Hola Habr Mi nombre es Aleksey Rak, soy el desarrollador de la asistente de voz Alice en la oficina de Minsk de Yandex. Obtuve este puesto yendo aquí en el mismo equipo para una pasantía de tres meses el año pasado. Te voy a contar sobre ella. Si desea probarlo usted mismo, aquí hay un
enlace a la pasantía 2019 .

¿Cómo me instalé?
Soy un estudiante de cuarto año en BSU, en 2018 me gradué de la Escuela de Análisis de Datos, vivo y vivo en Minsk.
Primero, yo, como otros graduados de SHAD, recibí un enlace a una pasantía en 2018. Dentro de una semana después de enviar el cuestionario, fue necesario asignar tiempo, 6 horas seguidas, para completar el concurso en línea. Contenía tareas sobre la teoría de la probabilidad, la capacidad de codificar, crear algoritmos. Fue posible escribir el código en el idioma en el que sabes cómo. Escribí varias tareas en C ++, varias en Python, elegí el lenguaje dependiendo de la facilidad de uso para una tarea en particular.
Cuando envía una decisión, llega inmediatamente un veredicto, luego de lo cual la tarea puede resolverse nuevamente para obtener una respuesta más correcta. Me llevó un par de horas completar todas las tareas. No resolví algunos de los problemas en el primer intento.
Pocos días después, los reclutadores se pusieron en contacto conmigo y me pidieron una primera entrevista cara a cara en la oficina de Minsk. Fue con Alexei Kolesov, el jefe del equipo de modelos acústicos y biométricos, donde tuve que trabajar. La entrevista consistió en resolver problemas en una hoja de papel o en una pizarra y responder preguntas sobre teoría de la probabilidad, algoritmos y aprendizaje automático. Creo que los antecedentes de la programación de la Olimpiada me permitirían hacer frente al concurso en línea, incluso si no hubiera estudiado en el ShAD, pero en la entrevista, la experiencia de ShAD fue realmente útil para mí.
Unos días más tarde, tuvo lugar la segunda reunión, donde me pidieron dos tareas más sobre el conocimiento de algoritmos: calentamiento y básico. Con cada tarea era así: propuse una solución, respondí varias preguntas sobre esta solución y luego escribí el código en una hoja de papel.
Pocos días después me informaron que me aceptaron para una pasantía. Se suponía que debía durar tres meses completos (como resultado, sucedió). No prometieron cambiar a una posición permanente, pero dijeron que esa opción es posible.
Empezando
El primer día, después de resolver los problemas de organización y comprar una computadora portátil, fui a almorzar con mis colegas. Hablamos, luego armé un repositorio de equipo y tomé la primera tarea: compilar un script Python simple para comenzar a ejecutar un programa ya terminado en varios hilos y acelerar así su ejecución. En el proceso de creación del script, me familiaricé con el sistema de revisión de código, cuando otros miembros del equipo verifican su código. Sabiendo que sus colegas más cercanos tratarán con él primero y, en el futuro, con otros desarrolladores, intente escribir con mayor claridad. En la programación olímpica, todo es algo diferente: la velocidad con la que programa es importante, y lo más probable es que ni siquiera necesite ver lo que ha escrito. Por otro lado, cuando tuve que enfrentar una situación antes de Yandex de que todavía tenía que leer el código, también traté de hacerlo más o menos claro.
Durante la pasantía, resolví varias veces problemas similares a este script, pero mi tiempo principal lo dediqué a un proyecto mucho más grande: un nuevo decodificador para el observador Alice.
Para los dispositivos y aplicaciones Yandex donde se puede llamar al asistente por voz, todo funciona como el usuario espera, necesita un observador de alta calidad: un mecanismo de activación por voz. Muy a menudo, la frase de activación (que debe pronunciar para iniciar Alice) contiene la palabra "Alice" en sí.
Spotter incluye la preparación de funciones (funciones para el aprendizaje automático), una red neuronal y un decodificador.
Decodificador anterior
La versión anterior del decodificador funcionaba procesando vectores de probabilidad. Hay un modelo acústico: una red neuronal, que para cada cuadro (un fragmento de discurso que dura entre 10 y 20 milisegundos) devuelve la probabilidad de que se haya pronunciado. Los marcos pueden superponerse. El decodificador contenía una matriz con probabilidades para los últimos 100 cuadros "escuchados" por el dispositivo. El sonido de cada letra corresponde a un determinado vector de probabilidades. En el vector para la letra A, el algoritmo encontró el elemento con la probabilidad más alta, después de lo cual consideró solo la parte correcta de la matriz en relación con este elemento. Luego, la operación se repitió para las letras L, I, C y A, cada vez que la matriz fue "cortada" por el elemento encontrado. Los sonidos de A al principio y al final de la palabra son realmente diferentes: el segundo de ellos generalmente se llama Shva, parece A, E y O al mismo tiempo.
Si la probabilidad final resultó ser mayor que el valor umbral, entonces el algoritmo consideró que la palabra en realidad fue dicha y activó a Alice para el usuario.

Tal esquema condujo al hecho de que el asistente a veces se encendía espontáneamente no solo cuando la gente decía "Alicia", sino también cuando escuchaba otras palabras, por ejemplo, "Alejandro". Los sonidos en la primera parte de esta palabra ("Alex") siguen en el mismo orden y básicamente coinciden con los sonidos en la palabra "Alice". La diferencia está solo en las letras E y K, pero E en su sonido está muy cerca de I, y el algoritmo no tuvo en cuenta la presencia de la letra K.

En teoría, puede buscar en el discurso pronunciado no solo la palabra "Alice", sino también palabras similares. No hay tantos: "Alexander", "Alexa", "arrestado", "escaleras", "aristarco". Si el algoritmo creyera que el usuario con una alta probabilidad dijo uno de ellos, entonces sería posible prohibir la activación, independientemente del resultado del decodificador principal.
Sin embargo, la activación por voz debería funcionar incluso sin Internet. Por lo tanto, el decodificador es un mecanismo local. Funciona gracias a una red neuronal, que cada vez se ejecuta directamente en el dispositivo del usuario (por ejemplo, en el teléfono), sin comunicarse con los servidores Yandex. Y dado que todo sucede localmente, el rendimiento (del mismo teléfono en comparación con todo el centro de datos) deja mucho que desear. Reconocer no solo la palabra "Alice" significaría complicar significativamente el trabajo de esta pequeña red neuronal y exceder los límites de rendimiento. La activación comenzaría a funcionar más lentamente, el asistente respondería con un largo retraso.
Se necesitaba un decodificador fundamentalmente diferente. Los colegas me sugirieron que implementara la idea del Modelo Oculto de Markov, HMM: al comienzo de mi pasantía, la comunidad ya lo describía bien y también encontró aplicación en el asistente Alexa de Amazon.
Nuevo decodificador HMM
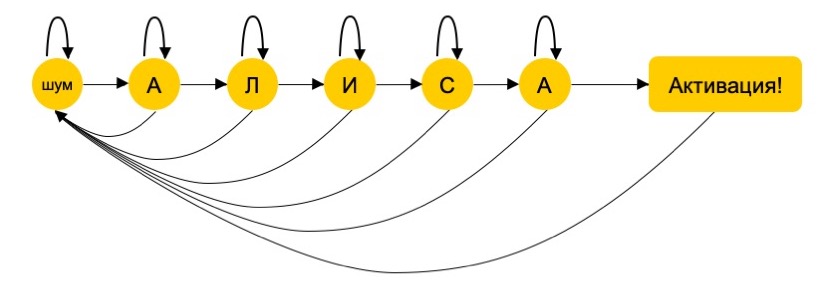
El decodificador HMM crea un gráfico de 6 vértices: uno para cada sonido en la palabra "Alice", más uno más para todos los demás sonidos: otro discurso o ruido. Las probabilidades de transiciones entre vértices se estiman en una muestra de voz grabada y anotada. Para cada sonido escuchado, se consideran 6 probabilidades: coincidir con cada una de las cinco letras y con el sexto vértice (es decir, con cualquier sonido que no sea el que se encuentra en la palabra "Alicia"). Si el usuario dice "Alexander", el decodificador caerá en K: la probabilidad de que el sonido hablado no sea parte de la frase de activación será demasiado grande y el asistente no funcionará.
En un futuro próximo, estos cambios estarán disponibles para todos los usuarios de la biblioteca Alice y SpeechKit.
Finalización de la pasantía y transición a un trabajo permanente.
De los tres meses de la pasantía, me llevó un año y medio escribir un decodificador HMM. Al final de este mes y medio, el gerente me dijo que una transición a un puesto permanente y un contrato ilimitado sería posible (aunque no garantizado) si continuaba trabajando de manera productiva. Casi al mismo tiempo, tomé unas vacaciones de dos semanas para ir al campamento de programación de la Olimpiada. Al regresar, comencé una nueva tarea: entrenar a observadores para varios dispositivos: Yandex.Phone, computadora de a bordo con Yandex.Auto y otros.
Después de un par de semanas, aproximadamente un mes antes del final de la pasantía, se realizó mi primera entrevista sobre un puesto permanente, y unos días después, el segundo, el último. Hablé con los líderes de equipos relacionados. En la primera de las entrevistas, me hicieron preguntas teóricas: sobre aprendizaje automático, redes neuronales, regresión logística, métodos de optimización. Además, preguntaron sobre la regularización, es decir, sobre la reducción del grado de reentrenamiento de un algoritmo dado y sobre qué algoritmos se aplican los métodos de regularización. La segunda entrevista fue práctica: hablamos por Skype con un colega de Moscú, y en el proceso escribí el código en un simple editor en línea.
Por mi propia iniciativa, no conseguí un trabajo a tiempo completo, pero en ¾, el hecho es que mis estudios en BSU aún no han terminado. En una posición constante, también participo en la selección automática de valores de umbral y otros hiperparámetros. En cada momento, el sistema gana la probabilidad de que se pronuncie la palabra clave "Alice". El clasificador final compara esta probabilidad con un valor umbral y, si se supera el umbral, activa a Alice. Anteriormente, el umbral fue seleccionado por los desarrolladores, la tarea actual es aprender cómo hacer esto automáticamente.
Entonces llegué a Yandex, conservando mi lugar en el equipo de Alice.