
Nota del traductor
La mayoría de los productos de software modernos no son monolíticos, sino que consisten en muchas partes que interactúan entre sí. En esta situación, es necesario que la comunicación de las partes interactivas del sistema tenga lugar en un idioma (a pesar de que estas partes pueden escribirse en diferentes lenguajes de programación y ejecutarse en diferentes máquinas). Para simplificar la solución a este problema, ayuda a gRPC - open-source-framework de Google, lanzado en 2015. Inmediatamente resuelve una serie de problemas, permitiendo:
- use el lenguaje de Protocol Buffers para describir la interacción de los servicios;
- generar código de programa basado en el protocolo descrito para 11 idiomas diferentes para la parte del cliente y la parte del servidor;
- implementar la autorización entre componentes que interactúan;
- use tanto la interacción sincrónica como la asincrónica.
gRPC me pareció un marco bastante interesante, y estaba interesado en conocer la experiencia real de Dropbox en la construcción de un sistema basado en él. El artículo tiene muchos detalles relacionados con el uso del cifrado, la construcción de un sistema confiable, observable y productivo, el proceso de migración de la antigua solución RPC a la nueva.
Descargo de responsabilidadEl artículo original no contiene una descripción de gRPC, y algunos puntos pueden no parecerle claros. Si no está familiarizado con gRPC u otros marcos similares (por ejemplo, Apache Thrift), le recomiendo que primero se familiarice con las ideas principales (será suficiente leer dos pequeños artículos del sitio web oficial:
“¿Qué es gRPC?” Y
“Conceptos de gRPC” ).
Gracias a Aleksey Ivanov, alias
SaveTheRbtz, por escribir el artículo original y ayudar a traducir lugares difíciles.
Dropbox gestiona muchos servicios escritos en diferentes idiomas y atiende millones de solicitudes por segundo. En el centro de nuestra arquitectura orientada a servicios se encuentra Courier, un marco RPC basado en gPC. En el proceso de su desarrollo, aprendimos mucho sobre la extensibilidad de gRPC, la optimización del rendimiento y la transición desde el sistema RPC anterior.
Nota: la publicación contiene fragmentos de código para Python y Go. También usamos Rust y Java.Camino a gRPC
Courier no es el primer marco de Dropbox RPC. Incluso antes de comenzar a dividir el sistema monolítico de Python en servicios separados, necesitábamos una base confiable para el intercambio de datos entre servicios, especialmente porque elegir un marco tendría consecuencias a largo plazo.
Antes de eso, Dropbox experimentó con diferentes marcos RPC. Primero, teníamos un protocolo individual para la serialización y deserialización manual. Algunos servicios, como el
registro basado en Scribe , utilizan
Apache Thrift . Al mismo tiempo, nuestro marco principal de RPC era un protocolo HTTP / 1.1 con mensajes serializados usando Protobuf.
Al crear un marco, elegimos entre varias opciones. Podríamos introducir Swagger (ahora conocido como
OpenAPI ) en el antiguo marco RPC,
introducir un nuevo estándar o crear un marco basado en Thrift o gRPC. El argumento principal a favor de gRPC fue la posibilidad de utilizar prototipos existentes. Además, la transferencia de datos multiplex HTTP / 2 y bidireccional fueron útiles para nuestras tareas.
Nota: si fbthrift existiera en ese momento, probablemente examinaríamos más de cerca las soluciones de Thrift.Lo que Courier trae a gRPC
Courier no es un protocolo RPC; Es un medio para integrar gRPC en una infraestructura existente. Se suponía que el marco era compatible con nuestras herramientas de autenticación, autorización y descubrimiento de servicios, así como con la recopilación, registro y seguimiento de estadísticas. Entonces creamos Courier.
Aunque en algunos casos usamos Bandaid como un proxy gRPC, la mayoría de nuestros servicios se comunican directamente entre sí para minimizar el impacto de RPC en la latencia.Fue importante para nosotros reducir la cantidad de código de rutina que debe escribirse. Dado que Courier sirve como un marco general para el desarrollo de servicios, contiene características que todos necesitan. La mayoría de ellos están habilitados de manera predeterminada y pueden controlarse mediante argumentos de línea de comando, y algunos están marcados con una casilla de verificación.
Seguridad: identidad de servicio y autenticación mutua TLS
Courier implementa nuestro mecanismo de identificación de servicio estándar. A cada servidor y cliente se le asigna un certificado TLS individual emitido por nuestra propia autoridad de certificación. El identificador personal codificado en el certificado, que se utiliza para la autenticación mutua: el servidor verifica al cliente, el cliente verifica al servidor.
En TLS, donde controlamos ambos lados de la conexión, hemos introducido restricciones estrictas. Todos los RPC internos requieren cifrado
PFS . La versión requerida de TLS es 1.2 y superior. También limitamos el número de algoritmos simétricos y asimétricos, prefiriendo
ECDHE-ECDSA-AES128-GCM-SHA256 .
Después de pasar por la identificación y descifrado de la solicitud, el servidor verifica si el cliente tiene los permisos necesarios. Las listas de control de acceso (ACL) y los límites de velocidad se pueden configurar tanto para servicios en general como para métodos individuales. Sus parámetros también se pueden cambiar a través de nuestro sistema de archivos distribuido (AFS). Gracias a esto, los propietarios de servicios pueden soltar la carga en segundos, sin siquiera reiniciar los procesos. Courier se encargará de suscribirse a las notificaciones y actualizar la configuración.
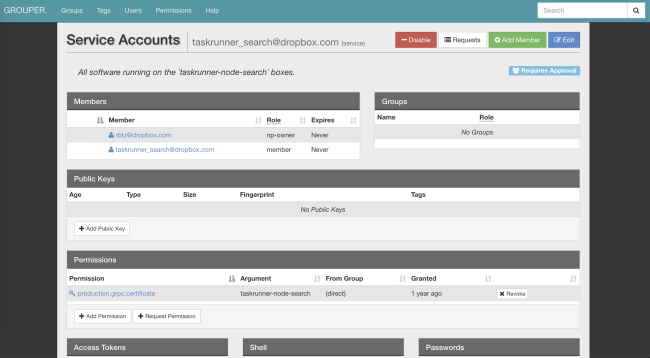
El servicio de identidad es un identificador global para ACL, límites de velocidad, estadísticas, etc. Además, es criptográficamente seguro.Aquí hay un ejemplo de configuración de ACL y límite de velocidad utilizado en nuestro
servicio de reconocimiento de patrones ópticos :
limits: dropbox_engine_ocr: # All RPC methods. default: max_concurrency: 32 queue_timeout_ms: 1000 rate_acls: # OCR clients are unlimited. ocr: -1 # Nobody else gets to talk to us. authenticated: 0 unauthenticated: 0
 Estamos considerando la posibilidad de cambiar al formato SVID (documento SPIFFE verificado criptográficamente), lo que ayudará a combinar nuestro marco con muchos proyectos de código abierto.
Estamos considerando la posibilidad de cambiar al formato SVID (documento SPIFFE verificado criptográficamente), lo que ayudará a combinar nuestro marco con muchos proyectos de código abierto.Observabilidad: estadísticas y seguimiento
Con solo un identificador, puede encontrar fácilmente registros, estadísticas, archivos de rastreo y otros datos sobre Courier.
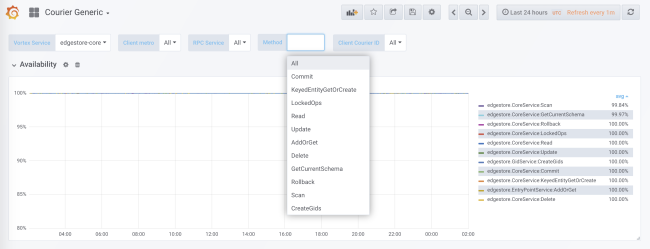
Durante la generación de código, se agrega la recopilación de estadísticas para cada servicio y cada método tanto en el lado del cliente como en el lado del servidor. Las estadísticas del lado del servidor se dividen por ID de cliente. En la configuración estándar, recibirá datos detallados sobre la carga, los errores y el tiempo de retraso para cada servicio que utiliza Courier.
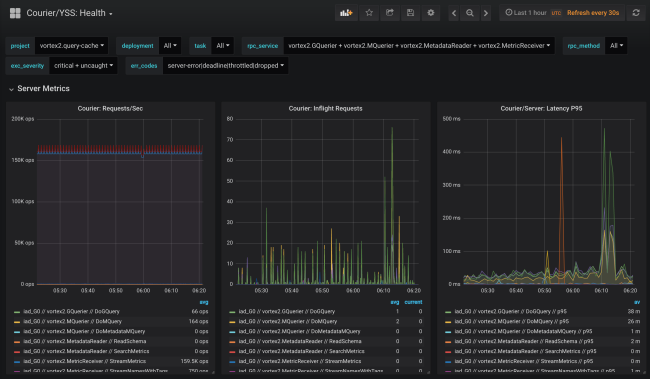
Las estadísticas de mensajería incluyen datos sobre disponibilidad y latencia en el lado del cliente, así como en el número de solicitudes y el tamaño de la cola en el lado del servidor. Hay otros gráficos útiles, en particular histogramas de tiempo de respuesta para cada método y el tiempo de apretones de manos TLS para cada cliente.
Una de las ventajas de nuestra generación de código es la posibilidad de inicialización estática de estructuras de datos, como histogramas y gráficos de trazas. Esto minimiza el impacto en el rendimiento.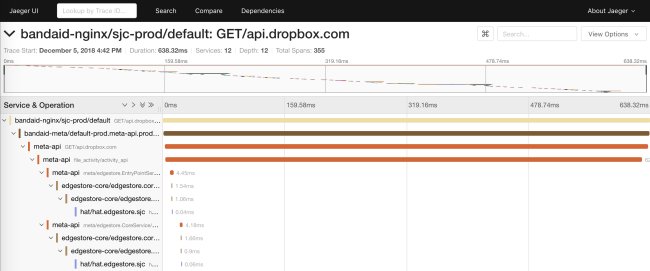
El antiguo sistema RPC solo distribuía
request_id a través de la API. Esto permitió combinar datos de los registros de diferentes servicios. En Courier, presentamos una API basada en un subconjunto de las especificaciones
OpenTracing . Escribimos nuestras propias bibliotecas en el lado del cliente, y en el lado del servidor implementamos una solución basada en Cassandra y
Jaeger .

El rastreo nos permite generar diagramas de dependencia de un servicio en tiempo de ejecución. Esto ayuda a los ingenieros a ver todas las dependencias transitivas de un servicio en particular. Además, la función es útil para rastrear dependencias no deseadas después de la implementación.
Fiabilidad: plazos y desconexión
Courier proporciona un lugar central para implementar funciones comunes del cliente (por ejemplo, tiempos de espera) en diferentes idiomas. Gradualmente agregamos varias características, a menudo basadas en los resultados de un análisis "póstumo" de problemas emergentes.
Plazos
Cada solicitud de gRPC tiene una fecha límite que indica el tiempo de espera del cliente. Dado que los apéndices de Courier distribuyen automáticamente los metadatos conocidos, la fecha límite de solicitud incluso se transfiere fuera de la API. Dentro del proceso, los plazos reciben una visualización nativa. Por ejemplo, en Go, están representados por el resultado de
context.Context del método
WithDeadline .
De hecho, pudimos solucionar clases enteras de problemas de confiabilidad al obligar a los ingenieros a establecer plazos para definir los servicios apropiados.
Este enfoque va más allá de RPC. Por ejemplo, nuestro ORM MySQL serializa un contexto RPC junto con una fecha límite en un comentario de consulta SQL. Nuestro proxy SQL puede analizar comentarios y "matar" consultas cuando se produce la fecha límite. Y como beneficio adicional al depurar llamadas a la base de datos, tenemos un enlace de consulta SQL a una consulta RPC específica.
Desconectar
Otro problema común que enfrentaron los clientes del sistema RPC anterior fue la implementación del algoritmo de retardo exponencial individual y fluctuaciones a pedido repetido.
Intentamos encontrar una solución inteligente al problema de desconexión en Courier, comenzando con la implementación del búfer LIFO (último en entrar, primero en salir) entre el servicio y el grupo de tareas.
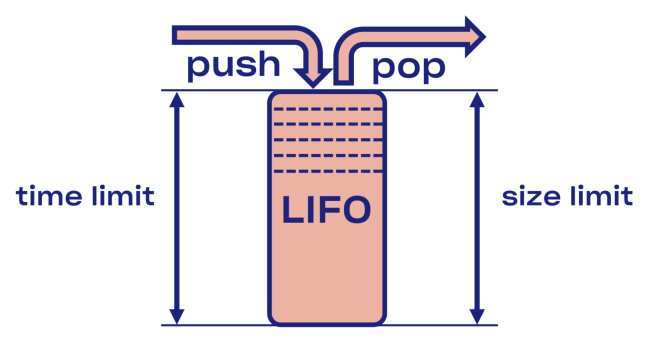
En caso de sobrecarga, LIFO se desconectará automáticamente. La cola, que es importante, está limitada no solo por el tamaño, sino también
por el tiempo (la solicitud puede pasar en la cola solo un cierto tiempo).
Menos LIFO: cambio del orden de procesamiento de solicitudes. Si desea conservar el pedido original, use CoDel . También existe la posibilidad de desconectarse, y el orden de procesamiento de las solicitudes seguirá siendo el mismo.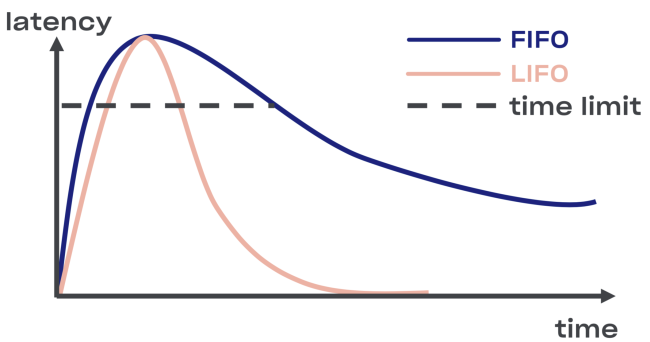
Introspección: puntos finales de depuración
Aunque los puntos finales de depuración no son directamente parte de Courier, se usan ampliamente en Dropbox y son demasiado útiles para no mencionarlos.
Por razones de seguridad, puede abrirlos en un puerto separado o en un socket Unix (para controlar el acceso mediante permisos de archivo). También debe considerar la autenticación mutua de TLS, con la cual los desarrolladores tendrán que proporcionar sus certificados para acceder a los puntos finales (principalmente no solo de lectura).Ejecución
La capacidad de analizar el estado de un servicio durante su funcionamiento es muy útil para la depuración. Por ejemplo,
se puede acceder a los perfiles de memoria dinámica y CPU a través de puntos finales HTTP o gRPC .
Planeamos aprovechar esta oportunidad en el procedimiento de verificación canaria, para automatizar la búsqueda de la diferencia entre las versiones antigua y nueva del código.Los puntos finales permiten modificar el estado de un servicio en tiempo de ejecución. En particular, los servicios basados en Golang pueden configurar dinámicamente
GCPercent .
La biblioteca
La exportación automática de datos específicos de la biblioteca como punto final RPC puede ser útil para los desarrolladores de la biblioteca. Por ejemplo, la biblioteca
malloc puede volcar estadísticas internas en un volcado . Otro ejemplo: un punto final de depuración puede cambiar el nivel de registro de servicio sobre la marcha.
Rpc
Por supuesto, la solución de problemas en protocolos cifrados y codificados no es fácil. Por lo tanto, introducir tantas herramientas como sea posible a nivel RPC es una buena idea. Un ejemplo de una API tan introspectiva
es la solución Channelz .
Nivel de aplicación
Ser capaz de aprender las opciones de nivel de aplicación también puede ser útil. Un buen ejemplo es un punto final con información general sobre la aplicación (con un hash de archivos fuente o de ensamblaje, una línea de comando, etc.). Puede ser utilizado por un sistema de orquestación para verificar la integridad al implementar un servicio.
Optimización del rendimiento
Al expandir nuestro marco gRPC a la escala requerida, encontramos varios cuellos de botella específicos para Dropbox.
Consumo de recursos de TLS Handshakes
En los servicios que sirven a muchas relaciones, como resultado de los apretones de manos TLS, la carga combinada de la CPU puede ser bastante grave (especialmente al reiniciar un servicio popular).
Para mejorar el rendimiento al firmar, reemplazamos los pares de claves RSA-2048 con el ECDSA P-256. Aquí hay ejemplos de su rendimiento (nota: con RSA, la verificación de firma es más rápida).
RSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'RSA 2048' Did ... RSA 2048 signing operations in .............. (1527.9 ops/sec) Did ... RSA 2048 verify (same key) operations in .... (37066.4 ops/sec) Did ... RSA 2048 verify (fresh key) operations in ... (25887.6 ops/sec)
ECDSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'ECDSA P-256' Did ... ECDSA P-256 signing operations in ... (40410.9 ops/sec) Did ... ECDSA P-256 verify operations in .... (17037.5 ops/sec)
Dado que la verificación con RSA-2048 es aproximadamente tres veces más rápida que con ECDSA P-256, puede elegir RSA para certificados raíz y finales para aumentar la velocidad de operación. Pero desde el punto de vista de la seguridad, no todo es tan simple: construirá cadenas de varias primitivas criptográficas y, por lo tanto, el nivel de los parámetros de seguridad resultantes será el más bajo. Y si desea mejorar el rendimiento, no recomendamos utilizar certificados de la versión RSA-4096 (y superior) como certificados raíz y finales.
También descubrimos que elegir una biblioteca TLS (y marcas de compilación) tiene un impacto significativo tanto en el rendimiento como en la seguridad. Compare, por ejemplo, la compilación LibreSSL en macOS X Mojave con el OpenSSL autoescrito en el mismo hardware.
LibreSSL 2.6.4: ~ openssl speed rsa2048 LibreSSL 2.6.4 ... sign verify sign/s verify/s rsa 2048 bits 0.032491s 0.001505s 30.8 664.3
OpenSSL 1.1.1a: ~ openssl speed rsa2048 OpenSSL 1.1.1a 20 Nov 2018 ... sign verify sign/s verify/s rsa 2048 bits 0.000992s 0.000029s 1208.0 34454.8
Sin embargo, la forma más rápida de crear un apretón de manos TLS es no crearlo en absoluto. Hemos incluido soporte para la reanudación de la sesión en gRPC-core y gRPC-python, reduciendo así la carga en la CPU durante la implementación.
El cifrado es económico
Muchos creen erróneamente que el cifrado es costoso. De hecho, incluso las computadoras modernas más simples realizan un cifrado simétrico casi al instante. Un procesador estándar puede cifrar y autenticar datos a una velocidad de 40 Gb / s por núcleo:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'AES' Did ... AES-128-GCM (8192 bytes) seal operations in ... 4534.4 MB/s
Sin embargo, aún teníamos que configurar gRPC para nuestros bloques de memoria, operando a una velocidad de 50 Gb / s. Descubrimos que si la velocidad de cifrado es aproximadamente igual a la velocidad de copia, entonces es importante minimizar el número de operaciones de
memoria. Además, realizamos algunos cambios en el propio gRPC.
Los protocolos autenticados y encriptados evitaron muchos problemas desagradables (por ejemplo, corrupción de datos por el procesador, DMA o en la red). Incluso si no usa gRPC, le recomendamos usar TLS para contactos internos.Canales de datos de alta latencia (BDP)
Nota del traductor: el subtítulo original usaba el término
producto de retraso de ancho de banda , que no tiene una traducción establecida al ruso.
La red troncal de Dropbox incluye muchos centros de datos . A veces, los nodos ubicados en diferentes regiones tienen que comunicarse a través de RPC, por ejemplo, para la replicación. Cuando se usa TCP, el núcleo del sistema es responsable de limitar la cantidad de datos transmitidos en una conexión particular (dentro de /
proc / sys / net / ipv4 / tcp_ {r, w} mem ), aunque gRPC basado en HTTP / 2 tiene su propia herramienta control de flujo El límite superior de BDP
en grpc-go está estrictamente limitado a 16 MB , lo que puede provocar un cuello de botella.
net.Server Golang o grpc.Server
Inicialmente, en nuestro código Go, admitíamos HTTP / 1.1 y gRPC con un único
servidor de red . La solución tenía sentido en términos de mantenimiento del código del programa, pero no funcionó a la perfección. La distribución de HTTP / 1.1 y gRPC a través de servidores y la migración de gRPC a grpc. El servidor mejoró significativamente el ancho de banda de Courier y el uso de memoria.
golang / protobuf o gogo / protobuf
Cambiar a gRPC puede aumentar el costo de la clasificación y la desorganización. Para el código Go, pudimos reducir significativamente la carga de la CPU en los servidores Courier al cambiar a
gogo / protobuf .
Como siempre, la transición a gogo / protobuf estuvo acompañada de algunas preocupaciones , pero si limita razonablemente la funcionalidad, no debería haber problemas.Detalles de implementación
En esta sección, penetraremos más profundamente en el dispositivo Courier, consideraremos los esquemas de protobuf y ejemplos de trozos de varios idiomas. Todos los ejemplos se toman del servicio de prueba, que utilizamos durante las pruebas de integración de Courier.
Descripción del servicio
Eche un vistazo a un extracto de la definición del servicio de prueba:
service Test { option (rpc_core.service_default_deadline_ms) = 1000; rpc UnaryUnary(TestRequest) returns (TestResponse) { option (rpc_core.method_default_deadline_ms) = 5000; } rpc UnaryStream(TestRequest) returns (stream TestResponse) { option (rpc_core.method_no_deadline) = true; } ... }
Como se indicó anteriormente, se requiere una fecha límite para todos los métodos de mensajería. Con la siguiente opción, puede establecer la fecha límite para todo el servicio:
option (rpc_core.service_default_deadline_ms) = 1000;
Al mismo tiempo, cada método se puede establecer en su propia fecha límite, cancelando la fecha límite de todo el servicio (si corresponde):
option (rpc_core.method_default_deadline_ms) = 5000;
En casos raros cuando la fecha límite no tiene sentido (por ejemplo, al rastrear un recurso), el desarrollador puede deshabilitarlo:
option (rpc_core.method_no_deadline) = true;
Además de esto, la descripción del servicio debe contener documentación API detallada, posiblemente con ejemplos de uso.
Generación de trozos
Para proporcionar una mayor flexibilidad, Courier genera sus propios apéndices sin depender de la funcionalidad del interceptor proporcionada por gRPC (con la excepción de Java, en el que la API del interceptor tiene suficiente potencia). Comparemos nuestros talones con los talones estándar de Golang.
Así es como se ven los trozos de servidor gRPC predeterminados:
func _Test_UnaryUnary_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) { in := new(TestRequest) if err := dec(in); err != nil { return nil, err } if interceptor == nil { return srv.(TestServer).UnaryUnary(ctx, in) } info := &grpc.UnaryServerInfo{ Server: srv, FullMethod: "/test.Test/UnaryUnary", } handler := func(ctx context.Context, req interface{}) (interface{}, error) { return srv.(TestServer).UnaryUnary(ctx, req.(*TestRequest)) } return interceptor(ctx, in, info, handler) }
Todo el procesamiento se lleva a cabo en el interior: decodificación de protobuf, lanzamiento de interceptores (ver la variable
interceptor en el código), lanzamiento del controlador UnaryUnary.
Ahora eche un vistazo a los trozos de Courier:
func _Test_UnaryUnary_dbxHandler( srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) ( interface{}, error) { defer processor.PanicHandler() impl := srv.(*dbxTestServerImpl) metadata := impl.testUnaryUnaryMetadata ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx) stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId) stats.TotalCount.Inc() req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, FullMethodPath: "/test.Test/UnaryUnary", Req: &test.TestRequest{}, Handler: impl._UnaryUnary_internalHandler, ClientId: clientId, EnqueueTime: time.Now(), } metadata.WorkPool.Process(req).Wait() return req.Resp, req.Err }
Aquí hay bastante código, así que analicémoslo.
Primero, aplazamos la llamada al controlador de pánico, que es responsable de recopilar los errores automáticamente. Esto nos permitirá recopilar todas las excepciones no detectadas en el repositorio central para su posterior agregación e informes:
defer processor.PanicHandler()
Otra razón por la que ejecutamos nuestro propio controlador de pánico es para asegurarnos de que la aplicación se bloquea si se produce un error. El controlador HTTP estándar de golang / net en este caso ignorará el problema y continuará atendiendo nuevas solicitudes (incluso dañadas e inconsistentes).
Luego pasamos el contexto, redefiniendo los valores basados en los metadatos de la solicitud entrante:
ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx)
También creamos (y caché para mayor eficiencia) estadísticas del cliente del lado del servidor para una agregación más detallada:
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
Esta línea crea estadísticas para cada cliente (es decir, un identificador TLS) durante la ejecución. También tenemos estadísticas sobre todos los métodos para cada servicio. Dado que el generador de código auxiliar tiene acceso a todos los métodos durante la generación de código, podemos crearlos de forma estática de antemano, evitando así retrasar el programa.
Después de eso, creamos una estructura de solicitud, la transferimos al grupo de tareas y esperamos la ejecución:
req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, ... } metadata.WorkPool.Process(req).Wait()
Tenga en cuenta que en este punto no decodificamos protobuf, ni lanzamos el interceptor. Antes de esto, el grupo de acceso, la priorización y la limitación del número de solicitudes ejecutadas deben pasar por el grupo de tareas.
Tenga en cuenta que la biblioteca gRPC admite la interfaz TAP, que le permite interceptar solicitudes a una velocidad tremenda. La interfaz proporciona la infraestructura para construir limitadores de velocidad efectivos con un consumo mínimo de recursos.Códigos de error específicos para diferentes aplicaciones.
Nuestro generador de código auxiliar también permite a los desarrolladores asignar códigos de error específicos de la aplicación utilizando opciones especiales:
enum ErrorCode { option (rpc_core.rpc_error) = true; UNKNOWN = 0; NOT_FOUND = 1 [(rpc_core.grpc_code)="NOT_FOUND"]; ALREADY_EXISTS = 2 [(rpc_core.grpc_code)="ALREADY_EXISTS"]; ... STALE_READ = 7 [(rpc_core.grpc_code)="UNAVAILABLE"]; SHUTTING_DOWN = 8 [(rpc_core.grpc_code)="CANCELLED"]; }
Tanto los errores de gRPC como de aplicación se propagan dentro del servicio, y en el borde de la API, todos los errores son reemplazados por DESCONOCIDO. Gracias a esto, podemos evitar transferir el problema a otros servicios, lo que puede provocar un cambio en su semántica.
Cambios de Python
Los stubs de Python agregan un parámetro de contexto explícito a todos los manejadores de Courier:
from dropbox.context import Context from dropbox.proto.test.service_pb2 import ( TestRequest, TestResponse, ) from typing_extensions import Protocol class TestCourierClient(Protocol): def UnaryUnary( self, ctx, # type: Context request, # type: TestRequest ):
Al principio parecía extraño, pero con el tiempo, los desarrolladores se acostumbraron a
ctx explícito como solían hacerlo.
Tenga en cuenta que nuestros talones están completamente escritos para
mypy , que se compensa durante la refactorización principal. Además, la integración con algunos IDEs (por ejemplo, PyCharm) se simplifica.
Continuando con la tendencia de la escritura estática, agregamos anotaciones mypy a los protocolos mismos:
class TestMessage(Message): field: int def __init__(self, field : Optional[int] = ..., ) -> None: ... @staticmethod def FromString(s: bytes) -> TestMessage: ...
Estas anotaciones evitarán muchos errores comunes, como asignar un valor de
Ninguno a un campo de tipo
cadena , por ejemplo
.Este código
está disponible aquí .
Proceso de migracion
Crear una nueva pila RPC no es una tarea fácil, pero ni siquiera se encuentra al lado del proceso de una transición completa, si se mira desde el punto de vista de la complejidad operativa. Por lo tanto, tratamos de hacer que sea lo más fácil posible para los desarrolladores cambiar del antiguo RPC a Courier. Dado que la migración suele ir acompañada de errores, decidimos implementarla por etapas.
Paso 0: congela el antiguo RPC
En primer lugar, congelamos el antiguo RPC para no disparar a un objetivo en movimiento. También incitó a las personas a cambiar a Courier, porque todas las nuevas funciones, como el rastreo, solo estaban disponibles en los servicios de Courier.
Paso 1: interfaz común para viejos RPC y Courier
Comenzamos definiendo una interfaz común para el antiguo RPC y Courier. Se suponía que nuestra generación de código aseguraría que ambas versiones de los apéndices correspondieran a esta interfaz:
type TestServer interface { UnaryUnary( ctx context.Context, req *test.TestRequest) ( *test.TestResponse, error) ... }
Paso 2: migra a la nueva interfaz
Después de eso, comenzamos a cambiar cada servicio a una nueva interfaz, mientras continuamos usando el antiguo RPC. A menudo, los cambios en el código fueron una gran diferencia, afectando a todos los métodos del servicio y sus clientes. Como esta etapa es la más problemática, queríamos eliminar completamente el riesgo cambiando solo una cosa a la vez.
Los servicios simples con una pequeña cantidad de métodos y el derecho a cometer errores se pueden migrar simultáneamente, sin prestar atención a nuestras advertencias.Paso 3: migrar clientes al RPC Courier
Durante el proceso de migración, comenzamos a lanzar simultáneamente servidores antiguos y nuevos en diferentes puertos de la misma máquina. El cambio de la implementación RPC del lado del cliente se realizó cambiando una línea:
class MyClient(object): def __init__(self): - self.client = LegacyRPCClient('myservice') + self.client = CourierRPCClient('myservice')
Tenga en cuenta que con este modelo, puede transferir un cliente a la vez, comenzando con aquellos con un nivel más bajo de SLA.
Paso 4: limpieza
, , RPC ( ). — .
Conclusiones
, Courier — RPC-, , Dropbox.
, Courier:
- — . .
- — , .
- , . Codegen.
- . , , . , : .
- RPC- — , . . .
Courier, gRPC , , , .
gRPC Python , C++ Python Rust . ALTS TLS- (, ).