un nuevo conjunto de pruebas. Los organizadores nunca regresaron con métricas específicas, limitándose a un comentario general de que nadie hizo la prueba tan bien como en una muestra retrasada.
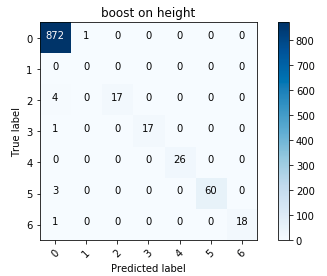 Matriz de error para impulsar
Matriz de error para impulsarEn general, estuve satisfecho con los resultados; en particular, reducir la altura a una variable categórica valió la pena.
Durante el último día, tuvimos que resumir los algoritmos entrenados en un producto que un cliente potencial podría usar, y preparar una presentación de nuestra solución lista para la empresa.
Aquí, el perfeccionismo me ayudó a escribir un código relativamente limpio, que no desapareció ni siquiera en un tiempo limitado. A partir de las piezas de código listas para usar, el prototipo se desarrolló rápidamente y tuve tiempo de depurar los errores. En contraste con las etapas anteriores, aquí el desempeño de la solución jugó un papel más importante, en lugar de cumplir con criterios formales.
 Producto terminado - Utilidad CLI
Producto terminado - Utilidad CLIHacia el final de la sesión, obtuve una utilidad CLI que acepta una carpeta de origen como entrada y devuelve tablas con los resultados de la predicción en una forma conveniente para el tecnólogo.
En la etapa final, tuve la oportunidad de hablar sobre mis éxitos y ver a qué llegaron otros participantes. Incluso bajo criterios estrictos, nuestras decisiones fueron completamente diferentes: alguien se agrupó con éxito, otros utilizaron hábilmente métodos lineales. Durante las presentaciones, los concursantes se centraron en sus puntos fuertes: algunos pusieron a la venta del producto, otros más inmersos en detalles técnicos; Había hermosos gráficos e interfaces de solución adaptativa.
 La principal ventaja de mi solución encaja en una diapositiva
La principal ventaja de mi solución encaja en una diapositiva¿Qué pasa con la competencia en general?
Las competiciones de este tipo son una gran oportunidad para descubrir qué tan rápido puede realizar tareas típicas de su especialidad. Los criterios se compilaron de tal manera que no el que recibió los mejores resultados (como, por ejemplo, en Kaggle) obtenga la mayor cantidad de puntos, sino que pueda realizar las operaciones típicas del trabajo diario en la industria más rápidamente. En mi opinión, la participación y la victoria en tales competencias pueden decirle a un empleador potencial no menos que la experiencia en la industria, en los hackathons y Kaggle.
Lenonid Sherstyuk,
Analista de Datos, Analítica Avanzada, SIBUR