Durante el año pasado, el tema de la inteligencia cibernética o Inteligencia de amenazas ha ganado una creciente popularidad en la carrera de armas cibernéticas entre atacantes y defensores. Obviamente, obtener información de manera proactiva sobre las amenazas cibernéticas es algo muy útil, pero no protegerá la infraestructura por sí misma. Es necesario crear un proceso que ayude a gestionar correctamente tanto la información sobre el método de un posible ataque como el tiempo disponible para prepararse para él. Y la condición clave para la formación de dicho proceso es la integridad de la información sobre las amenazas cibernéticas.

Los datos primarios de Threat Intelligence se pueden obtener de una amplia variedad de fuentes. Pueden ser
suscripciones gratuitas , información de socios, un equipo de investigación técnica de la empresa, etc.
Hay tres etapas principales de trabajar con la información obtenida a través del proceso de Inteligencia de amenazas (aunque nosotros, como centro para monitorear y responder a los ataques cibernéticos, tenemos una cuarta etapa: notificar a los clientes sobre la amenaza):
- Obtención de información, procesamiento primario.
- Detección de indicadores de compromiso (Indicador de compromiso, COI).
- Verificación retrospectiva.
Adquisición de información, procesamiento primario
La primera etapa se puede llamar la más creativa. Comprender correctamente la descripción de una nueva amenaza, resaltar los indicadores relevantes, determinar su aplicabilidad a una organización específica, filtrar información innecesaria sobre los ataques (por ejemplo, dirigida específicamente a ciertas regiones), todo esto es a menudo una tarea difícil. Al mismo tiempo, hay fuentes que proporcionan datos exclusivamente verificados y relevantes que se pueden agregar a la base de datos automáticamente.
Para un enfoque sistemático del procesamiento de la información, recomendamos dividir los indicadores obtenidos en el marco de Threat Intelligence en dos grandes grupos: host y red. La detección de indicadores de red no significa un compromiso inequívoco del sistema, pero la detección de indicadores de host, como regla, señala de manera confiable el éxito de un ataque.
Los indicadores de red incluyen dominios, URL, direcciones de correo, un conjunto de direcciones IP y puertos. Los indicadores de host están ejecutando procesos, cambios en las ramas y archivos del registro, cantidades hash.
Indicadores recibidos como parte de una sola alerta de amenaza, tiene sentido combinarse en un grupo. En el caso de la detección de indicadores, esto facilita enormemente la determinación del tipo de ataque y también facilita la verificación del sistema potencialmente comprometido para todos los posibles indicadores de un informe de amenaza específico.
Sin embargo, a menudo uno tiene que lidiar con indicadores, cuya detección no nos permite hablar inequívocamente de un sistema comprometido. Estas pueden ser direcciones IP que pertenecen a grandes corporaciones y redes de alojamiento, dominios de correo de servicios de correo publicitario, nombres y sumas hash de archivos ejecutables legítimos. Los ejemplos más simples son las direcciones IP de Microsoft, Amazon, CloudFlare, que a menudo se enumeran, o procesos legítimos que aparecen en el sistema después de instalar paquetes de software, por ejemplo, pageant.exe, un agente para almacenar claves. Para evitar una gran cantidad de falsos positivos, es mejor filtrar tales indicadores, pero, digamos, no los deseche, la mayoría de ellos no son completamente inútiles. Si existe la sospecha de un sistema comprometido, se realiza una verificación completa de todos los indicadores, y la detección de incluso un indicador indirecto puede confirmar estas sospechas.
Como no todos los indicadores son igualmente útiles, en Solar JSOC utilizamos el llamado peso del indicador. Por convención, la detección del inicio de un archivo, cuya suma de hash coincide con el hash del archivo ejecutable malicioso, tiene un peso umbral. La detección de dicho indicador conduce instantáneamente a la ocurrencia de un evento de seguridad de la información. Un solo acceso a la dirección IP de un host potencialmente peligroso en un puerto no específico no conducirá a un evento IB, pero caerá en un perfil especial que acumula estadísticas, y la detección de nuevas llamadas también conducirá a una investigación.
Al mismo tiempo, existen mecanismos que nos parecieron razonables en el momento de la creación, pero que finalmente se reconocieron como ineficaces. Por ejemplo, inicialmente se estableció que ciertos tipos de indicadores tendrán una vida útil limitada, después de lo cual se desactivarán. Sin embargo, como lo ha demostrado la práctica, cuando se conecta a una nueva infraestructura, a veces se encuentran hosts que han estado infectados con varios tipos de malware durante años. Por ejemplo, una vez al conectar a un cliente, se detectó el virus de Corkow en la máquina del jefe del servicio de IS (los indicadores tenían más de cinco años en ese momento), y una investigación posterior reveló una puerta trasera explotada y un keylogger en el host.
Detección de indicadores de compromiso.
Trabajamos con muchas instalaciones de varios sistemas SIEM, sin embargo, la estructura general de los registros que caen en la base de datos de indicadores está estandarizada y se ve así:
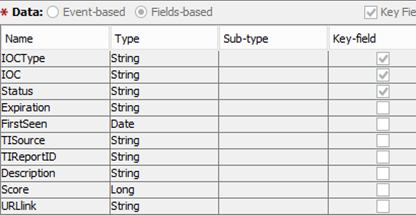
Por ejemplo, al ordenar los indicadores por TIReportID, puede encontrar todos los indicadores que aparecieron en la descripción de una amenaza específica, y al hacer clic en el enlace URL puede obtener una descripción detallada de la misma.
Al construir el proceso de Inteligencia de amenazas, es muy importante analizar los sistemas de información conectados al SIEM en términos de su utilidad para identificar indicadores de compromiso.
El hecho es que la descripción del ataque generalmente incluye varios tipos de indicadores de compromiso, por ejemplo, la cantidad hash del malware, la dirección IP del servidor SS que está activando, y así sucesivamente. Pero si las direcciones IP a las que accede el host son monitoreadas por muchos medios de protección, entonces la información sobre las cantidades de hash es mucho más difícil de obtener. Por lo tanto, consideramos todos los sistemas que pueden servir como fuente de cualquier registro desde el punto de vista de qué indicadores pueden rastrear:
Tipo de indicador
| Tipo de fuente
|
Dominio
| Servidores proxy, NGFW, servidores DNS
|
URL
|
Zócalo
| Proxies, NGFW, FW
|
Mail
| Servidores de correo, antispam, DLP
|
Proceso
| Registros del host, DB AVPO, Sysmon
|
Registro
| Registros del anfitrión
|
Hash sum
| Registros del host, DB AVPO, Sysmon, Sandboxes CMDB
|
Esquemáticamente, el proceso de detección de indicadores de compromiso se puede representar de la siguiente manera:

Ya hablé sobre los primeros dos puntos anteriores, ahora un poco más sobre la verificación de la base de datos del COI. Por ejemplo, tomaremos los eventos que contienen información sobre direcciones IP. La regla de correlación para cada evento lleva a cabo cuatro posibles comprobaciones en función de los indicadores:

La búsqueda se lleva a cabo mediante indicadores relevantes del tipo Socket, mientras que el diseño general de la dirección IP y el puerto correspondiente se verifica para verificar el cumplimiento del indicador. Porque En la información sobre la amenaza, el puerto específico no siempre se indica, la IP: cualquier construcción comprueba la presencia de una dirección con un puerto indefinido en la base de datos.
Se implementa un diseño similar en una regla que detecta indicadores de compromiso en los eventos de cambio de registro. En la información entrante, a menudo no hay datos sobre una clave o valor en particular, por lo tanto, cuando se ingresa un indicador en la base de datos, los datos que se desconocen o no tienen un valor exacto se reemplazan con 'cualquiera'. Las opciones de búsqueda final son las siguientes:

Habiendo encontrado el indicador de compromiso en los registros, la regla de correlación crea un evento de correlación marcado con la categoría que procesa la regla de incidente (discutimos esto en detalle en el artículo "
Cocina DERECHA ").
Además de la categoría, el evento de correlación se complementará con información sobre en qué alerta o informe apareció este indicador, su peso, datos de amenazas y un enlace a la fuente. El procesamiento posterior de eventos de detección de indicadores de todo tipo se realiza mediante la regla de incidentes. Su trabajo se puede presentar esquemáticamente de la siguiente manera:

Pero, por supuesto, debe tener en cuenta las excepciones: en casi cualquier infraestructura hay dispositivos cuyas acciones son legítimas, a pesar de que contienen formalmente signos de un sistema comprometido. Dichos dispositivos a menudo incluyen cajas de arena, varios escáneres, etc.
La necesidad de correlacionar los eventos de detección de indicadores de diferentes tipos también se debe al hecho de que los indicadores heterogéneos suelen estar presentes en la información sobre amenazas.
En consecuencia, una agrupación de eventos de detección de indicadores puede permitirle ver toda la cadena de ataque desde el momento de la penetración hasta la operación.
Proponemos considerar la implementación de uno de los siguientes escenarios como un evento de seguridad de la información:
- Detección de un indicador de compromiso altamente relevante.
- Detección de dos indicadores diferentes de un informe.
- Alcanzando el umbral.
Con las dos primeras opciones, todo está claro, y la tercera es necesaria cuando no tenemos más datos que la actividad de red del sistema.
Verificación retrospectiva de indicadores de compromiso
Después de recibir información sobre la amenaza, identificar los indicadores y organizar su identificación, es necesario realizar una verificación retrospectiva que le permita detectar un compromiso que ya ha ocurrido.
Si profundizo un poco más en cómo funciona esto en SOC, puedo decir que este proceso requiere una cantidad de tiempo y recursos verdaderamente colosales. La búsqueda de indicadores de compromiso en los registros durante medio año nos obliga a mantener una cantidad impresionante de ellos disponibles para cheques en línea. Además, el resultado de la verificación no solo debe ser información sobre la presencia de indicadores, sino también datos generales sobre el desarrollo del ataque. Al conectar nuevos sistemas de información del cliente, los datos de ellos también deben verificarse en busca de indicadores. Para esto, es necesario refinar constantemente el llamado "contenido" de SOC: reglas de correlación e indicadores de compromiso.
Para el sistema ArcSight SIEM, incluso una búsqueda de este tipo en las últimas semanas puede llevar mucho tiempo. Por lo tanto, se decidió aprovechar las tendencias.
"Una tendencia es un recurso de ESM que define cómo y durante qué período de tiempo se agregarán y evaluarán los datos para determinar las tendencias o corrientes predominantes. Una tendencia ejecuta una consulta específica en un horario definido y duración de tiempo ".
ESM_101_Guide
Después de varias pruebas en sistemas cargados, se desarrolló el siguiente algoritmo para usar tendencias:

Las reglas de creación de perfiles que completan las hojas activas correspondientes con datos útiles le permiten distribuir la carga total en el SIEM. Después de recibir los indicadores, las solicitudes se crean en las hojas y tendencias correspondientes, en función de los informes que se realizarán, que a su vez se distribuirán en todas las instalaciones. De hecho, solo queda ejecutar informes y procesar los resultados.
Vale la pena señalar que el proceso de procesamiento puede mejorarse y automatizarse continuamente. Por ejemplo, hemos introducido una plataforma para almacenar y procesar indicadores de compromiso MISP, que actualmente cumple con nuestros requisitos de flexibilidad y funcionalidad. Sus análogos están ampliamente representados en el mercado de código abierto - YETI, extranjero - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, Russian - TI.Platform, R-Vision Threat Intelligence Platform. Ahora estamos realizando pruebas finales de descarga automatizada de eventos directamente desde la base de datos SIEM. Esto acelerará en gran medida la notificación de indicadores de compromiso.
El elemento principal de la inteligencia cibernética.
Sin embargo, el eslabón final en el procesamiento tanto de los indicadores como de los informes son ingenieros y analistas, y las herramientas mencionadas anteriormente solo ayudan a tomar decisiones. En nuestro país, el grupo de respuesta es responsable de agregar indicadores, y el grupo de monitoreo es responsable de la exactitud de los informes.
Sin personas, el sistema no funcionará lo suficiente; no se pueden prever todas las pequeñas cosas y excepciones. Por ejemplo, observamos llamadas a las direcciones IP de los nodos TOR, pero en los informes para el cliente compartimos la actividad del host comprometido y el host en el que simplemente se instaló el navegador TOR. Es posible automatizarlo, pero es bastante difícil pensar en todos estos puntos de antemano al configurar las reglas. Resulta que el grupo de respuesta, de acuerdo con varios criterios, elimina los indicadores que crearán una gran cantidad de falsos positivos. Y viceversa: se puede agregar un indicador específico que sea muy relevante para algunos clientes (por ejemplo, el sector financiero).
El grupo de monitoreo puede eliminar la actividad de la caja de arena del informe final, verificar que los administradores bloqueen con éxito un recurso malicioso, pero agregar actividad sobre el escaneo externo sin éxito, mostrando al cliente que los atacantes verifican su infraestructura. La máquina no tomará tales decisiones.

En lugar de salida
¿Por qué recomendamos este método de trabajar con Threat Intelligence? En primer lugar, te permite alejarte del esquema, cuando para cada nuevo ataque necesitas crear una regla de correlación separada. Esto lleva un tiempo inaceptablemente largo y revela solo el ataque en curso.
El método descrito aprovecha al máximo las capacidades de TI: solo necesita agregar indicadores, y esto es un máximo de 20 minutos desde el momento en que aparecen, y luego realizar una verificación retrospectiva completa de los registros. Por lo tanto, reducirá el tiempo de respuesta y obtendrá resultados de prueba más completos.
Si tiene alguna pregunta, bienvenido a comentar.