Hola Habr! Mi nombre es Sergey Lezhnin, soy arquitecto senior en Sbertekh. Una de las direcciones de mi trabajo es el Sistema Frontal Unificado. Este sistema tiene un servicio de gestión de parámetros de configuración. Es utilizado por muchos usuarios, servicios y aplicaciones, lo que requiere un alto rendimiento. En esta publicación, contaré cómo evolucionó este servicio desde la primera, la más simple, hasta su versión actual y por qué finalmente implementamos la arquitectura completa 180 grados.

Aquí es donde comenzamos: esta es la primera implementación del servicio de gestión de parámetros:
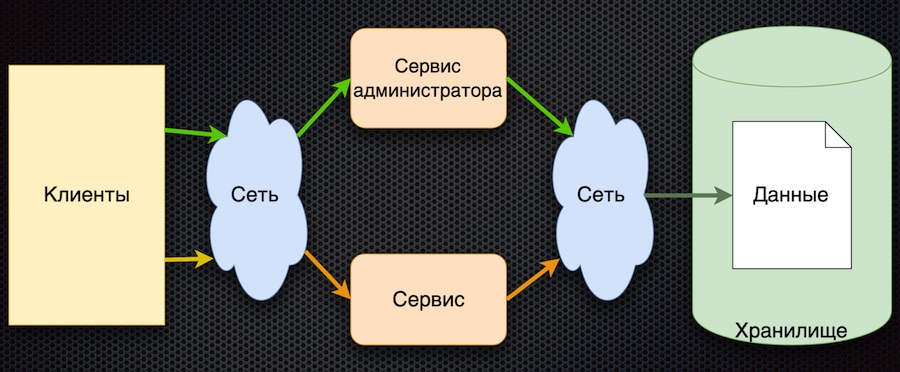
El cliente solicita los parámetros de configuración del servicio. El servicio traduce la solicitud a la base de datos, recibe una respuesta y la devuelve al cliente. Al mismo tiempo, los administradores pueden administrar los parámetros utilizando su servicio separado: agregar nuevos valores, cambiar los actuales.
Este enfoque tiene una ventaja: la simplicidad. Hay más desventajas, aunque todas están relacionadas:
- acceso frecuente al almacenamiento a través de la red,
- alta competencia por el acceso a la base de datos (la tenemos ubicada en un nodo),
- bajo rendimiento
Para pasar la prueba de carga, esta arquitectura tenía que proporcionar la carga no más que la que viene a través del acceso directo a la base de datos. Como resultado, la prueba de carga de este circuito no pasó.
La segunda etapa: decidimos almacenar en caché los datos en el lado del servicio.

Aquí, los datos de la solicitud se cargan inicialmente en la memoria caché compartida y se devuelven de la memoria caché en las siguientes solicitudes. El administrador del servicio no solo administra los datos, sino que también los marca en la memoria caché para que, cuando cambien, se actualicen.
Entonces redujimos el número de accesos al repositorio. Al mismo tiempo, la sincronización de datos resultó ser simple, ya que el servicio de administrador tiene acceso a la memoria caché en la memoria y controla el reinicio. Por otro lado, si ocurre una falla en la red, el cliente no podrá recibir datos. Y, en general, la lógica de obtener datos es complicada: si no hay datos en el caché, debe obtenerlos de la base de datos, ponerlos en el caché y solo luego devolverlos. Necesidad de desarrollar más.
La tercera etapa de desarrollo es el almacenamiento en caché de datos del lado del cliente:
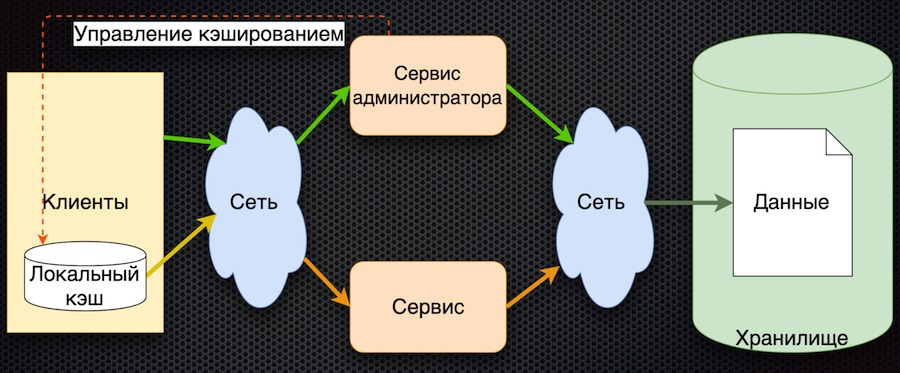
El cliente tiene un shell para acceder al servicio (el "módulo del cliente"), que oculta el caché de datos local. Si los datos solicitados no están en la memoria caché cuando se solicita, se llama al servicio. El servicio solicita parámetros de la base de datos y los devuelve. En comparación con el esquema anterior, la gestión del almacenamiento en caché es complicada aquí. Para restablecer los parámetros, el servicio debe notificar a los clientes que estos parámetros han cambiado.
En esta arquitectura, reducimos el número de llamadas al servicio y a la base de datos. Ahora, si el parámetro ya se solicitó, volverá al cliente sin acceder a la red, incluso si el servicio o la base de datos no están disponibles. Por otro lado, el gran inconveniente es que la lógica de intercambiar datos con el cliente es complicada, además debe notificarlo a través de algún servicio, por ejemplo, la cola de mensajes. El cliente debe suscribirse al tema, recibe notificaciones sobre el cambio de parámetros y, en su caché, el cliente debe restablecerlos para obtener nuevos valores. Esquema bastante complicado.
Finalmente, llegamos a la última etapa en este momento. En esto fuimos ayudados por los principios básicos formulados en el Manifiesto Reactivo.
- Receptivo: el sistema responde lo más rápido posible.
- Resistente: el sistema continúa respondiendo incluso en caso de falla.
- Elástico: el sistema utiliza recursos de acuerdo con la carga.
- Dirigido por mensajes: proporciona asincronía y mensajes gratuitos entre los componentes del sistema.
El esquema correspondiente a este enfoque resultó ser bastante simple:
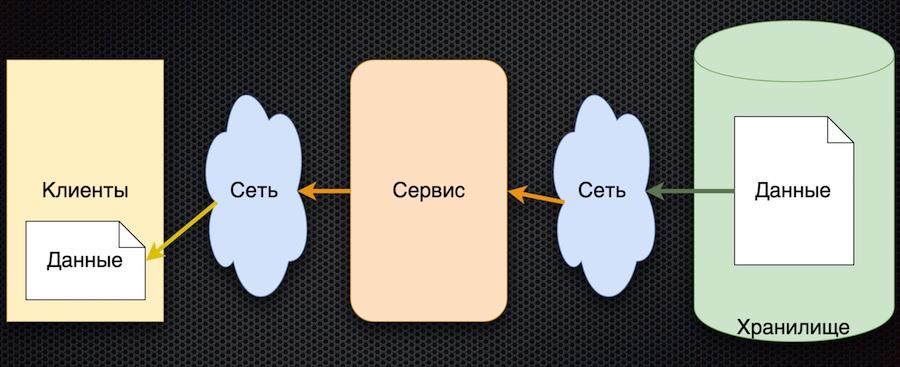
El principio general es el siguiente: el cliente se suscribe al parámetro de configuración, y cuando sus valores cambian, el servidor lo notifica al cliente. El esquema anterior está ligeramente simplificado: no refleja que cuando un cliente se registra, necesita inicializar y obtener el valor inicial. Pero luego está lo principal: las flechas cambiaron de dirección. Anteriormente, un cliente o caché solicitaba activamente un servicio para cambios de datos, pero ahora el servicio mismo envía eventos sobre cambios de datos y el cliente los actualiza.
Esta arquitectura tiene varias ventajas importantes. El número de llamadas al servicio y al almacenamiento se reduce, porque el cliente no lo solicita activamente. De hecho, el atractivo para cada parámetro deseado se produce solo una vez, al suscribirse a él. Entonces el cliente simplemente recibe una secuencia de cambios. La disponibilidad de datos aumenta porque el cliente siempre tiene un valor: se almacena en caché. Y en general, este esquema para intercambiar parámetros es bastante simple.
El único inconveniente de esta arquitectura es la incertidumbre en la inicialización de datos. Hasta la primera actualización por suscripción, el valor del parámetro permanece indefinido. Pero esto se puede resolver estableciendo los valores de parámetros predeterminados del cliente, que se reemplazan por los reales durante la primera actualización.
Selección de tecnología
Una vez aprobado el esquema, comenzamos la búsqueda de productos para su implementación.
Elija entre
Vertx.io ,
Akka.io y
Spring Boot .

La tabla resume las características que nos interesan. Vertx y Akka tienen actores, y Sping Boot tiene una biblioteca de microservicios que está esencialmente cerca de los actores. De manera similar con la reactividad: Spring Boot tiene su propia biblioteca WebFlux que implementa las mismas características. Estimamos la ligereza aproximadamente dentro de la mesa. En cuanto a los idiomas, de las tres opciones, Vertx se considera un políglota: es compatible con Java, Scala, Kotlin y JavaScript. Akka tiene Scala y Java; Kotlin probablemente también se puede usar, pero no hay soporte directo. Spring tiene Java, Kotlin y Groovy.
Como resultado, Vertx ganó. Por cierto, hablaron mucho sobre él en la conferencia JUG, y de hecho muchas compañías lo usan. Aquí hay una captura de pantalla del sitio del desarrollador:

En Vertx.io, el esquema de implementación de nuestra solución es el siguiente:

Decidimos almacenar los parámetros no en la base de datos, sino en el repositorio de Git. Podemos utilizar muy bien esta fuente de datos relativamente lenta debido al hecho de que el cliente no solicita parámetros activamente y se reduce el número de visitas.
Un lector (vertical) lee datos del repositorio de Git en la memoria de la aplicación para acelerar el acceso del usuario a los datos. Esto es importante, por ejemplo, al suscribirse a parámetros. Además, el lector procesa las actualizaciones: vuelve a leer y marca los datos, reemplaza los datos antiguos por nuevos.
Event Bus es un servicio de Vertx que envía eventos entre verticales y también a través de puentes. Incluso a través del puente websocket, que se utiliza en este caso. Cuando llegan los eventos de cambio de parámetros, el bus de eventos los envía al cliente.
Finalmente, en el lado del cliente, aquí se implementa un cliente web simple, que se suscribe a eventos (cambios de parámetros) y muestra estos cambios en las páginas.
Como funciona
Mostramos cómo funciona todo a través de una aplicación web.
Lanzamos la página de la aplicación en el navegador. Nos suscribimos a los cambios de datos clave. Luego vamos a la página del proyecto en GitLab local, cambiamos los datos en formato JSON y los guardamos en el repositorio. La aplicación muestra el cambio correspondiente, que necesitábamos.
Eso es todo. Puede encontrar el código fuente de la demostración en mi
repositorio git y hacer preguntas en los comentarios.