
Buen dia
En la práctica real, a menudo encuentra tareas que están lejos de ser complejos algoritmos de ML, pero al mismo tiempo no son menos importantes y urgentes para el negocio.
Hablemos de uno de ellos.
La tarea se reduce a distribuir (aserrar, rasplitovat - la jerga del negocio es inagotable) los datos de alguna tabla objetivo con agregados (valores agregados) en una tabla de granularidad más detallada.
Por ejemplo, el departamento comercial necesita desglosar el plan anual acordado a nivel de marca, en detalle, para los productos, para que los especialistas en marketing desglosen el presupuesto anual de comercialización por país, el departamento de planificación y económico para desglosar los gastos comerciales generales por centros de responsabilidad financiera, etc. etc.
Si siente que tareas como esta ya se avecinan frente a usted en el horizonte o ya están tratando a aquellos que han sufrido tales tareas, entonces le pido un gato.
Considere un ejemplo real:
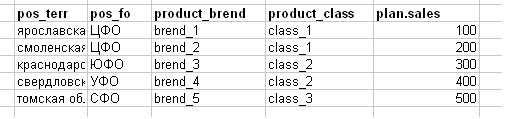
Bajan el plan de ventas como una tarea como en la imagen de abajo (intencionalmente simplifiqué el ejemplo, en realidad: un banner de Excel de 100-200 mb).
Explicación del encabezado:
- pos_terr-territorio (región) de la salida
- pos_fo: el distrito federal de la tienda (por ejemplo, el Distrito Federal Central-Distrito Federal Central)
- product_brend - marca del producto
- clase_producto - clase de producto
- plan.sales es un plan de ventas para cualquier cosa.
Y piden, por ejemplo, romper su mega-mesa (en el marco del ejemplo de nuestros hijos, por supuesto, es más modesto) - al canal de ventas. A la pregunta, de acuerdo con qué lógica dividir, obtengo la respuesta: "pero tome las estadísticas de ventas reales para el cuarto trimestre de tal año, obtenga las cuotas reales de canales en% para cada línea del plan y desglose estas partes de la línea del plan".
De hecho, esta es la respuesta más frecuente en tales tareas ...
Hasta ahora, todo parece bastante simple.
Me da este hecho (ver la imagen a continuación):
- pos_channell - canal de ventas (atributo objetivo para el plan)
- fact.sales: ventas reales de algo.
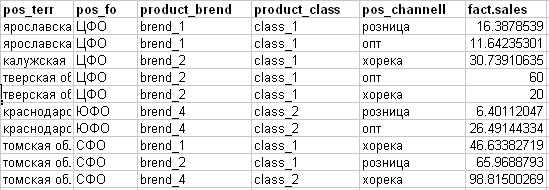
Basado en el enfoque obtenido para "aserrar" en el ejemplo de la primera línea del plan, lo desglosaremos en base al hecho de algo como esto:

Sin embargo, si comparamos el hecho con el plan para toda la placa con el fin de comprender si todas las líneas del plan se pueden "cortar" adecuadamente en acciones, obtenemos la siguiente imagen: (verde: todos los atributos de la línea del plan coincidieron con el hecho, las celdas amarillas no coincidían).
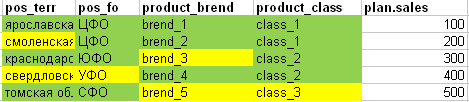
- En la primera línea del plan, todos los campos se encuentran completamente en el hecho.
- En la segunda línea del plan, el territorio correspondiente no se encontró en el hecho
- La tercera línea del plan no es suficiente en el hecho de que la marca
- La cuarta línea del plan no es suficiente en el hecho del territorio y el distrito federal.
- La quinta línea del plan carece de hecho de la marca y la clase.
Como dijo Panikovsky: "Vio la Shura, vio: son de oro ..."

Voy al cliente comercial y aclaro sobre el ejemplo de la segunda línea, ¿qué tipo de enfoque ve para tales situaciones?
Recibo la respuesta: "para los casos en que no es posible calcular la proporción de canales para la marca No. 2 en la región de Smolensk (teniendo en cuenta el hecho de que tenemos la región de Smolensk en el Distrito Federal Central-Distrito Federal Central), ¡entonces rompa esta línea de acuerdo con la estructura de canales dentro de todo el Distrito Federal Central!"
Es decir, para {región de Smolensk + marca_2} agregamos el hecho a nivel del Distrito Federal Central y dividimos la región de Smolensk de la siguiente manera:

Volviendo y digiriendo lo que escuché, trato de generalizar a una heurística más universal:
Si no hay datos en el nivel de detalle actual de la tabla de hechos, entonces antes de calcular los recursos compartidos para el campo objetivo (canal de ventas), agregamos la tabla de hechos al atributo de jerarquía anterior.
Es decir, si no fuera por el territorio, entonces agregamos el hecho a un nivel jerárquico más alto: acciones para el mismo Distrito Federal Central que en el plan. Si no fuera por la marca, entonces en la jerarquía anterior hay una clase de producto; en consecuencia, contamos las acciones de la misma clase, etc.
Es decir combinamos el plan y el hecho en los campos de acoplamiento para los cuales consideramos las partes en el hecho y en cada iteración de acuerdo con el plan no distribuido restante, reducimos sucesivamente la composición de los campos de acoplamiento.
Un cierto patrón de distribución de datos ya se avecina aquí:
- De hecho, distribuimos el plan en función de la coincidencia completa de los campos correspondientes.
- Obtenemos un plan roto (lo acumulamos en el resultado intermedio) y un plan continuo (no todas las líneas coinciden)
- Tomamos un plan ininterrumpido y lo dividimos de hecho a un nivel jerárquico más alto (es decir, abandonamos un cierto campo de acoplamiento de estas 2 tablas y agregamos el hecho sin este campo para calcular las acciones)
- Obtenemos un plan roto (lo agregamos al resultado intermedio) y un plan continuo (no todas las líneas coinciden)
- Y repetimos los mismos pasos hasta que no haya un plan "sin resolver".
En general, nadie nos obliga a eliminar consistentemente los campos de enganche solo dentro de la jerarquía. Por ejemplo, ya hemos eliminado la marca y el territorio de los campos de enganche y distribuimos el plan restante por: product_class (jerarquía sobre la marca) + Fed.krug (jerarquía sobre el territorio). Y todavía tengo un saldo no asignado del plan.
Además, podemos eliminar de los campos de acoplamiento la clase de producto o el distrito federal, como ya no están incrustados en la jerarquía del otro.
Teniendo en cuenta que hay docenas y filas de campos en tales tablas, hasta un millón haciendo tales manipulaciones con las manos, la tarea no es la más agradable.
Y dado que las tareas de este tipo me llegan regularmente al final de cada año (aprobando los presupuestos para el próximo año en la junta directiva), tuvo que traducir este proceso en algún tipo de plantilla universal flexible.
Y como la mayoría de las veces trabajo con datos a través de R, la implementación es, por consiguiente, la misma.
Primero, necesitamos escribir una función mágica universal que tome una tabla base (basetab) con datos para un desglose (en nuestro ejemplo, un plan) y una tabla para calcular acciones (sharetab) en base a la cual "veremos" los datos (en nuestro ejemplo, hecho). Pero la función también debe comprender lo que se debe hacer con estos objetos, por lo que la función también aceptará el vector de los nombres de los campos de acoplamiento (merge.vrs), es decir, aquellos campos que tienen nombres idénticos en ambas tablas y nos permitirán conectar una tabla a la otra con estos campos donde funciona (es decir, unión correcta). Además, la función debe comprender qué columna de la tabla base debe tomarse en la distribución (basetab.value) y en función de qué campo contar los recursos compartidos (sharetab.value). Bueno, y lo más importante: qué tomar para el campo resultante (sharetab.targetvars), en nuestro caso, queremos detallar el plan a través del canal de ventas.
Por cierto, esta variable sharetab.targetvars no es aleatoria en mi plural: puede que no sea un campo sino un vector de nombres de campo, para los casos en que necesite agregar no un campo a la tabla base desde la tabla compartida sino varios a la vez (por ejemplo, en función del hecho, no puede dividir el plan solo a través del canal de ventas, pero también por el nombre de los productos incluidos en la marca).
Sí, y una condición más :) mi función debe ser lo más local y legible posible, sin ningún edificio de varios pisos en 2 pantallas (realmente no me gustan las funciones grandes).
En la última condición, el popular paquete dplyr encaja lo más cómodamente posible, y teniendo en cuenta que sus operadores de tuberías deben comprender los nombres textuales de los campos que se han reducido a la función, no podría funcionar sin la
evaluación Standart .
Aquí está este bebé (sin contar los comentarios internos):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
En la salida, la función debe devolver data.frame de la unión de dos tablas con esas líneas del plan + hecho donde fue posible dividir el plan en la versión actual de los campos de acoplamiento, y con las líneas originales del plan (y el hecho vacío) en las líneas donde el plan no se pudo dividir en la iteración actual.
Es decir, el resultado devuelto por la función después de la primera iteración (rompiendo la primera línea del plan para la región de Yaroslavl) se verá así:
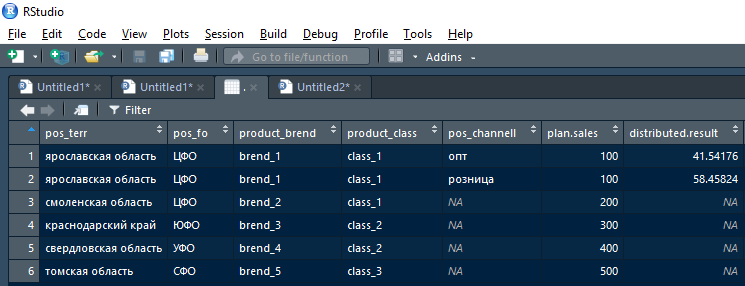
Además, este resultado puede tomarse por un resultado distribuido no vacío en el resultado acumulativo y por un resultado distribuido vacío (NA): enviar a la siguiente iteración típica, pero desglosado por acciones en un nivel jerárquico superior.
Todo el encanto y la conveniencia es que el trabajo se realiza en el mismo tipo de bloques y una función universal, todo lo que se necesita en cada paso (iteración) es corregir el vector merge.vrs y observar cómo la magia hace todo este trabajo tedioso para usted:

Sí, casi olvido un pequeño matiz: si algo sale mal y al final obtenemos un plan roto que en total no será igual al plan antes del desglose, será difícil rastrear en qué iteración todo salió mal.
Por lo tanto, suministramos cada iteración con una suma de verificación:
(_)-(___ )-(___.)=0
Ahora intentemos ejecutar nuestro ejemplo a través de la plantilla de distribución y ver qué obtenemos en la salida.
Primero, obtenga los datos de origen:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. Distribuimos por Terr, FD (distrito federal), marca, clase merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. Distribuimos por pho, marca, clase (es decir, abandonamos el territorio de hecho)
2. Distribuimos por pho, marca, clase (es decir, abandonamos el territorio de hecho)La única diferencia con respecto al primer bloque es que acortaron ligeramente merge.fields al eliminar pos_terr en él
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. Distribuir por pho, clase merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. Distribuir por clase merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. Distribuir por FD
5. Distribuir por FD merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
Como puede ver, no queda ningún plan "no aserrado" y la aritmética del plan distribuido es igual al original.

Y aquí está el resultado con los canales de ventas (en la columna de la derecha, se muestra la función: por qué campos se activó el acoplamiento / agregación para que luego podamos entender de dónde proviene esta distribución)

Eso es todo El artículo no era muy pequeño, pero hay más texto explicativo que el código en sí.
Espero que este enfoque flexible ahorre tiempo y nervios no solo para mí :-)
Gracias por su atencion