Recientemente, Jupyter Notebook se ha vuelto muy popular entre los expertos en ciencia de datos, convirtiéndose en el estándar de facto para la creación rápida de prototipos y análisis de datos. En Netflix, tratamos de ampliar aún más los límites de sus capacidades al repensar qué puede ser Notebook, quién puede usarse y qué pueden hacer con él. Ponemos mucho esfuerzo en traducir nuestra visión en realidad.
En este artículo, queremos decirle por qué creemos que Jupyter Notebooks es tan atractivo y eso nos inspira en el camino. Además, describimos los componentes de nuestra infraestructura y revisamos nuevas formas de usar Jupyter Notebook en Netflix.

Nota del traductor: cuidado, mucho texto y pocas imágenes
Si no tiene mucho tiempo, le sugerimos que vaya inmediatamente a la sección Casos de uso .
¿Por qué todo esto?
Los datos son el poder de Netflix. Permean nuestros pensamientos, influyen en nuestras decisiones y desafían nuestras hipótesis . Cobran experimentos y la aparición de uno nuevo en una escala sin precedentes . Los datos nos permiten descubrir significados inesperados y experimentar una increíble experiencia personalizada para 130 millones de nuestros usuarios en todo el mundo .
Hacer realidad todo esto es un logro considerable, que requiere un impresionante soporte de ingeniería e infraestructura. Todos los días, se reciben más de 1 billón de eventos en una secuencia (canalización de ingestión de transmisión) que se procesa y registra en un almacenamiento en la nube de 100 PB. Y todos los días, nuestros usuarios realizan más de 150,000 tareas con estos datos, cubriendo todo, desde informes hasta aprendizaje automático y algoritmos de recomendación.
Para admitir tales escenarios de uso a tal escala, hemos construido uno de los mejores en la industria, una plataforma de datos flexible, potente y, según sea necesario, sofisticada (Netflix Data Platform). También desarrollamos herramientas y servicios adicionales, como Genie (servicio de ejecución de tareas) y Metacat (meta-almacenamiento). Estas herramientas reducen la complejidad, lo que permite admitir una gama más amplia de usuarios en toda la empresa.

La variedad de usuarios es impresionante, pero hay que pagar por ello: la plataforma de datos de Netflix y su ecosistema de herramientas y servicios deben escalar para admitir escenarios de uso adicionales, idiomas, esquemas de acceso y mucho más. Para una mejor comprensión del problema, consideramos tres posiciones comunes: un ingeniero analista, un ingeniero de datos y un científico de datos.
 La diferencia en la preferencia de idiomas y herramientas para diferentes posiciones
La diferencia en la preferencia de idiomas y herramientas para diferentes posicionesComo regla general, cada posición prefiere usar su propio conjunto de herramientas e idiomas. Por ejemplo, un ingeniero de datos puede crear un nuevo conjunto de datos que contenga billones de secuencias de eventos utilizando Scala en IntelliJ. El analista puede usarlos en un nuevo informe de calidad de transmisión global utilizando SQL y Tableau. Este informe puede ir a un científico de datos que creará un nuevo modelo de compresión de transmisión usando R y RStudio. A primera vista, estos procesos parecen fragmentados, aunque complementarios, pero si se mira más profundamente, cada uno de estos procesos tiene varias tareas superpuestas:
exploración de datos : ocurre en una etapa temprana del proyecto; puede incluir una descripción general de datos de muestra, consultas para análisis estadísticos y visualización de datos
preparación de datos : una tarea repetitiva, puede incluir limpiar, estandarizar, transformar, desnormalizar y agregar datos; por lo general, la parte del proyecto que consume más tiempo
validación de datos - una tarea que ocurre regularmente; puede incluir una encuesta de datos muestreados, análisis estadístico, análisis agregado y visualización de datos; generalmente ocurre como parte de la exploración de datos, preparación de datos, desarrollo, pre-implementación y post-implementación
producción : ocurre en una etapa tardía del proyecto; puede incluir implementación de código, adiciones de muestra, capacitación de modelos, validación de datos y flujos de trabajo de programación
Para ampliar las capacidades de nuestros usuarios, queremos que estas tareas sean lo más fáciles posible.
Para ampliar las capacidades de nuestra plataforma, queremos minimizar la cantidad de herramientas que deben ser compatibles. Pero como? Ninguna herramienta individual puede cubrir todas estas tareas. Además, a menudo una tarea requiere el uso de varias herramientas. Sin embargo, si nos desconectamos, surge un patrón común para todas las herramientas e idiomas: ejecutar código, examinar datos, presentar el resultado.
Dio la casualidad de que se desarrolló un proyecto de código abierto específicamente para esto: Proyecto Jupyter .
Cuadernos Jupyter

El cuaderno Jupyter en nteract muestra a Vega y Altair
El proyecto Jupyter se lanzó en 2014 con el objetivo de crear un conjunto consistente de herramientas de código abierto para la investigación, el flujo de trabajo reproducible y el análisis de datos. Estas herramientas han sido muy elogiadas por la industria y hoy Jupyter se ha convertido en una parte integral del conjunto de herramientas de cualquier científico de datos. Para comprender el alcance de su influencia, observamos que Jupyter recibió el Premio ACM Software Systems 2017 , un prestigioso premio que comparte con Java, Unix y the_Web.
Para entender por qué el Jupyter Notebook es tan atractivo para nosotros, considere sus características principales:
- protocolo de mensajería para analizar y ejecutar código independientemente del idioma
- formato de archivo con la capacidad de editar, para descripción, visualización y ejecución de código, salida y notas de descuento
- interfaz web para escritura interactiva, ejecución de código y visualización de resultados
El protocolo Jupyter proporciona una API de mensajería estandarizada con núcleos que actúan como módulos de cómputo y proporciona una arquitectura componible, compartiendo así dónde se almacena el código (UI) y dónde se ejecuta (el núcleo). Por lo tanto, separando la interfaz y el núcleo, los cuadernos pueden trabajar en varios idiomas manteniendo la flexibilidad para configurar el tiempo de ejecución. Si existe un idioma para un idioma que puede intercambiar mensajes utilizando el protocolo Jupyter, Notebook puede ejecutar código enviando y recibiendo mensajes a ese núcleo.
Además de todo, todo esto es compatible con un formato de archivo que le permite almacenar tanto el código en sí como los resultados de su ejecución en un solo lugar. Esto significa que puede ver los resultados de la ejecución más adelante sin tener que reiniciar el código. Los cuadernos también pueden almacenar una descripción detallada del contexto y de lo que sucede exactamente dentro de él. Esto lo convierte en un formato ideal para transmitir un contexto comercial, corregir suposiciones, comentar código, describir conclusiones y mucho más.
Casos de uso
Entre los muchos escenarios, los casos de uso más populares son: acceso a datos, plantillas de cuaderno y cuadernos de programación.
Acceso a datos
Jupyter Notebook apareció originalmente en Netflix para admitir flujos de trabajo de ciencia de datos. A medida que creció su uso entre los expertos en ciencia de datos, vimos el potencial para expandir las capacidades de nuestras herramientas. Nos dimos cuenta de que podíamos usar la versatilidad y la arquitectura de Jupyter Notebook y expandir sus capacidades para compartir datos. En el tercer trimestre de 2017, comenzamos seriamente a trabajar en hacer de Notebook una herramienta para un círculo reducido de especialistas en un representante de primera clase de la Plataforma de datos de Netflix.
Desde el punto de vista de nuestros usuarios, los portátiles ofrecen una interfaz conveniente para la ejecución interactiva de comandos, la investigación de resultados y la visualización de datos, todo en un entorno de desarrollo en la nube. También admitimos la biblioteca Python, que combina el acceso a la plataforma API. Esto significa que los usuarios tienen acceso programático a prácticamente toda la plataforma de Netflix a través de Notebook. Gracias a esta combinación de flexibilidad, potencia y facilidad de uso, la compañía experimentó un fuerte aumento en su uso por parte de todo tipo de usuarios de la plataforma.
Hoy, notebook es la herramienta de datos más popular en Netflix.
Plantillas de cuaderno
A medida que el soporte para Jupyter Notebooks se expandió dentro de la plataforma, comenzamos a introducir nuevas funciones para usarlo para cumplir con nuevos escenarios de uso. De aquí vinieron las computadoras portátiles parametrizadas. Las computadoras portátiles con parámetros representan exactamente lo que dice su nombre: una computadora portátil que le permite establecer parámetros en el código y recibir información en tiempo de ejecución. Esto proporciona un buen mecanismo para que los usuarios definan el cuaderno como plantillas reutilizables.
Nuestros usuarios han encontrado muchas formas de usar dichos patrones. Enumeramos algunos de los más utilizados:
- Científico de datos : experimente con diferentes coeficientes y resuma los resultados
- Ingeniero de datos : realice una recopilación de auditorías de calidad de datos como parte del proceso de implementación.
- Analista de datos : comparta consultas y visualizaciones preparadas para que las partes interesadas puedan explorar los datos más de lo que permite Tableau
- Ingeniero de software : envíe los resultados de un script para solucionar un bloqueo
Programación de cuadernos (programador)
Una de las formas originales de usar Notebook es crear una capa de fusión para programar flujos de trabajo.
Dado que cada computadora portátil puede ejecutarse en un núcleo arbitrario, podemos admitir cualquier entorno de tiempo de ejecución definido por el usuario. Y dado que los cuadernos describen un flujo de ejecución lineal dividido en celdas, podemos relacionar la falla con una celda específica. Esto permite a los usuarios describir la ejecución y las visualizaciones en una forma más narrativa, que puede capturarse con precisión al inicio en un momento posterior.
Tal paradigma le permite usar una computadora portátil para el trabajo interactivo y cambiar sin problemas a la ejecución múltiple y al uso del programador. Lo que resultó ser muy conveniente para los usuarios. Muchos usuarios crean flujos de trabajo completos en el cuaderno solo para luego duplicarlos en archivos separados y ejecutarlos en el momento adecuado. Al tratar el cuaderno como una descripción secuencial del proceso, podemos programarlo fácilmente para que se ejecute como cualquier otro flujo de trabajo.
Podemos planificar la ejecución de otros tipos de trabajo a través de cuadernos. Cuando se ejecuta un trabajo de Spark o Presto desde el planificador, el código fuente se inserta en el cuaderno recién creado y se ejecuta. Este cuaderno se convierte en un depósito de historial que contiene código fuente, parámetros, configuraciones, registros de ejecución, mensajes de error, etc. Al solucionar problemas, esto proporciona un punto de partida rápido para la investigación, ya que toda la información relevante está dentro y el cuaderno puede ejecutarse para la depuración interactiva.
Infraestructura portátil
El soporte de los escenarios descritos anteriormente en la escala de Netflix requiere una amplia infraestructura de soporte. Presente brevemente varios proyectos que serán discutidos en las siguientes secciones:
nteract es la nueva generación de interfaz de usuario basada en React para portátiles Jupyter. Proporciona una interfaz simple e intuitiva y ofrece varias mejoras para la interfaz de usuario clásica de Jupyter, como barras de herramientas de celdas en línea, celdas de arrastrar y soltar y un explorador incorporado.
Biblioteca Papermill para parametrización, ejecución y análisis de cuadernos Jupyter. Con la ayuda de la cual puede propagar varios cuadernos con varios parámetros y ejecutarlos simultáneamente. Papermill también le permite recopilar y resumir métricas para una colección completa de cuadernos.
Commuter es un servicio ligero y escalable verticalmente para ver y compartir notebook. Proporciona una versión de API compatible con Jupyter para el contenido y facilita la lectura de portátiles almacenados localmente en Amazon S3. También ofrece un explorador para buscar y compartir archivos.
Titus es una plataforma de administración de contenedores que proporciona un lanzamiento de contenedores escalable y confiable e integración nativa de la nube con Amazon AWS. Titus fue desarrollado en Netflix y se usa en combate para soportar los sistemas de transmisión, recomendación y contenido de Netflix.
Se puede encontrar una descripción más detallada de la arquitectura en el artículo Programando cuadernos en Netflix . Para el propósito de esta publicación, nos restringimos a los tres componentes fundamentales del sistema: almacenamiento, ejecución e interfaz.
 Infraestructura de portátiles en Netflix
Infraestructura de portátiles en NetflixAlmacenamiento
La plataforma de datos de Netflix utiliza el almacenamiento en la nube Amazon S3 y EFS, que los portátiles tratan como sistemas de archivos virtuales. Esto significa que cada usuario tiene un directorio de inicio de EFS que contiene un espacio de trabajo personal para portátiles. En este espacio, almacenamos cualquier cuaderno creado o cargado por el usuario. Este es también el lugar donde ocurre la lectura y la escritura cuando el usuario inicia de manera interactiva la computadora portátil. Usamos la combinación [espacio de trabajo + nombre de archivo] para el espacio de nombres, es decir /efs/users/kylek/notebooks/MySparkJob.ipynb para ver, compartir y en el programador de ejecución. Tal acuerdo previene colisiones y facilita la identificación tanto del usuario como de la ubicación del portátil en EFS.
La ruta al espacio de trabajo le permite ignorar la complejidad del almacenamiento en la nube para el usuario. Por ejemplo, solo los nombres de los archivos del cuaderno se muestran en el directorio, es decir MySparkJob.ipynb. El mismo archivo está disponible a través del terminal: ~ / notebooks / MySparkJob.ipynb.

Almacenamiento de portátiles vs. acceso
Cuando el usuario establece la tarea de iniciar el cuaderno, el planificador copia el cuaderno del usuario de EFS al directorio compartido en S3. El cuaderno en S3 se convierte en la fuente de la verdad para el planificador, o el cuaderno de origen. Cada vez que el planificador (despachador) inicia el cuaderno, crea un nuevo cuaderno desde la fuente. Este nuevo cuaderno es lo que realmente comienza y se convierte en un registro invariable de una ejecución específica, que contiene el código ejecutable, la salida y los registros de cada celda. Lo llamamos cuaderno de salida (salida).
La co-creación es una característica fundamental de Netflix. Por lo tanto, no fue sorprendente cuando los usuarios comenzaron a intercambiar enlaces URL al cuaderno. Con el crecimiento de esta práctica, nos enfrentamos con el problema de la reescritura accidental causada por el acceso simultáneo de varios usuarios a la misma computadora portátil. Nuestros usuarios querían una manera de compartir su computadora portátil activa en modo de solo lectura. Esto condujo a la creación de Commuter . Bajo el capó, Commuter muestra la API de Jupyter para listar / archivos y / api / contenidos en una lista de directorios, para ver el contenido de los archivos y acceder a los metadatos de los archivos. Esto significa que los usuarios pueden ver portátiles sin consecuencias para tareas de combate o portátiles en vivo.
Calcular
Administrar los recursos informáticos es una de las partes más difíciles de trabajar con datos. Esto es especialmente cierto en Netflix, donde utilizamos la arquitectura de contenedor altamente escalable en AWS. Todos los trabajos en la Plataforma de datos se ejecutan en contenedores, incluidas consultas, canalizaciones y portátiles. Naturalmente, queríamos abstraernos lo más posible de esta complejidad.
Se proporciona un contenedor cuando el usuario inicia el servidor portátil. Proporcionamos valores predeterminados racionales para los recursos del contenedor que funcionan para ~ 87.3% de los patrones de ejecución. Cuando esto no es suficiente, los usuarios pueden solicitar más recursos utilizando una interfaz simple.

Los usuarios pueden seleccionar tanto o tan poco cálculo + memoria como necesiten
También proporcionamos un tiempo de ejecución unificado con una imagen de contenedor terminada. La imagen tiene bibliotecas compartidas y un conjunto predefinido de núcleos predeterminados. No todo en la imagen es estático: nuestros núcleos usan las últimas versiones de Spark y las últimas configuraciones de clúster para nuestra plataforma. Esto reduce el desorden y el tiempo de ajuste para las nuevas computadoras portátiles y, en general, nos mantiene en un solo entorno de tiempo de ejecución.
Bajo el capó, gestionamos la orquestación y los entornos con Titus , nuestro servicio de administración de contenedores Docker. Además, creamos un contenedor sobre este servicio, administrando configuraciones e imágenes específicas del servidor de usuario. La imagen también incluye grupos y roles de seguridad del usuario, así como variables de entorno comunes para la identificación en las bibliotecas incluidas. Esto significa que nuestros usuarios pueden pasar menos tiempo en infraestructura y más tiempo en datos.
Interfaz
Anteriormente, describimos nuestra visión de que los portátiles deberían ser la herramienta más efectiva y óptima para trabajar con datos. Pero esto presenta un desafío interesante: ¿cómo puede una interfaz admitir a todos los usuarios? No sabemos la respuesta exacta, pero tenemos algunas ideas.
Sabemos que se necesita simplicidad. Significa una interfaz de usuario intuitiva con un estilo minimalista, y también requiere una experiencia de usuario reflexiva que haga que las cosas complejas sean fáciles de hacer. Esta filosofía encaja bien con los objetivos de nteract , escrita en la interfaz React para el cuaderno Jupyter. Enfatiza la componibilidad como principios de diseño fundamentales, por lo que es una parte ideal de nuestra visión.
La queja más común de nuestros usuarios es la falta de visualización nativa para todos los idiomas, especialmente para los idiomas que no son Python. El Explorador de datos de Nteract es un buen ejemplo de cómo facilitar las cosas complejas al proporcionar una forma independiente del idioma para explorar rápidamente los datos.
Puede ver el Explorador de datos en acción en este ejemplo en MyBinder. (la carga puede tardar varios minutos)

Visualizar el conjunto de datos del Informe de felicidad mundial con el Explorador de datos de nteract
También presentamos soporte incorporado para la parametrización, lo que simplifica la planificación del lanzamiento del cuaderno y crea plantillas reutilizables.
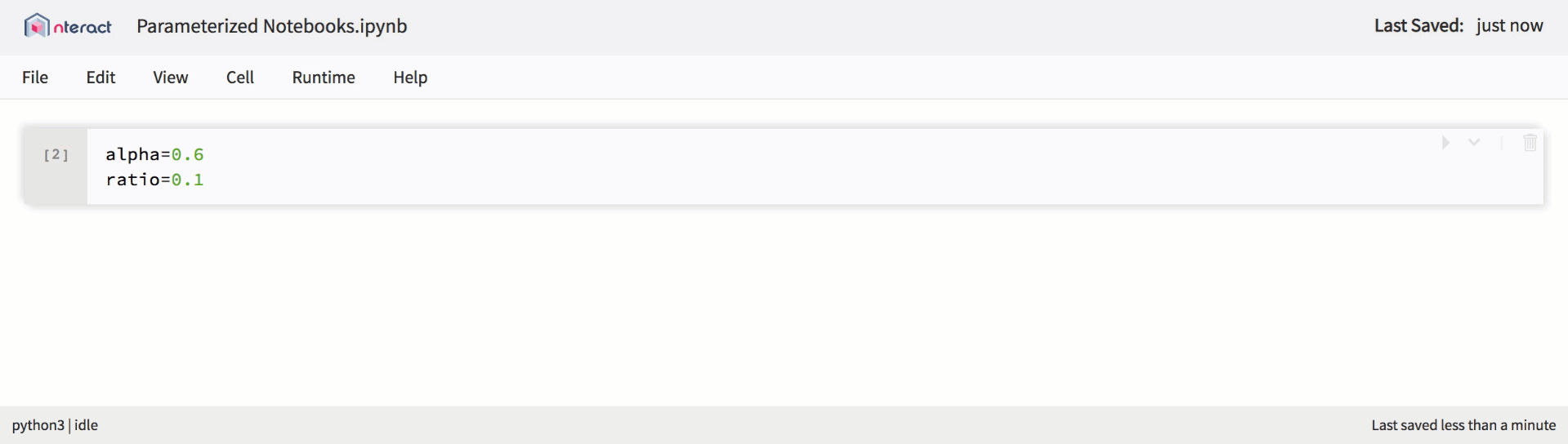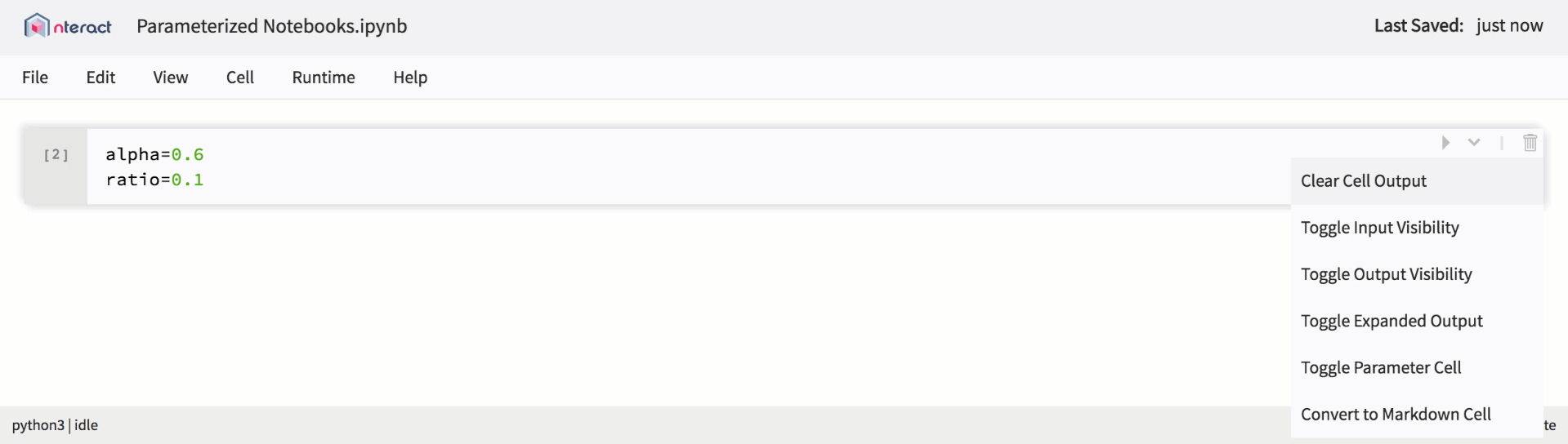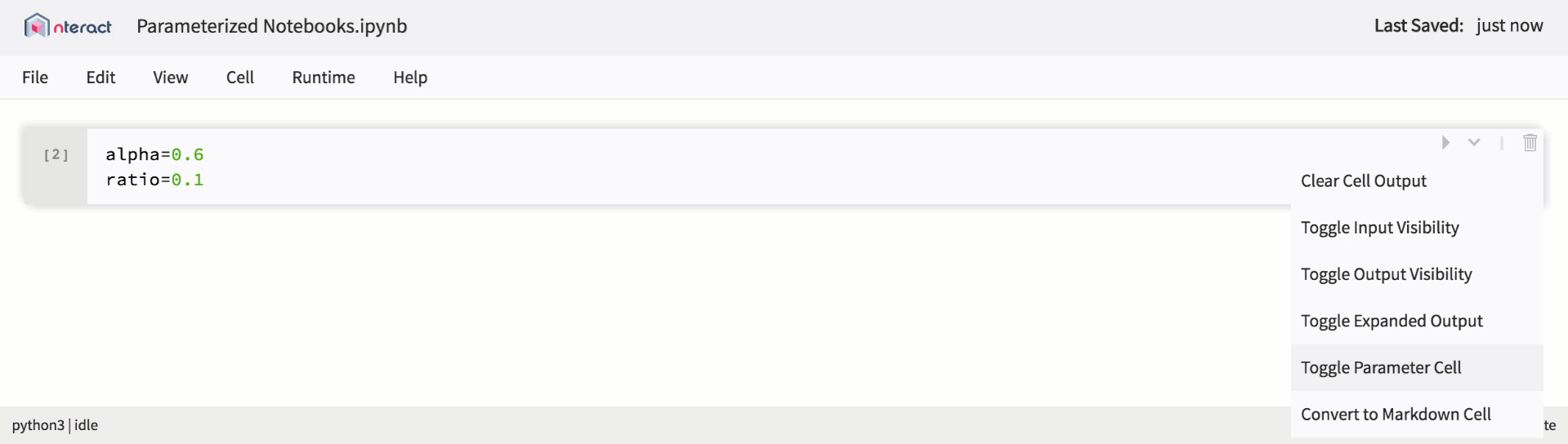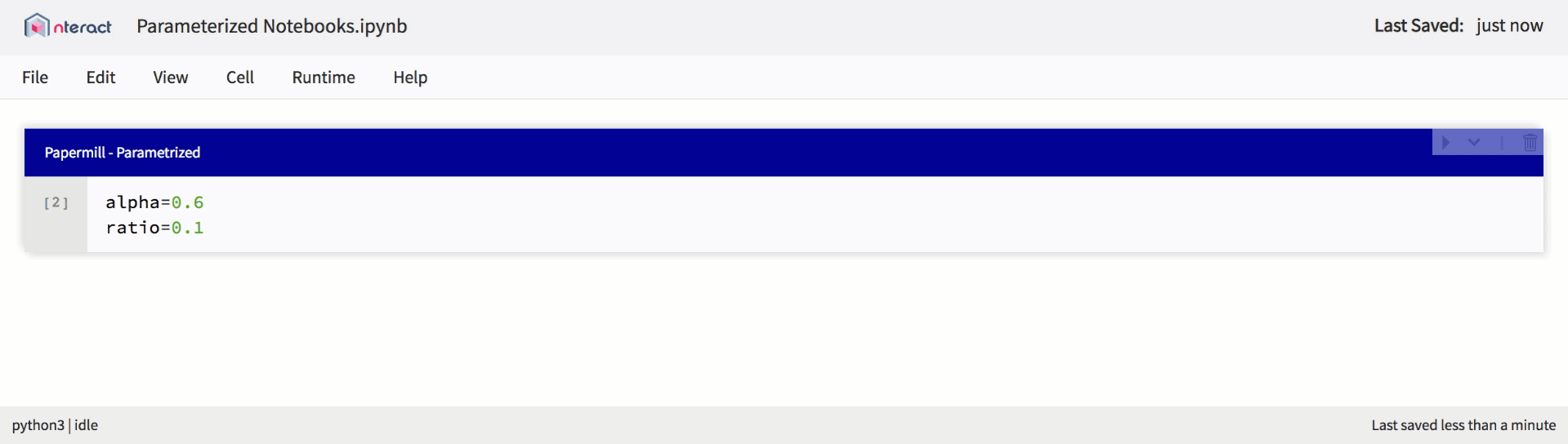
Soporte nativo para portátiles parametrizados en nteract
Jupyter notebook , . , notebook. 12 , . , , , . , , Spark DataFrames, Scala. .
Open Source Projects
Netflix . , , . Netflix Data Platform Netflix OSS . “Not Invented Here”. Spark , Jupyter pandas .
, , Jupyter Project, . , nteract notebook UI Netflix. , . , Jupyter Notebook, , , . nteract.
, Netflix, . , , , , . , Papermill, .
What's Next ( )
, – (Netflixers) . Notebook Netflix. , . , .
! . , notebook. notebook Netflix, . :
I: Notebook Innovation ( )
II: Scheduling Notebooks
:
Scheduling workflows , — .