Cuando pienso en cómo funcionan los clientes ingenuos de RPC, recuerdo una broma:
El tribunal
"Demandado, ¿por qué mataste a una mujer?"
- Estoy en el autobús, el conductor se acerca a la mujer y le exige que compre un boleto. La mujer abrió su bolso, sacó su bolso, cerró su bolso, abrió su bolso, cerró su bolso, abrió su bolso, puso su bolso allí, cerró su bolso, abrió su bolso, tomó su dinero, abrió su bolso, tomó su bolso, cerró su bolso, abrió su bolso y puso su bolso allí , cerró su bolso, abrió su bolso, puso su bolso allí.
- Y que?
- El controlador le dio un boleto. Una mujer abrió su bolso, sacó su bolso, cerró su bolso, abrió su bolso, cerró su bolso, abrió su bolso, puso su bolso allí, cerró su bolso, abrió su bolso, colocó su boleto, cerró su bolso, abrió su bolso, sacó su bolso, cerró su bolso, abrió su bolso , puse el bolso allí, cerré el bolso, abrí el bolso, puse el bolso allí, cerré el bolso.
"Toma el cambio", llegó la voz del controlador. La mujer ... abrió su bolso ...
"Sí, no es suficiente matarla", el fiscal no puede soportar.
"Así que lo hice".
© S. Altov

Aproximadamente lo mismo sucede en el proceso de solicitud-respuesta, si lo aborda frívolamente:
- el proceso del usuario escribe una solicitud serializada en el socket, de hecho la copia en el buffer del socket en el nivel del sistema operativo;
Esta es una operación bastante difícil, porque es necesario hacer un cambio de contexto (incluso si puede ser "fácil"); - cuando al sistema operativo le parece que se puede escribir algo en la red, se forma un paquete (la solicitud se copia nuevamente) y se envía a la tarjeta de red;
- la tarjeta de red escribe el paquete en la red (posiblemente después del almacenamiento en búfer);
- (en el camino, un paquete puede almacenarse varias veces en los enrutadores);
- finalmente, el paquete llega al host de destino y se almacena en la tarjeta de red;
- la tarjeta de red envía una notificación al sistema operativo, y cuando el sistema operativo encuentra la hora, copia el paquete en su búfer y establece el indicador de listo en el descriptor de archivo;
- (aún debe recordar enviar el ACK en respuesta);
- después de un tiempo, la aplicación del servidor se da cuenta de que el descriptor está listo (usando epoll) y algún día copia la solicitud en el búfer de la aplicación;
- y finalmente, la aplicación del servidor procesa la solicitud.
Como saben, la respuesta se transmite exactamente de la misma manera solo en la dirección opuesta. Por lo tanto, cada solicitud pasa un tiempo notable en el sistema operativo para su mantenimiento, y cada respuesta pasa el mismo tiempo nuevamente.
Esto se hizo especialmente notable después de Meltdown / Spectre, ya que los parches lanzados condujeron a un aumento significativo en el costo de las llamadas al sistema. A principios de enero de 2018, nuestro clúster Redis de repente comenzó a consumir una CPU y media o dos veces más, porque Amazon ha aplicado parches de kernel apropiados para cubrir estas vulnerabilidades. (Es cierto que Amazon aplicó una nueva versión del parche un poco más tarde, y el consumo de CPU cayó casi a los niveles anteriores. Pero el conector ya ha comenzado a nacer).
Desafortunadamente, todos los conectores Go ampliamente conocidos para Redis y Memcached funcionan de la siguiente manera: el conector crea un grupo de conexiones, y cuando necesita enviar una solicitud, extrae una conexión del grupo, escribe una solicitud y luego espera una respuesta. (Es especialmente triste que el conector a Memcached haya sido escrito por el propio Brad Fitzpatrick). Y algunos conectores tienen una implementación tan infructuosa de este grupo que el proceso de eliminar la conexión del grupo se convierte en una botnet en sí mismo.
Hay dos formas de facilitar este arduo trabajo de reenvío de solicitud / respuesta:
- Utilice el acceso directo a la tarjeta de red: DPDK, netmap, PF_RING, etc.
- No envíe cada solicitud / respuesta como un paquete separado, sino combínelas, si es posible, en paquetes más grandes, es decir, extienda la sobrecarga de trabajar con la red para varias solicitudes. Juntos más divertido!
La primera opción, por supuesto, es posible. Pero, en primer lugar, esto es para los valientes, ya que debe escribir la implementación de TCP / IP usted mismo (por ejemplo, como en ScyllaDB). Y en segundo lugar, de esta manera facilitamos la situación solo en un lado, en el que nosotros mismos escribimos. No quiero volver a escribir Redis (todavía), por lo que los servidores consumirán la misma cantidad, incluso si el cliente usa el genial DPDK.
La segunda opción es mucho más simple y, lo más importante, facilita la situación inmediatamente en el cliente y en el servidor. Por ejemplo, una base de datos en memoria se jacta de que puede servir a millones de RPS, mientras que Redis no puede atender a un par de cientos de miles . Sin embargo, este éxito no es tanto la implementación de esa base en memoria como la decisión una vez aceptada de que el protocolo será completamente asíncrono, y los clientes deben usar esta asincronía siempre que sea posible. Lo que muchos clientes (especialmente los utilizados en los puntos de referencia) implementan con éxito enviando solicitudes a través de una conexión TCP y, si es posible, enviándolas juntas a la red.
Un artículo bien conocido muestra que Redis también puede entregar un millón de respuestas por segundo si se utiliza la canalización. La experiencia personal en el desarrollo de historias en memoria también indica que la canalización reduce significativamente el consumo de CPU SYS y le permite usar el procesador y la red de manera mucho más eficiente.
La única pregunta es cómo usar la canalización, si en la solicitud las solicitudes en Redis a menudo llegan de una en una. Y si falta un servidor y Redis Cluster se usa con una gran cantidad de fragmentos, incluso cuando se encuentra un paquete de solicitudes, se divide en solicitudes individuales para cada fragmento.
La respuesta, por supuesto, es "obvia": realice un trazado de tubería implícito, recopile las solicitudes de todas las gorutinas que se ejecutan en paralelo a un servidor Redis y las envíe a través de una conexión.
Por cierto, el tendido implícito de tuberías no es tan raro en los conectores en otros idiomas: nodejs node_redis , C # RedisBoost , python aioredis y muchos otros. Muchos de estos conectores están escritos en la parte superior de los bucles de eventos y, por lo tanto, parece natural recopilar solicitudes de "flujos de cálculo" paralelos. En Go, se promueve el uso de interfaces síncronas y, aparentemente, porque pocas personas deciden organizar su propio "bucle".
Queríamos usar Redis de la manera más eficiente posible y, por lo tanto, decidimos escribir un nuevo conector "mejor" (tm): RedisPipe .
¿Cómo hacer un tendido de tubería implícito?
El esquema básico:
- Las rutinas de la lógica de la aplicación no escriben solicitudes directamente en la red, sino que las pasan al recolector de rutinas;
- si es posible, el recolector recopila un montón de solicitudes, las escribe en la red y las pasa al lector de rutina;
- Goroutine-reader lee las respuestas de la red, las compara con las solicitudes correspondientes y notifica a los goroutines de la lógica acerca de la respuesta recibida.
Algo debe ser notificado sobre la respuesta. Un astuto programador de Go sin duda dirá: "¡A través del canal!"
Pero esta no es la única primitiva de sincronización posible y no la más eficiente incluso en el entorno Go. Y dado que diferentes personas tienen diferentes necesidades, haremos que el mecanismo sea extensible, permitiendo al usuario implementar la interfaz (llamémosla Future ):
type Future interface { Resolve(val interface{}) }
Y luego el esquema básico se verá así:
type future struct { req Request fut Future } type Conn struct { c net.Conn futmtx sync.Mutex wfutures []future futtimer *time.Timer rfutures chan []future } func (c *Conn) Send(r Request, f Future) { c.futmtx.Lock() defer c.futmtx.Unlock() c.wfutures = append(c.wfutures, future{req: r, fut: f}) if len(c.wfutures) == 1 { futtimer.Reset(100*time.Microsecond) } } func (c *Conn) writer() { for range c.futtimer.C { c.futmtx.Lock() futures, c.wfutures = c.wfutures, nil c.futmtx.Unlock() var b []byte for _, ft := range futures { b = AppendRequest(b, ft.req) } _, _err := ccWrite(b) c.rfutures <- futures } } func (c *Conn) reader() { rd := bufio.NewReader(cc) var futures []future for { response, _err := ParseResponse(rd) if len(futures) == 0 { futures = <- c.rfutures } futures[0].fut.Resolve(response) futures = futures[1:] } }
Por supuesto, este es un código muy simplificado. Omitido
- establecimiento de conexión;
- Tiempos de espera de E / S
- manejo de errores de lectura / escritura;
- restablecer la conexión;
- la capacidad de cancelar la solicitud antes de enviarla a la red;
- optimizando la asignación de memoria (reutilizando el buffer y las matrices de futuros).
Cualquier error de E / S (incluido un tiempo de espera) en el código real conduce a una resolución de todos los errores futuros correspondientes a las solicitudes enviadas y en espera de ser enviadas.
La capa de conexión no está involucrada en el reintento de la solicitud, y si es necesario (y posible) volver a intentar la solicitud, se puede hacer en un nivel superior de abstracción (por ejemplo, en la implementación del soporte de Redis Cluster que se describe a continuación).
Observación Inicialmente, el circuito parecía un poco más complicado. Pero en el proceso de experimentos simplificado a tal opción.
Observación 2. Se imponen requisitos muy estrictos al futuro. Método de resolución: debe ser lo más rápido posible, prácticamente sin bloqueo y en ningún caso de pánico. Esto se debe al hecho de que se llama sincrónicamente en el ciclo del lector, y cualquier "freno" inevitablemente conducirá a la degradación. La implementación de Future.Resolve debe hacer el mínimo necesario de acciones lineales: despertar al expectante; tal vez maneje el error y envíe un reintento asincrónico (utilizado en la implementación del soporte de clúster).
Efecto
¡Un buen punto de referencia es la mitad del artículo!
Un buen punto de referencia es uno que esté lo más cerca posible de combatir el uso en términos de efectos observados. Y esto no es fácil de hacer.
La opción de referencia , que me parece bastante similar a la real:
- el "script" principal emula 5 clientes paralelos,
- en cada "cliente", por cada 300-1000 rps "deseadas", se activa la gorutina (se activan 3 gorutinas por 1000 rps, se ejecutan 124 gorutinas por 128000 rps),
- gorutin usa una instancia separada del limitador de velocidad y envía solicitudes en series aleatorias, de 5 a 15 solicitudes.
La aleatoriedad de la serie de consultas nos permite lograr una distribución aleatoria de la serie en la línea de tiempo, que refleja más correctamente la carga real.
Texto ocultoLas opciones incorrectas fueron:
a) utilice un limitador de velocidad para todas las gorutinas del "cliente" y recurra a él para cada solicitud; esto lleva a un consumo excesivo de CPU por el propio limitador de velocidad, así como a una mayor rotación de tiempo de goroutin, lo que degrada el rendimiento de RedisPipe a rps medias (pero inexplicablemente mejora a la altura);
b) utilice un limitador de velocidad para todas las gorutinas del "cliente" y envíe solicitudes en serie: el limitador de velocidad no está consumiendo tanto la CPU, pero la alternancia de gorutinas en el tiempo solo aumenta;
c) use un limitador de velocidad para cada goroutine, pero envíe la misma serie de 10 solicitudes; en este escenario, las goroutines se despiertan demasiado simultáneamente, lo que mejora injustamente los resultados de RedisPipe.
Las pruebas se realizaron en una instancia de AWS c5-2xlarge de cuatro núcleos. La versión de Redis es 5.0.
La relación de la intensidad de consulta deseada, la intensidad total resultante y consumida por el rábano de la CPU:
| rps previstos | redigo
rps /% cpu | redispipe no espere
rps /% cpu | redispipe 50µs
rps /% cpu | redispipe 150µs
rps /% cpu |
|---|
| 1000 * 5 | 5015/7% | 5015/6% | 5015/6% | 5015/6% |
| 2000 * 5 | 10022/11% | 10022/10% | 10022/10% | 10022/10% |
| 4000 * 5 | 20036/21% | 20036/18% | 20035/17% | 20035/15% |
| 8000 * 5 | 40020/45% | 40062/37% | 40060/26% | 40056/19% |
| 16000 * 5 | 79994/71% | 80102/58% | 80096/33% | 80090/23% |
| 32000 * 5 | 159590/96% | 160 180/80% | 160,167 / 39% | 160150/29% |
| 64000 * 5 | 187774/99% | 320 313/98% | 320,283 / 47% | 320,258 / 37% |
| 92000 * 5 | 183206/99% | 480,443 / 97% | 480,407 / 52% | 480 366/42% |
| 128000 * 5 | 179744/99% | 640,484 / 97% | 640,488 / 55% | 640,428 / 46% |
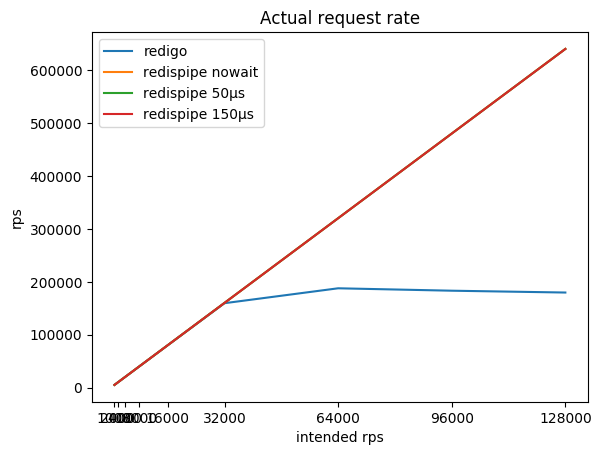
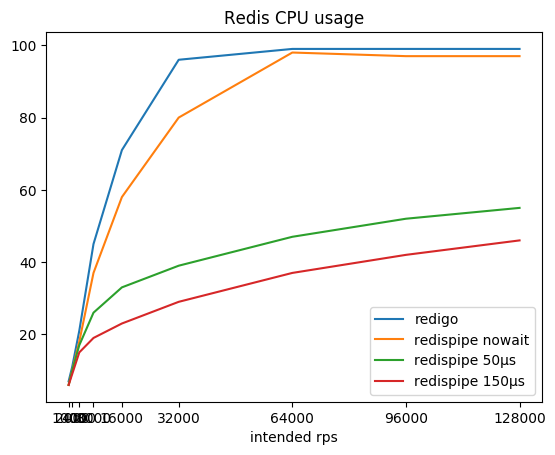
Puede notar que con un conector que funciona de acuerdo con el esquema clásico (solicitud / respuesta + grupo de conexiones), Redis consume rápidamente el núcleo del procesador, después de lo cual se convierte en una tarea imposible obtener más de 190 krps.
RedisPipe le permite exprimir toda la potencia requerida de Redis. Y cuanto más nos detenemos para recopilar solicitudes paralelas, menos Redis consume CPU. Ya se obtiene un beneficio tangible a 4krps del cliente (20krps en total) si se usa una pausa de 150 microsegundos.
Incluso si la pausa no se usa explícitamente cuando Redis descansa en la CPU, el retraso aparece por sí solo. Además, las solicitudes comienzan a ser almacenadas por el sistema operativo. Esto permite que RedisPipe aumente el número de solicitudes ejecutadas con éxito cuando el conector clásico ya está bajando sus patas.
Este es el resultado principal, para lo cual fue necesario crear un nuevo conector.
¿Qué sucede entonces con el consumo de CPU en el cliente y con las solicitudes retrasadas?
| rps previstos | redigo
% cpu / ms | redispipe nowait
% cpu / ms | redispipe 50ms
% cpu / ms | redispipe 150ms
% cpu / ms |
|---|
| 1000 * 5 | 13 / 0.03 | 20 / 0.04 | 46 / 0.16 | 44 / 0.26 |
| 2000 * 5 | 25 / 0.03 | 33 / 0.04 | 77 / 0.16 | 71 / 0.26 |
| 4000 * 5 | 48 / 0.03 | 60 / 0.04 | 124 / 0.16 | 107 / 0.26 |
| 8000 * 5 | 94 / 0.03 | 119 / 0.04 | 178 / 0.15 | 141 / 0.26 |
| 16000 * 5 | 184 / 0.04 | 206 / 0.04 | 228 / 0.15 | 177 / 0.25 |
| 32000 * 5 | 341 / 0.08 | 322 / 0.05 | 280 / 0.15 | 226 / 0.26 |
| 64000 * 5 | 316 / 1.88 | 469 / 0.08 | 345 / 0.16 | 307 / 0.26 |
| 92000 * 5 | 313 / 2,88 | 511 / 0.16 | 398 / 0.17 | 366 / 0.27 |
| 128000 * 5 | 312 / 3.54 | 509 / 0.37 | 441 / 0,19 | 418 / 0.29 |
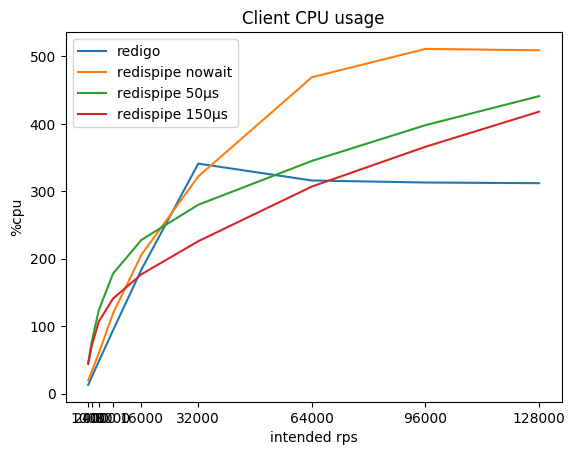
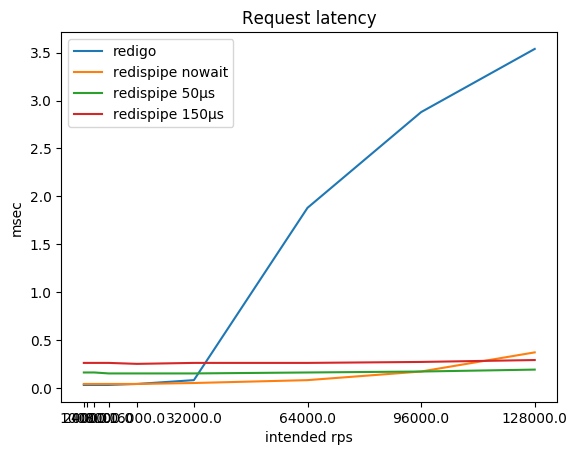
Puede notar que en pequeños rps RedisPipe consume más CPU que el "competidor", especialmente si se usa una pequeña pausa. Esto se debe principalmente a la implementación de temporizadores en Go y la implementación de las llamadas del sistema utilizadas en el sistema operativo (en Linux es futexsleep), ya que en el modo "sin pausa" la diferencia es significativamente menor.
A medida que aumenta el rps, la sobrecarga para los temporizadores se compensa con una sobrecarga menor para la conectividad de red, y después de 16 krps por cliente, el uso de RedisPipe con una pausa de 150 microsegundos comienza a brindar beneficios tangibles.
Por supuesto, después de que Redis descansaba en la CPU, la latencia de las solicitudes que usan el conector clásico comienza a aumentar. Sin embargo, no estoy seguro de que, en la práctica, a menudo alcances 180 krps en una instancia de Redis. Pero si es así, tenga en cuenta que puede tener problemas.
Mientras Redis no se ejecute en la CPU, la latencia de la solicitud, por supuesto, sufre el uso de una pausa. Este compromiso se establece intencionalmente en el conector. Sin embargo, esta compensación solo se nota si Redis y el cliente están en el mismo host físico. Dependiendo de la topología de la red, un viaje de ida y vuelta a un host vecino puede ser de cien microsegundos a un milisegundo. En consecuencia, la diferencia en el retraso ya en lugar de nueve veces (0.26 / 0.03) se convierte en tres veces (0.36 / 0.13) o se mide solo por un par de decenas de por ciento (1.26 / 1.03).
En nuestra carga de trabajo, cuando Redis se usa como caché, la expectativa total de respuestas de la base de datos con una pérdida de caché es mayor que la expectativa total de respuestas de Redis, porque se cree que el aumento en el retraso no es significativo.
El principal resultado positivo es una tolerancia al crecimiento de la carga: si de repente la carga en el servicio aumenta N veces, Redis no consumirá la CPU la misma N veces más. Para soportar cuadruplicar la carga de 160 krps a 640 krps, Redis gastó solo 1.6 veces más CPU, aumentando el consumo del 29 al 46%. Esto nos permite no tener miedo de que Redis se doblegue de repente. La escalabilidad de la aplicación tampoco estará determinada por el funcionamiento del conector y el costo de la conectividad de la red (léase: costos de CPU de SYS).
Observación El código de referencia opera con valores pequeños. Para despejar mi conciencia, repetí la prueba con valores de tamaño 768 bytes. El consumo de CPU por rábano aumentó notablemente (hasta un 66% en una pausa de 150 µs), y el techo para un conector clásico cae a 170 krps. Pero todas las proporciones observadas permanecieron iguales, y de ahí las conclusiones.
Racimo
Para escalar usamos Redis Cluster . Esto nos permite usar Redis no solo como caché, sino también como almacenamiento volátil y, al mismo tiempo, no perder datos al expandir / comprimir un clúster.
Redis Cluster utiliza el principio de cliente inteligente, es decir el cliente debe monitorear el estado del clúster y también responder a los errores auxiliares que devuelve el "rábano" cuando el "ramo" se mueve de una instancia a otra.
En consecuencia, el cliente debe mantener conexiones a todas las instancias de Redis en el clúster y emitir una conexión a la requerida para cada solicitud. Y fue en este lugar que el cliente usó antes (no señalaremos con el dedo) que se fastidió mucho. El autor, que sobrestimó la comercialización de Go (CSP, canales, gorutinas), implementó la sincronización del trabajo con el estado del clúster enviando devoluciones de llamada a la gorutina central. Esto se ha convertido en un botnek serio para nosotros. Como parche temporal, tuvimos que lanzar cuatro clientes en un clúster, cada uno, a su vez, elevando hasta cientos de conexiones en el grupo para cada instancia de Redis.
En consecuencia, el nuevo conector se encargó de evitar este error. Toda interacción con el estado del clúster en la ruta de ejecución de la consulta se realiza de la manera más libre posible:
- el estado del clúster se hace prácticamente inmutable, y no hay numerosas mutaciones aromatizadas por átomos
- el acceso al estado se produce mediante atomic.StorePointer / atomic.LoadPointer y, por lo tanto, se puede obtener sin bloquear.
Por lo tanto, incluso durante la actualización del estado del clúster, las solicitudes pueden usar el estado anterior sin temor a esperar en un bloqueo.
El estado del clúster se actualiza cada 5 segundos. Pero si hay una sospecha de inestabilidad del clúster, la actualización es forzada:
func (c *Cluster) control() { t := time.NewTicker(c.opts.CheckInterval) defer t.Stop()
Si la respuesta MOVED o ASK recibida del rábano contiene una dirección desconocida, se inicia su adición asincrónica a la configuración. (Lo siento, no descubrí cómo simplificar el código, porque aquí está el enlace ). No fue sin el uso de bloqueos, pero se toman por un corto período de tiempo. La expectativa principal se realiza al guardar la devolución de llamada en la matriz: la misma vista lateral futura.
Se establecen conexiones con todas las instancias de Redis, con maestros y esclavos. Dependiendo de la política preferida y el tipo de solicitud (lectura o escritura), la solicitud puede enviarse tanto al maestro como al esclavo. Esto tiene en cuenta la "vivacidad" de la instancia, que consiste tanto en la información obtenida al actualizar el estado del clúster como en el estado actual de la conexión.
func (c *Cluster) connForSlot(slot uint16, policy ReplicaPolicyEnum) (*redisconn.Connection, *errorx.Error) { var conn *redisconn.Connection cfg := c.getConfig() shard := cfg.slot2shard(slot) nodes := cfg.nodes var addr string switch policy { case MasterOnly: addr = shard.addr[0]
Hay un críptico RoundRobinSeed.Current() . Esto, por un lado, es una fuente de aleatoriedad, y por otro, aleatoriedad que no cambia con frecuencia. Si selecciona una nueva conexión para cada solicitud, esto degrada la eficiencia de la canalización. Es por eso que la implementación predeterminada cambia el valor de Current cada pocas decenas de milisegundos. Para tener menos superposiciones en el tiempo, cada host selecciona su propio intervalo.
Como recordará, la conexión utiliza el concepto de Futuro para solicitudes asincrónicas. El clúster utiliza el mismo concepto: un futuro personalizado se envuelve en uno agrupado, y ese se alimenta a la conexión.
¿Por qué envolver el futuro personalizado? En primer lugar, en el modo de clúster, "rábano" devuelve maravillosos "errores" MOVIDO y PREGUNTA con la información a dónde ir para obtener la clave que necesita, y, después de recibir dicho error, debe repetir la solicitud a otro host. En segundo lugar, dado que todavía necesitamos implementar la lógica de redireccionamiento, ¿por qué no incrustar la solicitud para volver a intentarlo con un error de E / S (por supuesto, solo si la solicitud de lectura):
type request struct { c *Cluster req Request cb Future slot uint16 policy ReplicaPolicyEnum mayRetry bool } func (c *Cluster) SendWithPolicy(policy ReplicaPolicyEnum, req Request, cb Future) { slot := redisclusterutil.ReqSlot(req) policy = c.fixPolicy(slot, req, policy) conn, err := c.connForSlot(slot, policy, nil) if err != nil { cb.Resolve(err) return } r := &request{ c: c, req: req, cb: cb, slot: slot, policy: policy, mayRetry: policy != MasterOnly || redis.ReplicaSafe(req.Cmd), } conn.Send(req, r, 0) } func (r *request) Resolve(res interface{}, _ uint64) { err := redis.AsErrorx(res) if err == nil { r.resolve(res) return } switch { case err.IsOfType(redis.ErrIO): if !r.mayRetry {
Este también es un código simplificado. Se omite la restricción en el número de reintentos, la memorización de conexiones problemáticas, etc.
Comodidad
Solicitudes asincrónicas, ¡Future es una superkule! Pero terriblemente incómodo.
La interfaz es lo más importante. Puedes vender cualquier cosa si tiene una buena interfaz. Es por eso que Redis y MongoDB han ganado popularidad.
Por lo tanto, es necesario convertir nuestras solicitudes asincrónicas en síncronas.
AsError no se ve como un Go-way nativo para obtener un error. Pero me gusta porque desde mi punto de vista, el resultado es Result<T,Error> y AsError es un patrón de coincidencia ersatz.
Desventajas
Pero, desafortunadamente, hay una mosca en la pomada en este bienestar.
El protocolo Redis no implica reordenar solicitudes. Y al mismo tiempo, tiene solicitudes de bloqueo como BLPOP, BRPOP.
Esto es un fracaso
Como sabe, si dicha solicitud está bloqueada, bloqueará todas las solicitudes que la sigan. Y no hay nada que hacer al respecto.
Después de una larga discusión, se decidió prohibir el uso de estas solicitudes en RedisPipe.
Por supuesto, si realmente lo necesita, puede: poner el parámetro ScriptMode: true , y eso está en su conciencia.
Alternativas
De hecho, todavía hay una alternativa que no mencioné, pero que los lectores expertos pensaron, es el rey de la twemproxy de cachés de clúster.
Él hace por Redis lo que hace nuestro conector: transforma una "solicitud / respuesta" grosera y desalmada en una suave "colocación de tuberías".
Pero la propia twemproxy sufrirá el hecho de que tendrá que trabajar en un sistema de "solicitud / respuesta". Esta vez Y en segundo lugar, usamos "rábano" y "almacenamiento poco confiable" y, a veces, cambiamos el tamaño del clúster. Y twemproxy no facilita la tarea de reequilibrio de ninguna manera y, además, requiere un reinicio al cambiar la configuración del clúster.
Influencia
No tuve tiempo de escribir un artículo, y las olas de RedisPipe ya se han ido. Se ha adoptado un parche en Radix.v3 que agrega canalización a su Pool:
Consulte RedisPipe y descubra si se puede incorporar su estrategia de canalización / procesamiento por lotes implícito
Canalización automática para comandos en Pool
Son ligeramente inferiores en velocidad (a juzgar por sus puntos de referencia, pero no lo diré con certeza). Pero su ventaja es que pueden enviar comandos de bloqueo a otras conexiones desde el grupo.
Conclusión
Ya hace un año que RedisPipe contribuye a la efectividad de nuestro servicio.
Y en previsión de cualquier "día caluroso", uno de los recursos, cuya capacidad no causa preocupación, es la CPU en los servidores Redis.
Repositorio
Punto de referencia