El modelo de Infraestructura como Código (IaC), a veces denominado "infraestructura programable", es un modelo mediante el cual el proceso de configuración de la infraestructura es similar al proceso de programación de software. Esencialmente, marcó el comienzo de eliminar los límites entre escribir aplicaciones y crear entornos para estas aplicaciones. Las aplicaciones pueden contener scripts que crean y administran sus propias máquinas virtuales. Esta es la base de la computación en la nube y una parte integral de DevOps.
La infraestructura como código le permite administrar máquinas virtuales a nivel de software. Esto elimina la necesidad de configuración manual y actualizaciones para los componentes individuales del equipo. La infraestructura se vuelve extremadamente "resistente", es decir, reproducible y escalable. Un operador puede implementar y administrar tanto una como 1000 máquinas usando el mismo conjunto de código. Entre los beneficios garantizados de la infraestructura como código se encuentran la velocidad, la rentabilidad y la reducción de riesgos.
Esto es exactamente de lo que se trata la decodificación del informe de Kirill Vetchinkin en DevOpsDays Moscow 2018. El informe: reutilización de módulos Ansible, almacenamiento en Git, revisión, reconstrucción, beneficios financieros, escala horizontal con 1 clic.
A quién le importa, por favor, debajo del gato.
Hola a todos Como ya dije, soy Vetchinkin Kirill. Trabajo en TYME y hoy hablaremos de la infraestructura como un código. También hablaremos sobre cómo aprendimos a ahorrar en esta práctica, porque es bastante costosa. Escribir una gran cantidad de código es bastante costoso para configurar la infraestructura.
Hablaré brevemente sobre la compañía. Yo trabajo en TYME. Tuvimos un cambio de marca. Ahora nos llamamos PaySystem, como su nombre lo indica, estamos comprometidos con los sistemas de pago. Tenemos nuestras propias soluciones: estos son procesamientos y desarrollo personalizado. El desarrollo personalizado es la banca electrónica, la facturación y similares. Y como saben, si este es un desarrollo personalizado, entonces se trata de una gran cantidad de proyectos cada año. El proyecto va después del proyecto. Cuantos más proyectos, más infraestructura del mismo tipo tiene que ser levantada. Como los proyectos suelen estar muy cargados, utilizamos la arquitectura de microservicios. Por lo tanto, en un proyecto hay muchos, muchos pequeños subproyectos.

En consecuencia, administrar todo este zoológico sin un DevOps completo es muy difícil. Por lo tanto, nuestra compañía ha implementado varias prácticas de DevOps. Naturalmente, trabajamos en kanban, en SCRUM, almacenamos todo en git. Después de comprometerse, hay una integración continua, se ejecutan pruebas. Los probadores escriben pruebas de punta a punta en PyTest que comienzan todas las noches. La prueba unitaria comienza después de cada confirmación. Utilizamos un proceso de compilación e implementación por separado: ensamblado, luego implementamos en varios entornos muchas veces. Estábamos en ventanas. En Windows implementamos usando Octopus deploy. Este año estamos desarrollando DotNet Core. Por lo tanto, ahora podemos ejecutar software en sistemas Linux. Dejamos Octopus y llegamos a Ansible. Hoy hablaremos sobre esta parte, que es una nueva práctica que desarrollamos este año, algo que no teníamos antes. Cuando tiene pruebas, cuando sabe cómo construir bien la aplicación, está bien implementarla en algún lugar. Pero si tiene dos entornos configurados de manera diferente, aún caerá y caerá en producción. Por lo tanto, administrar configuraciones es una práctica muy importante. De eso es de lo que hablaremos hoy.

Describiré brevemente cómo se construye la economía laboral del producto: el 60 por ciento se gasta en desarrollo , el análisis toma alrededor del 10 por ciento, el control de calidad (pruebas) toma alrededor del 20 por ciento, y todo lo demás se asigna a la configuración. Cuando los sistemas funcionan a pleno rendimiento, tienen muchos software de terceros, los sistemas operativos se configuran casi de la misma manera. Pasamos más tiempo haciendo esto, esencialmente haciendo lo mismo. Hubo una idea para automatizar todo y reducir el costo de configuración de la infraestructura. Tareas similares están automatizadas, bien depuradas y no contienen operaciones manuales.

Cada aplicación funciona en algún tipo de entorno. Veamos en qué consiste todo. Como mínimo, debemos tener un sistema operativo , debe configurarse, hay algunas aplicaciones de terceros que también deben configurarse, la aplicación en sí misma debe recibir las configuraciones, pero para que todo el producto funcione, la aplicación en sí misma debe iniciarse, la cual opera en todo este sistema. También hay una red que también debe configurarse, pero hoy no hablaremos de la red porque tenemos diferentes clientes, diferentes dispositivos de red. También intentamos automatizar la configuración de la red, pero dado que los dispositivos son diferentes, no hubo ningún beneficio particular de esto, gastamos más recursos en esto. Pero automatizamos los sistemas operativos, las aplicaciones de terceros y la transferencia de parámetros de configuración a las propias aplicaciones.

Hay dos enfoques sobre cómo puede configurar los servidores: a mano: si los configura a mano, puede obtener una situación en la que haya configurado la producción de una manera, la prueba de la otra, todo es verde en la prueba, las pruebas son verdes. Se implementa en producción y no hay un marco allí, nada funciona para usted. Otro ejemplo: tres servidores de aplicaciones se configuran a mano. Un servidor de aplicaciones se configuró de una manera, otro servidor de aplicaciones de una manera diferente. Los servidores pueden trabajar de diferentes maneras. Otro ejemplo: hubo una situación en la que un servidor Stage dejó de funcionar por completo para nosotros. Comenzamos a crear un nuevo servidor usando y después de 30 el servidor estaba listo. Otro ejemplo: el servidor simplemente dejó de funcionar. Si lo configura con sus manos, entonces debe buscar a una persona que sepa cómo configurarlo, debe presentar la documentación. Como sabemos, la documentación no es relevante. Estos son grandes problemas. Y, lo más importante, esta es una auditoría, es decir, en términos generales, tiene diez administradores, cada uno de ellos configura algo con sus manos, no está muy claro si lo configuraron correcta o incorrectamente, y cómo entender si luego la configuración, podrían poner algo superfluo, abrir algunos puertos innecesarios.

Hay una opción alternativa, esto es exactamente de lo que estamos hablando hoy, esta es la configuración del código. Es decir, tenemos un repositorio git en el que se almacena toda la infraestructura. Todos los scripts se almacenan allí, con la ayuda de los cuales lo configuraremos. Como todo esto está en git, obtenemos todos los beneficios de la gestión de código, como en el desarrollo, es decir, podemos hacer revisiones, auditorías, historial de cambios, quién hizo, por qué, comentarios, podemos retroceder. Para trabajar con el código, debe usar la tubería de ensamblaje continuo: la tubería de implementación. Para que un sistema en particular realice cambios en los servidores, es decir, no una persona haría algo con sus manos, sino que el sistema lo haría exclusivamente.

Como el sistema que realiza los cambios, utilizamos Ansible. Como no tenemos una gran cantidad de servidores, es bastante adecuado para nosotros. Si tiene 100-200 servidores allí, entonces tendrá pequeños problemas, ya que (es decir, Ansible) todavía se conecta a cada uno y los configura a su vez, esto es un problema. Es mejor usar otros medios que no empujen, sino que tiren. Pero para nuestra historia, cuando tenemos muchos proyectos, pero no más de 20 servidores, esto es muy adecuado para nosotros. Ansible tiene una gran ventaja: es un umbral de entrada bajo. Es decir, literalmente, cualquier especialista en TI en tres semanas puede dominarlo por completo. Él tiene muchos módulos. Es decir, puede administrar las nubes, las redes, los archivos, la instalación de programas, la implementación, absolutamente todo. Si no hay módulos, puede escribir los suyos, finalmente puede escribir algo utilizando el shell de Ansible o el módulo de comando.

En general, consideraremos brevemente cómo se ve generalmente esta herramienta. Ansible tiene módulos de los que ya hablé. Es decir, pueden ser entregados, escritos por ellos mismos, que están haciendo algo. Hay inventarios: aquí es donde implementaremos nuestros cambios, es decir, estos son los hosts, sus direcciones IP, variables específicas de estos hosts. Y, en consecuencia, el papel. Los roles son lo que implementaremos en estos servidores. Y también nuestros hosts están agrupados en grupos, es decir, en este caso vemos que tenemos dos grupos: el servidor de la base de datos y el servidor de aplicaciones. En cada grupo tenemos tres autos. Están conectados a través de ssh. Por lo tanto, resolvemos los problemas de los que hablamos anteriormente, que en primer lugar nuestros servidores están configurados de manera idéntica, ya que el mismo rol se aplica a los servidores. Y de la misma manera, si ejecutamos este rol en varias máquinas, para cada una funcionará de la misma manera.
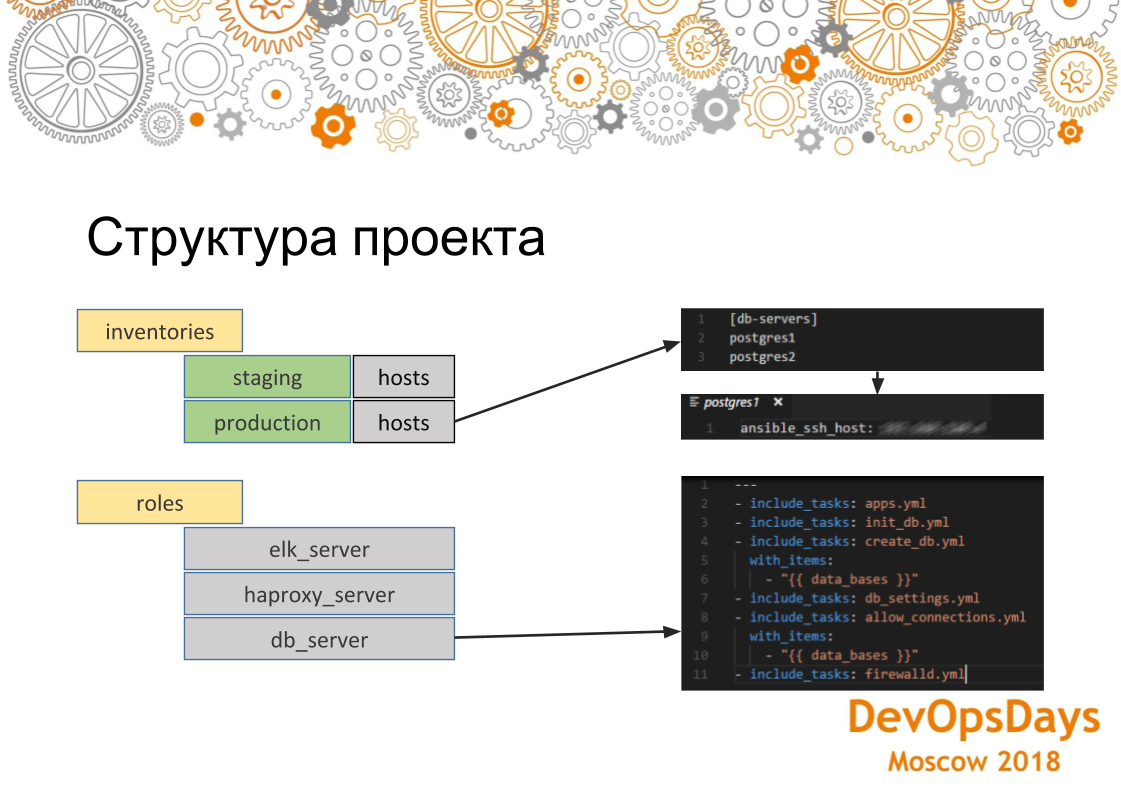
Si analizamos más a fondo cómo está estructurado el proyecto Ansible, entonces aquí vemos que los hosts son aceptables para los inventarios de producción. Este grupo está indicado y hay dos servidores en él. Si vamos a un servidor específico, vemos que la dirección IP de esta máquina se indica aquí. Allí también se pueden indicar otros parámetros: variables específicas de este entorno. Si nos fijamos en los roles. Ese rol contiene varias tareas que se realizarán. En este caso, esta es la función para instalar PostgreSQL. Es decir, instalamos la aplicación necesaria, creamos la base de datos. Aquí usamos un bucle. Ellos (bases de datos) se crearán un poco. Luego establecemos la conexión necesaria: direcciones IP que pueden iniciar sesión en esta base de datos. Y, en consecuencia, configuramos al final del firewall. La configuración se aplicará a todos los servidores del grupo.

Simplemente aborde el problema en sí: aprendimos cómo configurar el servidor usando Ansible y todo estuvo bien. Pero, como dije, tenemos muchos proyectos. Son casi todos iguales. Algunos de estos sistemas están involucrados en cada proyecto (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). Para cada uno, escribimos un papel. Podemos rodar desde el botón.

Pero tenemos muchos proyectos, y en cada uno se superponen esencialmente. Es decir, en uno de esos conjuntos, en el segundo, en el tercero. Obtenemos puntos de intersección en los que los mismos roles en diferentes proyectos.

Tenemos un repositorio con una aplicación, tenemos un repositorio con infraestructura para el proyecto. El segundo proyecto tiene exactamente lo mismo. Infraestructura continua. Y el tercero. Si implementamos lo mismo, entonces esencialmente resultará copiar y pegar. Haremos el mismo papel en 10 lugares. Entonces, si hay algún error, gobernaremos en 10 lugares.

Lo que hicimos: asumimos todos los roles que son comunes a todos los proyectos y todas sus configuraciones que vienen del exterior a un repositorio separado y los pusimos en un git en una carpeta separada, a la que llamamos Infraestructura TYME. Allí tenemos un rol para PostgreSQL, para ELK, para implementar clústeres de Kubernetes. Si necesitamos poner algún proyecto, digamos el mismo PostgreSQL, luego enciéndalo como un submódulo, reescriba los inventarios, es decir, en términos generales, la configuración en la que desempeñar este rol. No reescribimos el rol en sí: ya existe. Y con un clic de un botón, PostgreSQL aparece en todos los proyectos nuevos. Si necesita aumentar un clúster de Kubernetes, lo mismo.

Por lo tanto, resultó reducir el costo de escribir roles. Es decir, escribieron una vez, lo usaron 10 veces. Cuando el proyecto va después del proyecto, es muy conveniente. Pero dado que ahora estamos trabajando con la infraestructura como código, naturalmente necesitamos las canalizaciones de las que hablamos. Las personas se comprometen en git, pueden cometer algún tipo de incorrección: necesitamos rastrear todo esto. Por lo tanto, hemos construido tal tubería. Es decir, el desarrollador comete scripts Ansible en git. Teamity los rastrea y los transfiere a Ansible. Teamcity se necesita aquí solo por una razón: en primer lugar, tiene una interfaz visual (hay una versión gratuita de Ansible Tower - AWX, que resuelve el mismo problema - aprox. Ed.) A diferencia de Ansible gratis y, en principio, tenemos Teamcity como un solo Ci. Entonces, en principio, Ansible tiene un módulo que puede rastrear a git. Pero en este caso lo hicieron solo a imagen y semejanza. Y tan pronto como lo rastrea, transfiere todo el código a Ansible y Ansible, respectivamente, los inicia en el servidor de integración y cambia la configuración. Si se viola este proceso, entonces estamos analizando lo que está mal, por qué los scripts fueron mal escritos.

El segundo punto es que hay una infraestructura específica, aquí tenemos la infraestructura implementada por separado, la aplicación se implementa por separado. Pero hay una infraestructura específica para cada aplicación, es decir, que debe implementarse antes de lanzarla. Aquí, en consecuencia, es imposible transferirlo a una tubería diferente. Debería tener esto implementado en el mismo contenedor que la aplicación misma. Es decir, digamos, los marcos son algo popular cuando necesita instalar un marco para una nueva aplicación y colocar otro marco para otra. Así es como con esta situación. O necesitas limpiar los cachés. Por ejemplo, Ansible también puede subir, limpiar el caché.

Pero aquí usamos docker en combinación con Ansible. Es decir, nuestra infraestructura específica está en la ventana acoplable, no específica en Ansible. Entonces, compartimos este pequeño delta en Docker, todo lo demás, fundamental, en Ansible.

Un punto muy importante: si implementa la infraestructura a través de algún tipo de scripts, a través del código, si todavía tiene manipulaciones manuales del servidor, entonces esta es una vulnerabilidad potencial. Porque digamos que pones Java en el servidor de prueba, escribiste el rol ELK, lo rodaste. La implementación en la prueba fue exitosa. Implementar en producción, pero no hay Java. Y no especificó java en el script: la implementación en producción cayó. Por lo tanto, debe quitar los derechos de todos los servidores a los administradores para que no puedan rastrearlo con sus manos y realizar todos los cambios a través de git. Todo este transportador por el que pasamos nosotros. Hay una cosa, pero no apriete demasiado las tuercas. Es decir, es necesario introducir dicho proceso gradualmente. Porque todavía está sin recortar. En nuestro caso, dejamos acceso a todos los sistemas a la cabeza del administrador principal en caso de incidentes imprevistos. El acceso se otorga con la condición de que no configurará nada a mano.

¿Cómo funciona el desarrollo? Despliegue en la puesta en escena, la producción debe estar libre de errores. Algo podría romperse aquí. Si el despliegue en el entorno de integración cae constantemente en errores, será malo. Esto es similar a la depuración de aplicaciones en una máquina remota. Cuando un desarrollador desarrolla por primera vez todo en una máquina, lo compila. Si todo se compila, luego lo envía al repositorio. Utiliza el mismo enfoque. Los desarrolladores usan Visual Studio Code con complementos Ansible, Vagrant, Docker, etc. Los desarrolladores prueban su código de infraestructura en un vagabundo local. Se levanta un sistema operativo limpio. Los propios scripts para subir esta máquina también están en este repositorio con la infraestructura de la que hablamos. El desarrollador comienza a instalar un servidor FTP en él. Si algo salió mal, simplemente lo elimina, lo vuelve a cargar y nuevamente intenta instalar el software necesario utilizando scripts de implementación. Después de depurar los scripts de implementación, realiza una solicitud de fusión a la rama principal. Después de fusionar la Solicitud de fusión, el CI reenvía estos cambios al servidor de integración.

Como todos los scripts son de código, podemos escribir pruebas. Digamos que instalamos PostgreSQL. Queremos verificar si funciona o no. Para hacer esto, use el módulo de afirmación Ansible. Compare la versión instalada de PostgreSQL con la versión en los scripts. Por lo tanto, entendemos que está instalado, generalmente se está ejecutando, es la versión que esperábamos.

Vemos que la prueba pasó. Entonces nuestro libro de jugadas funcionó correctamente. Puedes escribir tantas pruebas como quieras. Son idempotentes. Idempotencia (una operación que, si se aplica a cualquier valor varias veces, siempre da como resultado el mismo valor que con una sola aplicación). Si escribe scripts gratuitos para la instalación y configuración, asegúrese de que sus scripts siempre obtengan el mismo valor si los ejecuta varias veces.

Hay otro tipo de prueba que no se relaciona directamente con las pruebas de infraestructura. Pero parecen afectarlo indirectamente. Estas son pruebas de extremo a extremo. Tenemos la infraestructura y las aplicaciones mismas están instaladas en el mismo servidor, que los probadores prueban. Si lanzamos algún tipo de infraestructura incorrecta, simplemente no pasaremos pruebas complejas. Es decir, nuestra aplicación de alguna manera funcionará incorrectamente. En este ejemplo, instalamos una nueva versión en producción: la aplicación funciona. Luego se realizó una confirmación en git y pruebas de extremo a extremo, que tienen lugar por la noche, con el seguimiento de que aquí no tenemos un archivo en ftp. Desmontamos este caso y vemos que el problema está en la configuración de ftp. Arreglamos los scripts en el código, lo implementamos nuevamente y todo se vuelve verde. La misma historia con el código. El código de infraestructura y la infraestructura se prueban indirectamente de una forma u otra. Luego podemos implementarlo en producción.

, CI (Teamcity), integration 8 10. , . , OPS ( ) . Dashboard . — , . , . , . . . , , , . : - . . Slack , - - - .

Ok, , , - , . trunk based . Master — . Master CI (Teamcity) integration . CI , integration . release candidate. . . , end-to-end , staging . production. , staging .

. ? , PostgreSQL. 5 . , . 1-2 . . , PostgreSQL . PostgreSQL , staging, production 4 . , , . , . - .

git submodule Ansible . , . git submodule Ansible . inventories , . 30 . git submodule .

: , . , , , staging , . , , , , , , staging. — , , - .

6 . — 10 . . . , . - git submodule, . . , , , . , , .

.
-, , : , Ansible git , : “ , - ”. ? git . , . 100% . . .
, . . , RabbitMQ, ELK, . , ELK . , , ELK. ELK, , ELK .
, , , , . , , , , . , . .
. , , , , , , . git. , — git, , : , - . .
, , , code review. , , . , . , , , , , . , : . . . , - - .
, .
: , git submodule, . - , latest . inventories. — , . , , .. . — . .
: - Ansible ( A B, B C A, )? , ?
: . . , - IP , , , , . . , , , , , . , - , , , RabbitMQ RabbitMQ, . - , .
PD: Sugiero que todos los interesados en Github traduzcan al texto informes interesantes de conferencias. Puedes hacer un grupo en github para traducir. Hasta ahora, lo estoy traduciendo a texto en mi cuenta de github ; también puede enviar una solicitud de extracción para corregir un artículo allí.