En artículos anteriores, ya escribieron sobre cómo funciona nuestra tecnología de reconocimiento de texto:
Hasta 2018, el reconocimiento de los caracteres japoneses y chinos se organizó de la misma manera: principalmente usando clasificadores de raster y de características. Pero con el reconocimiento de los jeroglíficos hay dificultades:
- Una gran cantidad de clases que deben distinguirse.
- Dispositivo de carácter más complejo en su conjunto.

Es tan difícil decir inequívocamente cuántos caracteres tiene el alfabeto chino en la escritura, como es preciso contar cuántas palabras en ruso. Pero con mayor frecuencia en la escritura china se usan ~ 10,000 caracteres. Con ellos limitamos el número de clases utilizadas en el reconocimiento.
Los dos problemas descritos anteriormente también conducen al hecho de que para lograr una alta calidad, debe usar una gran cantidad de características y estas características se calculan en las imágenes de los caracteres por más tiempo.
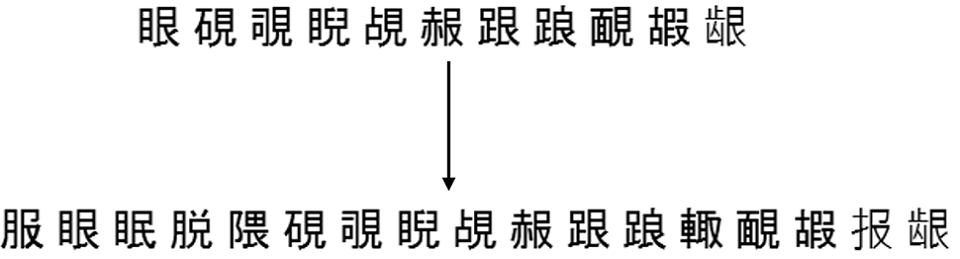
Para que estos problemas no condujeran a desaceleraciones severas en todo el sistema de reconocimiento, tuve que usar muchas heurísticas, principalmente destinadas a cortar rápidamente un número significativo de jeroglíficos, que definitivamente esta imagen no parece. Todavía no ayudó hasta el final, pero queríamos llevar nuestra tecnología a un nivel completamente nuevo.
Comenzamos a estudiar la aplicabilidad de las redes neuronales convolucionales para aumentar tanto la calidad como la velocidad de reconocimiento de los jeroglíficos. Quería reemplazar toda la unidad para reconocer un solo carácter para estos idiomas con la ayuda de redes neuronales. En este artículo, describiremos cómo finalmente lo logramos.
Un enfoque simple: una red de convolución para reconocer todos los jeroglíficos
En general, el uso de redes convolucionales para el reconocimiento de caracteres no es una idea nueva en absoluto.
Históricamente, se utilizaron por
primera vez precisamente para esta tarea en 1998. Es cierto que estos no eran caracteres impresos, sino letras y números escritos a mano en inglés.
Más de 20 años, la tecnología en el campo del aprendizaje profundo, por supuesto, ha avanzado. Incluyendo arquitecturas más avanzadas y nuevos enfoques de aprendizaje.
La arquitectura presentada en el diagrama anterior (LeNet), de hecho, y hoy es muy adecuada para tareas tan simples como el reconocimiento de texto impreso. "Simple" lo llamo en comparación con otras tareas de visión por computadora, como la búsqueda y el reconocimiento de rostros.
Parece que la solución no es más simple. Tomamos una red neuronal, una muestra de jeroglíficos etiquetados y la entrenamos para el problema de clasificación. Desafortunadamente, resultó que no todo es tan simple. Todas las modificaciones posibles de LeNet para la tarea de clasificar 10,000 jeroglíficos no proporcionaron calidad suficiente (al menos comparable al sistema de reconocimiento que ya tenemos).
Para lograr la calidad requerida, tuvimos que considerar arquitecturas más profundas y complejas: WideResNet, SqueezeNet, etc. Con su ayuda, fue posible alcanzar el nivel de calidad requerido, pero dieron una fuerte reducción de velocidad: 3-5 veces en comparación con el algoritmo básico en la CPU.
Alguien puede preguntar: "¿Cuál es el punto de medir la velocidad de la red en la CPU, si funciona mucho más rápido en el procesador de gráficos (GPU)"? Aquí vale la pena hacer un comentario sobre el hecho de que la velocidad del algoritmo en la CPU es principalmente importante para nosotros. Estamos desarrollando tecnología para la gran línea de productos de reconocimiento de ABBYY. En el mayor número de escenarios, el reconocimiento se realiza en el lado del cliente, y no podemos saber que tiene una GPU.
Entonces, al final, llegamos al siguiente problema: una red neuronal para reconocer todos los caracteres dependiendo de la elección de la arquitectura funciona muy mal o muy lentamente.
Modelo de reconocimiento de jeroglíficos de red neuronal de dos niveles
Tenía que buscar otra forma. Al mismo tiempo, no quería abandonar las redes neuronales. Parecía que el mayor problema era una gran cantidad de clases, por lo que era necesario construir redes de arquitectura compleja. Por lo tanto, decidimos que no entrenaríamos una red para un gran número de clases, es decir, para todo el alfabeto, sino que entrenaríamos muchas redes para un pequeño número de clases (subconjuntos del alfabeto).
En detalles generales, el sistema ideal se presentó de la siguiente manera: el alfabeto se divide en grupos de caracteres similares. La red de primer nivel clasifica a qué grupo de caracteres pertenece una imagen determinada. Para cada grupo, a su vez, se entrena una red de segundo nivel, que produce la clasificación final dentro de cada grupo.
Imagen en la que se puede hacer clic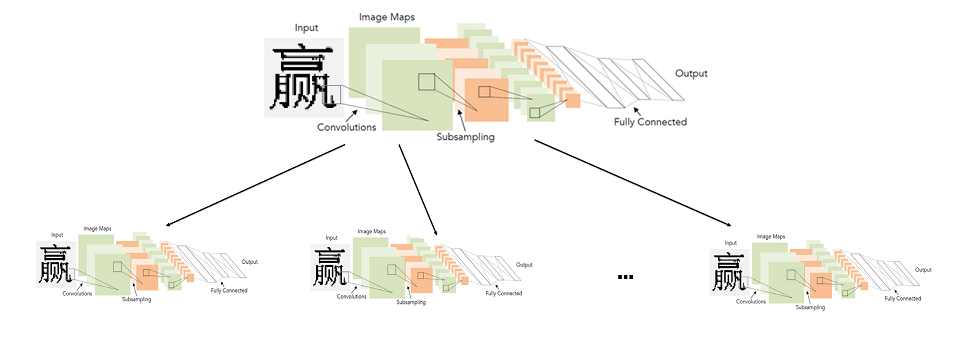
Por lo tanto, hacemos la clasificación final mediante el lanzamiento de dos redes: la primera determina qué red de segundo nivel lanzar y la segunda ya realiza la clasificación final.
En realidad, el punto fundamental aquí es cómo dividir a los personajes en grupos para que la red de primer nivel pueda ser precisa y rápida.
Construyendo un clasificador de primer nivel
Para comprender qué símbolos de red son más fáciles de distinguir y cuáles son más difíciles, es más fácil observar qué signos destacan para símbolos particulares. Para hacer esto, tomamos una red clasificadora entrenada para distinguir todos los caracteres del alfabeto con buena calidad y observamos las estadísticas de activación de la penúltima capa de esta red; comenzamos a mirar las representaciones de características finales que la red recibe para todos los caracteres.
Al mismo tiempo, sabíamos que la imagen debería ser algo como lo siguiente:
Este es un ejemplo simple para el caso de clasificar una selección de dígitos escritos a mano (MNIST) en 10 clases. En la penúltima capa oculta, que va antes de la clasificación, solo hay 2 neuronas, lo que hace que sus estadísticas de activación sean fáciles de mostrar en el avión. Cada punto en el gráfico corresponde a algún ejemplo de la muestra de prueba. El color de un punto corresponde a una clase específica.
En nuestro caso, la dimensión del espacio de características fue mayor que 128 en el ejemplo. Corrimos un grupo de imágenes de una muestra de prueba y recibimos un vector de características para cada imagen. Después de eso, fueron normalizados (divididos por la longitud). De la imagen de arriba es obvio por qué vale la pena hacerlo. Agrupamos los vectores normalizados por el método KMeans. Obtuvimos un desglose de la muestra en grupos de imágenes similares (desde el punto de vista de la red).
Pero al final, necesitábamos obtener una partición del alfabeto en grupos, y no una partición de la muestra de prueba. Pero el primero del segundo no es difícil de obtener: es suficiente asignar cada etiqueta de clase al clúster que contiene la mayoría de las imágenes de esta clase. En la mayoría de las situaciones, por supuesto, toda la clase incluso terminará dentro de un grupo.
Bueno, eso es todo, tenemos una partición del alfabeto completo en grupos de caracteres similares. Luego queda elegir una arquitectura simple y entrenar al clasificador para distinguir entre estos grupos.
Aquí hay un ejemplo de 6 grupos aleatorios que se obtienen dividiendo el alfabeto fuente completo en 500 grupos:
Construcción de clasificadores de segundo nivel.
A continuación, debe decidir qué conjunto de personajes objetivo aprenderán los clasificadores de segundo nivel. La respuesta parece ser obvia: estos deberían ser grupos de caracteres obtenidos en el paso anterior. Esto funcionará, pero no siempre con buena calidad.
El hecho es que el clasificador del primer nivel comete errores en cualquier caso y pueden compensarse parcialmente mediante la construcción de conjuntos del segundo nivel de la siguiente manera:
- Arreglamos una cierta muestra separada de imágenes de símbolos (que no participan ni en la capacitación ni en las pruebas);
- Ejecutamos esta muestra a través de un clasificador de primer nivel capacitado, marcando cada imagen con la etiqueta de este clasificador (etiqueta de grupo);
- Para cada símbolo, consideramos todos los grupos posibles a los que el clasificador del primer nivel pertenece a las imágenes de este símbolo;
- Agregue este símbolo a todos los grupos hasta alcanzar el grado de cobertura requerido T_acc;
- Consideramos los grupos finales de símbolos como conjuntos de objetivos del segundo nivel, en los que se entrenarán los clasificadores.
Por ejemplo, las imágenes del símbolo "A" fueron asignadas por el clasificador de primer nivel 980 veces al 5 ° grupo, 19 veces al 2 ° grupo y 1 vez al 6 ° grupo. En total tenemos 1000 imágenes de este símbolo.
Luego podemos agregar el símbolo "A" al 5to grupo y obtener un 98% de cobertura de este símbolo. Podemos atribuirlo al quinto y segundo grupo y obtener una cobertura del 99.9%. Y podemos atribuirlo inmediatamente a grupos (5, 2, 6) y obtener una cobertura del 100%.
En esencia, T_acc establece cierto equilibrio entre velocidad y calidad. Cuanto mayor sea, mayor será la calidad final de la clasificación, pero mayores serán los conjuntos de objetivos del segundo nivel y más difícil será la clasificación en el segundo nivel.
La práctica muestra que incluso con T_acc = 1, el aumento en el tamaño de los conjuntos como resultado del procedimiento de reposición descrito anteriormente no es tan significativo, en promedio, aproximadamente 2 veces. Obviamente, esto dependerá directamente de la calidad del clasificador entrenado de primer nivel.
Aquí hay un ejemplo de cómo funciona esta finalización para uno de los conjuntos de la misma partición en 500 grupos, que era mayor:
Resultados de incrustación del modelo
Los modelos de dos niveles entrenados finalmente han funcionado más rápido y mejor que los clasificadores utilizados anteriormente. De hecho, no fue tan fácil "hacer amigos" con el mismo gráfico de división lineal (GLD). Para hacer esto, tuve que enseñar por separado el modelo para distinguir los caracteres de la basura a priori y los errores de segmentación de línea (para devolver una baja confianza en estas situaciones).
El resultado final de incrustar en el algoritmo de reconocimiento de documentos completo a continuación (obtenido en la colección de documentos chinos y japoneses), la velocidad se indica para el algoritmo completo:
Mejoramos la calidad y aceleramos tanto en modo normal como en modo rápido, mientras transferimos todo el reconocimiento de caracteres a las redes neuronales.
Un poco sobre el reconocimiento de extremo a extremo
Hoy en día, la mayoría de los sistemas de OCR conocidos públicamente (el mismo Tesseract de Google) utilizan la arquitectura de extremo a extremo de las redes neuronales para reconocer cadenas o sus fragmentos en su totalidad. Pero aquí usamos redes neuronales precisamente como un reemplazo para un módulo de reconocimiento de un solo carácter. Esto no es un accidente.
El hecho es que la segmentación de una cadena en caracteres en chino impreso y japonés no es un gran problema debido a la impresión
monoespaciada . En este sentido, el uso del reconocimiento de extremo a extremo para estos idiomas no mejora en gran medida la calidad, pero es mucho más lento (al menos en la CPU). En general, no está claro cómo usar el enfoque de dos niveles propuesto en el contexto de extremo a extremo.
Por el contrario, hay lenguajes para los cuales la división lineal en caracteres es un problema clave. Ejemplos explícitos son árabe, hindi. Para el árabe, por ejemplo, las soluciones de extremo a extremo ya se están estudiando activamente con nosotros. Pero esta es una historia completamente diferente.
Alexey Zhuravlev, Jefe del Grupo de Nuevas Tecnologías de OCR