El año pasado, hubo una ola de artículos sobre fiestas en Silicon Valley en la prensa rusa y ucraniana, con cierta atmósfera de Hollywood, pero sin especificar nombres específicos, fotos y sin describir el desarrollo de hardware y las tecnologías de escritura de software asociadas con estos nombres. ¡Este artículo es diferente! También tendrá multimillonarios, genios y chicas, pero con fotos, diapositivas, diagramas y fragmentos de código de programa. Entonces
El otro día, el alcalde de Campbell, con el nombre ruso Paul Resnikoff, cortó el listón en la apertura de la nueva oficina de inicio de Wave Computing, que, junto con Broadcom, está desarrollando un chip de 7 nanómetros para acelerar el cálculo de las redes neuronales. La oficina está ubicada en el edificio de la histórica fábrica de frutas y conservas de finales del siglo XIX y principios del XX, cuando Silicon Valley era el huerto más grande del mundo. Incluso entonces, la oficina se dedicó a la innovación, introdujo los primeros motores eléctricos para transportadores de la industria de la ciruela albaricoque, para los que trabajaban unos 200 empleados, principalmente mujeres.
En la fiesta que siguió al corte de la cinta, se destacó a muchas personas famosas de la industria, incluido el compañero de armas de Kernigan-Richie y autor del compilador de C más popular de finales de los 70 y principios de los 80, Stephen Johnson, uno de los autores del estándar de números de punto flotante Jerome Kunen, inventor conceptos de bus local y el primer desarrollador de chipset PC AT Diosdado Banatao, ex desarrolladores de procesadores Sun, DEC, Cyrix, Intel, AMD y Silicon Graphics, chips Qualcomm, Xilinx y Cypress, analistas industriales, una niña con cabello rojo y otros habitantes de California Compañía de este tipo.
Al final de la publicación, hablaremos sobre qué libros leer y qué ejercicios hacer para unirse a esta comunidad.
Comencemos con Jerome Kunen, un innovador en aritmética de coma flotante y gerente de Apple desde el primer Macintosh.
Disertaciones de candidatos no son tan comunes que afectan la informática en miles de millones de dispositivos. Esto es en lo que se convirtió el Diser de Jerome Kunen (Contribuciones a un Estándar Propuesto para Aritmética de Punto Flotante Binario), cuyos resultados están incluidos en los números de punto flotante del Estándar 754 de IEEE. Después de graduarse de la escuela de posgrado de Berkeley en 1982, Jerome fue a trabajar a Apple, donde introdujo la biblioteca de coma flotante en el primer Macintosh.
Después de 10 años de gestión en Apple, Kunen asesoró a Hewlett-Packard y Microsoft, y en 2000 optimizó la aritmética de 128 bits para la nueva versión x86 de 64 bits de AMD. Jerome recientemente dirigió su atención a la investigación sobre estándares de punto flotante para redes neuronales, en particular disputas sobre Unum y Posit. Unum es el nuevo estándar propuesto, promovido por el científico de Caltech John Gustafson, autor del ahora ruidoso libro The End of Error, "The End of Error". Posit es una versión de Unum que se puede implementar de manera más eficiente (*) que Unum en hardware.
(*) Más eficiente en combinación de parámetros: frecuencia de reloj, número de ciclos por operación, rendimiento del transportador, área relativa en el chip y consumo de energía relativo.

Imágenes de artículos (no de Jerome)
Hacer que las matemáticas de punto flotante sean altamente eficientes para el hardware de IA y
Beating Floating Point en su propio juego: Posit Aritmetic de John L. Gustafson e Isaac Yonemoto :

Pero en la fiesta, Stephen / Steve Johnson es la persona en cuyo compilador se ha popularizado el lenguaje de programación C. El primer compilador de C fue escrito por Denis Ritchie, pero el compilador de Richie estaba estrechamente vinculado a la arquitectura PDP-11. Steve Johnson, basado en el trabajo de Alan Snyder, escribió a mediados de la década de 1970 el Compilador de C portátil (PCC), que fue fácil de rehacer para generar código para diferentes arquitecturas. Al mismo tiempo, el compilador de Johnson funcionó rápidamente y estaba optimizando. ¿Cómo logró esto?
En la entrada de PCC, Steve Johnson utilizó el analizador LALR (1) generado por YACC (Yet Another Compiler Compiler), también escrito por Steve Johnson. Después de eso, la tarea de compilación se redujo a manipular árboles en funciones recursivas y generar código a partir de la tabla de plantillas. Algunas de estas funciones recursivas eran independientes de la máquina, la otra parte fue escrita por personas que transfirieron PCC a otra máquina. La tabla de plantilla constaba de entradas de reglas del tipo "si un registro de tipo A y dos registros de tipo B están libres, reconstruya el árbol en un nodo de tipo C y genere código con una cadena D". La mesa dependía de la máquina.
Debido a la combinación de elegancia, flexibilidad y eficiencia, el compilador PCC se transfirió a más de 200 arquitecturas, desde PDP, VAX, IBM / 370, x86 hasta el BESM-6 soviético y Orbit 20-700 (una computadora a bordo en las primeras versiones del MiG-29). Según Denis Ritchie, casi todos los compiladores de C de principios de la década de 1980 se basaban en PCC. Desde el mundo BSD Unix, PCC fue reemplazado como el compilador GNU GCC estándar en 1994.
Además de PCC y Yacc, Steve Johnson también es el autor del programa original de verificación del programa Lint (ver, por ejemplo, el
artículo de 1978 ). Los nombres de los programas Yacc y Lint se han convertido en sustantivos comunes. En la década de 2000, Steve reescribió el front-end de MATLAB y escribió MLint. Ahora, Steve Johnson está ocupado con la tarea de paralelizar los algoritmos para calcular redes neuronales en dispositivos como CGRA (arquitectura reconfigurable de grano grueso), con decenas de miles de elementos tipo procesador que se abarcan mediante tensores a través de una red de decenas de miles de interruptores dentro de un chip masivo con miles de millones de transistores:

Pero con una copa de vino, el multimillonario Diosdado Banatao, fundador de Chips & Technologies, S3 Graphics e inversor en Marvell. Si programó una PC IBM en 1985-1988, cuando aparecieron por primera vez en la URSS, entonces puede saber que dentro de la mayoría de los gráficos AT-shek con EGA y VGA había chips de Chips & Technologies, que salieron simultáneamente con los de IBM. Los primeros conjuntos de chips C&T fueron diseñados por Banatao, que había aprendido a ser ingeniero electrónico en Stanford, y antes de que Stanford trabajara como ingeniero en Boeing. En 1987, Intel adquirió Chips & Technologies.


A la izquierda en la imagen de abajo está John Bourgoin, presidente de MIPS Technologies desde su apogeo en la década de 2000, cuando los chips con núcleos MIPS estaban dentro de la mayoría de los reproductores de DVD, cámaras digitales y televisores, con conjuntos de chips de Zoran, Sigma Design, Realtek, Broadcom y otras compañías. Antes de esto, John fue presidente de MIPS Silicon Graphics desde 1996, cuando los procesadores de MIPS estaban dentro de las estaciones de trabajo de Silicon Graphics que Hollywood usó para rodar las primeras películas realistas en 3D de Jurassic Park. Antes de Silicon Graphics, John fue uno de los vicepresidentes de AMD desde 1976.
Art Swift, derecha, fue vicepresidente de marketing de MIPS en la década de 2000, y antes de eso en la década de 1980 trabajó como ingeniero en Fairchild Semiconductor (sí, ese), luego vicepresidente de marketing en Sun, DEC, Cirrus Logic y Presidente de Transmet. Recientemente, Art ha sido el vicepresidente del comité de marketing de RISC-V y ha estado familiarizado con Syntacore y CloudBear en Rusia en este puesto. Y ahora se ha convertido en el presidente de la IP MIPS de Wave:

Las diapositivas de la
presentación sobre la historia de MIPS relacionadas con el período en que John Bourgoin controlaba el MIPS, en la imagen de arriba a la izquierda:

La compañía Transmet, cuyo presidente fue Art Swift durante algún tiempo, en la imagen de arriba a la derecha, lanzó el procesador Crusoe a fines de la década de 1990, que podía seguir las instrucciones x86 y llegó al mercado en las computadoras portátiles Toshiba Libretto L, NEC y Sharp. , cliente ligero de Compaq. Su ventaja competitiva sobre Intel y AMD se estableció en un bajo consumo de energía controlado.
La implementación directa y la verificación de la suite completa x86 es una tarea muy costosa, por lo que Transmeta fue al revés, lo que se asemeja a la ruta de la empresa rusa MTsST con el procesador Elbrus (la línea que comenzó con Elbrus 2000 y ahora se presenta como Elbrus 8C). Transmeta y Elbrus se basaron en un procesador estructuralmente simple con una microarquitectura VLIW, y el nivel de emulación x86 funcionó con la tecnología que Transmeta denominó transformación de código.
La idea de VLIW (Very Long Instruction Word) es bastante simple: varias instrucciones de procesador se declaran explícitamente como una súper instrucción y se ejecutan en paralelo. A diferencia de los procesadores superescalares, en particular Intel, que comienza con PentiumPro (1996), en el que el procesador selecciona varias instrucciones de la memoria y luego decide qué ejecutar en paralelo y qué secuencialmente, según un análisis automático de dependencias entre instrucciones.
Un procesador superescalar es mucho más complicado que VLIW, porque un superescalar tiene que gastar la lógica en mantener la ilusión de un programador de que todas las instrucciones seleccionadas se ejecutan una tras otra, aunque en realidad puede haber docenas de ellas dentro del procesador, en diferentes etapas de ejecución. En el caso de VLIW, la carga de mantener tal ilusión recae en el compilador de un lenguaje de alto nivel. En última instancia, el circuito VLIW se interrumpe cuando el procesador tiene que trabajar con una memoria caché multinivel, que tiene retrasos impredecibles que dificultan que el compilador programe instrucciones de reloj. Pero para los cálculos matemáticos (por ejemplo, poner a Elbrus en el radar y calcular el movimiento del objetivo) esta es la cuestión, especialmente en condiciones de escasez de personal de ingeniería calificado (más personas necesitan verificar el superescalar).
Ilustración de la idea VLIW, el procesador Crusoe y la subportátil Toshiba Libretto L1:

Y aquí, en el centro, en la foto de abajo Derek Meyer, Derek Meyer, actual CEO de Wave Computing. Antes de Wave, Derek era CEO de ARC, un desarrollador de núcleos de procesador ARC que se utilizan en chips de audio. Estos núcleos tenían
licencia en ese momento
, incluida la compañía rusa NIIMA Progress , que luego autorizó los núcleos MIPS y
mostró chips basados en ellos en una exposición en Kazan Innopolis . Derek Meyer ha viajado repetidamente a Rusia, a San Petersburgo, donde se encontraba el equipo de desarrollo de Virage Logic. En 2009, ARC adquirió Virage Logic, y en 2010, Synopsys, la compañía líder mundial en diseño de chips, adquirió ARC.
A la derecha de la foto,
Sergey Vakulenko , quien en los albores de su carrera se encontraba en los orígenes de Runet, trabajó en la cooperativa Demos y el Instituto Kurchatov, que trajo Internet a la URSS. Ahora Sergey está escribiendo un modelo con precisión de ciclo del elemento del procesador Wave para computar redes neuronales, y anteriormente escribió modelos con precisión de instrucción de núcleos MIPS que se usaron para verificar los núcleos de procesador MIPS I6400 Samurai, I7200 Shaolin y otros.

Aquí están Vadim Antonov y Sergey Vakulenko en 1990, con la primera computadora en la URSS conectada a Internet:

Y aquí está Larry Hudepohl a la derecha (¿Hüdepol está escrito en ruso?). Larry comenzó su carrera en Digital Equipment Corporation (DEC) como diseñador de procesadores para MicroVAX. Luego, Larry trabajó para una pequeña empresa, Cyrix, que a fines de la década de 1980 desafió a Intel e hizo un coprocesador FPU que era compatible con Intel 80387 y era un 50% más rápido. Luego, Larry diseñó chips MIPS en Silicon Graphics. Cuando MIPS Technologies se separó de Silicon Graphics, Larry y Ryan Quinter lanzaron juntos el primer producto independiente de MIPS, MIPS 4K, que se convirtió en la columna vertebral de la línea que dominaba la electrónica doméstica de los años 2000 (reproductores de DVD, cámaras, televisores digitales). Luego, MIPS 5K voló al espacio: fue utilizado por la agencia espacial japonesa JAXA. Luego, Larry, como vicepresidente de ingeniería de hardware, dirigió el desarrollo de las siguientes líneas, y ahora está trabajando en nuevas arquitecturas de aceleradores Wave.

La nave espacial japonesa, orgullosamente llamada Hayabusa-2 (Sapsan-2), que
aterrizó en la superficie del asteroide Ryugu el año pasado , está controlada por el procesador HR5000 basado en el núcleo del procesador MIPS 5Kf, que ha sido licenciado por mucho tiempo por MIPS Technologies.
Aquí hay una tubería serial simple del núcleo del procesador MIPS 5Kf de 64 bits de su
hoja de datos :

Justo en la foto: Darren Jones, Darren Jones. Fue el director de ingeniería de hardware en MIPS, quien dirigió el desarrollo de núcleos complejos, con subprocesos múltiples de hardware y superescalares con ejecución extraordinaria de instrucciones. Luego, Darren fue a Xilinx, donde estuvo involucrado en Xilinx Zynq - chips, en el cual se encuentra una combinación de FPGA y procesadores ARM. Darren ahora es vicepresidente de ingeniería en Wave.
En MIPS, Darren era el líder de un grupo cuyos miembros luego trabajaron para Apple y Samsung. La diseñadora Mónica, que fue a Samsung, una vez me dijo una frase que recordaba bien: "Diseño RTL: algunos principios simples y el resto es trampa" (desarrollo de equipos a nivel de transferencias de registros: algunos principios simples, todo lo demás es muhlezh ") Un ejemplo canónico de un muhlezh es un caché (el programa escribió datos y los leyó, pero solo se recordará más adelante), pero este es solo un caso muy especial de lo que Mónica pudo hacer.

El subprocesamiento múltiple de hardware y un superescalar extraordinario son dos enfoques diferentes para mejorar el rendimiento del procesador. El subprocesamiento múltiple de hardware le permite aumentar el rendimiento sin mucho consumo de energía, pero con una programación no trivial. El superescalar le permite ejecutar programas de un solo subproceso aproximadamente el doble de rápido, pero también gasta el doble de vatios. Pero sin trucos en programación.
Finalmente, el subprocesamiento múltiple de hardware se explicó bien en la Wikipedia rusa, aquí está su
subprocesamiento múltiple
temporal (se implementa en MIPS interAptiv y MIPS I7200 Shaolin), pero el
subprocesamiento múltiple
simultáneo (se realizó en procesadores DEC Alpha en la década de 1990, luego en SPARC y luego en MIPS I6400 Samurai / I6500 Daimyo).
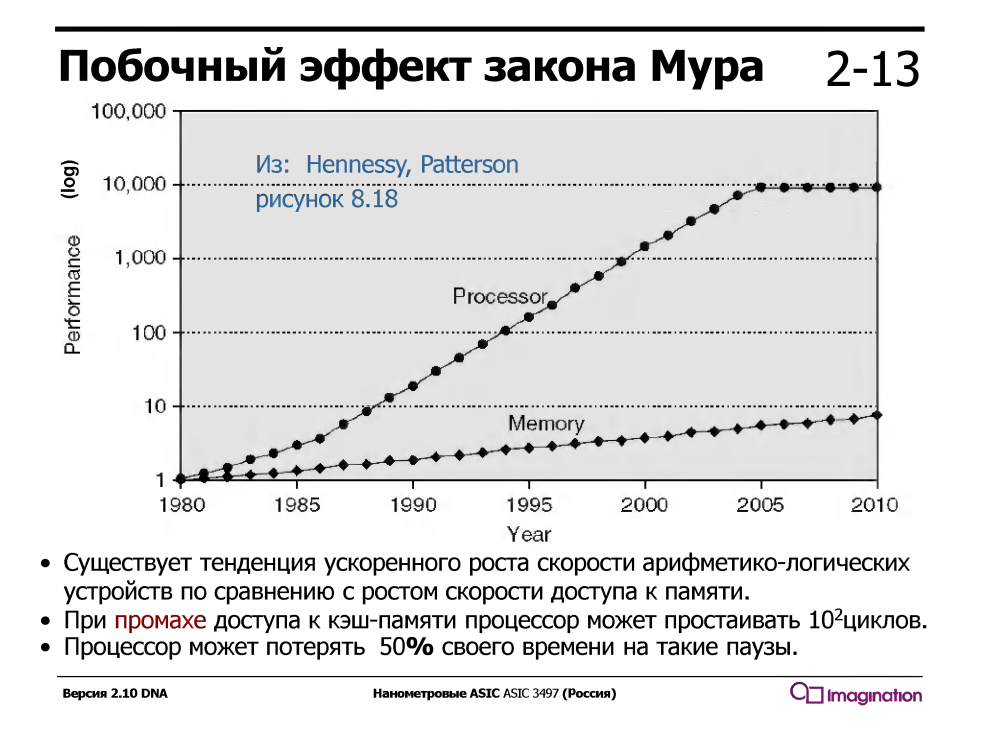
El subprocesamiento múltiple temporal explota el hecho de que un procesador con una tubería serie convencional está inactivo / esperando la mitad del tiempo de ejecución. ¿A qué está esperando? Datos que pasan por cachés desde la memoria. Y espera mucho tiempo: mientras espera una falla de caché, el procesador podría ejecutar docenas o incluso cien o dos instrucciones aritméticas simples como la suma.
Este no fue siempre el caso: en la década de 1960, los dispositivos aritméticos eran mucho más lentos que la memoria. Pero desde aproximadamente 1980, la velocidad de los núcleos del procesador ha crecido mucho más rápido que la velocidad de la memoria, e incluso la aparición de cachés de varios niveles en los procesadores resolvió el problema solo parcialmente.
Los procesadores con subprocesamiento múltiple temporal admiten varios conjuntos de registros, uno para cada subproceso, y cuando el subproceso actual está esperando datos de la memoria durante una falta de caché, el procesador cambia a otro subproceso. Esto ocurre instantáneamente, en un ciclo, sin interrupciones y miles de ciclos del controlador de interrupciones, que se activa durante el subprocesamiento múltiple de software (no hardware).
Aquí está la idea de múltiples subprocesos
en las diapositivas de los talleres de Charles Danchek , profesor de la Universidad de California Santa Cruz, Extensión de Silicon Valley. ¿Por qué en ruso? Debido a que Charles Danchek dio conferencias en MISiS de Moscú, y luego en el ITMO de San Petersburgo y el KPI de Kiev:


Curiosamente, el hardware multihilo se puede programar simplemente en C. Así es como se ve:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
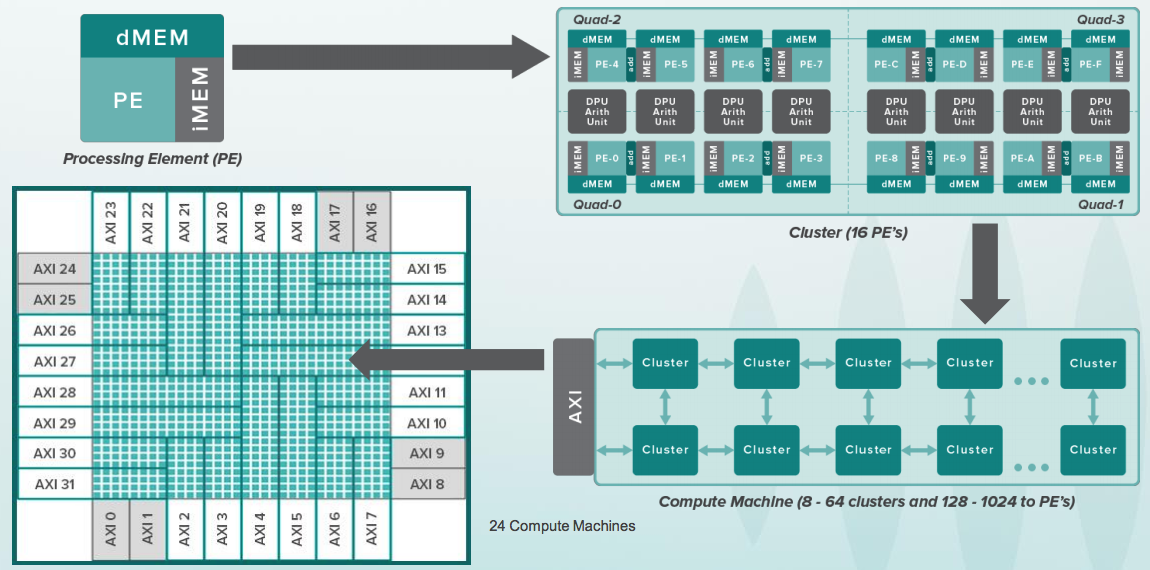
Aquí del lado de la fiesta está el dispositivo Wave para centros de datos. Todavía no funciona completamente, aunque los chips están disponibles para algunos clientes como parte del programa beta:

¿Qué hace este dispositivo? ¿Sabes programar en Python? Aquí en Python, puede construir usando la biblioteca TensorFlow que se llama el llamado Gráfico de flujo de datos (DFG). Las redes neuronales son esencialmente gráficos especializados con operaciones en matrices. En el grupo de software Wave, parte del cual está dirigido por Steve Johnson, hay un compilador con un subconjunto de la representación de Google TensorFlow en los archivos de configuración para los chips de este dispositivo. Después de la configuración, puede hacer el cálculo de tales gráficos muy rápidamente. El dispositivo está diseñado para centros de datos, pero el mismo principio se puede aplicar a chips pequeños, incluso dentro de dispositivos móviles, por ejemplo, para el reconocimiento facial:

Chijioke Anyanwu (izquierda): durante muchos años ha sido el custodio de todo el sistema de prueba central del procesador MIPS. Baldwyn Chieh (centro) es el diseñador de la nueva generación de elementos tipo procesador en Wave. Baldwin solía ser un diseñador senior en Qualcomm. Aquí están las
diapositivas sobre el dispositivo Wave de la conferencia HotChips :


La IA de innovación digital de nanómetros de cada compañía de Silicon Valley debe tener su propia chica con cabello brillante. Aquí hay una chica así en Wave. Se llama Athena, es socióloga por educación y trabaja en la oficina de la oficina:

Y así es como se ve la oficina desde el exterior, y tiene más de un siglo de historia desde el momento en que era una fábrica de conservas innovadora:


Y ahora la pregunta es: ¿cómo entender la arquitectura, la microarquitectura, los circuitos digitales, los principios de diseño de chips AI y participar en tales fiestas? La forma más fácil es estudiar el libro de texto "Circuitos digitales y arquitectura de computadoras" de David Harris y Sarah Harris, e ir a Wave Computing para el pasante de verano (se planea contratar 15 pasantes para el verano). Espero que esto también se pueda hacer en empresas microelectrónicas rusas que se dedican a desarrollos similares: ELVIS, Milander, Baikal Electronics, IVA Technologies y muchos otros. En Kiev, esto se puede hacer teóricamente en la compañía Melexis, que coopera con el KPI.
El otro día hubo una versión nueva y finalmente corregida del libro de texto Harris & Harris, que debería estar disponible aquí
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , pero este enlace no funciona para mí, y cuando lo haga, escribiré una publicación separada al respecto. Con las preguntas formuladas durante las entrevistas en Apple, Intel, AMD, y en qué páginas de este libro de texto (y otras fuentes) puede ver las respuestas.