La detección de ataques ha sido una tarea importante en la seguridad de la información durante décadas. Los primeros ejemplos conocidos de implementación de IDS se remontan a principios de la década de 1980.
Después de varias décadas, se formó una industria completa de herramientas de detección de ataques. Actualmente, hay varios tipos de productos, como IDS, IPS, WAF, firewalls, la mayoría de los cuales ofrecen detección de ataques basados en reglas. La idea de utilizar técnicas de detección de anomalías para detectar ataques basados en estadísticas de producción no parece tan realista como en el pasado. ¿O todo lo mismo?
Detección de anomalías en aplicaciones web
Los primeros cortafuegos diseñados específicamente para detectar ataques a aplicaciones web comenzaron a aparecer en el mercado a principios de la década de 1990. Desde entonces, tanto los métodos de ataque como los mecanismos de defensa han cambiado significativamente, y los atacantes pueden estar un paso adelante en cualquier momento.
Actualmente, la mayoría de los WAF intentan detectar ataques de la siguiente manera: existen algunos mecanismos basados en reglas que están integrados en el servidor proxy inverso. El ejemplo más llamativo es mod_security, el módulo WAF para el servidor web Apache, que se desarrolló en 2002. Identificar ataques usando reglas tiene varios inconvenientes; por ejemplo, las reglas no pueden detectar ataques de día cero, mientras que un experto puede detectar fácilmente los mismos ataques, y esto no es sorprendente, porque el cerebro humano no funciona en absoluto como un conjunto de expresiones regulares.
Desde el punto de vista de WAF, los ataques se pueden dividir en aquellos que podemos detectar por la secuencia de solicitudes, y aquellos en los que una solicitud HTTP (respuesta) es suficiente para resolver. Nuestra investigación se centra en detectar los últimos tipos de ataques: inyección de SQL, secuencias de comandos de sitios cruzados, inyección de entidades externas XML, recorrido de ruta, comando del sistema operativo, inyección de objetos, etc.
Pero primero, probémonos a nosotros mismos.
¿Qué pensará el experto cuando vea las siguientes consultas?
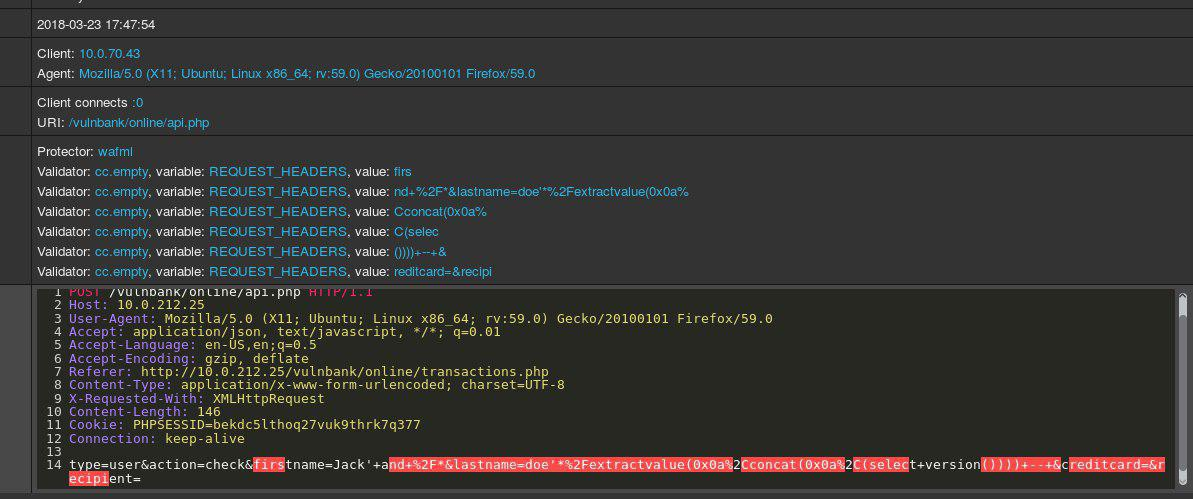
Eche un vistazo a un ejemplo de solicitud HTTP para aplicaciones:
Si se le asignó la tarea de detectar solicitudes maliciosas a una aplicación, lo más probable es que desee observar el comportamiento habitual del usuario durante algún tiempo. Al examinar las consultas para varios puntos finales de la aplicación, puede obtener una idea general de la estructura y las funciones de las consultas no peligrosas.
Ahora obtienes la siguiente consulta para análisis:

Es inmediatamente evidente que algo está mal aquí. Tomará algún tiempo comprender cómo es realmente aquí, y una vez que identifique la parte de la solicitud que parece anormal, puede comenzar a pensar qué tipo de ataque es. En esencia, nuestro objetivo es hacer que nuestra "inteligencia artificial para detectar ataques" funcione de la misma manera: para parecerse al pensamiento humano.
Lo obvio es que parte del tráfico, que a primera vista parece malicioso, puede ser normal para un sitio web en particular.
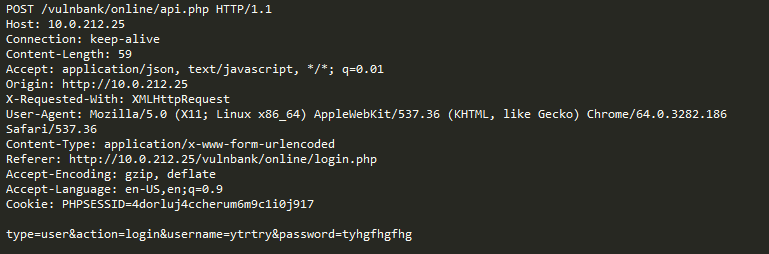
Por ejemplo, consideremos las siguientes consultas:
¿Esta consulta es anormal?
De hecho, esta solicitud es una publicación de un error en el rastreador Jira y es típica de este servicio, lo que significa que la solicitud es esperada y normal.
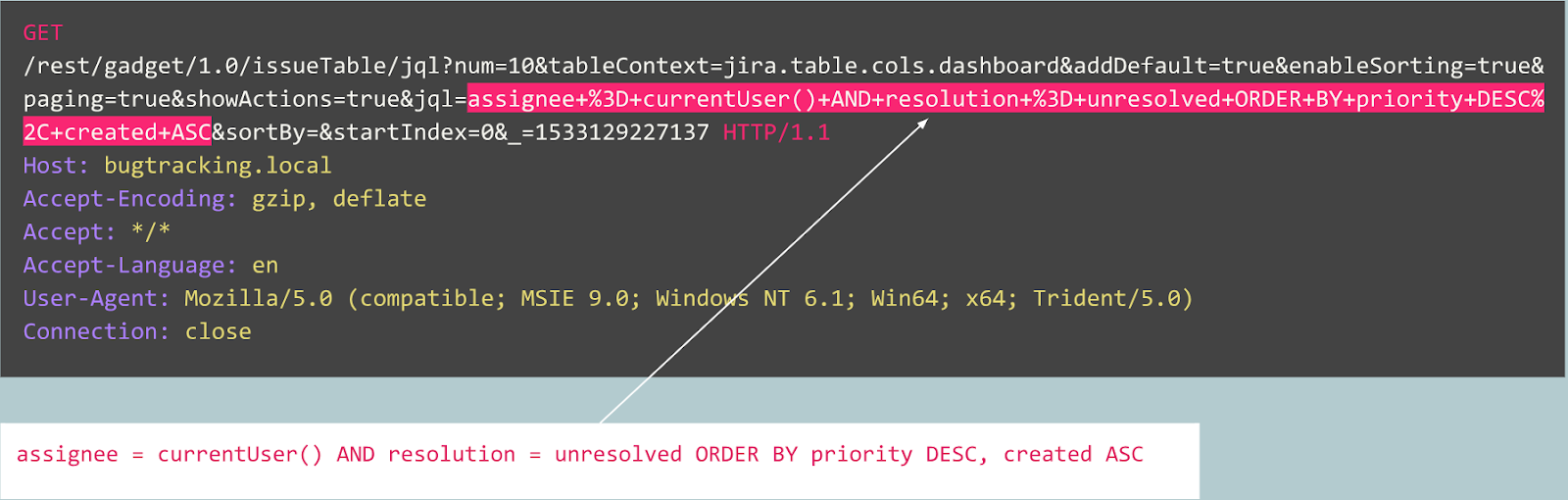
Ahora considere el siguiente ejemplo:

A primera vista, la solicitud parece un registro de usuario normal en un sitio web basado en Joomla CMS. Sin embargo, la operación solicitada es user.register en lugar del registro.register habitual. La primera opción está desactualizada y contiene una vulnerabilidad que permite a cualquiera registrarse como administrador. Un exploit para esta vulnerabilidad se conoce como Joomla <3.6.4 Creación de cuenta / Escalada de privilegios (CVE-2016-8869, CVE-2016-8870).

Por donde empezamos
Por supuesto, primero examinamos las soluciones existentes al problema. Se han realizado varios intentos para crear algoritmos de detección de ataques basados en estadísticas o aprendizaje automático durante décadas. Uno de los enfoques más populares es resolver el problema de clasificación, cuando las clases son algo así como "consultas esperadas", "inyecciones SQL", XSS, CSRF, etc. De esta manera, puede lograr una buena precisión para el conjunto de datos utilizando el clasificador Sin embargo, este enfoque no resuelve problemas muy importantes desde nuestro punto de vista:
- La selección de clase es limitada y predeterminada . ¿Qué sucede si su modelo en el proceso de aprendizaje está representado por tres clases, digamos "consultas normales", SQLi y XSS, y durante la operación del sistema encuentra CSRF o un ataque de día cero?
- El significado de estas clases . Suponga que necesita proteger diez clientes, cada uno de los cuales ejecuta aplicaciones web completamente diferentes. Para la mayoría de ellos, no tienes idea de cómo se ve realmente la inyección SQL para su aplicación. Esto significa que de alguna manera debe crear artificialmente conjuntos de datos de entrenamiento. Este enfoque no es óptimo, porque finalmente aprenderá de los datos que difieren en la distribución de los datos reales.
- Interpretabilidad de los resultados del modelo . Bueno, el modelo produjo el resultado de la inyección SQL, ¿y ahora qué? Usted y, lo que es más importante, su cliente, que es el primero en ver una advertencia y generalmente no es un experto en ataques web, debe adivinar qué parte de la solicitud su modelo considera malicioso.
Teniendo en cuenta todos estos problemas, decidimos intentar entrenar el modelo clasificador de todos modos.
Dado que el protocolo HTTP es un protocolo de texto, era obvio que necesitábamos echar un vistazo a los clasificadores de texto modernos. Un ejemplo bien conocido es el análisis de sentimientos en un conjunto de datos de revisión de películas IMDB. Algunas soluciones usan RNN para clasificar las revisiones. Decidimos probar un modelo similar con arquitectura RNN con algunas pequeñas diferencias. Por ejemplo, la arquitectura RNN de lenguaje natural usa una representación vectorial de palabras, pero no está claro qué palabras ocurren en un lenguaje no natural como HTTP. Por lo tanto, decidimos usar la representación vectorial de símbolos para nuestra tarea.
Las representaciones preparadas no resuelven nuestro problema, por lo que utilizamos asignaciones simples de caracteres en códigos numéricos con varios marcadores internos, como
GO y
EOS .
Después de que se completó el desarrollo y las pruebas del modelo, todos los problemas previstos anteriormente se hicieron aparentes, pero al menos nuestro equipo pasó de supuestos inútiles a algún resultado.
Que sigue
Luego, decidimos dar algunos pasos hacia la interpretabilidad de los resultados del modelo. En algún momento, nos encontramos con el mecanismo de atención "Atención" y comenzamos a implementarlo en nuestro modelo. Y dio resultados prometedores. Ahora nuestro modelo comenzó a mostrar no solo etiquetas de clase, sino también factores de atención para cada personaje que pasamos al modelo.
Ahora podríamos visualizar y mostrar en la interfaz web el lugar exacto donde se detectó el ataque de inyección SQL. Este fue un buen resultado, pero otros problemas de la lista seguían sin resolverse.
Era obvio que deberíamos seguir avanzando para beneficiarnos del mecanismo de atención y alejarnos de la tarea de clasificación. Después de leer una gran cantidad de estudios relacionados sobre modelos de secuencia (sobre mecanismos de atención [2], [3], [4], sobre la representación vectorial, sobre las arquitecturas de autoencoders) y experimentos con nuestros datos, pudimos crear un modelo de detección de anomalías que finalmente funcionaría más o menos como lo hace un experto.
Codificadores automáticos
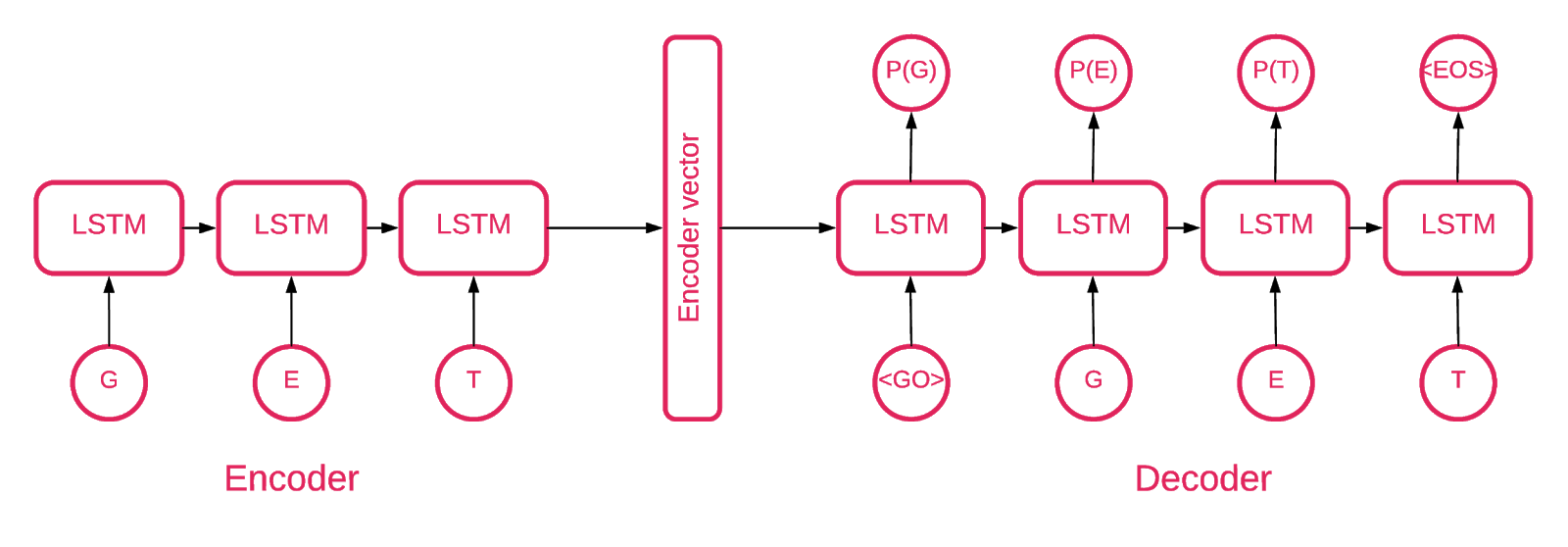
En algún momento, quedó claro que la arquitectura de Seq2Seq [5] es la más adecuada para nuestra tarea.
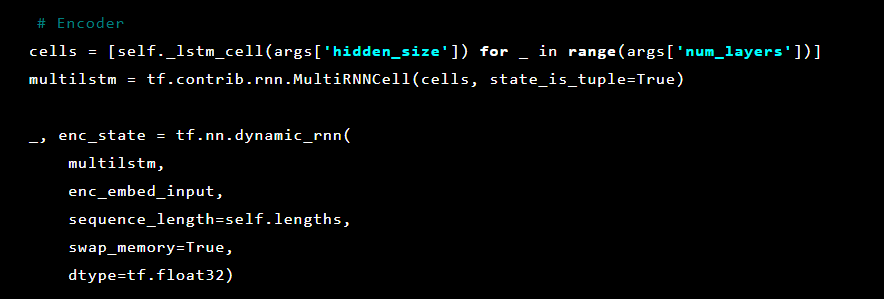
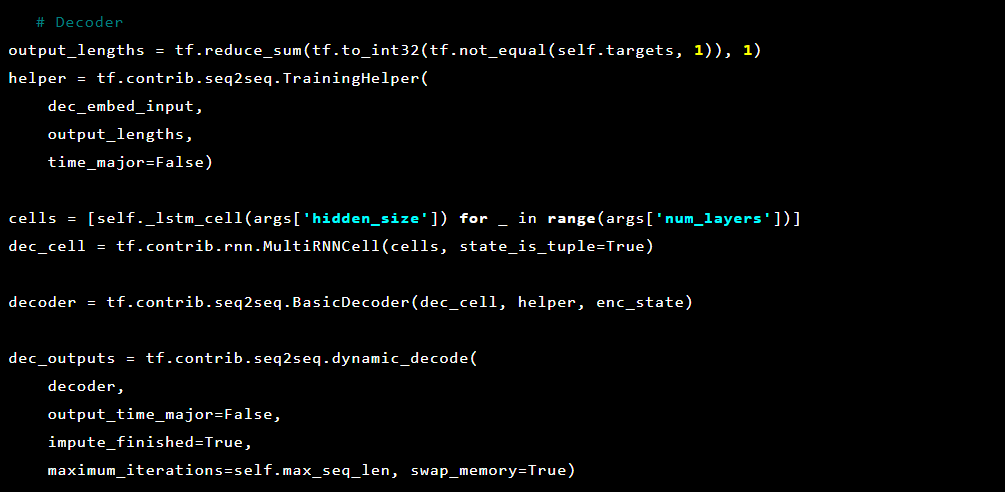
El modelo Seq2Seq [7] consta de dos LSTM multicapa: un codificador y un decodificador. El codificador asigna la secuencia de entrada a un vector de longitud fija. El decodificador decodifica el vector objetivo usando la salida del codificador. En el entrenamiento, un codificador automático es un modelo en el que los valores objetivo se establecen de la misma manera que los valores de entrada.
La idea es enseñar a la red a decodificar las cosas que vio o, en otras palabras, acercar la identidad. Si un codificador automático capacitado recibe un patrón anormal, probablemente lo recrea con un alto grado de error, simplemente porque nunca se ha visto.
Solución
Nuestra solución consta de varias partes: inicialización del modelo, capacitación, pronóstico y verificación. Esperamos que la mayor parte del código ubicado en el repositorio no requiera explicación, por lo que nos centraremos solo en las partes importantes.
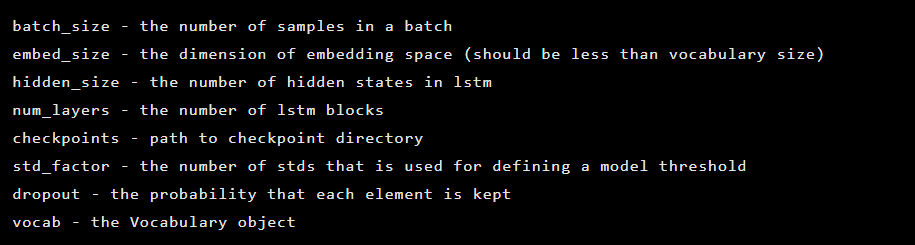
El modelo se crea como una instancia de la clase Seq2Seq, que tiene los siguientes argumentos de constructor:
A continuación, se inicializan las capas de codificador automático. Primer codificador:
Luego el decodificador:
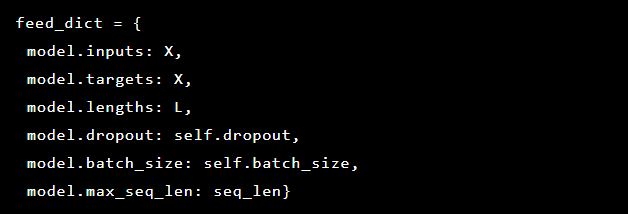
Como el problema que estamos resolviendo es detectar anomalías, los valores objetivo y la entrada son los mismos. Entonces nuestro feed_dict se ve así:
Después de cada era, el mejor modelo se guarda como un punto de referencia, que luego se puede descargar. Con fines de prueba, se creó una aplicación web que defendimos con un modelo para verificar si los ataques reales tuvieron éxito.
Inspirado por el mecanismo de atención, tratamos de aplicarlo al modelo de codificador automático para marcar las partes anormales de esta consulta, pero notamos que las probabilidades derivadas de la última capa funcionan mejor.

En la etapa de prueba de nuestra muestra retrasada, obtuvimos muy buenos resultados: la precisión y la recuperación son cercanas a 0,99. Y la curva ROC tiende a 1. Se ve increíble, ¿no?
Resultados
El modelo propuesto del codificador automático Seq2Seq pudo detectar anomalías en las solicitudes HTTP con una precisión muy alta.
Este modelo actúa como una persona: solo estudia las solicitudes de usuario "normales" para una aplicación web. Y cuando detecta anomalías en las solicitudes, selecciona la ubicación exacta de la solicitud, que considera anómala.
Probamos este modelo en algunos ataques en una aplicación de prueba y los resultados fueron prometedores. Por ejemplo, la imagen de arriba muestra cómo nuestro modelo detectó una inyección SQL dividida en dos parámetros en un formulario web. Dichas inyecciones SQL se denominan fragmentadas: partes de la carga útil de ataque se entregan en varios parámetros HTTP, lo que dificulta la detección de WAF basados en reglas, ya que generalmente prueban cada parámetro individualmente.
El código del modelo y los datos de entrenamiento y prueba se publican como una computadora portátil Jupyter para que todos puedan reproducir nuestros resultados y sugerir mejoras.
En conclusión
Creemos que nuestra tarea fue más bien no trivial. Nos gustaría, con un mínimo de esfuerzo (en primer lugar, evitar errores debido a la complejidad de la solución), encontrar una forma de detectar ataques que, como por arte de magia, hayan aprendido a decidir qué es bueno y qué es malo. En segundo lugar, quería evitar problemas con el factor humano, cuando exactamente un experto decide qué es un signo de un ataque y qué no. En resumen, me gustaría señalar que el codificador automático con la arquitectura Seq2Seq para el problema de la búsqueda de anomalías, en nuestra opinión y para nuestro problema, hizo un excelente trabajo.
También queríamos resolver el problema con la interpretación de los datos. El uso de arquitecturas complejas de redes neuronales suele ser muy difícil. En una serie de transformaciones, ya es difícil decir al final qué exactamente qué parte de los datos influyó más en la decisión. Sin embargo, después de repensar el enfoque de la interpretación de datos por el modelo, resultó suficiente para nosotros obtener las probabilidades para cada símbolo de la última capa.
Cabe señalar que esta no es una versión de producción. No podemos revelar los detalles de la implementación de este enfoque en un producto real, y queremos advertir que simplemente tomar e incorporar esta solución en algún producto no funcionará.
Repositorio de GitHub:
goo.gl/aNwq9UAutores : Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseniy Reutov (
Raz0r )
Referencias
- Comprender las redes LSTM
- Atención y redes neuronales recurrentes aumentadas
- La atención es todo lo que necesitas
- La atención es todo lo que necesitas (anotado)
- Tutorial de traducción automática neuronal (seq2seq)
- Autoencoders
- Secuencia a secuencia de aprendizaje con redes neuronales
- Construcción de codificadores automáticos en Keras