Introducción lírica
Una tarde, al poner las cosas en orden en un armario de pared, me topé con una gran caja de cartón. Sobrevivió a dos reubicaciones y no abrió durante tantos años que olvidé por completo lo que estaba almacenado en él. Resultó que había fotos, en álbumes, en sobres de una tienda, y algunas eran así.
Muchas fotografías fueron tomadas hace más de setenta años. Uno era abuelo: en su época de estudiante, todavía joven y guapo, con gafas absolutamente
destructivas . "Wow, mi abuelo usaba ropa hipster incluso antes de que se convirtiera en la corriente principal", pensé, e involuntariamente sonreí. Lo reconocí de inmediato, pero luego tomé fotos de personas de las que no recuerdo nada. En los rasgos faciales, puedes adivinar vagamente la relación, y eso es todo.

Cuando tenía quince años, mi abuela mostró repetidamente estas tarjetas y habló sobre los que están representados en ellas. Desafortunadamente, el valor de tales historias se entiende solo cuando no hay nadie para contarlas. En ese momento, por décima vez fue absolutamente desinteresado escuchar algunos cuentos cubiertos de musgo sobre los años anteriores a la guerra, los rechacé y les hice caso. Ahora, de repente, al darme cuenta de que parte de la historia de mi familia estaba irremediablemente perdida, tuve la idea de sistematizar y preservar lo que quedaba.
La solución ideal para almacenar datos familiares me pareció un híbrido de un motor wiki y un álbum de fotos. No había soluciones adecuadas ya hechas, así que tuve que escribir la mía. Se llama
Bonsai y es de código abierto bajo la licencia MIT. Luego habrá una historia sobre cómo está organizada y cómo usarla, así como la historia de su desarrollo y un poco de
DRAMA .

Otra bicicleta?
Hoy en día, hay muchas herramientas que le permiten crear árboles genealógicos y catalogar información sobre parientes. Se dividen condicionalmente en dos grandes categorías: servicios en línea y aplicaciones de escritorio.
En el caso de una aplicación de escritorio, la base de datos generalmente se almacena como un archivo en el disco. Abre la aplicación y la repone en modo de usuario único. Si es necesario, los datos se pueden exportar para hacer una copia de seguridad o transferirlos a otro sistema (por ejemplo, en formato
GEDCOM ). De los que vi, el más agradable de usar parecía
Gramps (gratis) y el
Life Tree doméstico (requiere una compra única).
El lado opuesto del espectro son los servicios web. Almacenan sus datos en servidores remotos y cobran una tarifa de uso periódica. Dado que este es un producto comercial con una base centralizada y una buena monetización, los servicios de este plan le brindan la oportunidad, por ejemplo, de buscar familiares perdidos mediante pruebas de ADN o registros de archivo.
Los pros y los contras de ambas opciones son bastante obvios. En el primer caso, almacena la base de datos localmente y controla completamente el acceso a ella y la creación de copias de seguridad. Si la aplicación es de código abierto, si es necesario, incluso puede agregarle funcionalidad adicional. Sin embargo, trabajar con dicha base de datos juntos o ver datos desde otro dispositivo será difícil. En el segundo, por el contrario, el acceso es desde cualquier dispositivo, pero usted cede sus datos a terceros y espera su decencia. En la historia de mi familia no hay secretos comprometedores y terribles, sin embargo, todavía considero que esta información es puramente personal y, en principio, no quiero que nadie más la almacene o analice.
Dadas las deficiencias de ambos enfoques, podemos formular una lista de requisitos para el motor "ideal":
- Aplicación web alojada en su propio servidor
- Creación de artículos sobre personas, mascotas, lugares, eventos, etc. como un wiki
- Descargar medios
- Marcas de personas en fotos y videos.
- Construcción automática de árboles genealógicos
- Calendario con todas las fechas importantes.
- Herramientas para coedición y relleno
Para ser justos, logré encontrar varios proyectos con una implementación autohospedada, pero estaban en un estado deplorable: la apariencia se congeló a mediados de la década de 2000, no había un conjunto completo de la funcionalidad necesaria y no quería profundizar en los scripts heredados en PHP. Además, el proyecto de mascota anterior había terminado y había un deseo de asumir algo nuevo.
La regla de oro dice:
si quieres hacerlo bien, ¡hazlo tú mismo!Las tecnologías utilizadas se seleccionaron de acuerdo con tres criterios: mi experiencia con ellas, popularidad y sin apertura. Aquí está el resultado:
- Rantime : .NET Core 2.1
- Back - end : ASP.NET Core MVC
- Base de datos : PostgreSQL
- Lógica frontend : parcialmente Vue, parcialmente jQuery.
- Estilos frontend : Bootstrap + Sass
Los roles de apoyo incluyen Elasticsearch para búsqueda de texto completo y ffmpeg para tomar capturas de pantalla del video.
Esquema de datos
Los objetos principales en la base de datos Bonsai son una
página y un
archivo multimedia . Están conectados por una relación de muchos a muchos a través de las
marcas . Una etiqueta puede tener un título sin un enlace, por ejemplo, si necesita etiquetar a alguien en una foto, pero no hay información en una página completa al respecto.
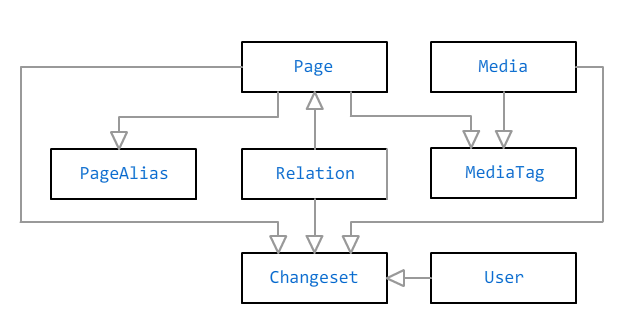
Además del texto libre, la página puede contener
datos que se ingresan en campos especiales en el panel de administración. Los hechos adicionales se calculan sobre los hechos: por ejemplo, si indica la fecha de nacimiento de la persona, se marcará en el calendario y su página mostrará la edad actual (o la esperanza de vida, si también se indica la fecha de fallecimiento), el sexo puede usarse para determinar el nombre correcto de la relación ("padre "O" madre "en lugar de los" padres "comunes), y así sucesivamente. Los hechos se almacenan en la base de datos como un documento JSON.
Hay cinco tipos de páginas para elegir: persona, mascota, evento, lugar, etc. La lista de datos disponibles depende del tipo de página: por ejemplo, "educación" es relevante solo para una persona, "fecha de nacimiento" - para una persona y un animal, y "dirección" - solo para un lugar.
Las páginas están interconectadas por
relaciones : "padre", "cónyuge", "amigo", "propietario", "residente" y muchos otros. Algunas relaciones pueden ser limitadas en el tiempo (cónyuge, propietario, residente), otras se consideran permanentes.
Cuando guarda cualquier página o relación, se verifica la coherencia del modelo resultante. Por ejemplo,
los años de vida de los cónyuges deben superponerse , una persona no puede tener más de un padre biológico de cada sexo y tampoco puede
convertirse en su propio padre . Los matrimonios del mismo sexo, sin embargo, son permisibles.
La edición de una página, un archivo multimedia o una relación guarda el
cambio en la base de datos. Esto le permite guardar el historial de ediciones y revertirlas si es necesario.
Relación
El parentesco es uno de los conceptos más antiguos de la sociedad. Ya en el idioma
pre-indoeuropeo, había muchos nombres para ellos, que, en una forma ligeramente modificada, migraron a los idiomas modernos de varios grupos: la palabra "madre" será entendida por el ruso, el inglés y el chino.
Hay muchas opciones para el parentesco, pero las básicas son tres:
padre ,
hijo y
cónyuge . Le permiten construir un gráfico dirigido de la familia donde estas relaciones son aristas y las personas son nodos. En esta columna, puede expresar cualquier otra relación, conociendo el camino entre los participantes y su género: por ejemplo, para identificar al abuelo de alguien, primero debe encontrar a su padre (cualquier género), y luego el padre de este padre (hombre), y así sucesivamente.
En el panel de administración de Bonsai, puede ingresar las relaciones de estos tres tipos básicos. Lo opuesto se creará automáticamente para cada relación: padre por hijo, cónyuge por cónyuge, dueño por mascota. El motor calcula todas las relaciones adicionales y se muestran en la barra lateral de la página:
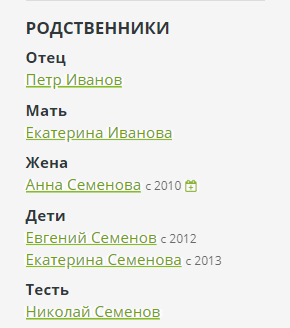
Para calcular la relación, se utiliza un recorrido de gráfico elemental y los nombres de relación se establecen en forma de un DSL especial:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
Incluso una persona puede tener
muchos parientes directos. Bonsai divide los enlaces en los siguientes grupos:
- La relación de sangre más cercana es la familia en la que la persona creció: madre y padre, abuelos, hermanos y hermanas. Si observa el gráfico, esta es la ruta 1-2 pasos hacia arriba y 1 hacia los lados.
- Familia propia : un grupo por cada cónyuge e hijos de él. Esto también incluye a los familiares del cónyuge: suegra, cuñado y similares.
- Otros : parientes más distantes (nietos, tíos, tías) y lazos no familiares (amigos, colegas).
A veces, una forma de determinar la pertenencia a un grupo no es suficiente. Los datos pueden estar incompletos, pero aún deben mostrarse de la manera más adecuada posible. Considere el siguiente gráfico de hermanos:
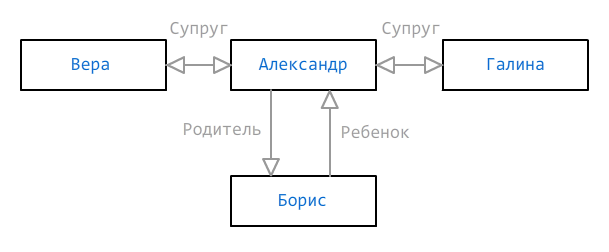
Como podemos ver, dos esposas (Vera y Galina) y un hijo (Boris) están indicados para Alexander, pero no sabemos cuál de las esposas es la madre del niño; tal vez esta sea una especie de tercera mujer, pero aún no ha sido agregada. Para tales casos, se pueden indicar varias rutas que deberían existir o no, y están marcadas con signos
+ y
- respectivamente:
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
Árbol genealógico
Cualquier motor de genealogía decente debería ser capaz de construir un árbol genealógico. Esta es la forma más visual de mostrar información general sobre las personas y sus relaciones familiares. Los datos se almacenan en la base de datos en forma de un gráfico dirigido y, en teoría, debería ser fácil de visualizar. En la práctica, fue con la exhibición del árbol que surgieron las mayores dificultades.
Aquí hay algunos ejemplos de cómo se verían los árboles genealógicos:

Árbol genealógico de Targaryenov. Muy compacto, porque está hecho a mano. Generar tal árbol a partir de datos arbitrarios será extremadamente difícil automáticamente.
Dioses griegos La representación gráfica se genera a partir de una
sintaxis de reducción especial , en la que aún debe organizar manualmente todos los bloques y dibujar los enlaces entre ellos. Un poco como el arte ASCII.

Presentación de un árbol en forma de diagrama semicircular. Se genera fácilmente de forma automática, pero solo tiene en cuenta antepasados directos.
Miré a través de muchas opciones. Lo más estéticamente agradable fue en el sitio web MyHeritage:
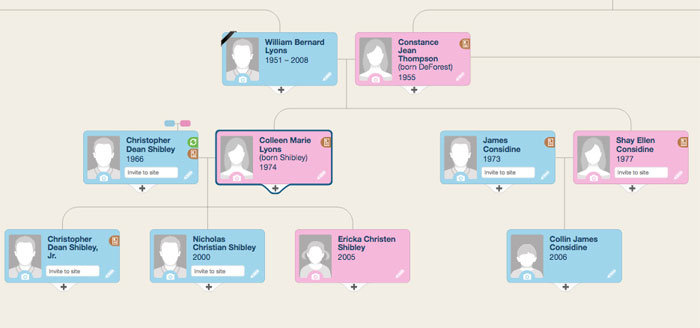
La representación de dicho árbol se puede dividir en tres pasos condicionales: obtener datos de la base de datos, organizar bloques / líneas de conexión y mostrarlos directamente en la página. Si todo fue trivial con el primer y tercer paso, entonces en el segundo tropecé.
Los intentos de lanzar una solución hecha a sí misma a toda prisa terminaron en un fiasco completo. Una disposición competente de elementos gráficos es un área tan compleja que las
disertaciones están escritas en ella, y los
componentes terminados son como un apartamento en Moscú. De acuerdo, no podrás escribir tú mismo, pero ¿seguramente hay soluciones gratuitas decentes?
La mayoría de mis esperanzas estaban en la
biblioteca D3.js. Quizás esto es lo primero que viene a la mente si necesita dibujar un gráfico o cuadro en una página web. Por desgracia, entre más de trescientos (!) Ejemplos en la wiki, no había uno más o menos similar a un árbol con MyHeritage.
El siguiente paso fue sumergirse en bibliotecas que no estaban involucradas en el renderizado, sino en el cálculo de la disposición óptima de los elementos en el gráfico. La mayoría de ellos ofrecen el llamado
diseño de la Fuerza . Este es un enfoque muy simple, que se basa en fórmulas físicas: los nodos de la gráfica están representados por cuerpos elásticos, y las líneas de conexión están representadas por resortes. Se puede reconocer fácilmente por su animación característica: el gráfico parece "enderezarse" sobre la marcha, y esto no es una característica adicional, sino una consecuencia inevitable de la naturaleza de simulación del algoritmo. El enfoque de diseño forzado es bueno para visualizar datos sin una jerarquía clara (por ejemplo, conexiones en redes sociales), pero el árbol genealógico de esta forma parece defectuoso.
Otra opción considerada es la biblioteca
Graphviz . El resultado de su trabajo puede reconocerse fácilmente por las flechas características. Se utiliza un lenguaje especial
DOT para describir el gráfico. Los casos de prueba se ven aún más o menos, pero hay problemas con los datos reales: las flechas "se rompen" y se conectan en ángulos extraños, el gráfico se desliza hacia arriba y no puede ajustarlo y no puede evitarlo.
Al no haber encontrado una solución adecuada por mi cuenta, decidí pedirla por cuenta propia, y luego comenzó el mismo
DRAMA .
El pedido se realizó en la mañana del 22 de octubre, y en una hora recibió varias respuestas. Uno de los encuestados se llamaba Vladislav; envió un ejemplo de una solución similar y prometió completar la tarea en
un día . Esta velocidad me pareció sospechosa, pero esperaba su experiencia y para mí mismo le di al chico un error de una semana. Los primeros días, Vladislav hizo preguntas adicionales, sin dejar de sorprenderme con una profunda inmersión en el proyecto y una actitud atenta a los detalles, y luego desapareció. Se despertó el 1 de noviembre, se disculpó por la desaparición forzada por razones familiares y envió un enlace con una versión beta que se parecía bastante a lo que quería si no fuera por el nodo en las líneas de conexión en el centro:
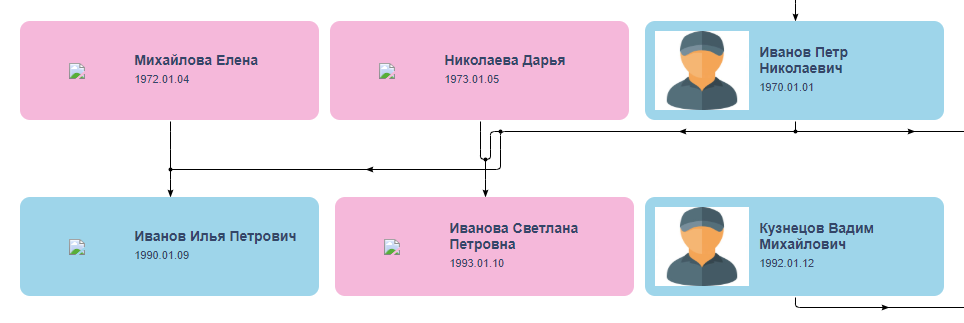
La desaparición del intérprete siempre es una llamada de atención, pero nunca se sabe, sucede algo, porque él hizo algo. ¡Que continúe! Envié un prepago y comencé a esperar mejoras. Después de un par de días, Vladislav escribió que no podía solucionar el problema y luego desapareció nuevamente, esta vez durante tres semanas. Durante este tiempo, no hizo nada y se negó a devolver el anticipo, porque "la tarea fue realizada por un
estúpido ex amigo que lo decepcionó y no le devolvió el dinero". Después de un par de preguntas aclaratorias, el desafortunado delegado dejó de intentar disculparse y se calló. Así que ahora vivimos, de vez en cuando le recuerdo la deuda, y en respuesta envía una captura de pantalla de la aplicación bancaria, dicen, "no hay dinero, pero tan pronto como sea, de inmediato". ¡Deseo que Vladislav tenga éxito en los negocios y enriquecerse más rápido!
Lanzó al niño - menos en karma!Perder dinero no fue tan molesto, pero pasó un mes, y la tarea no se movió, y ahora no había ningún lugar para esperar ayuda. En primer lugar, estaba enojado conmigo mismo: tomé el camino de menor resistencia, violé la
regla de oro , y aquí está el resultado. Lleno de ira justa, nuevamente me senté a estudiar bibliotecas para dibujar gráficos y ¡he aquí! - De repente encontró exactamente lo que necesita.
La biblioteca se llamaba
Eclipse Layout Kernel , abreviado ELK. Como puede suponer, se usa para mostrar diagramas en el Eclipse IDE, pero también se puede usar de forma autónoma. En general, está escrito en Java, pero hay una versión transmitida en JS. Sí, su código es una
pesadilla y pesa un megabyte y medio, pero estas deficiencias se pueden perdonar por el hecho de que
simplemente funciona y hace exactamente lo correcto. La interfaz es elemental: los nodos, bordes y configuraciones se transmiten a la entrada, y en la salida obtenemos las coordenadas. Puede dibujar un árbol con ellos de cualquier manera conveniente: elegí SVG para conectar líneas y divs con posicionamiento absoluto para bloques.
La integración de la biblioteca y la selección de configuraciones óptimas tomó dos noches en la fuerza. Esto, por supuesto, no es "un día", como prometió mi desafortunado y arrogante profesional independiente, sino bastante cerca. Como resultado, Bonsai pudo mostrar el árbol aproximadamente de esta forma:
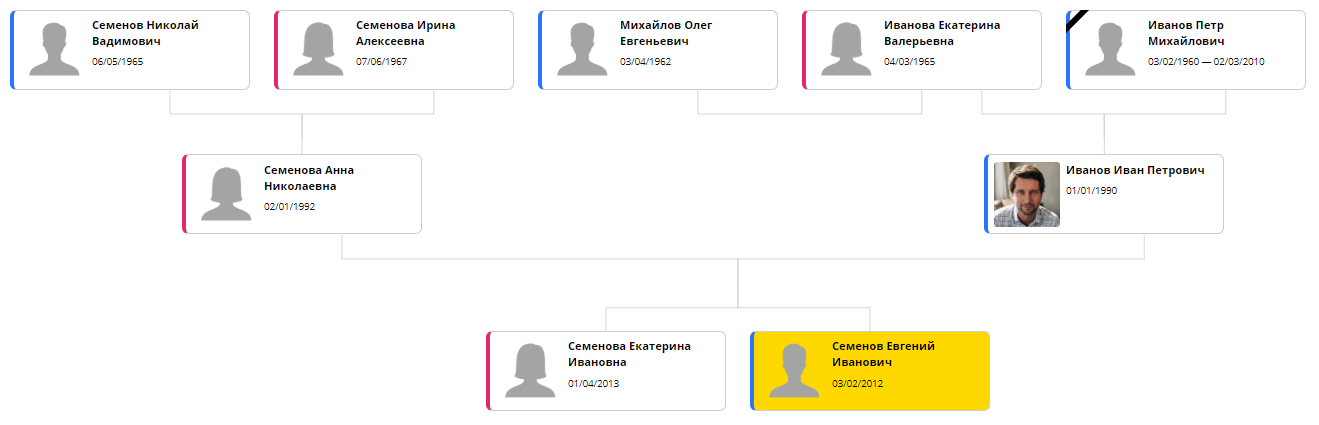
Ahora el único problema que queda es el tiempo de procesamiento. ELK utiliza un algoritmo iterativo: puede acercarse a la ubicación óptima al dedicar más tiempo. En un árbol de 20-30 elementos, un buen resultado requiere aproximadamente 5 segundos. Debido a esto, una página con un árbol se abre cada vez durante mucho tiempo, y rápidamente comienza a molestar. Para la próxima versión, el cálculo se transferirá al backend para que se pueda hacer una vez al cambiar la página y el almacenamiento en caché.
Búsqueda de texto completo
Un sistema para almacenar información textual sería inútil sin una conveniente búsqueda de texto completo. Bonsai utiliza la base de datos PostgreSQL, por lo que lo primero que decidí fue comprobar qué podía ofrecer de inmediato. Otra decepción:
tsvector hace frente a palabras comunes, pero se niega a buscar lo más importante: nombres y apellidos:
SELECT to_tsvector('') @@ to_tsquery(''),
Los trigramas tampoco dieron nada bueno. Al final, me decidí por una opción bastante esperada: ElasticSearch +
Russian Morfology . Resultó ser muy inconveniente trabajar con él desde .NET, pero se las arregla con un sólido cinco con una búsqueda por nombre.
Imperfección consciente
Al trabajar en un proyecto, las situaciones ocurrían regularmente cuando un
perfeccionista interno estaba furioso por la solución elegida. El área temática es bastante no estándar y las "buenas maneras" generalmente aceptadas no siempre funcionan.
Por ejemplo, ¿qué sucede cuando abrimos cualquier página?
- El texto de la página se compila de Markdown a HTML. Si el texto contiene enlaces a otras páginas y archivos multimedia, tendrá que ir a la base de datos para obtener más información.
- Los hechos se deserializan del JSON en el que se almacenan en la base de datos, en el modelo de vista.
- Las relaciones están determinadas. Para hacer esto, desde la larga base de datos, es necesario obtener el gráfico de conexión completo y encontrar nodos en él de acuerdo con una lista de rutas previamente conocida.
A primera vista, parece una operación terriblemente difícil, pero en realidad no se debe a la cantidad relativamente pequeña de datos. ¿Cuántos parientes puedes recordar y quieres escribir? Intente contarlos por interés y descubra que será muy difícil marcar al menos un centenar. ¿Y cuántas personas quieren dar acceso? ¡Incluso un número astronómicamente grande para una familia es mil personas! - Según los estándares de las bases de datos modernas, sigue siendo ridículo.
Por supuesto, el modelo de vista de página compilada todavía se almacena en caché la primera vez que se abre y se reutiliza en los posteriores, principalmente porque era muy fácil de implementar. La regla de invalidación de caché para los cambios en el panel de administración también se toma de la manera más simple posible: si cambiamos solo el texto y algunos datos
locales (lista de idiomas, tipo de sangre, color de cabello, etc.), simplemente restablezca esta página específica. Con cualquier otro cambio (nombre de la página, fecha de nacimiento o sexo, agregando o cambiando cualquier conexión), el caché se restablece por
completo . Sí, esta no es la forma más inteligente de limpiar. Sí, seguro, podría escribir un algoritmo complejo que restablecería solo lo que necesita, pero para este proyecto no justificaría los costos.
El proyecto no admite la localización y el cambio de apariencia, la autorización funciona en OAuth en Facebook \ Google, y el panel de administración se realiza en los formularios habituales, y no en un marco de SPA basado en la última moda. Todo esto
podría realizarse o mejorarse, pero no habría resuelto ningún problema y, por lo tanto, se habría perdido el tiempo.
Mirando hacia el futuro
Otra razón por la que no tiene sentido invertir en la complejidad del dispositivo del motor es la naturaleza efímera de la implementación en comparación con los datos que almacena. Solo piense por un momento: la web en su forma actual ha existido durante casi veinte años, y la historia familiar ha existido
durante siglos . Nadie ha resuelto este problema simplemente porque la industria de la tecnología de la información en sí misma existe mucho menos. Que se puede hacer
El motor tendrá que ser reescrito regularmente desde cero, al igual que durante miles de años, los monjes han sido difíciles de copiar textos de libros en ruinas a otros nuevos. La única diferencia es que el libro puede durar cien años con un manejo adecuado y la aplicación, con una solidez de 15-20 años. Espero que en veinte años todavía pueda hacerlo yo mismo, pero en otros veinte años mis hijos o nietos tendrán que hacerlo. Me gustaría dejarles una fuente simple, comprensible y documentada.
En las primeras etapas del diseño, quería incrustar un cierto lenguaje similar al SQL en el motor, con la ayuda de la cual pude obtener respuestas a preguntas específicas: "cuál es el porcentaje de mis antepasados con ojos azules", "cuando Ivan compró el primer auto", etc. Esta idea tuvo que ser abandonada porque requeriría, en lugar del texto sin formato, ingresar toda la información en una determinada forma formal, y solo una descripción de este tipo llevaría años. Por otro lado, la comprensión del lenguaje natural está ganando impulso. No me sorprenderá si dentro de diez o dos años será posible pedirle a Siri que lea el texto por usted, siga los enlaces y, como resultado, presente un extracto de los hechos. Chicos, empujen!
¿Cómo intentarlo?
Lamentablemente, no puedo proporcionar un enlace a la demostración finalizada: no hay ningún servidor que pueda soportar el efecto habra. Pero hay algunas capturas de pantalla visuales (se puede hacer clic en las imágenes).
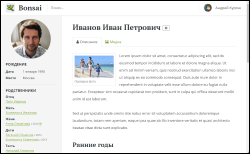

Si Bonsai te pareció útil y quieres ejecutarlo tú mismo, el código fuente se puede descargar desde Github:
https://github.com/impworks/bonsaiLas instrucciones detalladas de instalación se proporcionan en el archivo Léame. Necesitarás esto:
- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.xy el complemento de morfología rusa
- Aplicación de Facebook o Google para la autorización de oAuth
Después del primer lanzamiento, se crean varias páginas de prueba y fotos en la base de datos. Para la producción, este comportamiento no es necesario y el indicador lo deshabilita en la configuración.
Hace apenas un mes, lancé mi propia instancia y comencé a ejecutarla, obteniendo datos reales. Se encuentra cierta aspereza, pero de lo contrario estoy completamente satisfecho con el resultado. Ahora el proyecto se desarrollará y finalizará gradualmente. Las tareas principales son acelerar la visualización del árbol, permitir la descarga de documentos en forma de PDF y agregar ajustes de los derechos de acceso. Sería bueno mejorar la usabilidad del panel de administración en algunos lugares o reconocer automáticamente las caras en la foto,
pero esto no es exacto .