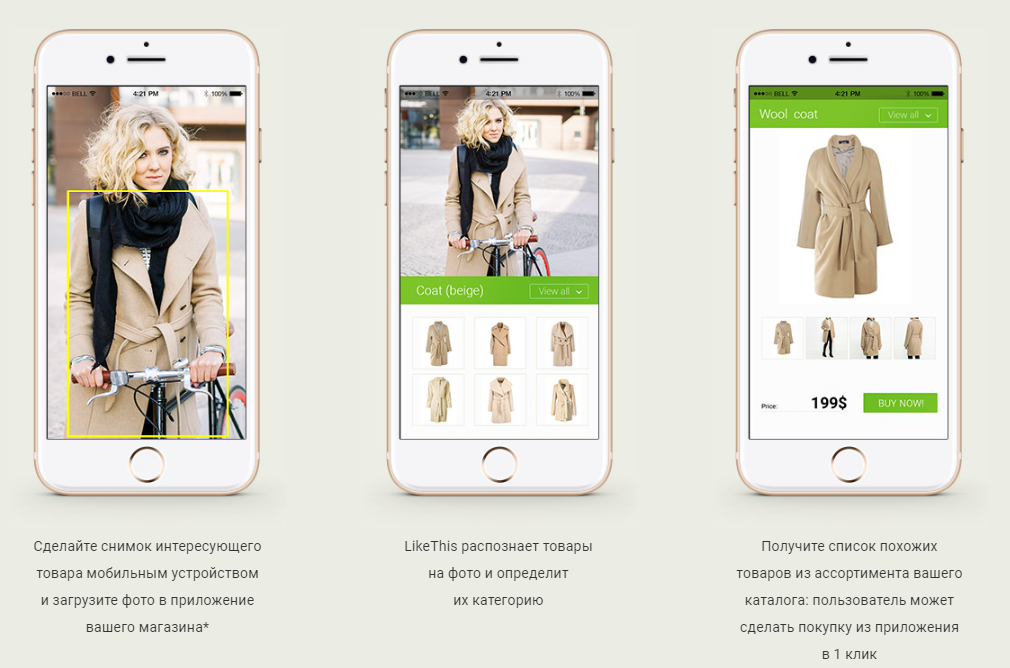
En este artículo quiero hablar sobre cómo creamos un sistema de búsqueda de ropa similar (más precisamente ropa, zapatos y bolsos) a partir de fotografías. Es decir, en términos comerciales, un servicio de recomendación basado en redes neuronales.
Como la mayoría de las soluciones de TI modernas, podemos comparar el desarrollo de nuestro sistema con el ensamblaje del constructor de Lego, cuando tomamos muchos pequeños detalles, instrucciones y creamos un modelo listo a partir de esto. Aquí hay una instrucción: qué detalles tomar y cómo aplicarlos para que su GPU pueda seleccionar productos similares de una fotografía, encontrará en este artículo.
De qué partes está construido nuestro sistema:
- detector y clasificador de ropa, zapatos y bolsos en imágenes;
- rastreador, indexador o módulo para trabajar con catálogos electrónicos de tiendas;
- módulo de búsqueda de imágenes similares;
- JSON-API para una interacción conveniente con cualquier dispositivo y servicio;
- interfaz web o aplicación móvil para ver los resultados.
Al final del artículo, se describirán todos los "rastrillos" que pisamos durante el desarrollo y recomendaciones sobre cómo neutralizarlos.
Declaración del problema y creación del rubricador.
La tarea y el caso de uso principal del sistema suena bastante simple y claro:
- el usuario envía a la entrada (por ejemplo, a través de una aplicación móvil) una fotografía en la que hay prendas de vestir y / o bolsos y / o zapatos;
- el sistema determina (detecta) todos estos objetos;
- encuentra para cada uno de ellos los productos más similares (relevantes) en tiendas reales en línea;
- le da al usuario productos con la capacidad de ir a una página de producto específica para su compra.
En pocas palabras, el objetivo de nuestro sistema es responder la famosa pregunta: "¿Y usted no tiene lo mismo, solo con botones de nácar?"
Antes de precipitarse en el grupo de codificación, marcado y capacitación de redes neuronales, debe determinar con bastante claridad las categorías que estarán dentro de su sistema, es decir, aquellas categorías que detectará la red neuronal. Es importante comprender que cuanto más amplia y detallada sea la lista de categorías, más universal es, ya que una gran cantidad de categorías pequeñas y estrechas, como mini vestido, midi-dress, maxi-dress siempre se pueden combinar con un toque en una categoría de tipo de vestido. PERO NO viceversa. En otras palabras, el rubricator debe estar bien pensado y compilado al comienzo del proyecto, para no volver a hacer el mismo trabajo 3 veces más tarde. Compilamos el rubricator, tomando como base varias tiendas grandes, como Lamoda.ru, Amazon.com, e intentamos hacerlo lo más ancho posible, por un lado, y lo más versátil posible, por otro lado, para facilitar la asociación de categorías de detectores con diferentes categorías en el futuro tiendas en línea (te contaré más sobre cómo hacer este grupo en la sección de rastreadores e indexadores). Aquí hay un ejemplo de lo que sucedió.
 Categorías de ejemplo
Categorías de ejemploNuestro catálogo actualmente tiene solo 205 categorías: ropa de mujer, ropa de hombre, zapatos de mujer, zapatos de hombre, bolsos, ropa para recién nacidos. La versión completa de nuestro clasificador está disponible
en el enlace .
Indexador o módulo para trabajar con catálogos electrónicos de tiendas.
Para buscar productos similares en el futuro, necesitamos crear una base extensa de lo que buscaremos. En nuestra experiencia, la calidad de la búsqueda de imágenes similares depende directamente del tamaño de la base de búsqueda, que debe exceder al menos 100K imágenes, y preferiblemente 1M imágenes. Si agrega 1-2 pequeñas tiendas en línea a la base de datos, lo más probable es que no obtenga resultados impresionantes simplemente porque en el 80% de los casos no hay nada realmente similar al artículo deseado en su catálogo.
Entonces, para crear una gran base de datos de imágenes que necesita para procesar catálogos de varias tiendas en línea, esto es lo que incluye este proceso:
- Primero, necesita encontrar las fuentes XML de las tiendas en línea, por lo general, puede encontrarlas disponibles gratuitamente en Internet, o solicitándolas en la propia tienda o en varios agregadores como Admitad;
- el feed es procesado (analizado) por un programa especial: un rastreador, que descarga todas las imágenes del feed, las coloca en el disco duro (más precisamente, en el almacenamiento de red al que está conectado su servidor), escribe toda la metainformación sobre los productos en la base de datos;
- luego se inicia otro proceso: el indexador, que calcula vectores de características binarias de 128 dimensiones para cada imagen. Puede combinar el rastreador y el indexador en un módulo o programa, pero históricamente hemos desarrollado que estos eran procesos diferentes. Esto se debió principalmente al hecho de que inicialmente calculamos descriptores (hashes) para cada imagen distribuida en una gran flota de máquinas, ya que este era un proceso muy intensivo en recursos. Si trabaja solo con redes neuronales, entonces la primera máquina con una GPU es suficiente para usted;
- los vectores binarios se escriben en la base de datos, todos los procesos se completan y listo, la base de datos de su producto está lista para una búsqueda adicional;
- pero aún queda un pequeño truco: dado que todas las tiendas tienen diferentes catálogos con diferentes categorías en el interior, entonces debe comparar las categorías de todos los feeds contenidos en su base de datos con las categorías del detector (más precisamente, el clasificador) de los productos, a esto le llamamos el proceso de mapeo. Esta es una rutina manual, pero un trabajo muy útil, durante el cual el operador, editando manualmente un archivo XML normal, compara las categorías de fuentes en la base de datos con las categorías del detector. Aquí está el resultado:
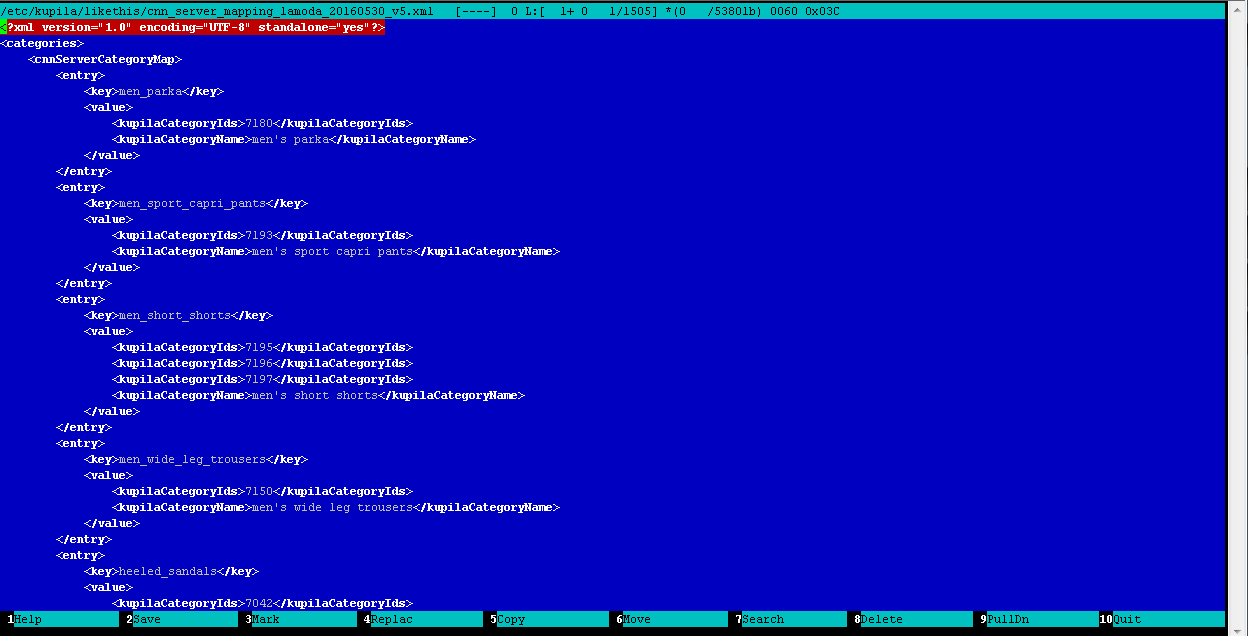 Ejemplo de archivo de mapeo de categoría: catalogador-clasificador
Ejemplo de archivo de mapeo de categoría: catalogador-clasificadorDetección y clasificación.
Para encontrar algo similar a lo que nuestro ojo encontró en la foto, primero debemos detectar este "algo" (es decir, localizar y seleccionar el objeto). Hemos recorrido un largo camino en la creación de un detector, comenzando por entrenar cascadas OpenCV que no funcionaron en absoluto para esta tarea, y terminando con tecnología moderna para detectar y clasificar
R-FCN y el clasificador basado en la red neuronal
ResNet .
Como los datos que se utilizaron para la capacitación y las pruebas (las llamadas muestras de capacitación y prueba), tomamos todo tipo de imágenes de Internet:
- buscar en imágenes de Google / Yandex;
- conjuntos de datos marcados por terceros;
- redes sociales;
- sitios de revistas de moda;
- Tiendas de ropa, zapatos, bolsos en internet.
El marcado se llevó a cabo utilizando una herramienta samopisny, el resultado del marcado fueron conjuntos de imágenes y archivos * .seg para ellos, que almacenan las coordenadas de los objetos y las etiquetas de clase para ellos. En promedio, de 100 a 200 imágenes fueron etiquetadas para cada categoría, el número total de imágenes en 205 clases fue de 65,000.
Después de que el entrenamiento y las muestras de prueba estén listas, realizamos una doble verificación del marcado, dando todas las imágenes a otro operador. Esto nos permitió filtrar una gran cantidad de errores que afectan fuertemente la calidad del entrenamiento de la red neuronal, es decir, el detector y el clasificador. Luego, comenzamos a entrenar la red neuronal utilizando herramientas estándar y "despegamos" la próxima instantánea de la red neuronal "en el calor del día" en unos pocos días. En promedio, el tiempo de entrenamiento del detector y clasificador en el volumen de datos de 65,000 imágenes en una GPU Titan X es de aproximadamente 3 días.
Una red neuronal prefabricada de alguna manera debe ser verificada por su calidad, es decir, para evaluar si la versión actual de la red se ha vuelto mejor que la anterior y en qué medida. Cómo lo hicimos
- la muestra de prueba consistió en 12,000 imágenes y se presentó exactamente de la misma manera que la capacitación;
- escribimos una pequeña herramienta que ejecutó toda la muestra de prueba a través del detector y compiló una tabla de este tipo (la versión completa de la tabla está disponible aquí );
- esta tabla se agrega a Excel en una nueva pestaña y se compara con la anterior manualmente o con las fórmulas integradas de Excel;
- en la salida obtenemos los indicadores generales del detector y clasificador TPR / FPR en todo el sistema en y para cada categoría por separado.
 Ejemplo de una tabla de informes sobre la calidad del detector y el clasificador.
Ejemplo de una tabla de informes sobre la calidad del detector y el clasificador.Módulo de búsqueda de imágenes similares
Después de detectar elementos de vestuario en la fotografía, iniciamos el motor de búsqueda de imágenes similares, así es como funciona:
- para todos los fragmentos de imagen recortados (bienes detectados), los vectores de características binarias de 128 bits de la red neuronal se calculan en forma y color (de dónde provienen, ver más abajo);
- los mismos vectores calculados anteriormente en la etapa de indexación para todas las imágenes de los bienes almacenados en la base de datos ya están cargados en la RAM de la computadora (ya que para buscar otros similares será necesario realizar una gran cantidad de búsquedas y comparaciones por pares, cargamos toda la base de datos inmediatamente en la memoria, lo que nos permitió aumentar la velocidad de búsqueda es decenas de veces, mientras que la base de aproximadamente 100 mil productos cabe en no más de 2-3 GB de RAM);
- los coeficientes de búsqueda para esta categoría provienen de la interfaz o de las propiedades codificadas, por ejemplo, en la categoría "vestido", buscamos más en color que en forma (por ejemplo, búsqueda de 8 a 2 formas de color), y en la categoría "zapatos de tacón alto" buscamos Color de forma 1 a 1, ya que tanto la forma como el color son igualmente importantes aquí;
- Además, los vectores para el cultivo (fragmentos) de la imagen de entrada se comparan en pares con la imagen de la base de datos, teniendo en cuenta los coeficientes (se compara la distancia de Hamming entre los vectores);
- Como resultado, se forma un conjunto de productos similares de la base de datos para cada fragmento de producto cortado, y se asigna un peso para cada producto (de acuerdo con una fórmula simple, teniendo en cuenta la normalización, de modo que todos los pesos estén en el rango de 0 a 1) para la posibilidad de enviar a la interfaz, así como para más clasificación
- Se muestra una variedad de productos similares en la interfaz a través de la API web-JSON.
Las redes neuronales para la formación de vectores de redes neuronales en forma y color se entrenan de la siguiente manera.
- Para entrenar la red neuronal en forma, tomamos todas las imágenes marcadas, recortamos los fragmentos de acuerdo con el marcado y los distribuimos en carpetas según la clase: es decir, todos los suéteres en una carpeta, todas las camisetas en otra y todos los zapatos de tacón alto en la tercera, etc. d. A continuación, entrenamos un clasificador ordinario basado en esta muestra. Por lo tanto, tipo de "explicar" a la red neuronal nuestra comprensión de la forma del objeto.
- Para entrenar la red neuronal en color, tomamos todas las imágenes marcadas, recortamos los fragmentos según el marcado y los distribuimos en carpetas según el color: es decir, colocamos todas las camisetas, zapatos, bolsos, etc. en la carpeta "verde". color verde (como resultado, cualquier objeto de color verde generalmente se acumula en una carpeta), en la carpeta "despojado" ponemos todas las cosas en una tira, y en la carpeta "rojo-blanco" todas las cosas rojas-blancas. Luego, entrenamos un clasificador separado para estas clases, como si "explicara" a la red neuronal su comprensión del color de una cosa.
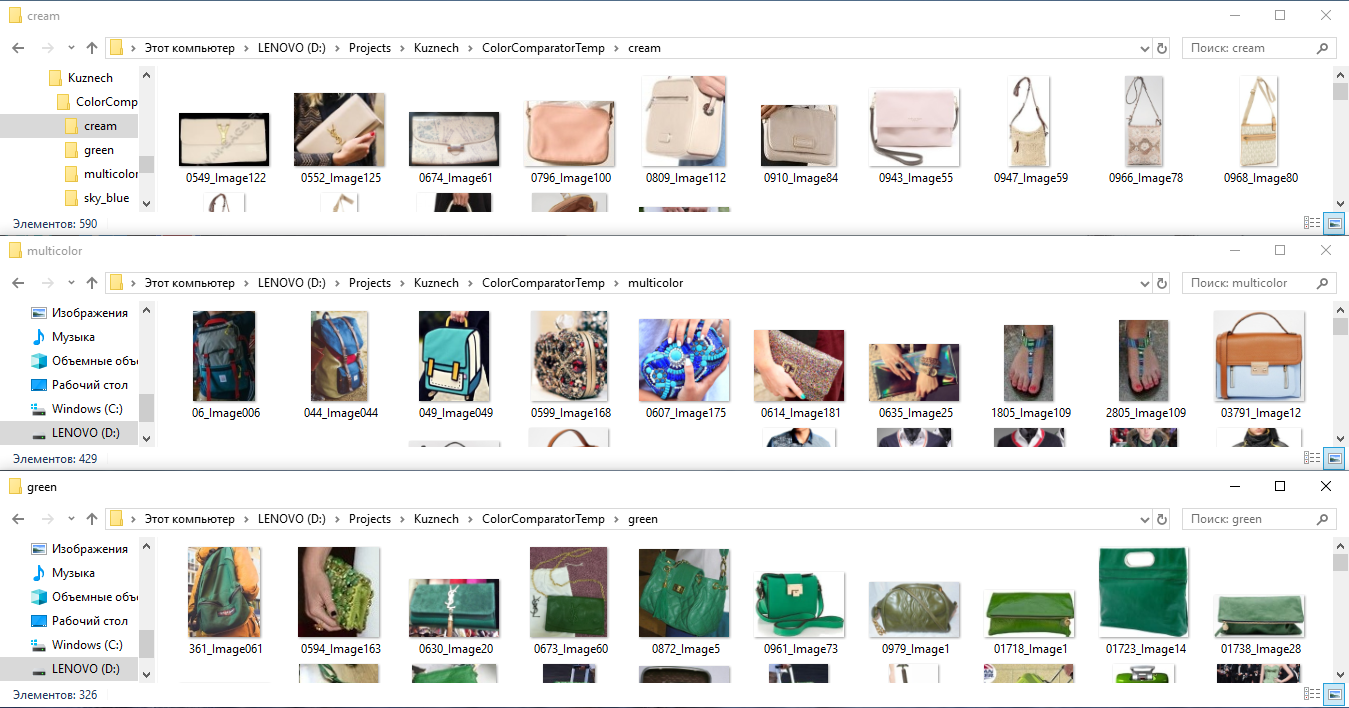 Un ejemplo de marcado de imágenes por color para obtener vectores de signos de redes neuronales por color.
Un ejemplo de marcado de imágenes por color para obtener vectores de signos de redes neuronales por color.Curiosamente, dicha tecnología funciona bien incluso en fondos complejos, es decir, cuando se cortan fragmentos de cosas no claramente a lo largo del contorno (máscara), sino a lo largo de un marco rectangular, que el marcador ha definido.
La búsqueda de otros similares se basa en la extracción de vectores de características binarias de la red neuronal de esta manera: la salida de la penúltima capa se toma, comprime, normaliza y binariza. En nuestro trabajo, nos comprimimos a un vector de 128 bits. Puede hacerlo de manera un poco diferente, por ejemplo, como se describe en el artículo de Yahoo "
Aprendizaje profundo de códigos de hash binarios para la recuperación rápida de imágenes ", pero la esencia de todos los algoritmos es casi la misma: se buscan imágenes similares a la imagen comparando las propiedades que opera la red neuronal dentro de las capas.
Inicialmente, como tecnología para buscar imágenes similares, utilizamos hash o descriptores de imágenes basados (calculados con mayor precisión) en ciertos algoritmos matemáticos, como el operador Sobel (o hash de contorno), el algoritmo SIFT (o puntos singulares), trazando un histograma o comparando el número de ángulos en una imagen . Esta tecnología funcionó y dio un resultado más o menos sensato, pero los hash no se comparan con la tecnología para buscar imágenes similares basadas en propiedades asignadas por una red neuronal. Si intenta explicar la diferencia en 2 palabras, entonces el algoritmo de comparación de imágenes basado en hash es una "calculadora" que está configurada para comparar imágenes usando alguna fórmula y funciona continuamente. Una comparación que usa características de una red neuronal es la "inteligencia artificial", entrenada por una persona para resolver un problema específico de cierta manera. Puede dar un ejemplo tan burdo: si busca suéteres hash en rayas blancas y negras, es probable que encuentre todas las cosas en blanco y negro como similares. Y si busca utilizando una red neuronal, entonces:
- en los primeros lugares encontrarás todos los suéteres con rayas blancas y negras,
- entonces todos los suéteres blancos y negros
- y luego todos los suéteres a rayas.
JSON-API para una interacción conveniente con cualquier dispositivo y servicio
Hemos creado una WEB-JSON-API simple y conveniente para comunicar nuestro sistema con cualquier dispositivo y sistema, lo que, por supuesto, no es ninguna innovación, sino un buen estándar de desarrollo sólido.
Interfaz web o aplicación móvil para ver resultados
Para verificar visualmente los resultados, así como para demostrar el sistema a los clientes, hemos desarrollado interfaces simples:
Errores cometidos en el proyecto.
- Inicialmente, es necesario definir más claramente la tarea, y es, según la tarea, seleccionar fotografías para el diseño. Si necesita buscar fotos UGC (Contenido generado por el usuario), este es un caso y ejemplos de diseño. Si necesita una búsqueda de fotos de revistas brillantes, este es un caso diferente, y si necesita una búsqueda de fotos donde se encuentra un objeto grande sobre un fondo blanco, esta es una historia separada y una muestra completamente diferente. Lo mezclamos todo en una pila, lo que afectó la calidad del detector y el clasificador.
- En las fotografías, siempre debe marcar TODOS los objetos, al menos por el hecho de que al menos de alguna manera se adapte a su tarea, por ejemplo, al elegir una selección de vestuario similar, debe marcar inmediatamente todos los accesorios (cuentas, anteojos, pulseras, etc.), cabeza sombreros, etc. Porque ahora que tenemos un gran conjunto de entrenamiento, para agregar otra categoría necesitamos redistribuir TODAS las fotos, y este es un trabajo muy voluminoso.
- Lo más probable es que la detección se realice con una red de máscara, la transición a Mask-CNN y una solución moderna basada en Detectron es una de las áreas del desarrollo del sistema.
- Sería bueno decidir de inmediato cómo va a determinar la calidad de la selección de imágenes similares: existen 2 métodos: "a simple vista" y este es el método más simple y económico y el segundo método "científico", cuando recopila datos de "expertos" (personas, (estoy probando su algoritmo de búsqueda similar) y, en base a estos datos, forme una muestra de prueba y un catálogo específicamente para buscar imágenes similares. Este método es bueno en teoría y parece bastante convincente (para usted y para los clientes), pero en la práctica su implementación es difícil y bastante costosa.
Conclusión y nuevos planes de desarrollo.
Esta tecnología está bastante lista y adecuada para su uso, ahora opera en uno de nuestros clientes en la tienda en línea como un servicio de recomendación. Además, recientemente, comenzamos a desarrollar un sistema similar en otra industria (es decir, ahora estamos trabajando con otros tipos de productos).
Desde planes inmediatos: transferir la red a Mask-CNN, así como volver a marcar y volver a marcar imágenes para mejorar la calidad del detector y el clasificador.
En conclusión, quiero decir que de acuerdo con nuestros sentimientos, dicha tecnología y, en general, las redes neuronales son capaces de resolver hasta el 80% de las tareas complejas y altamente intelectuales que nuestro cerebro cumple a diario. ¡La única pregunta es quién es el primero en implementar dicha tecnología y descargar a una persona del trabajo de rutina, liberando espacio para la creatividad y el desarrollo, que es, en nuestra opinión, el propósito más importante del hombre!
Referencias