Hace algún tiempo, bajo la marca VTB, tres grandes bancos se fusionaron: VTB, ex-VTB24 y ex-Bank of Moscow. Para los observadores externos, el banco VTB combinado ahora funciona como un todo, pero desde el interior, todo parece mucho más complicado. En esta publicación, hablaremos sobre los planes para crear una red unificada del banco VTB integrado, compartir trucos para organizar la interacción de los cortafuegos, conectar y combinar segmentos de red sin interrumpir los servicios.
Dificultades en la interacción de infraestructuras dispares.
Las operaciones de VTB están actualmente respaldadas por tres infraestructuras heredadas: el ex Banco de Moscú, el ex VTB24 y el propio VTB. Las infraestructuras de cada uno de ellos tienen su propio conjunto de perímetros de red, en cuyo borde hay equipos de protección. Una de las condiciones para integrar las infraestructuras a nivel de red es la existencia de una estructura de direccionamiento IP consistente.
Inmediatamente después de la fusión, comenzamos a alinear los espacios de direcciones, y ahora está a punto de completarse. Pero el proceso lleva tiempo y es rápido, y los plazos para organizar el acceso cruzado entre infraestructuras eran muy ajustados. Por lo tanto, en la primera etapa, conectamos las infraestructuras de los diferentes bancos entre sí en la forma en que están, a través de los cortafuegos para varias zonas de seguridad principales. De acuerdo con este esquema, para organizar el acceso de un perímetro de red a otro, es necesario enrutar el tráfico a través de muchos firewalls y otros medios de protección, difundir en las direcciones conjuntas de recursos y usuarios utilizando las tecnologías NAT y PAT. Además, todos los firewalls en los cruces están reservados tanto local como geográficamente, y esto siempre debe tenerse en cuenta al organizar interacciones y construir cadenas de servicios.
Tal esquema es bastante funcional, pero ciertamente no puede llamarlo óptimo. Hay problemas técnicos y organizativos. Es necesario coordinar y documentar las interacciones de muchos sistemas cuyos componentes están dispersos en diferentes infraestructuras y zonas de seguridad. Al mismo tiempo, en el proceso de transformación de las infraestructuras, es necesario actualizar rápidamente esta documentación para cada sistema. La realización de este proceso carga en gran medida nuestro recurso más valioso: especialistas altamente calificados.
Los problemas técnicos se expresan en la multiplicación del tráfico en los enlaces, la gran carga de herramientas de seguridad, la complejidad de organizar las interacciones de red, la incapacidad de crear algunas interacciones sin la traducción de direcciones.
El problema de la multiplicación del tráfico surge principalmente debido a las muchas zonas de seguridad que interactúan entre sí a través de firewalls en diferentes sitios. Independientemente de la ubicación geográfica de los propios servidores, si el tráfico va más allá del perímetro de la zona de seguridad, pasará por una cadena de características de seguridad que pueden estar en otras ubicaciones. Por ejemplo, tenemos dos servidores en un centro de datos, pero uno en el perímetro de VTB y el otro en el perímetro de la red ex-VTB24. El tráfico entre ellos no va directamente, sino que pasa a través de 3-4 firewalls que pueden estar activos en otros centros de datos, y el tráfico se enviará al firewall y regresará varias veces a través de la red troncal.
Para garantizar una alta confiabilidad, necesitamos cada firewall en 3-4 copias: dos en un sitio en forma de clúster HA y uno o dos firewalls en otro sitio, a los cuales se cambiará el tráfico si se interrumpe el clúster de firewall principal o el sitio en su conjunto.
Resumimos Tres redes independientes son un
montón de problemas : complejidad excesiva, la necesidad de equipos costosos adicionales, cuellos de botella, dificultades de redundancia y, como resultado, altos costos para operar la infraestructura.
Enfoque de integración general
Dado que decidimos asumir la transformación de la arquitectura de red, comenzaremos con las cosas básicas. Vayamos de arriba a abajo, comenzaremos analizando los requisitos de la empresa, los solicitantes, los ingenieros de sistemas y el personal de seguridad.
- Según sus necesidades, diseñamos la estructura objetivo de las zonas de seguridad y los principios de interconexión entre estas zonas.
- Imponemos esta estructura de zonas en la geografía de nuestros principales consumidores: centros de datos y grandes oficinas.
- A continuación, formamos la red de transporte MPLS.
- Debajo, ya traemos la red primaria que proporciona servicios a la capa física.
- Seleccionamos ubicaciones para la colocación de módulos de borde y módulos de firewall.
- Una vez que la imagen objetivo se vuelve clara, trabajamos y aprobamos la metodología para la migración de la infraestructura existente a la infraestructura objetivo para que el proceso sea transparente para los sistemas de trabajo.
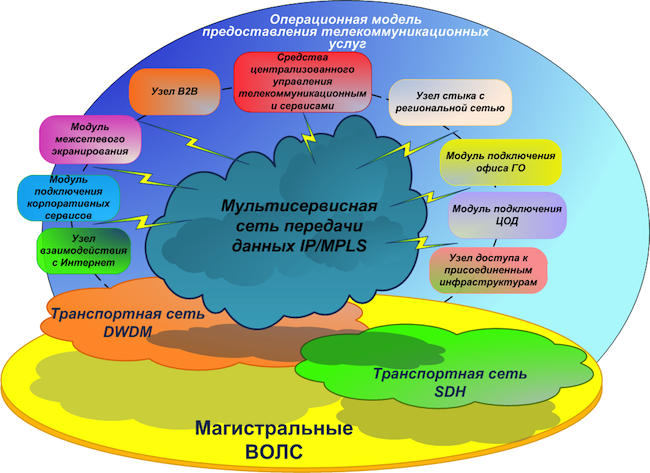
Concepto de red de destinoTendremos una red troncal primaria: esta es una infraestructura de transporte de telecomunicaciones basada en líneas de comunicación de fibra óptica (FOCL), equipos de formación de canales pasivos y activos. También puede usar el subsistema de densificación de canal óptico xWDM y, posiblemente, una red SDH.
Con base en la red primaria, estamos construyendo la llamada
red central . Tendrá un único plan de direcciones y un único conjunto de protocolos de enrutamiento. La red central incluye:
- MPLS - red multiservicio;
- DCI - enlaces entre centros de datos;
- Módulos EDGE: varios módulos de conexión: firewall, organizaciones asociadas, canales de Internet, centros de datos, LAN, redes regionales.
Creamos
una red multiservicio de
acuerdo con un principio jerárquico con la asignación de nodos de tránsito (P) y final (PE) . Durante un análisis preliminar de los equipos disponibles en el mercado hoy en día, quedó claro que sería económicamente más factible transferir el nivel de nodos P a equipos separados que combinar la funcionalidad P / PE en un dispositivo.
Una red multiservicio tendrá alta disponibilidad, tolerancia a fallas, tiempo de convergencia mínimo, escalabilidad, alto rendimiento y funcionalidad, en particular IPv6 y soporte de multidifusión.
Durante la construcción de la red troncal, tenemos la intención de
abandonar las tecnologías patentadas (siempre que sea posible sin comprometer la calidad), a medida que nos esforzamos por hacer que la solución sea flexible y no esté vinculada a un proveedor específico. Pero al mismo tiempo, no queremos crear una "vinagreta" a partir del equipo de varios proveedores. Nuestro principio fundamental de diseño es proporcionar el número máximo de servicios cuando se utiliza un equipo que es mínimamente suficiente para este número de proveedores. Esto permitirá, entre otras cosas, organizar el mantenimiento de la infraestructura de la red, utilizando un número limitado de personal. También es importante que el nuevo equipo sea compatible con el equipo existente para garantizar un proceso de migración sin interrupciones.
Se planea rediseñar completamente la estructura de las zonas de seguridad de las redes VTB, ex-VTB24 y ex-Banco de Moscú en el marco del proyecto con el objetivo de combinar segmentos funcionalmente duplicados. Se planifica una estructura unificada de zonas de seguridad con reglas de enrutamiento comunes y un concepto unificado de acceso entre redes. Planeamos llevar a cabo firewalls entre zonas de seguridad utilizando firewalls de hardware separados, espaciados en dos ubicaciones principales. También planeamos implementar todos los módulos perimetrales de forma independiente en dos sitios diferentes con redundancia automática entre ellos en base a protocolos de enrutamiento dinámico estandarizados.
Organizamos la gestión de los equipos de la red central a través de una red física separada (fuera de banda). El acceso administrativo a todos los equipos de red se proporcionará a través de un único servicio de autenticación, autorización y contabilidad (AAA).
Para encontrar rápidamente problemas en la red, es muy importante poder copiar el tráfico desde cualquier punto de la red para su análisis y entregarlo al analizador a través de un canal de comunicación independiente. Para hacer esto, crearemos una red aislada para el tráfico SPAN, con la ayuda de la cual recopilaremos, filtraremos y transmitiremos los flujos de tráfico a los servidores de análisis.
Para estandarizar los servicios proporcionados por la red y la posibilidad de asignar costos, presentaremos un único catálogo con indicadores SLA. Pasamos al modelo de servicio, en el que tenemos en cuenta la interconexión de la infraestructura de red con las tareas aplicadas, la interconexión de elementos de aplicaciones de control y su impacto en los servicios. Y este modelo de servicio es compatible con un sistema de monitoreo de red para que podamos asignar correctamente los costos de TI.
De la teoría a la práctica.
Ahora bajaremos un nivel y le informaremos sobre las soluciones más interesantes en nuestra nueva infraestructura que pueden serle útiles.
Bosque de recursos: detalles
Ya hemos
conocido a los residentes de Khabrovsk con el bosque de recursos VTB. Ahora intente dar una descripción técnica más detallada.
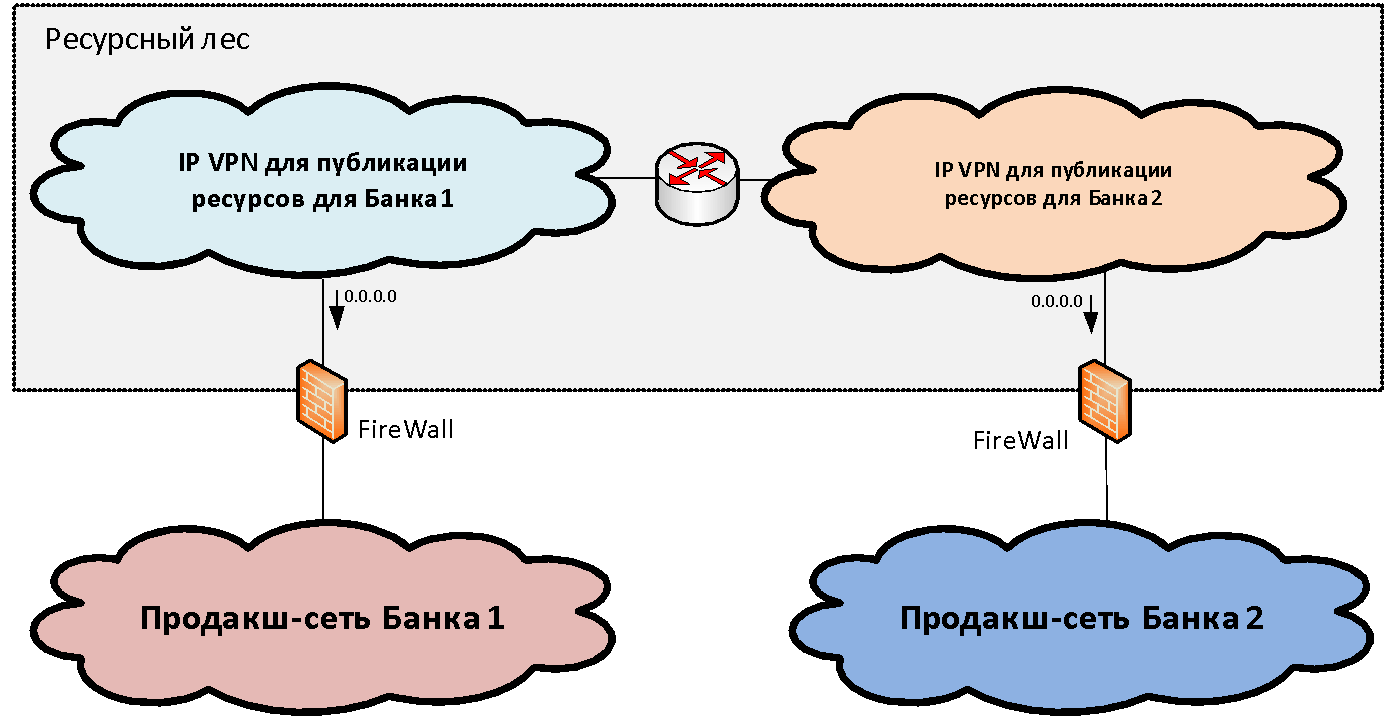
Supongamos que tenemos dos (por simplicidad) infraestructuras de red de diferentes organizaciones que deben combinarse. Dentro de cada infraestructura, como regla, entre el conjunto de segmentos de red funcionales (zonas de seguridad), se puede distinguir el segmento de red productivo principal, donde se encuentran los principales sistemas industriales. Conectamos estas zonas productivas a una determinada estructura de segmentos de bloqueo, que llamamos el
"bosque de recursos" . Estos segmentos de puerta de enlace publican los recursos compartidos disponibles de las dos infraestructuras.
El concepto de un bosque de recursos, desde el punto de vista de la red, es crear una zona de seguridad de puerta de enlace que consista en dos VPN IP (para el caso de dos bancos). Estas VPN IP se enrutan libremente entre ellas y se conectan a través de firewalls a segmentos productivos. El direccionamiento IP para estos segmentos se selecciona de un rango disjunto de direcciones IP. Por lo tanto, el enrutamiento hacia el bosque de recursos es posible desde las redes de ambas organizaciones.
Pero con el enrutamiento del bosque de recursos a los segmentos industriales, la situación es algo peor, ya que el direccionamiento en ellos a menudo se cruza y es imposible formar una sola tabla. Para resolver este problema, solo necesitamos dos segmentos en el bosque de recursos. En cada uno de los segmentos del bosque de recursos, se escribe una ruta predeterminada hacia la red industrial de "su" organización. Es decir, los usuarios pueden acceder sin traducir las direcciones a su segmento "propio" del bosque de recursos y a otro segmento a través de PAT.
Por lo tanto, dos segmentos del bosque de recursos representan una zona de seguridad de puerta de enlace única, si dibuja el borde a lo largo de los firewalls. Cada uno de ellos tiene su propia ruta: la puerta de enlace predeterminada mira hacia "su" banco. Si colocamos un recurso en algún segmento del bosque de recursos, los usuarios del banco correspondiente pueden interactuar con él sin NAT.
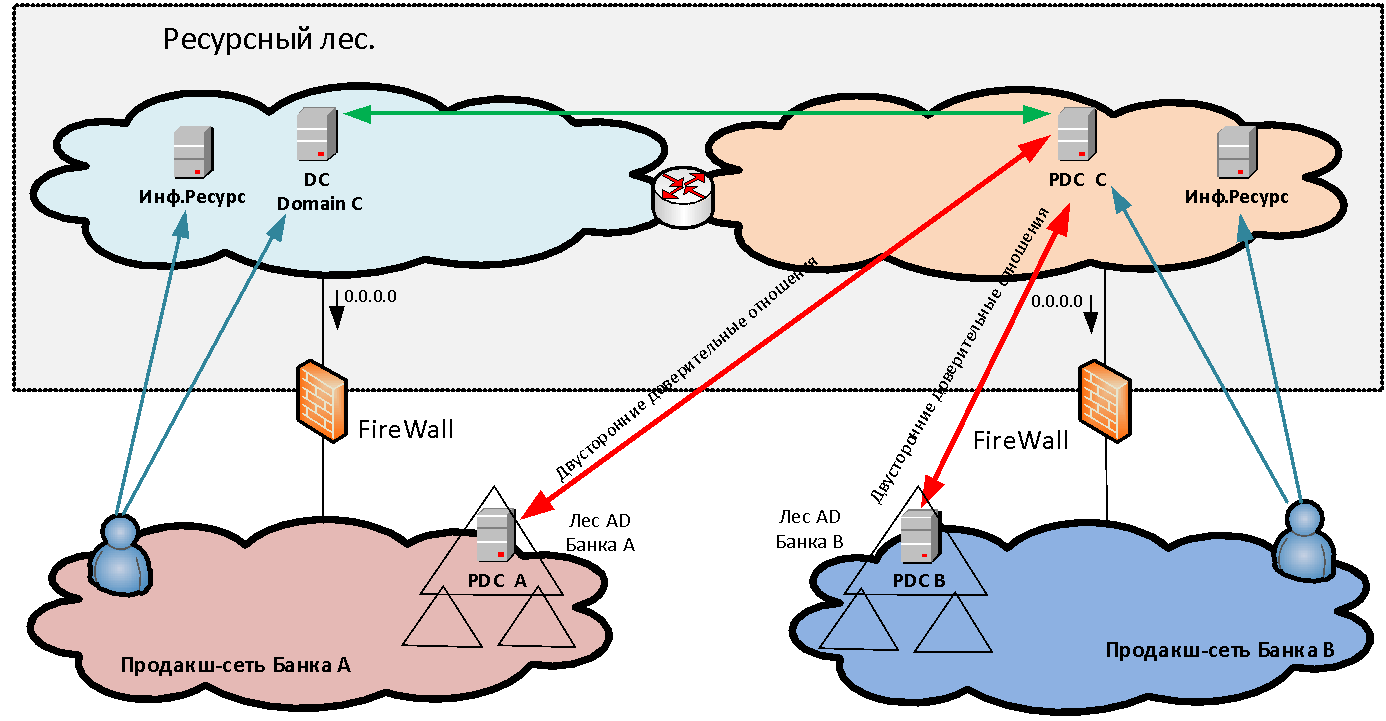
La interacción sin NAT es muy importante para muchos sistemas y, en primer lugar, para las interacciones de dominio de Microsoft; después de todo, en el bosque de recursos tenemos servidores de Active Directory para el nuevo dominio común, con los que ambas organizaciones establecen los fideicomisos. Además, sin interacción NAT, se requieren sistemas como Skype for Business, ABS "MBANK" y muchas otras aplicaciones diferentes, donde el servidor vuelve a la dirección del cliente. Y si el cliente está detrás de PAT, la conexión inversa ya no se establecerá.
Los servidores que instalamos en los segmentos del bosque de recursos se dividen en dos categorías: infraestructura (por ejemplo, servidores MS AD) y acceso a algunos sistemas de información. El último tipo de servidor que llamamos Data Marts. Los escaparates suelen ser servidores web, cuyo backend ya está detrás del firewall en la red de producción de la organización que creó este escaparate en el bosque de recursos.
¿Y cómo se
autentican los usuarios al acceder a los recursos publicados? Si simplemente proporcionamos acceso a algunas aplicaciones para uno o dos usuarios en otro dominio, entonces podemos crear cuentas separadas para la autenticación en nuestro dominio para ellos. Pero cuando hablamos de la fusión masiva de infraestructuras, por ejemplo, 50 mil usuarios, no es realista comenzar y mantener cuentas cruzadas separadas para ellos. Crear fideicomisos directos entre bosques de diferentes organizaciones tampoco siempre es posible, tanto por razones de seguridad como por la necesidad de hacer que los usuarios de PAT se encuentren en condiciones de intersección de espacios de direcciones. Por lo tanto, para resolver el problema de la autenticación unificada de usuarios, se crea un nuevo bosque MS AD que consta de un dominio en el perímetro del bosque de recursos. En este nuevo dominio, los usuarios se autentican al acceder a los servicios. Para hacer esto posible, se establecen fideicomisos bilaterales a nivel forestal entre el bosque nuevo y los bosques de dominio de cada organización. Por lo tanto, el usuario de cualquiera de las organizaciones puede autenticarse en cualquier recurso publicado.
Obtener integración de red
Después de establecer la interacción de los sistemas a través de la infraestructura del bosque de recursos y, por lo tanto, eliminar los síntomas agudos, llegó el momento de retomar la integración directa de las redes.
Para hacer esto, en la primera etapa, conectamos los segmentos de productos de tres bancos a un único firewall potente (lógicamente unificado, pero físicamente muchas veces reservado en diferentes sitios). El cortafuegos proporciona interacción directa entre los sistemas de diferentes bancos.
Con ex-VTB24, antes de organizar cualquier interacción directa entre los sistemas, ya logramos alinear los espacios de direcciones. Habiendo formado las tablas de enrutamiento en el firewall y abriendo los accesos apropiados, pudimos asegurar la interacción entre sistemas en dos infraestructuras diferentes.
Con el ex Banco de Moscú, los espacios de direcciones en el momento de la organización de las interacciones aplicadas no estaban alineados, y tuvimos que usar NAT mutuo para organizar la interacción de los sistemas. El uso de NAT creó una serie de problemas de resolución de DNS que se resolvieron mediante el mantenimiento de zonas DNS duplicadas. Además, debido a NAT, hubo dificultades con la operación de varios sistemas de aplicación. Ahora casi hemos eliminado las intersecciones de los espacios de direcciones, pero nos enfrentamos al hecho de que muchos sistemas VTB y ex-Banco de Moscú están estrechamente unidos para interactuar en las direcciones traducidas. Ahora necesitamos migrar estas interacciones a direcciones IP reales mientras mantenemos la continuidad del negocio.
Abolición de NAT
Aquí nuestro objetivo es garantizar el funcionamiento de los sistemas en un solo espacio de direcciones para una mayor integración de los servicios de infraestructura (MS AD, DNS) y la aplicación (Skype for Business, MBANK). Desafortunadamente, dado que algunos de los sistemas de aplicaciones ya están vinculados entre sí en las direcciones traducidas, se requiere trabajo individual con cada sistema de aplicaciones para eliminar NAT para interacciones específicas.
A veces puedes
optar por tal truco : configura el mismo servidor al mismo tiempo, tanto en la dirección traducida como en la real. Por lo tanto, los administradores de aplicaciones pueden probar el trabajo en una dirección real antes de la migración, intentar cambiar a la interacción no NAT por su cuenta y retroceder si es necesario. Al mismo tiempo, monitoreamos el firewall usando la función de captura de paquetes para ver si alguien se está comunicando con el servidor a través de la dirección traducida. Tan pronto como se detiene la comunicación, de acuerdo con el propietario del recurso, dejamos de transmitir: el servidor solo tiene una dirección real.
Después de analizar NAT, desafortunadamente, por algún tiempo será necesario mantener el firewall entre segmentos funcionalmente idénticos, porque no todas las zonas cumplen con los mismos estándares de seguridad. Después de estandarizar los segmentos, el firewall entre los segmentos se reemplaza por el enrutamiento y las zonas de seguridad funcionalmente idénticas se fusionan.
Cortafuegos
Pasemos al problema del cortafuegos entre redes. En principio, es relevante para cualquier organización grande en la que sea necesario proporcionar tolerancia a fallas tanto local como global de los equipos de protección.
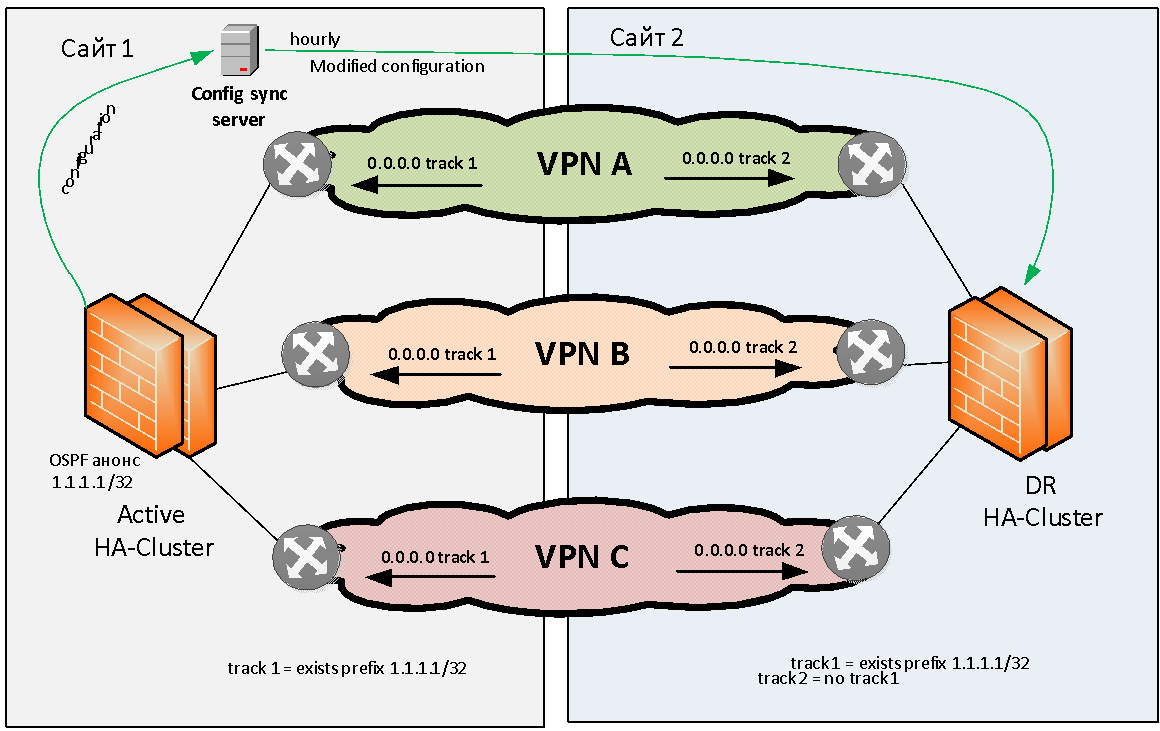
Tratemos de formular el problema de la reserva del firewall en general. Tenemos dos sitios: el sitio 1 y el sitio 2. Hay varios (por ejemplo, tres) VPN MPLS IP que se comunican entre sí a través de un firewall con estado. Este firewall debe reservarse localmente y geográficamente.
No consideraremos el problema de la copia de seguridad local de los firewalls; casi cualquier fabricante proporciona la capacidad de ensamblar firewalls en un clúster HA local. En cuanto a la reserva geográfica de los firewalls, prácticamente ningún proveedor tiene esta tarea lista para usar.
Por supuesto, puede "extender" un clúster de firewall en varios sitios a lo largo de L2, pero luego este clúster representará un único punto de falla y la confiabilidad de nuestra solución no será muy alta. Debido a que los clústeres a veces se congelan por completo debido a errores de software, o caen en un estado cerebral dividido debido a una ruptura de enlace L2 entre sitios. Debido a esto, de inmediato nos negamos a extender los clústeres de firewall sobre L2.
Necesitábamos idear un esquema en el que si un módulo de firewall fallaba en un sitio, se produciría una transición automática a otro sitio. Así es como lo hicimos.
Se decidió apegarse al modelo de reserva geográfica activa / en espera cuando el clúster activo se encuentra en el mismo sitio. De lo contrario, inmediatamente encontramos problemas con el enrutamiento asimétrico, que es difícil de resolver con una gran cantidad de VPN L3.
El clúster de firewall activo debe indicar de alguna manera su correcto funcionamiento. Como método de señalización, elegimos el anuncio OSPF desde el cortafuegos a la red de la ruta de prueba (bandera) con la máscara / 32. El equipo de red en el sitio 1 monitorea la presencia de esta ruta desde el firewall y, si está disponible, activa el enrutamiento estático (por ejemplo, 0.0.0.0 / 0), hacia el clúster de firewall dado. Esta ruta predeterminada estática se coloca (a través de la redistribución) en la tabla de protocolo BGP MP y se distribuye a través de la red troncal. , OSPF , , IP VPN.
, , , .
1 - , , 1 , 2 — . , , VPN' . , , , .
, active/standby. active-. , . , (, IP- ). . . .
L3 , . .
. , , — , , . L3-, .
, IP-. MPLS VPN. MPLS VPN «IN» VPN «OUT». VPN HUB-and-spoke VPN. Spoke HUB' VPN, .
«IN»
- Spoke VPN' VPN. «OUT»
Spoke VPN' .
MPLS VPN «IN». VPN . VPN HUB-VPN «IN» . . , Policy Based Routing. VPN «OUT», VPN «OUT» Spoke-VPN.
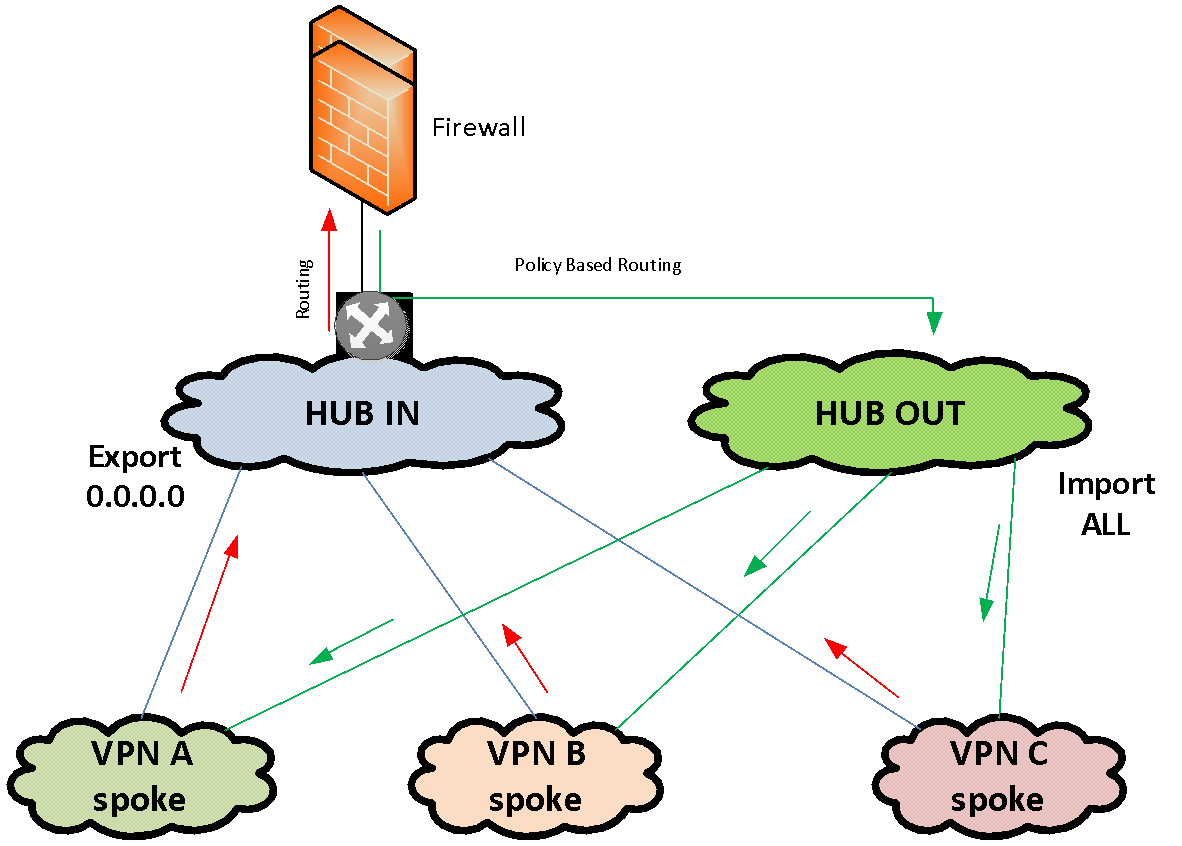
VPN, . MPLS import / export HUB VPN.
VPN , — , VLAN, ..
Conclusión
, , . , , , . .