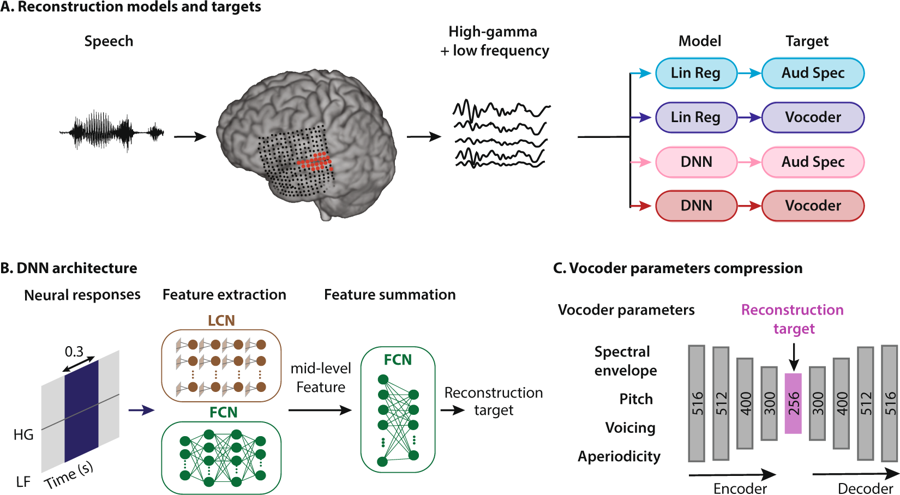
 Esquema del método de reconstrucción del habla. Una persona escucha palabras, como resultado, las neuronas de su corteza auditiva se activan. Los datos se interpretan de cuatro maneras: combinando dos tipos de modelos de regresión y dos tipos de representaciones del habla, luego ingresan al sistema de red neuronal para extraer características que posteriormente se utilizan para configurar los parámetros del vocoder
Esquema del método de reconstrucción del habla. Una persona escucha palabras, como resultado, las neuronas de su corteza auditiva se activan. Los datos se interpretan de cuatro maneras: combinando dos tipos de modelos de regresión y dos tipos de representaciones del habla, luego ingresan al sistema de red neuronal para extraer características que posteriormente se utilizan para configurar los parámetros del vocoderLos neuroingenieros de la Universidad de Columbia (EE. UU.) Fueron los primeros en el mundo en
crear un sistema que traduce los pensamientos humanos en un discurso comprensible y distinguible, aquí está la
grabación de sonido de palabras (mp3) sintetizadas por la actividad cerebral.
Al observar la actividad en la corteza auditiva, el sistema restaura las palabras que una persona escucha con una claridad sin precedentes. Por supuesto, esta no es la calificación de los pensamientos en el sentido literal de la palabra, pero se ha dado un paso importante en esta dirección. De hecho, patrones similares de actividad cerebral ocurren en la corteza cerebral cuando una persona imagina que está escuchando el habla, o cuando mentalmente habla palabras.
Este avance científico que utiliza tecnologías de inteligencia artificial nos acerca a la creación de interfaces neuronales efectivas que conectan la computadora directamente al cerebro. También ayudará a las personas que no pueden hablar y a quienes se recuperan de un derrame cerebral o por alguna otra razón que no pueden hablar palabras de manera temporal o constante para comunicarse.
Décadas de investigación han demostrado que, en el proceso de hablar o incluso de hablar mentalmente, aparecen patrones de actividad de control en el cerebro. Además, surge un patrón de señal distinto (y reconocible) cuando escuchamos a alguien o imaginamos que estamos escuchando. Los expertos han intentado durante mucho tiempo registrar y descifrar estos patrones para "liberar" los pensamientos de una persona del cráneo, y traducirlos automáticamente a forma oral.
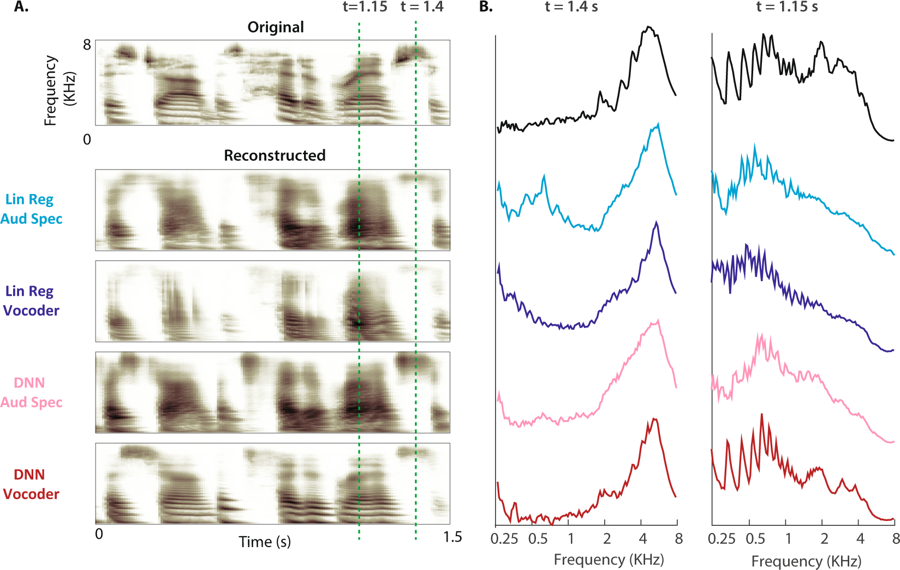 (A) El espectrograma original de una muestra de voz se muestra arriba. Los espectrogramas auditivos reconstruidos de los cuatro modelos se muestran a continuación. (B) La potencia de magnitud de las bandas de frecuencia durante voz sorda (t = 1.4 s) y voz (t = 1.15 s: el espacio se muestra mediante líneas discontinuas para el espectrograma original y cuatro reconstrucciones)
(A) El espectrograma original de una muestra de voz se muestra arriba. Los espectrogramas auditivos reconstruidos de los cuatro modelos se muestran a continuación. (B) La potencia de magnitud de las bandas de frecuencia durante voz sorda (t = 1.4 s) y voz (t = 1.15 s: el espacio se muestra mediante líneas discontinuas para el espectrograma original y cuatro reconstrucciones)"Esta es la misma tecnología que Amazon Echo y Apple Siri usan para responder verbalmente nuestras preguntas",
explica la Dra. Nima Mesgarani, autora principal del artículo. Para enseñar al vocoder a interpretar la actividad cerebral, los expertos encontraron cinco pacientes con epilepsia que ya se habían sometido a una cirugía cerebral. Se les pidió que escucharan oraciones hechas por diferentes personas, mientras que los electrodos midieron la actividad cerebral, que fue procesada por cuatro modelos. Estos patrones neuronales enseñaron vocoder. Luego, los investigadores pidieron a los mismos pacientes que escucharan cómo los hablantes pronuncian números del 0 al 9, registrando señales cerebrales que podrían pasar a través del vocoder. El sonido producido por el vocoder en respuesta a estas señales es analizado y borrado por varias redes neuronales.
Como resultado del procesamiento a la salida de la red neuronal, se recibió una voz de robot que pronunció una secuencia de números. Para probar la precisión del reconocimiento, se les dio a las personas escuchar sonidos sintetizados por su propia actividad cerebral: "Descubrimos que las personas pueden entender y repetir sonidos en el 75% de los casos, lo cual es mucho más alto y excede cualquier intento previo", dijo el Dr. Mesgarani.
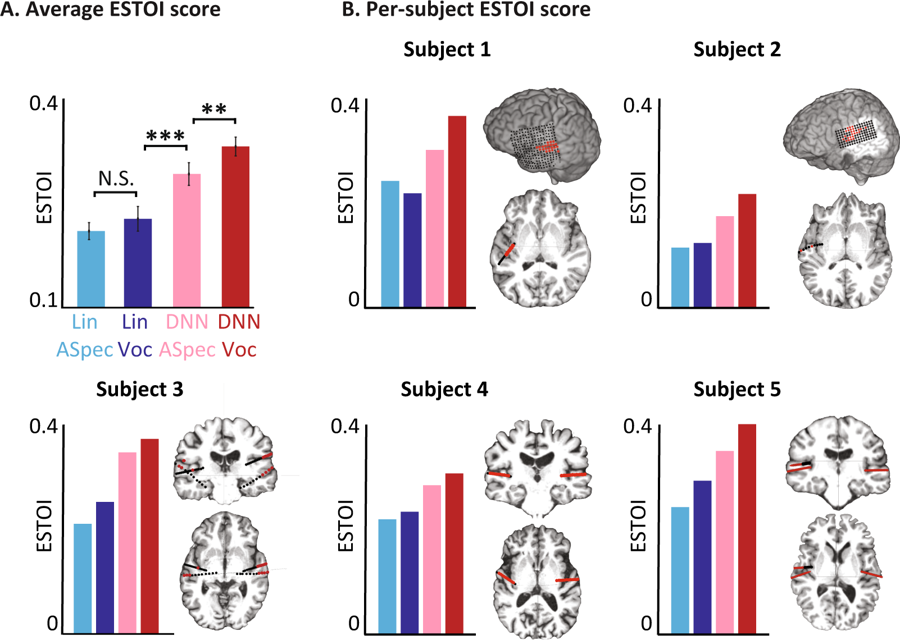 Calificaciones objetivas para diferentes modelos. (A) Puntaje promedio de ESTOI para todas las materias para los cuatro modelos. B) La cobertura y ubicación de los electrodos y el puntaje ESTOI para cada una de las cinco personas. Todos tienen una puntuación ESTOI más alta para el codificador de voz DNN que otros modelos.
Calificaciones objetivas para diferentes modelos. (A) Puntaje promedio de ESTOI para todas las materias para los cuatro modelos. B) La cobertura y ubicación de los electrodos y el puntaje ESTOI para cada una de las cinco personas. Todos tienen una puntuación ESTOI más alta para el codificador de voz DNN que otros modelos.Ahora los científicos planean repetir el experimento con palabras y oraciones más complejas. Además, se ejecutarán las mismas pruebas para detectar señales cerebrales cuando una persona se imagina lo que está diciendo. En última instancia, esperan que el sistema se convierta en parte del implante, lo que traduce los pensamientos del usuario directamente en palabras.
El artículo científico fue
publicado el 29 de enero de 2019 en el dominio público en la revista
Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
El código del programa para realizar un análisis fonémico, calcular amplitudes de alta frecuencia y reconstruir un espectrograma auditivo se ha puesto
a disposición del público .