
En el artículo anterior, hablamos sobre un problema de aprendizaje automático como ejemplos adversarios y algunos tipos de ataques que permiten que se generen. Este artículo se centrará en algoritmos de protección contra este tipo de efecto y recomendaciones para probar modelos.
Protección
En primer lugar, expliquemos de inmediato un punto: es imposible defenderse completamente de tal efecto, y esto es bastante natural. De hecho, si resolviéramos por completo el problema de los ejemplos adversarios, resolveríamos simultáneamente el problema de construir un hiperplano ideal, que, por supuesto, no se puede hacer sin un conjunto de datos general.
Hay dos etapas para defender un modelo de aprendizaje automático:
Aprendizaje : enseñamos a nuestro algoritmo a responder correctamente a ejemplos adversarios.
Operación : estamos tratando de detectar un ejemplo de confrontación durante la fase de operación del modelo.
Vale la pena decir de inmediato que puede trabajar con los métodos de protección presentados en este artículo utilizando la Caja de herramientas de robustez adversa de IBM.
Entrenamiento Adversarial

Si le pregunta a una persona que acaba de familiarizarse con el problema Adversarial con ejemplos, la pregunta: “¿Cómo protegerse de este efecto?”, Entonces, por supuesto, 9 de cada 10 personas dirán: “Agreguemos los objetos generados al conjunto de entrenamiento”. Este enfoque fue propuesto inmediatamente en el artículo Propiedades intrigantes de las redes neuronales en 2013. Fue en este artículo que este problema se describió por primera vez y el ataque L-BFGS, que permite recibir ejemplos adversos.
Este método es muy simple. Generamos ejemplos Adversarial usando varios tipos de ataques y los agregamos al conjunto de entrenamiento en cada iteración, aumentando así la "resistencia" del modelo Adversarial a los ejemplos.
La desventaja de este método es bastante obvia: en cada iteración de entrenamiento, para cada ejemplo, podemos generar una gran cantidad de ejemplos, respectivamente, y el tiempo para modelar el entrenamiento aumenta muchas veces.
Puede aplicar este método utilizando la biblioteca ART-IBM de la siguiente manera.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
Aumento de datos gaussiano
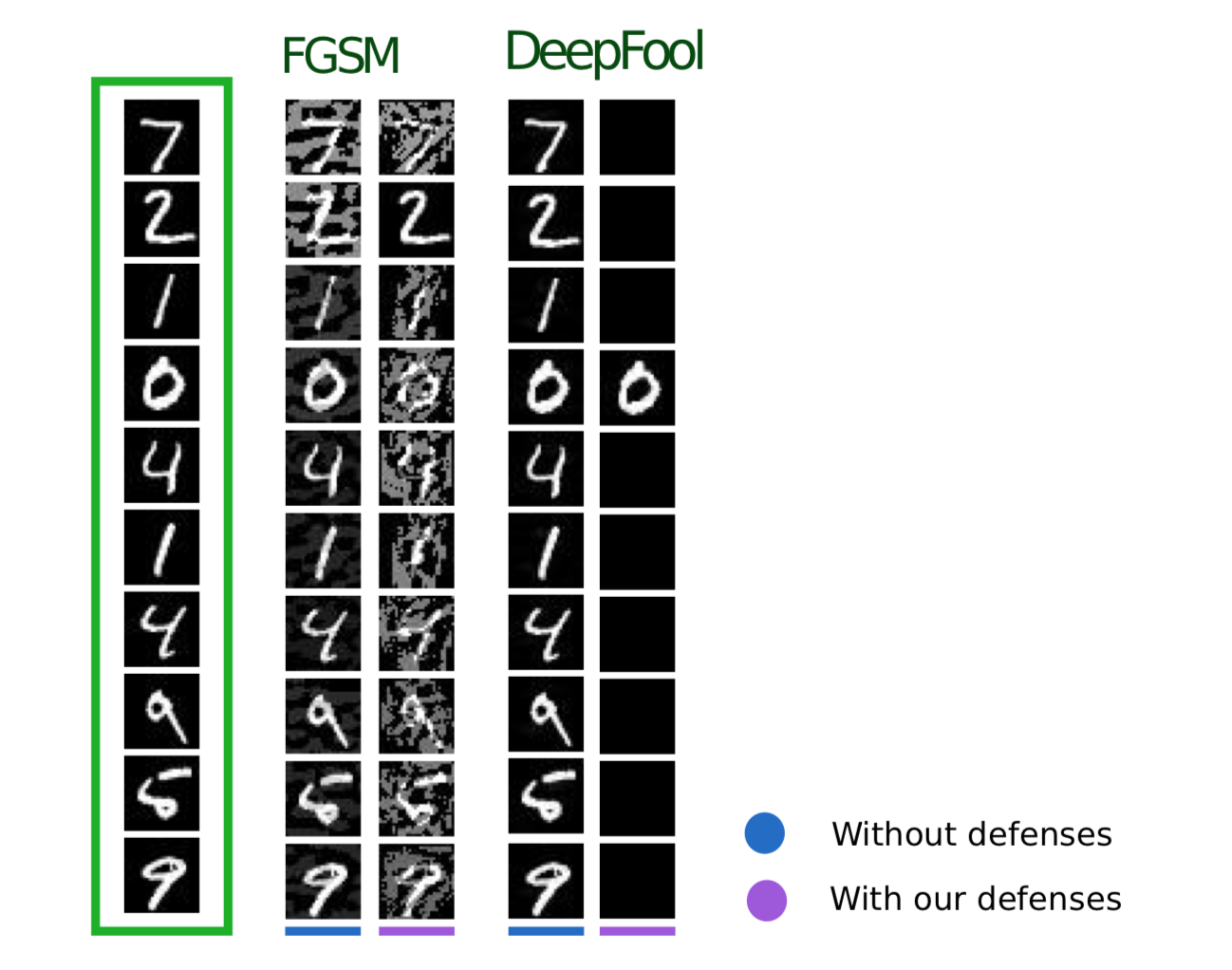
El siguiente método, descrito en el artículo Eficaces defensas contra ataques adversos , utiliza una lógica similar: también sugiere agregar objetos adicionales al conjunto de entrenamiento, pero a diferencia del Entrenamiento Adversario, estos objetos no son ejemplos adversos, sino objetos de conjunto de entrenamiento ligeramente ruidosos (Gaussian se usa como ruido ruido, de ahí el nombre del método). Y, de hecho, esto parece muy lógico, porque el principal problema de los modelos es precisamente su baja inmunidad al ruido.
Este método muestra resultados similares al Entrenamiento Adversario, al tiempo que dedica mucho menos tiempo a generar objetos para el entrenamiento.
Puede aplicar este método utilizando la clase GaussianAugmentation en ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
Suavizado de etiquetas
El método de suavizado de etiquetas es muy sencillo de implementar, pero tiene un gran significado probabilístico. No entraremos en detalles sobre la interpretación probabilística de este método; puede encontrarlo en el artículo original Repensar la arquitectura de inicio para la visión por computadora . Pero, para decirlo brevemente, Label Smoothing es un tipo adicional de regularización del modelo en el problema de clasificación, lo que lo hace más resistente al ruido.
De hecho, este método suaviza las etiquetas de clase. Haciéndolos, digamos, no 1, sino 0.9. Por lo tanto, los modelos de entrenamiento son multados por una "confianza" mucho mayor en la etiqueta de un objeto en particular.
La aplicación de este método en Python se puede ver a continuación.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
Acotado relu
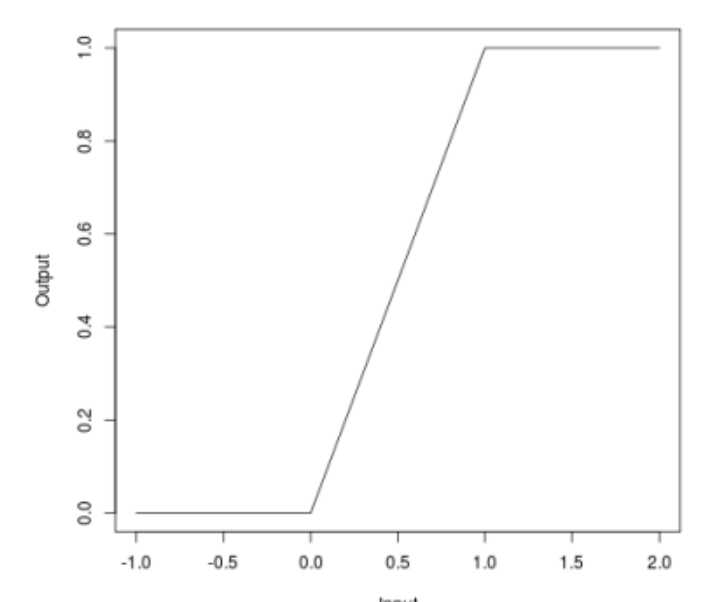
Cuando hablamos de ataques, muchos pudieron notar que algunos ataques (JSMA, OnePixel) dependen de qué tan fuerte es el gradiente en un punto u otro en la imagen de entrada. El método simple y "barato" (en términos de costos computacionales y de tiempo) de Bounded ReLU está tratando de resolver este problema.
La esencia del método es la siguiente. Reemplacemos la función de activación de ReLU en una red neuronal con la misma, que está limitada no solo desde abajo, sino también desde arriba, suavizando así los mapas de gradiente, y en puntos específicos no será posible obtener una salpicadura, lo que no le permitirá engañar al algoritmo cambiando un píxel de la imagen.
\ begin {ecation *} f (x) =
\ begin {cases}
0, x <0
\\
x, 0 \ leq x \ leq t
\\
t, x> t
\ end {casos}
\ end {ecuación *}
Este método también se ha descrito en el artículo Defensas eficientes contra ataques adversos
Conjuntos de modelos de construcción
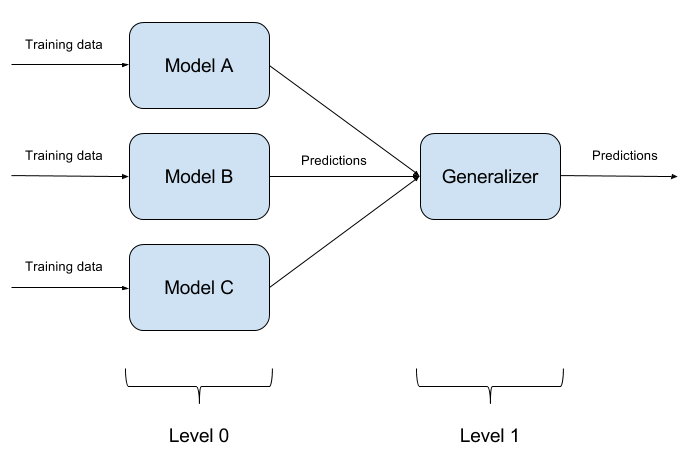
No es difícil engañar a un modelo entrenado. Engañar a dos modelos al mismo tiempo con un objeto es aún más difícil. ¿Y si hay N de tales modelos? En esto se basa el método de conjunto de modelos. Simplemente construimos N modelos diferentes y agregamos su salida en una sola respuesta. Si los modelos también están representados por diferentes algoritmos, entonces es extremadamente difícil engañar a dicho sistema, ¡pero es extremadamente difícil!
Es bastante natural que la implementación de conjuntos de modelos sea un enfoque puramente arquitectónico, que plantea muchas preguntas (¿Qué modelos básicos tomar? ¿Cómo agregar los resultados de los modelos básicos? ¿Existe una relación entre los modelos? Y así sucesivamente). Por esta razón, este enfoque no está implementado en ART-IBM
Exprimir características
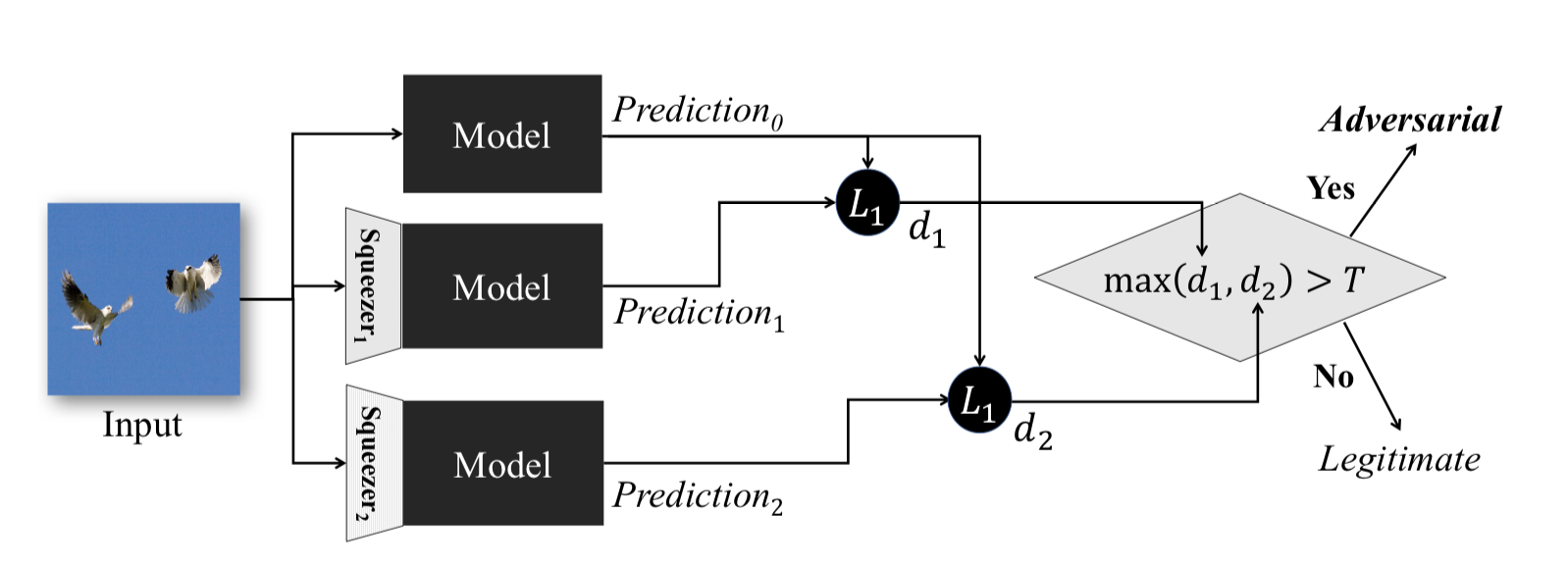
Este método, descrito en la compresión de características: detección de ejemplos adversos en redes neuronales profundas , funciona durante la fase operativa del modelo. Le permite detectar ejemplos adversos.
La idea detrás de este método es la siguiente: si entrena n modelos con los mismos datos, pero con diferentes relaciones de compresión, los resultados de su trabajo seguirán siendo similares. Al mismo tiempo, el ejemplo Adversarial, que funciona en la red de origen, probablemente fallará en redes adicionales. Por lo tanto, considerando la diferencia por pares entre las salidas de la red neuronal inicial y las adicionales, eligiendo el máximo de ellas y comparándolas con un umbral preseleccionado, podemos afirmar que el objeto de entrada es Adversarial o absolutamente válido.
El siguiente es un método para obtener objetos comprimidos utilizando ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
Terminaremos con los métodos de protección. Pero sería un error no comprender un punto importante. Si un atacante no tiene acceso a la entrada y salida del modelo, no comprenderá cómo se procesan los datos sin procesar dentro de su sistema antes de ingresar el modelo. Entonces, y solo entonces, todos sus ataques se reducirán a la clasificación aleatoria de los valores de entrada, lo que, naturalmente, es poco probable que conduzca al resultado deseado.
Prueba
Ahora hablemos de probar algoritmos para contrarrestar los ejemplos adversos. Aquí, antes que nada, es necesario entender cómo vamos a probar nuestro modelo. Si suponemos que de alguna manera un atacante puede obtener acceso completo a todo el modelo, entonces es necesario probar nuestro modelo utilizando los métodos de ataque de WhiteBox.
En otro caso, suponemos que un atacante nunca tendrá acceso a los "interiores" de nuestro modelo, pero podrá, aunque sea indirectamente, influir en los datos de entrada y ver el resultado del modelo. Entonces deberías aplicar los métodos de los ataques BlackBox.
El algoritmo de prueba general se puede describir con el siguiente ejemplo:
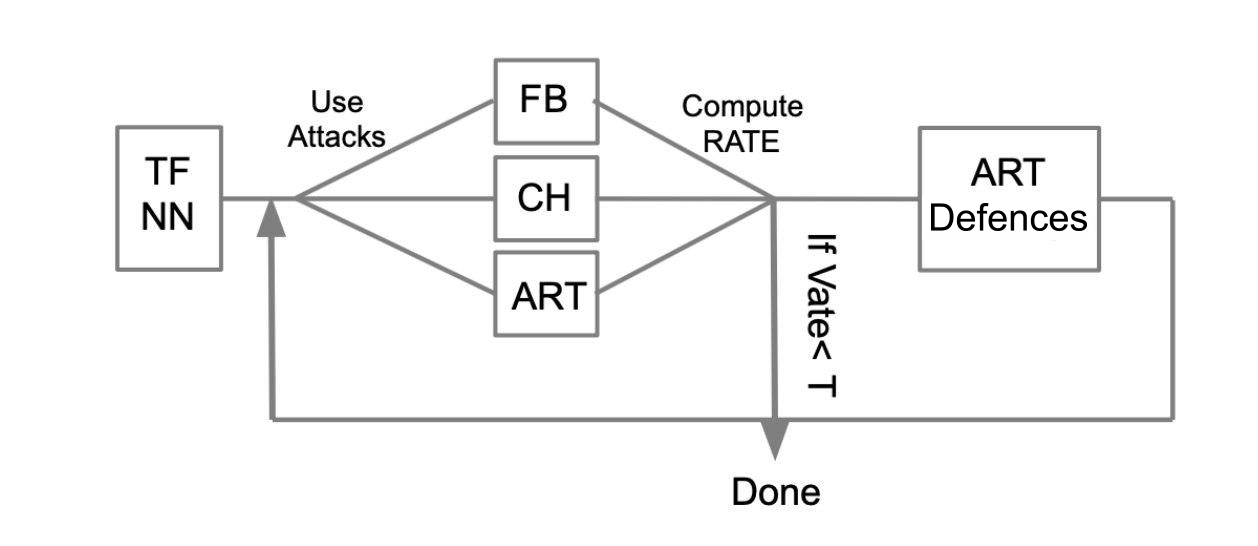
Que haya una red neuronal entrenada escrita en TensorFlow (TF NN). Afirmamos que nuestra red puede caer en manos de un atacante al penetrar en el sistema donde se encuentra el modelo. En este caso, necesitamos llevar a cabo ataques WhiteBox. Para hacer esto, definimos un grupo de ataque y marcos (FoolBox - FB, CleverHans - CH, Caja de herramientas de robustez adversaria - ART) que permiten implementar estos ataques. Luego, contando cuántos ataques tuvieron éxito, calculamos la tasa de éxito (SR). Si SR nos conviene, terminamos las pruebas; de lo contrario, utilizamos uno de los métodos de protección, por ejemplo, implementado en ART-IBM. Por otra parte, llevamos a cabo ataques y consideramos SR. Hacemos esta operación cíclicamente, hasta que SR nos convenga.
Conclusiones
Me gustaría terminar aquí con información general sobre ataques, defensas y pruebas de modelos de aprendizaje automático. Resumiendo los dos artículos, podemos concluir lo siguiente:
- No creas en el aprendizaje automático como una especie de milagro que puede resolver todos tus problemas.
- Cuando aplique algoritmos de aprendizaje automático en sus tareas, piense en cuán resistente es este algoritmo a una amenaza como los ejemplos adversos.
- Puede proteger el algoritmo tanto del lado del aprendizaje automático como del lado del sistema en el que se opera este modelo.
- Pruebe sus modelos, especialmente en casos donde el resultado del modelo afecta directamente la decisión
- Las bibliotecas como FoolBox, CleverHans, ART-IBM proporcionan una interfaz conveniente para atacar y defender modelos de aprendizaje automático.
También en este artículo me gustaría resumir el trabajo con las bibliotecas FoolBox, CleverHans y ART-IBM:
FoolBox es una biblioteca simple y comprensible para atacar redes neuronales, que admite muchos marcos diferentes.
CleverHans es una biblioteca que le permite realizar ataques cambiando muchos parámetros del ataque, un poco más complicado que FoolBox, admite menos marcos.
ART-IBM es la única biblioteca de lo anterior que le permite trabajar con métodos de seguridad, hasta ahora solo es compatible con TensorFlow y Keras, pero se está desarrollando más rápido que otros.
Aquí vale la pena decir que hay otra biblioteca para trabajar con ejemplos adversarios de Baidu, pero, desafortunadamente, es adecuada solo para personas que hablan chino.
En el próximo artículo sobre este tema, analizaremos parte de la tarea que se propuso resolver durante ZeroNights HackQuest 2018 engañando a una red neuronal típica utilizando la biblioteca FoolBox.