Bill Kennedy dijo en una conferencia sobre su maravilloso curso de
programación Ultimate Go :
Muchos desarrolladores buscan optimizar su código. Toman una línea y la reescriben, diciendo que esto será más rápido. Necesito parar Decir que este o aquel código es más rápido es posible solo después de que se perfila y se hacen puntos de referencia. La adivinación no es el enfoque correcto para escribir código.
Hace tiempo que quería demostrar con un ejemplo práctico cómo puede funcionar esto. Y el otro día, me llamó la atención el siguiente código, que podría usarse como ejemplo:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
Aquí, en todos los elementos del segmento de
compilaciones devueltos desde la base de datos,
PatchURLs se reemplaza por
ReversePatchURLs ,
ExtractedSize por
RPatchExtractedSize y se realiza el reverso: el orden de los elementos cambia para que el último elemento se convierta en el primero y el primero en el último.
En mi opinión, el código fuente es un poco complicado de leer y puede optimizarse. Este código realiza un algoritmo simple que consta de dos partes lógicas: cambiar elementos de corte y ordenar. Pero para que el programador aísle estos dos componentes, llevará tiempo.
A pesar de que ambas partes son importantes, el código inverso no está tan enfatizado como nos gustaría. Se dispersa a lo largo de tres líneas separadas: inicializando una nueva división, iterando una división existente en orden inverso, agregando un elemento al final de una nueva división. Sin embargo, uno no puede ignorar las ventajas indudables de este código: el código está funcionando y probado, y hablando objetivamente, es bastante adecuado. La percepción subjetiva del código por parte de un desarrollador individual no puede ser una excusa para reescribirlo. Desafortunadamente o afortunadamente, no reescribimos el código solo porque simplemente no nos gusta (o, como suele suceder, simplemente porque no es nuestro, ver
Fallo fatal ).
Pero, ¿qué sucede si logramos no solo mejorar la percepción del código, sino también acelerarlo significativamente? Este es un asunto completamente diferente. Puede ofrecer varios algoritmos alternativos que realizan la funcionalidad integrada en el código.
Primera opción: iterar sobre todos los elementos en un bucle de
rango ; Para invertir el corte original en cada iteración, agregue un elemento al principio de la matriz final. Por lo tanto, podríamos deshacernos de lo engorroso
de la variable
i , usar la función
len , es difícil percibir iterar sobre los elementos desde el final, y también reducir la cantidad de código en dos líneas (de siete líneas a cinco), y cuanto más pequeño sea el código, menos probabilidades hay de permitirlo un error
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
Después de haber eliminado la enumeración del segmento desde el final, distinguimos claramente entre las operaciones de cambio de elementos (tercera fila) y el reverso de la matriz original (cuarta fila).
La idea principal de la segunda opción es explotar aún más la variación de elementos y la clasificación. Primero, clasificamos los elementos y los cambiamos, y luego clasificamos el segmento por una operación separada. Este método requerirá una implementación adicional de la interfaz de clasificación para el segmento, pero aumentará la legibilidad y separará por completo y aislará el reverso de los elementos cambiantes, y el método
Reverso definitivamente le indicará al lector el resultado deseado.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
La tercera opción es casi una repetición de la segunda, pero
sort.Slice se usa para ordenar, lo que aumenta la cantidad de código en una línea, pero evita la implementación adicional de la interfaz de clasificación.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
A primera vista, en términos de complejidad interna, el número de iteraciones, las funciones aplicadas, el código inicial y el primer algoritmo están cerca; La segunda y la tercera opción pueden parecer más difíciles, pero es imposible decir inequívocamente cuál de las cuatro opciones es la óptima.
Por lo tanto, nos prohibimos tomar decisiones basadas en suposiciones no respaldadas por evidencia, pero es obvio que lo más interesante aquí es cómo se comporta la función append cuando se agrega un elemento al final y al comienzo del segmento. Después de todo, de hecho, esta función no es tan simple como parece.
Append funciona de la
siguiente manera : agrega un nuevo elemento al segmento existente si su capacidad es mayor que la longitud total, o reserva en la memoria un lugar para un nuevo segmento, copiando los datos del primer segmento, agregando los datos del segundo y devolviendo uno nuevo como resultado rebanada
El matiz más interesante en el trabajo de esta función es el algoritmo utilizado para reservar memoria para una nueva matriz. Dado que la operación más costosa es asignar una nueva pieza de memoria, los desarrolladores de Go hicieron un pequeño truco para hacer que la operación de
agregar sea más barata. Al principio, para no volver a reservar la memoria cada vez que se agrega un elemento, la cantidad de memoria se asigna con un cierto margen, dos veces el original, pero después de un cierto número de elementos, el tamaño de la sección de memoria recién reservada se convierte en no más de dos veces, sino en un 25%.
Dada la nueva comprensión de la función
append, la respuesta a la pregunta: "¿Qué será más rápido: agregar un elemento al final de un segmento existente o agregar un segmento existente a un segmento de un elemento?" - Ya más transparente. Se puede suponer que en el segundo caso, en comparación con el primero, habrá más asignaciones de memoria, lo que afectará directamente la velocidad del trabajo.
Así que nos acercamos sin problemas a los puntos de referencia. Con la ayuda de puntos de referencia, puede evaluar la carga del algoritmo en los recursos más críticos, como el tiempo de ejecución y la RAM.
Escribamos un punto de referencia para evaluar nuestros cuatro algoritmos, al mismo tiempo evaluaremos qué crecimiento puede darnos el rechazo de la clasificación (para comprender cuánto tiempo total se dedica a clasificar exactamente). Código de referencia:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
Inicie el punto de referencia con el comando
go test -bench =. -benchmem .
Los resultados de cálculo para los segmentos 10, 100, 1000, 10 000 y 100 000 elementos se presentan en el gráfico a continuación, donde F1 es el algoritmo inicial, F2 es la adición del elemento al comienzo de la matriz, F3 es el uso de
sort.Reverse to sort, F4 es el uso de
sort.Slice , F5 - rechazo de la clasificación.
Tiempo de operación Número de asignaciones de memoria
Número de asignaciones de memoria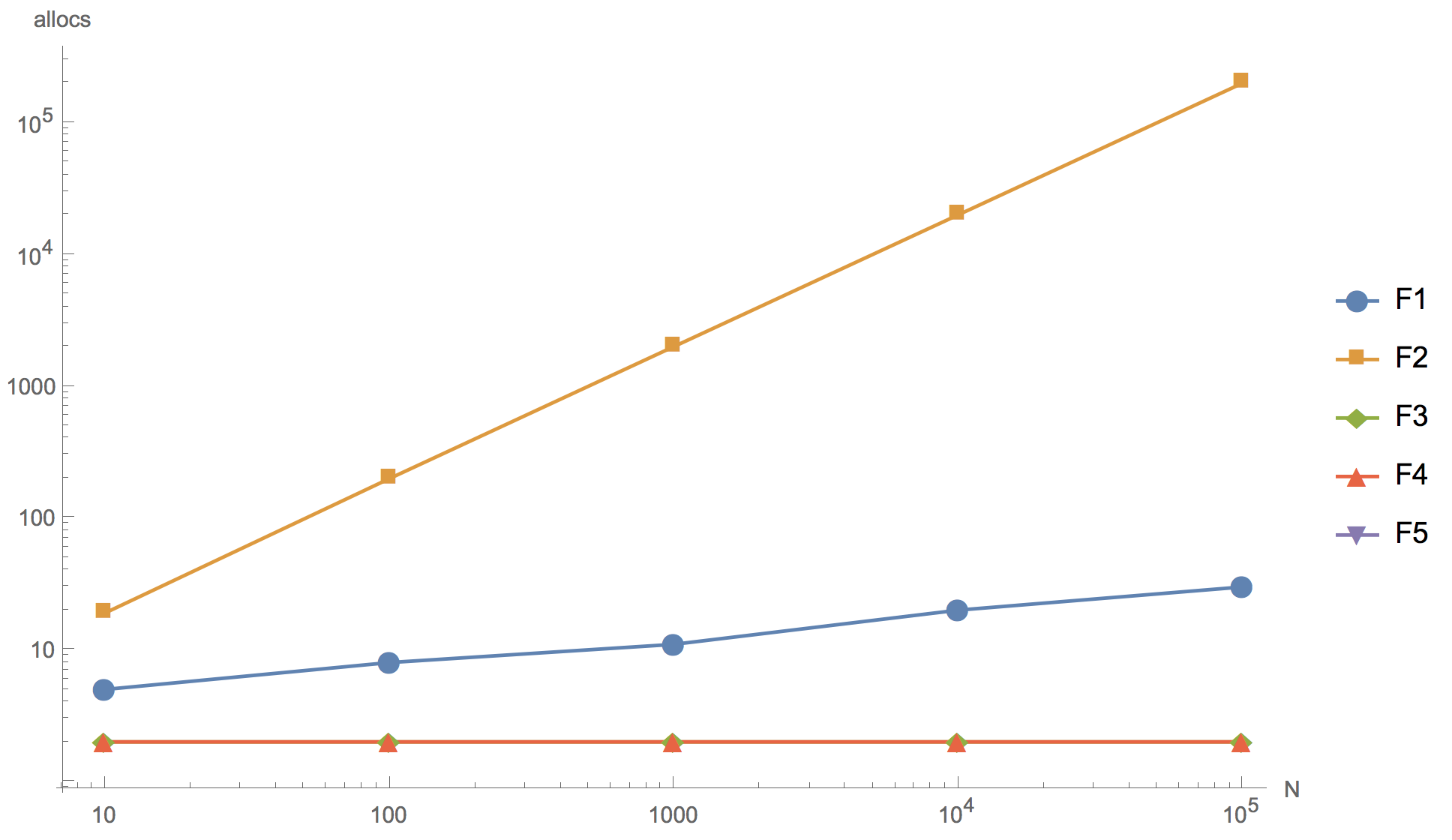
Como puede ver en el gráfico, puede aumentar la matriz, pero el resultado final ya se puede distinguir en principio en una porción de 10 elementos.
Ninguno de los algoritmos alternativos propuestos (F2, F3, F4) podría exceder el algoritmo original (F1) en velocidad. Incluso a pesar del hecho de que todos menos F2 tienen menos asignaciones de memoria que el original. El primer algoritmo (F2) con la adición de un elemento al comienzo del segmento resultó ser el más ineficiente: como se esperaba, tiene demasiadas asignaciones de memoria, tanto que es absolutamente imposible usarlo en el desarrollo de productos. Un algoritmo que utiliza la función de clasificación inversa incorporada (F3) es significativamente más lento que el original. Y solo ordenar. El
algoritmo de clasificación de
corte es comparable en velocidad al algoritmo original, pero es ligeramente inferior.
También puede notar que negarse a ordenar (F5) da una aceleración significativa. Por lo tanto, si realmente desea reescribir el código, puede ir en esta dirección, por ejemplo, elevando el segmento de
compilaciones iniciales de la base de datos, utilice la clasificación por ID DESC en lugar de ASC en la solicitud. Pero al mismo tiempo, nos vemos obligados a ir más allá de los límites de la sección de código considerada, lo que conlleva el riesgo de introducir múltiples cambios.
Conclusiones
Escribe puntos de referencia.
Tiene poco sentido gastar su tiempo pensando si un código en particular será más rápido. La información de Internet, las opiniones de colegas y otras personas, sin importar cuán autorizadas puedan ser, pueden servir como argumentos auxiliares, pero el papel del juez principal, al decidir si es o no un nuevo algoritmo, debe permanecer con los puntos de referencia.
Go es solo a primera vista un lenguaje bastante simple. La regla integral de 80⁄20 se aplica aquí. Este 20% representa las sutilezas de la estructura interna del lenguaje, cuyo conocimiento distingue al principiante del desarrollador experimentado. La práctica de escribir puntos de referencia para resolver sus preguntas es una de las formas más económicas y efectivas de obtener una respuesta y una comprensión más profunda de la estructura interna y los principios del lenguaje Go.