Los servicios deben escribirse de modo que siempre se mantenga una funcionalidad mínima, incluso si fallan los componentes críticos. Ilya Sidorov, jefe de uno de los equipos de desarrollo de productos del backend Yandex.Taxi, explicó en su informe cómo permitimos que el usuario ordene un automóvil cuando ciertas partes del sistema no funcionan, y con qué lógica activamos las versiones simplificadas del servicio.
Es importante escribir no solo servicios que funcionan bien, sino también servicios que funcionan bien.
"Estoy muy contento de verlos a todos". Hoy hablaré sobre la degradación graciosa. Si lo busca en Yandex, lo más probable es que aprenda a hacer que su sitio funcione sin JS. Te contaré un poco sobre otra cosa. Sobre la degradación elegante en relación con el backend.

Comencemos con la definición. ¿Cómo se ve en realidad?
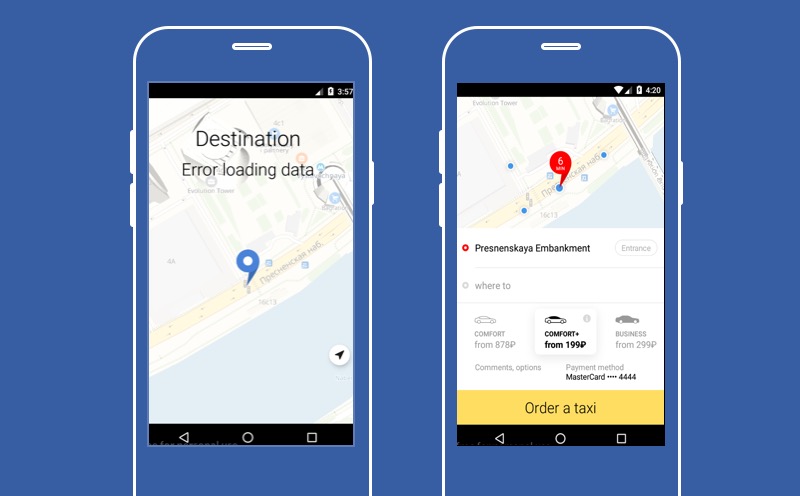
Aquí es donde se presenta nuestra aplicación Yandex.Taxi en caso de que uno de los servicios no funcione: el servicio para elegir el destino donde el conductor debe llevarlo. Como puede ver, en esta pantalla no hay un botón grande "Pedir un taxi", lo que significa que el usuario no podrá utilizar el servicio. Pero puede intentar degradar y permitir que el usuario no elija el punto B.
Entonces no podrá averiguar el precio exacto del viaje, no podremos construir una ruta, pero el usuario tendrá el botón "Pedir un taxi" y podrá utilizar nuestro servicio. La función principal de nuestra aplicación estará disponible. De eso es de lo que quiero hablar hoy. Sobre cómo degradarse adecuadamente y qué se puede hacer con un servicio que no funciona.
Plan de desempeño. Te diré cómo degradar qué hacer con el servicio. Puede desactivarlo y también usar un comportamiento diferente. Luego te diré cómo entender cuándo es el momento de desactivar nuestro servicio. Y al final hablaré sobre algunos matices que tuvimos que enfrentar cuando creamos un sistema de degradación automática para Yandex.Taxi.
¿Qué se puede hacer con un servicio que no funciona? Puede desactivar la funcionalidad. Si el servicio para predecir destinos individuales no funciona, entonces desactive este servicio. Si el chat entre el conductor y el pasajero no funciona, entonces apaga el chat. Si no puede pedir un automóvil, apague el botón "Solicitar un automóvil". Oh, no, eso no funciona. No todas las funciones se pueden desactivar. Y si no puede apagar algo, entonces necesita usar un enfoque diferente. Por ejemplo, puede intentar hacer un diseño o una funcionalidad simplificada. Llamamos a un comportamiento tan simplificado en Yandex una calabaza: decimos que el servicio se ha convertido en una calabaza.
Consideremos estas soluciones con más detalle.
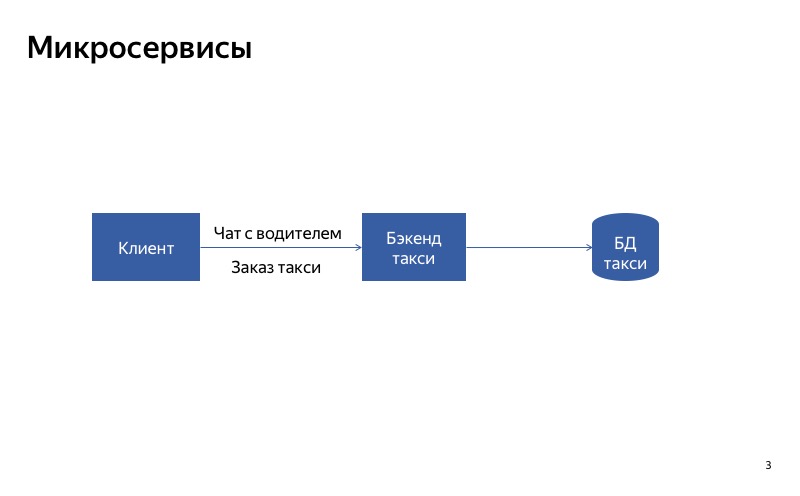
¿Cómo deshabilitar los servicios? Probablemente puedas hacer la arquitectura correcta. Supongamos que tenemos un servicio monolítico. Si una de sus partes falla, entonces se rompe todo el servicio. Pero si dividimos el servicio en partes para que los clientes utilicen diferentes servicios para diferentes solicitudes, será mucho mejor.
¿Cómo funcionará esto en un ejemplo? Hay un servicio Yandex.Taxi, en el que hay dos funciones principales: pedir un taxi y conversar con el conductor. Mientras tengamos un backend monolítico, si falla el chat con el conductor, la funcionalidad básica de pedir un taxi se verá afectada.
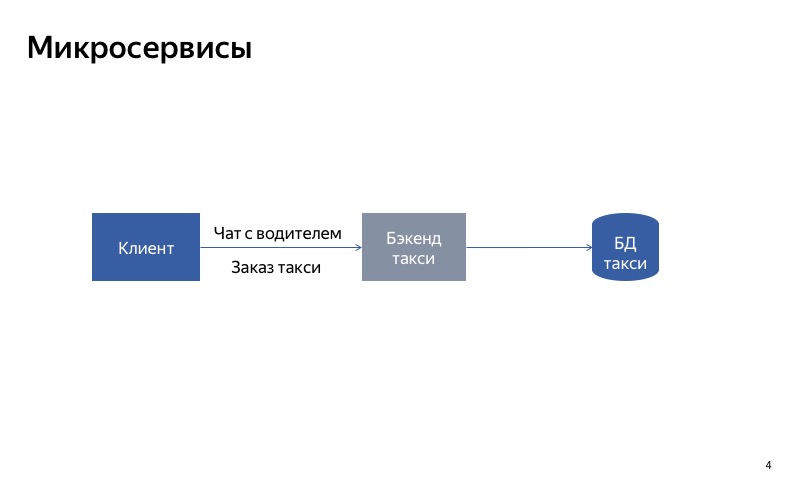
¿Qué puedes intentar hacer? Divide el servicio monolítico en dos partes. Una parte será responsable de ordenar un taxi y la otra, de comunicarse con el conductor.
Ahora todo se ve mucho mejor. Si el chat con el conductor se interrumpe, todo lo demás continúa funcionando correctamente.
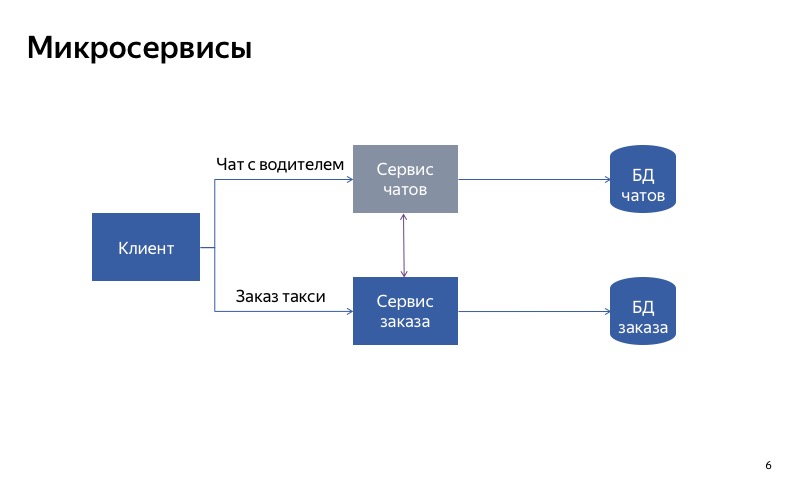
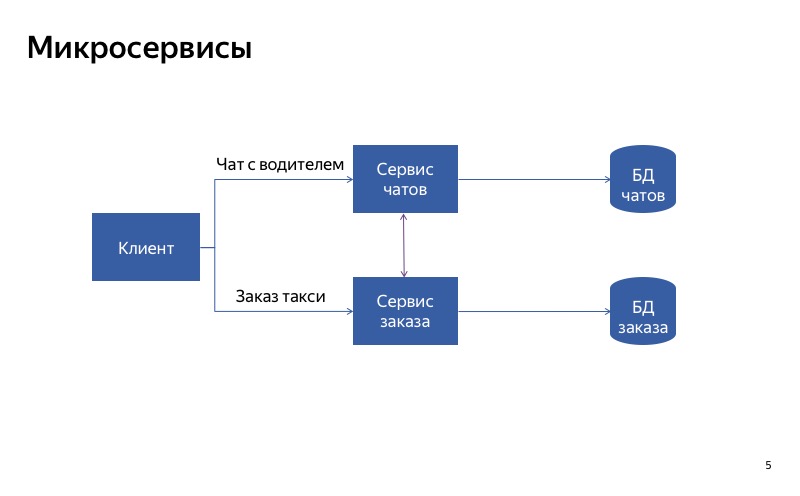
Como puede ver, el cliente utiliza diferentes API, diferentes solicitudes para realizar un pedido y comunicarse con el controlador.
Pero, de hecho, parece que ahora no todo es tan bueno, porque hay una conexión espuria entre el servicio de chat y el servicio de pedidos. Y puede resultar que el servicio de pedidos utiliza un servicio de chat inactivo. En este caso, la funcionalidad principal no funcionará.
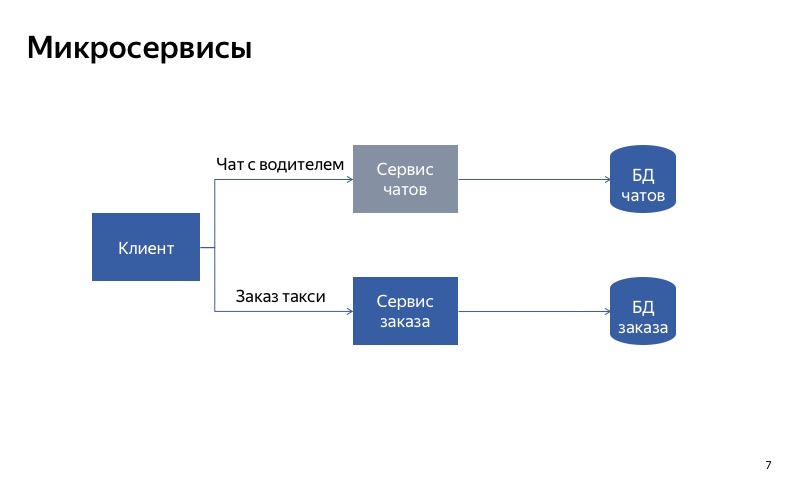
Y en este caso, todo es mucho mejor. La comunicación espuria ha desaparecido, y ahora nuestros servicios son verdaderamente independientes entre sí. Entonces, si el servicio de chat falla, aún puede tomar un taxi.
La conclusión de esto es la siguiente: si desea degradarse utilizando la separación de servicios, es muy importante hacer que los servicios sean independientes entre sí. Esto significa que deben tener diferentes puntos de entrada, diferentes puntos finales. Deben tener diferentes tiempos de ejecución. Y, por supuesto, deben usar diferentes bases de datos. De lo contrario, un servicio roto puede romper todos los demás servicios a lo largo de la cadena.
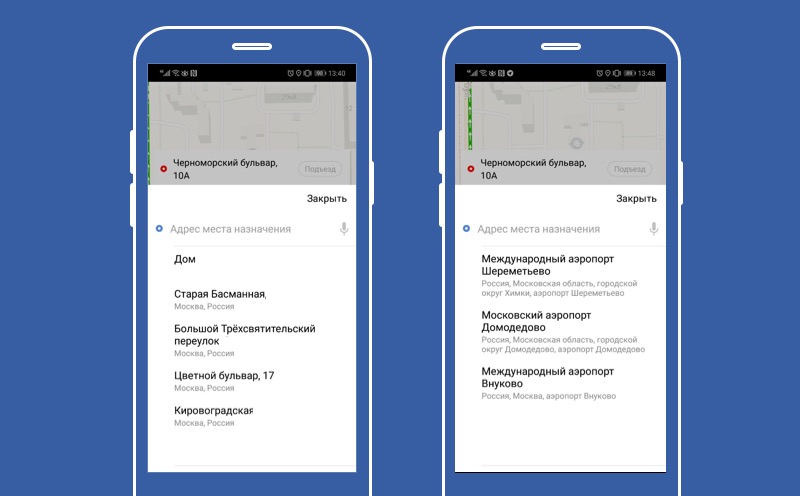
Bueno, hemos descubierto cómo deshabilitar la funcionalidad. Veamos ahora cómo hacer la funcionalidad predeterminada, cómo hacer calabaza. En esta pantalla, nuestro servicio de predicción de destinos. El servicio utiliza inteligencia artificial inteligente para predecir al usuario los mejores destinos para él en este momento. Y si la IA está cansada, entonces usamos el comportamiento predeterminado y le ofrecemos al usuario que abandone Moscú.
Veamos cómo funciona esto en la práctica.

Tenemos un cliente, se contacta con el servicio de destino y recibe un error.
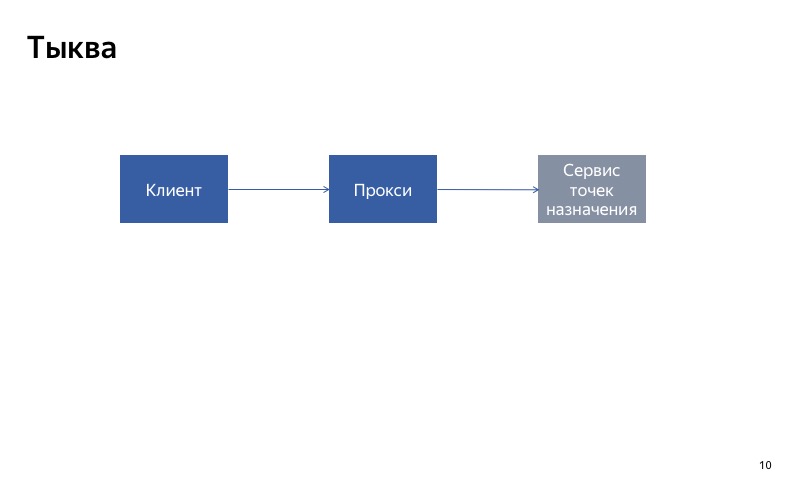
Ahora dos situaciones son posibles. La primera situación, si la falla fue única, es solo una solicitud fallida. En este caso, simplemente arrojamos un error al cliente, él hará una nueva solicitud y obtendrá sus destinos favoritos.
Pero si la falla es masiva, encendemos la calabaza y el usuario obtiene el comportamiento predeterminado.

Pero este comportamiento de piel dura es mucho más fácil de implementar, y esta calabaza es muy confiable, por lo que nos permite trabajar incluso cuando falla la IA. Si sabemos que los usuarios a menudo viajan a los aeropuertos, no notaremos un deterioro significativo en la vida de los usuarios.
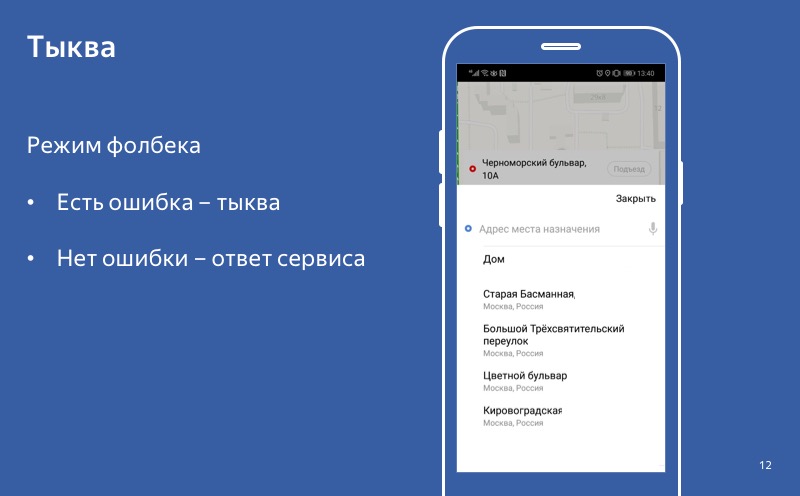
Incluso si el modo de degradación está activado, la calabaza está activada, pero el usuario se pone en contacto con el servicio y recibe una respuesta exitosa, entonces usamos esta respuesta, no la calabaza. Y este comportamiento - cuando en el caso de una respuesta lo usamos, y en caso de error usamos una calabaza - llamamos el modo de reserva.
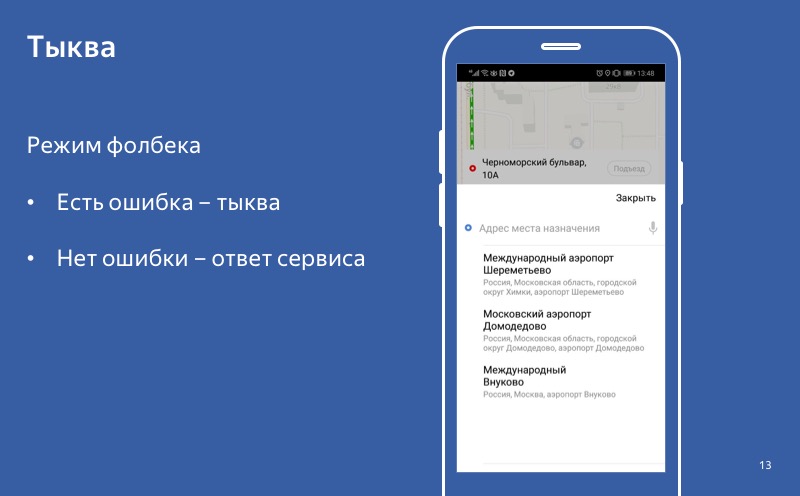
Sin error: una respuesta exitosa. Hay un error: una calabaza. Decimos que el retroceso se ha activado.
Resolví lo que se puede hacer con un servicio que no funciona. Puedes apagarlo, o puedes encender la calabaza. Pasemos ahora a la segunda parte y veamos cómo diagnosticar.
Tenemos dos grandes preguntas que deben responderse. La primera es cuando necesita apagar el servicio y encender la calabaza. El segundo es cuando necesita apagar la calabaza y volver a activar el servicio. Antes de que podamos responder a estas preguntas, necesitamos aclarar un punto.
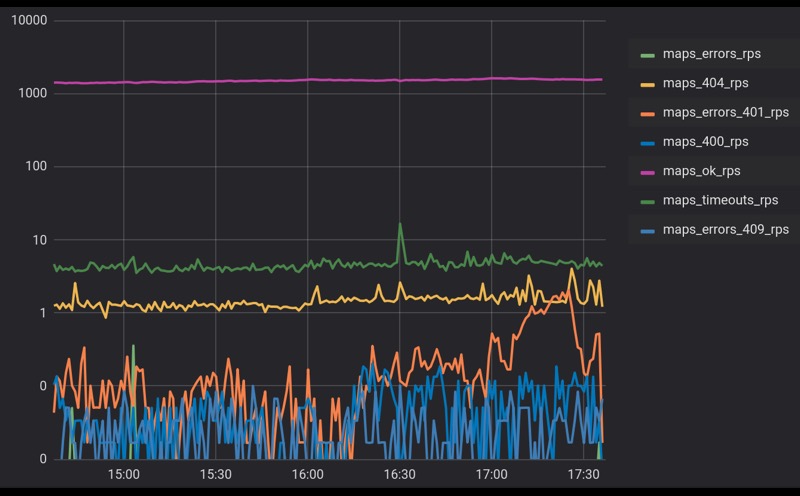
En cualquier sistema complejo que interactúa con una gran cantidad de agentes, siempre hay algunos antecedentes de errores. En esta diapositiva vemos un horario real de llamadas a uno de nuestros servicios. Llegan varios miles de RPS, obtenemos un poco menos del 1% de los errores. Aquí está la escala logarítmica.
Los errores pueden ser causados por varias cosas. Quizás este sea algún tipo de proceso interno, actualizar algún tipo de base de datos o simplemente procesos en segundo plano. Tal vez los clientes respondan a las solicitudes incorrectas, pero el hecho es que siempre tendremos antecedentes de errores. Tomémoslo y sigamos adelante.
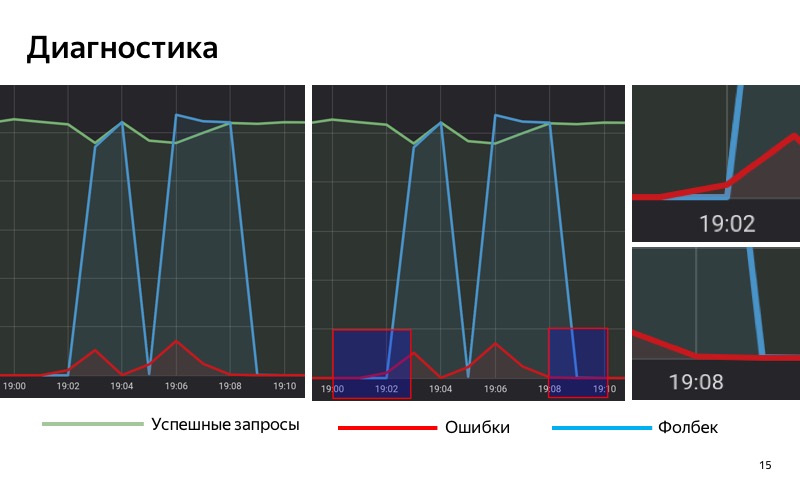
Entonces, utilizamos la solución basada en estadísticas. Tenemos una base de datos especial en la que guardamos estadísticas, guardamos la cantidad de consultas exitosas, la cantidad de consultas con errores y las consultas para las cuales se incluyó la reserva. Tomamos y acumulamos estadísticas sobre nuestro servicio durante un período de tiempo con una ventana deslizante. Cuando la proporción de solicitudes con errores en esta ventana deslizante supera un cierto umbral, habilitamos la recuperación. Y cuando el número de errores se vuelve menor que el umbral, lo apagamos.
Presta atención a las áreas seleccionadas. A las 19:01 comenzaron a aparecer los primeros errores, pero hasta ahora su participación es bastante pequeña, y hasta las 19:02 no incluimos la reserva. A las 19:02 se superó el umbral, activamos la reserva. A las 19:08 el proceso inverso: los errores terminaron, pero durante algún tiempo hemos activado el retroceso, porque el umbral todavía se supera en nuestra ventana deslizante. A las 19:09 apagamos la reserva.
Descubrimos cuándo apagar el servicio. Es necesario responder a la segunda pregunta: cuándo encenderlo. Es simple: utilizamos la misma solución basada en estadísticas.
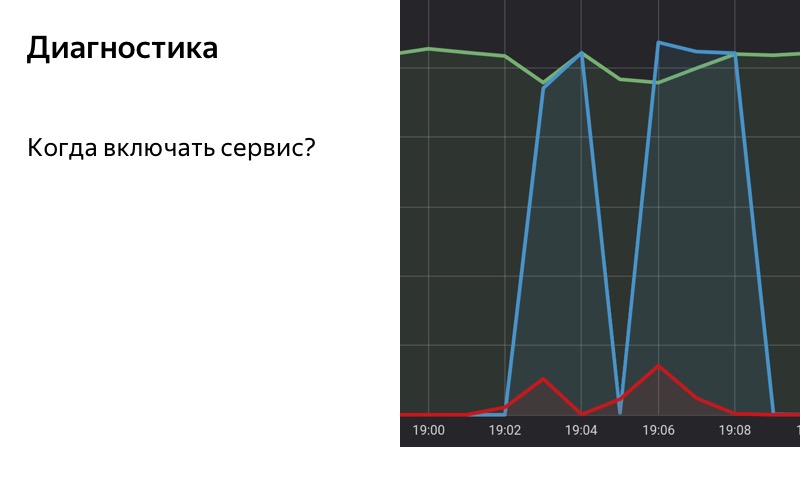
Es importante que no eliminemos la carga del servicio, incluso si activamos el modo de degradación. Esto es lo que nos permite continuar recibiendo estadísticas incluso si le mostramos al usuario una calabaza. Por lo tanto, podemos determinar que los errores han terminado, el servicio está reparado. Por lo tanto, puede volver a activarlo por completo.
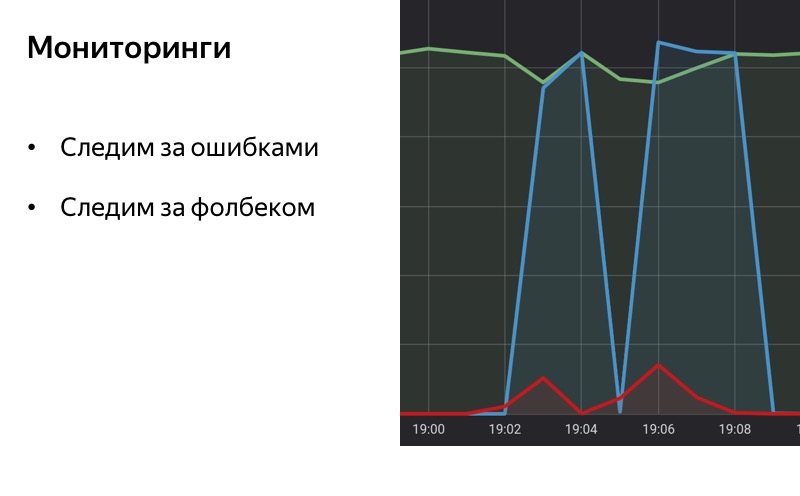
Cuando hablamos de degradación, no podemos decir sobre monitoreo. Un buen monitoreo es la mitad del éxito, la mitad del camino hacia el apagado automático o la degradación automática. Es importante que comprendamos qué tipo de problemas suceden con nuestro servicio, cuál puede ser la naturaleza de los errores y con qué frecuencia ocurren. Y quizás en la primera etapa ni siquiera necesitamos un interruptor automático. Simplemente, si la luz de monitoreo se enciende, podemos activar y desactivar el servicio manualmente. Cuando se apaga la lámpara de monitoreo, activamos el servicio.
Si hacemos una degradación automática, un cambio automático, entonces es importante hacer un monitoreo en el propio repliegue. Si el sistema de degradación funciona lo suficientemente bien, entonces los usuarios, de hecho, pueden no darse cuenta de que algo se ha roto en nosotros. Nosotros mismos podemos, si no hay monitoreo, no notarlo. Es importante monitorear el retroceso, es importante entender cuándo está encendido, cuándo está apagado, para que las estadísticas estén disponibles y podamos entender cuánto tiempo la funcionalidad no funciona, si nuestro backend empeora o mejora con el tiempo, dependiendo de cuánto tiempo pensemos en el retroceso .
Todo está con la parte principal.
Al final, me gustaría contarles algunos matices que tuvimos que enfrentar cuando estábamos desarrollando un sistema de degradación automática en Yandex.Taxi.
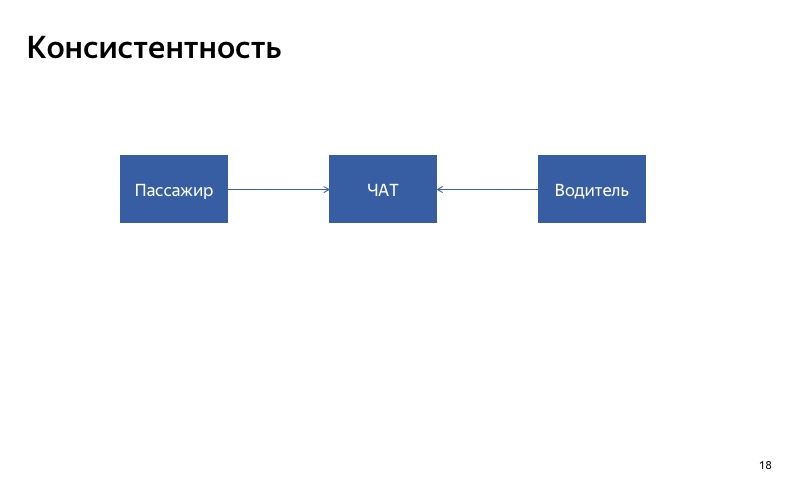
Lo primero a lo que debe prestar atención es la consistencia. Si está realizando una degradación automática para un determinado servicio, es importante que el servicio responda de manera consistente a todos sus clientes. Si tiene dos clientes que usan el servicio, es importante que las respuestas para estos dos clientes en caso de degradación sean consistentes. Y si tiene un servicio que está involucrado en algún proceso prolongado, debe comprender: tal vez al principio y al final del proceso, el servicio funcionará correctamente y se habilitará en algún punto intermedio.
Suena complicado, pero tratemos de explicarlo con un ejemplo. Quizás sea más claro.
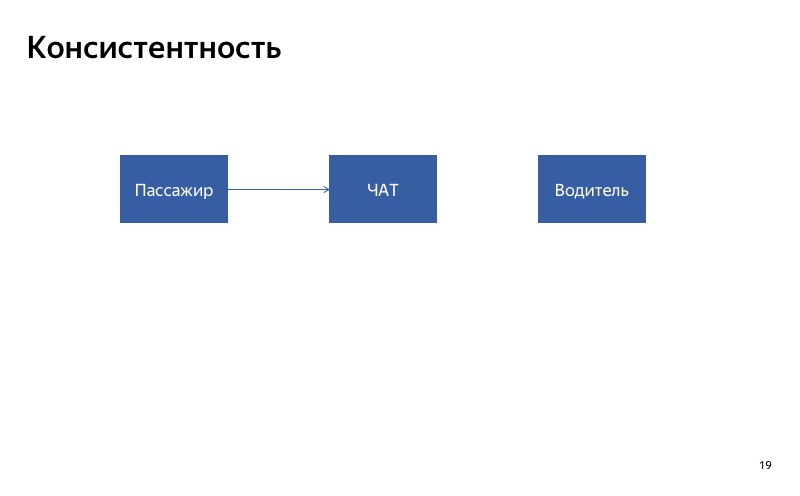
Aquí está nuestra conversación entre conductor y pasajero. La forma más fácil de degradarlo es deshabilitarlo. Imaginemos que el chat para el conductor está roto. Que va a pasar El cliente escribirá en el chat, pero el conductor no verá los mensajes. Probablemente serán muy infelices, maldecirán nuestra aplicación cuando se encuentren. En este caso, es importante que el chat se encienda al mismo tiempo o se apague al mismo tiempo para todos los participantes en el chat. Esto es lo que yo llamo consistencia.

El segundo matiz se refiere al hecho de que nuestra aplicación Yandex.Taxi está geo-distribuida: los taxis se pueden pedir en Moscú, Krasnoyarsk o Helsinki. Esto debe tenerse en cuenta incluso al desarrollar sistemas de degradación. Imagine que tenemos muchas solicitudes exitosas y muy pocas solicitudes con errores. Parece que esta es una situación normal, el fondo de los errores siempre está presente. Pero puedes ver la misma imagen de manera diferente.
Puede ver que el servicio no funciona en Mytishchi y necesita habilitar el respaldo para estos usuarios. La conclusión es: necesitas construir las estadísticas correctas. Para nosotros, como un servicio geo-distribuido, esto también significa que necesitamos construir estadísticas por ciudad. Si hacemos las estadísticas correctamente, veremos de inmediato que la mayoría de las solicitudes de Mytishchi se rompen y habilitamos el respaldo específicamente para los usuarios de Mytishchi. Y para todos los demás usuarios, continuaremos trabajando en modo normal, porque para ellos el servicio funciona correctamente.

Quizás para otros servicios habrá diferentes condiciones y otros matices.
Nuestros servicios son cada vez más complejos. A menudo dependen del mundo exterior, que no podemos predecir. Por lo tanto, es importante escribir no solo servicios que funcionen bien, sino también servicios que funcionen bien. Si aprende algo nuevo, dígaselo a sus colegas, comparta. Me gusta, compartir, volver a publicar. Degradar correctamente.