
Las redes sociales son uno de los productos de Internet más populares en la actualidad y una de las principales fuentes de datos para el análisis. Dentro de las propias redes sociales, se considera que la tarea más difícil e interesante en el campo de la ciencia de datos es la formación de un servicio de noticias. De hecho, para satisfacer las crecientes demandas del usuario por la calidad y relevancia del contenido, es necesario aprender cómo recopilar información de muchas fuentes, calcular el pronóstico de la reacción del usuario y el equilibrio entre docenas de métricas competidoras en la prueba A / B. Y grandes cantidades de datos, altas cargas de trabajo y requisitos estrictos para la velocidad de respuesta hacen que la tarea sea aún más interesante.
Parecería que hoy las tareas de clasificación ya se han estudiado a lo largo y ancho, pero si se mira de cerca, no es tan simple. El contenido en el feed es muy heterogéneo: esta es una foto de amigos y notas, videos virales, lecturas largas y pop científico. Para unir todo, necesita conocimiento de varios campos: visión por computadora, trabajo con textos, sistemas de recomendación y, sin falta, herramientas modernas de almacenamiento y procesamiento de datos altamente cargadas. Encontrar una persona con todas las habilidades es extremadamente difícil hoy, por lo que clasificar la cinta es realmente una tarea de equipo.
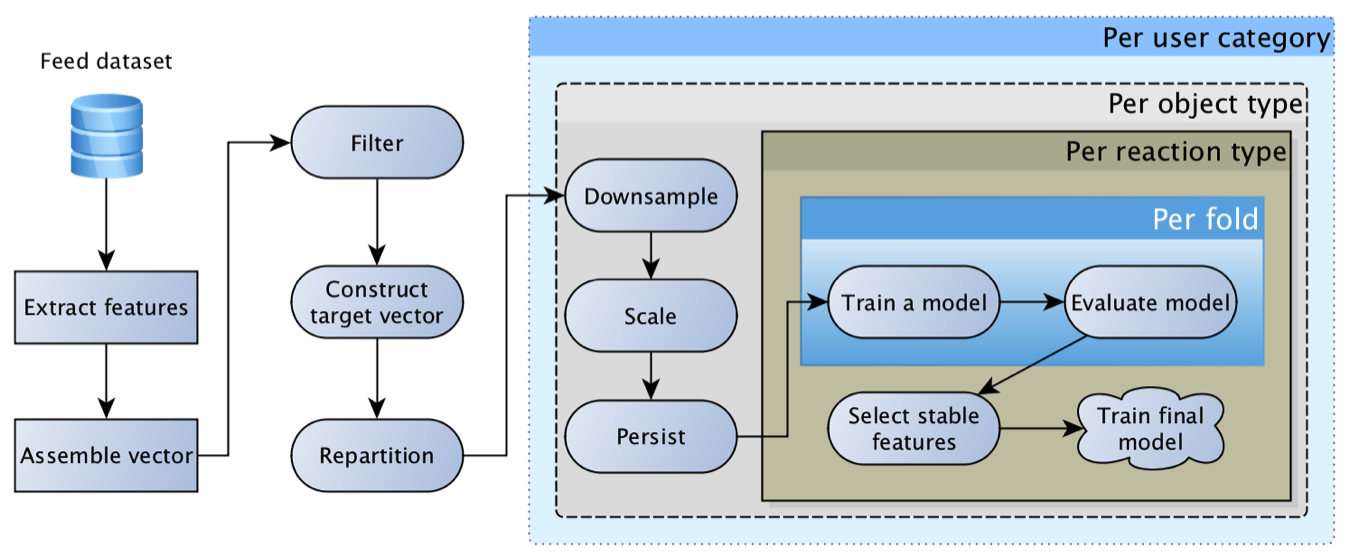
Odnoklassniki comenzó a experimentar con diferentes algoritmos de clasificación de cintas en 2012, y en 2014, el aprendizaje automático también se unió a este proceso. Esto fue posible, en primer lugar, gracias al progreso en el campo de las tecnologías para trabajar con flujos de datos. Recién comenzando a recopilar visualizaciones de objetos y sus atributos en
Kafka y agregando registros utilizando
Samza , pudimos construir un conjunto de datos para modelos de entrenamiento y
calcular las características más "atrayentes" : Haga clic en Tasa de objetos y pronósticos del sistema de recomendación "basado en" el
trabajo de colegas de LinkedIn .

Rápidamente se hizo evidente que el caballo de batalla de la regresión logística no puede sacar la cinta solo, porque el usuario puede tener una reacción muy diversa: clase, comentario, clic, ocultación, etc., y el contenido puede ser muy diferente: foto un amigo, una publicación grupal o una vidosik inscrita por un amigo. Cada reacción para cada tipo de contenido tiene su propia especificidad y su propio valor comercial. Como resultado, llegamos al concepto de una "
matriz de regresiones logísticas ": se construye un modelo separado para cada tipo de contenido y cada reacción, y luego sus pronósticos se multiplican por una matriz de peso formada por manos basadas en las prioridades comerciales actuales.
Este modelo fue extremadamente viable y durante mucho tiempo fue el principal. Con el tiempo, adquirió características cada vez más interesantes: para objetos, para usuarios, para autores, para la relación del usuario con el autor, para aquellos que interactuaron con el objeto, etc. Como resultado, los primeros intentos de reemplazar la regresión con una red neuronal terminaron en un triste "las características que tenemos son demasiado basura, la malla no da un impulso".
En este caso, a menudo el impulso más tangible desde el punto de vista de la actividad del usuario fue proporcionado por mejoras técnicas más que algorítmicas: recoger más candidatos para la clasificación, rastrear con mayor precisión los hechos del programa, optimizar la velocidad de respuesta del algoritmo y profundizar el historial de navegación. Tales mejoras a menudo producían unidades, y a veces incluso decenas de por ciento de aumento en la actividad, mientras que la actualización del modelo y la adición de una característica a menudo daban décimas de aumento porcentual.

Una dificultad separada en los experimentos con la actualización del modelo fue crear un reequilibrio de contenido: la distribución de pronósticos del "nuevo" modelo a menudo podría diferir significativamente de su predecesor, lo que condujo a una redistribución del tráfico y la retroalimentación. Como resultado, es difícil evaluar la calidad del nuevo modelo, ya que primero debe calibrar el equilibrio del contenido (repita el proceso de establecer los pesos de la matriz para fines comerciales). Después de estudiar la
experiencia de colegas de Facebook , nos dimos cuenta de que el modelo
necesita ser calibrado , y se agregó la regresión isotónica además de la regresión logística :).
A menudo, en el proceso de preparación de nuevos atributos de contenido, experimentamos frustración: un modelo simple que utiliza técnicas básicas de colaboración puede dar el 80%, o incluso el 90% del resultado, mientras que una red neuronal de moda, entrenada durante una semana en GPU súper caras, detecta perfectamente gatos y autos, pero aumenta métricas solo en el tercer dígito. A menudo se puede ver un efecto similar al implementar modelos temáticos, texto rápido y otras incrustaciones. Logramos superar la frustración observando la validación desde el ángulo correcto: el rendimiento de los algoritmos de colaboración mejora significativamente a medida que se acumula información sobre el objeto, mientras que para los objetos "frescos" los atributos de contenido dan un impulso tangible.
Pero, por supuesto, algún día se mejorarían los resultados de la regresión logística, y se logró el progreso aplicando el recientemente lanzado
XGBoost-Spark . La integración
no fue fácil , pero al final, el modelo finalmente se puso de moda y joven, y las métricas crecieron en un porcentaje.
Seguramente, se puede extraer mucho más conocimiento de los datos y la clasificación de la cinta se puede llevar a una nueva altura, y hoy todos tienen la oportunidad de probar suerte en esta tarea no trivial en la competencia
SNA Hackathon 2019 . La competencia se lleva a cabo en dos etapas: del 7 de febrero al 15 de marzo, descargue la solución a una de las tres tareas. Después del 15 de marzo, se resumirán los resultados intermedios, y 15 personas de la cima de la tabla de clasificación para cada tarea recibirán invitaciones a la segunda etapa, que se llevará a cabo del 30 de marzo al 1 de abril en la oficina de Moscú del Grupo Mail.ru. Además, la invitación a la segunda etapa recibirá a tres personas que lideran la calificación a fines del 23 de febrero.
¿Por qué hay tres tareas? Como parte de la fase en línea, ofrecemos tres conjuntos de datos, cada uno de los cuales presenta solo uno de los aspectos: imagen, texto o información sobre una variedad de atributos de colaboración. Y solo en la segunda etapa, cuando se unen expertos en diferentes campos, se revelará el conjunto de datos general, lo que le permitirá encontrar puntos para la sinergia de diferentes métodos.
Interesado en una tarea? Únete a
SNA Hackathon :)