Recientemente, están hablando cada vez más del análisis estático como uno de los medios importantes para garantizar la calidad de los productos de software que se están desarrollando, especialmente desde el punto de vista de la seguridad. El análisis estático le permite encontrar vulnerabilidades y otros errores, puede usarse en el proceso de desarrollo, integrándose en procesos personalizados. Sin embargo, en relación con su aplicación, surgen muchas preguntas. ¿Cuál es la diferencia entre herramientas pagas y gratuitas? ¿Por qué no es suficiente usar el linter? Al final, ¿qué tiene que ver la estadística con eso? Tratemos de resolverlo.

Respondamos la última pregunta de inmediato: las estadísticas no tienen nada que ver con eso, aunque el análisis estático se denomina erróneamente estadística. El análisis es estático, porque la aplicación no se inicia durante el escaneo.
Primero, descubramos qué queremos buscar en el código del programa. El análisis estático se usa con mayor frecuencia para buscar vulnerabilidades: secciones de código, cuya presencia puede conducir a una violación de la confidencialidad, integridad o disponibilidad del sistema de información. Sin embargo, se pueden usar las mismas tecnologías para buscar otros errores o características de código.
Hacemos una reserva de que, en general, el problema del análisis estático no tiene solución algorítmica (por ejemplo, según el teorema de Rice). Por lo tanto, debe limitar las condiciones de la tarea o permitir imprecisiones en los resultados (omitir vulnerabilidades, dar falsos positivos). Resulta que en programas reales, la segunda opción resulta estar funcionando.
Existen muchas herramientas gratuitas y de pago que reclaman la búsqueda de vulnerabilidades en aplicaciones escritas en diferentes lenguajes de programación. Consideremos cómo se organiza generalmente el analizador estático. Además, nos centraremos en el núcleo del analizador y los algoritmos. Por supuesto, las herramientas pueden diferir en la facilidad de uso de la interfaz, en el conjunto de funciones, en el conjunto de complementos para diferentes sistemas y en la facilidad de uso de la API. Este es probablemente un tema para un artículo separado.
Presentación intermedia
Se pueden distinguir tres pasos básicos en el esquema de operación de un analizador estático.
- Construir una representación intermedia (una representación intermedia también se denomina representación interna o modelo de código).
- El uso de algoritmos de análisis estático, como resultado de lo cual el modelo de código se complementa con nueva información.
- Aplicación de reglas de búsqueda de vulnerabilidad a un modelo de código aumentado.
Los diferentes analizadores estáticos pueden usar diferentes modelos de código, por ejemplo, el código fuente del programa, el flujo de tokens, el árbol de análisis, el código de tres direcciones, el gráfico de flujo de control, el código de bytes (estándar o nativo), etc.

Al igual que los compiladores, el análisis léxico y sintáctico se utiliza para construir una representación interna, a menudo un árbol de análisis (AST, Árbol de sintaxis abstracta). El análisis léxico divide el texto del programa en elementos semánticos mínimos, en la salida recibe una secuencia de tokens. El análisis verifica que la secuencia de tokens coincida con la gramática del lenguaje de programación, es decir, la secuencia de tokens resultante es correcta desde el punto de vista del lenguaje. Como resultado del análisis, se crea un árbol de análisis, una estructura que modela el código fuente del programa. A continuación, se aplica el análisis semántico; verifica el cumplimiento de condiciones más complejas, por ejemplo, la correspondencia de los tipos de datos en las instrucciones de asignación.
El árbol de análisis se puede usar como una representación interna. También puede obtener otros modelos del árbol de análisis. Por ejemplo, puede traducirlo a un código de tres direcciones, que, a su vez, crea un gráfico de flujo de control (CFG). Por lo general, CFG es el modelo principal para los algoritmos de análisis estático.

En el análisis binario (análisis estático de código binario o ejecutable), también se construye un modelo, pero las prácticas de ingeniería inversa ya se utilizan aquí: descompilación, desofuscación, traducción inversa. Como resultado, puede obtener los mismos modelos que el código fuente, incluido el código fuente (utilizando la descompilación completa). A veces, el código binario en sí mismo puede servir como una representación intermedia.
Teóricamente, cuanto más se acerca el modelo al código fuente, peor es la calidad del análisis. En el código fuente en sí, solo puede buscar expresiones regulares, lo que no le permitirá encontrar al menos ninguna vulnerabilidad complicada.
Análisis de flujo de datos.
Uno de los principales algoritmos de análisis estático es el análisis de flujo de datos. La tarea de este análisis es determinar en cada punto del programa cierta información sobre los datos en los que opera el código. La información puede ser diferente, por ejemplo, tipo de datos o valor. Según la información que deba determinarse, se puede formular la tarea de analizar el flujo de datos.

Por ejemplo, si es necesario determinar si una expresión es una constante, así como el valor de esta constante, entonces se resuelve el problema de propagar constantes (propagación constante). Si es necesario determinar el tipo de una variable, entonces podemos hablar sobre el problema de la propagación de tipos. Si necesita comprender qué variables pueden apuntar a un área específica de la memoria (almacenar los mismos datos), entonces estamos hablando de la tarea de análisis de sinónimos (análisis de alias). Hay muchas otras tareas de análisis de flujo de datos que se pueden usar en un analizador estático. Al igual que los pasos para construir un modelo de código, estas tareas también se usan en compiladores.
En la teoría de la construcción de compiladores, se describen soluciones al problema del análisis intraprocesal de un flujo de datos (es necesario rastrear los datos en un solo procedimiento / función / método). Las decisiones se basan en la teoría de las redes algebraicas y otros elementos de las teorías matemáticas. El problema de analizar el flujo de datos se puede resolver en tiempo polinómico, es decir, durante un tiempo aceptable para las computadoras, si las condiciones del problema satisfacen las condiciones del teorema de la capacidad de solución, que en la práctica no siempre ocurre.
Le diremos más sobre cómo resolver el problema del análisis intraprocesal del flujo de datos. Para establecer una tarea específica, además de determinar la información que necesita, debe determinar las reglas para cambiar esta información al pasar datos de acuerdo con las instrucciones en CFG. Recuerde que los nodos en el CFG son los bloques básicos: conjuntos de instrucciones, cuya ejecución siempre es secuencial, y los arcos indican la posible transferencia de control entre los bloques básicos.
Para cada instrucción
se definen conjuntos:
- (información generada por la instrucción ),
- (información destruida por la instrucción ),
- (información en el punto anterior a la instrucción ),
- (información en el punto después de la instrucción )
El objetivo del análisis de flujo de datos es definir conjuntos
y
para cada instrucción
programas El sistema básico de ecuaciones con el que se resuelven las tareas de análisis del flujo de datos está determinado por la siguiente relación (ecuaciones de flujo de datos):
La segunda relación formula las reglas por las cuales la información se "combina" en los puntos de confluencia de los arcos CFG (
- predecesores
en CFG). Se puede utilizar la operación de unión, intersección y algunas otras.
La información deseada (el conjunto de valores de las funciones presentadas anteriormente) se formaliza como una red algebraica. Las funciones
y
se consideran asignaciones monótonas en redes (funciones de flujo). Para las ecuaciones de flujo de datos, la solución es el punto fijo de estas asignaciones.
Los algoritmos para resolver problemas de análisis de flujo de datos buscan puntos máximos fijos. Existen varios enfoques para la solución: algoritmos iterativos, análisis de componentes fuertemente conectados, análisis T1-T2, análisis de intervalo, análisis estructural, etc. Existen teoremas sobre la exactitud de estos algoritmos; determinan el alcance de su aplicabilidad a problemas reales. Repito, las condiciones de los teoremas pueden no cumplirse, lo que conduce a algoritmos más complicados y resultados inexactos.
Análisis interprocedural.
En la práctica, es necesario resolver los problemas del análisis interprocedural del flujo de datos, ya que rara vez la vulnerabilidad se localizará por completo en una función. Hay varios algoritmos comunes.
Funciones en línea . En el punto de llamada de función, incorporamos la función llamada, reduciendo así la tarea de análisis interprocedural a la tarea de análisis intraprocedural. Este método se implementa fácilmente, pero en la práctica, cuando se aplica, se logra rápidamente una explosión combinatoria.
Construir un gráfico general del flujo de control del programa en el que las llamadas de función se reemplazan por transiciones a la dirección de inicio de la función llamada, y las instrucciones de retorno se reemplazan por transiciones a todas las instrucciones siguiendo todas las instrucciones para llamar a esta función. Este enfoque agrega una gran cantidad de rutas de ejecución irrealizables, lo que reduce en gran medida la precisión del análisis.
Un algoritmo similar al anterior, pero cuando se cambia a una función,
el contexto se
guarda , por ejemplo, un marco de pila. Por lo tanto, se resuelve el problema de crear rutas irrealizables. Sin embargo, el algoritmo es aplicable con una profundidad de llamada limitada.
Información de funciones de construcción (resumen de funciones). El algoritmo de análisis interprocedural más aplicable. Se basa en la construcción de un resumen para cada función: las reglas por las cuales la información sobre los datos se convierte al aplicar esta función, dependiendo de los diversos valores de los argumentos de entrada. El resumen listo para usar se utiliza en el análisis interno de procedimientos de funciones. Una dificultad separada aquí es la determinación del orden de la función transversal, ya que en el análisis caso por caso, ya se debe construir un resumen para todas las funciones llamadas. Por lo general, se crean algoritmos iterativos especiales para atravesar un gráfico de llamadas.
El análisis del flujo de datos interprocedimiento es una tarea exponencialmente difícil, por lo que el analizador necesita llevar a cabo una serie de optimizaciones y suposiciones (es imposible encontrar la solución exacta en el tiempo adecuado para la potencia informática). Por lo general, al desarrollar un analizador, es necesario encontrar un compromiso entre la cantidad de recursos consumidos, el tiempo de análisis, la cantidad de falsos positivos y las vulnerabilidades encontradas. Por lo tanto, un analizador estático puede funcionar durante mucho tiempo, consumir muchos recursos y dar falsos positivos. Sin embargo, sin esto es imposible encontrar las vulnerabilidades más importantes.
Es en este punto que los analizadores estáticos serios difieren de muchas herramientas abiertas, que, en particular, pueden posicionarse en la búsqueda de vulnerabilidades. Las comprobaciones rápidas en tiempo lineal son buenas cuando necesita obtener el resultado rápidamente, por ejemplo, durante la compilación. Sin embargo, este enfoque no puede encontrar las vulnerabilidades más críticas, por ejemplo, relacionadas con la implementación de datos.
Análisis de manchas
También deberíamos detenernos en una de las tareas del análisis de flujo de datos: el análisis de contaminación. El análisis de manchas le permite distribuir banderas en todo el programa. Esta tarea es clave para la seguridad de la información, ya que es con la ayuda de ella que se descubren vulnerabilidades relacionadas con la implementación de datos (inyección SQL, scripts de crossite, redirecciones abiertas, falsificación de la ruta del archivo, etc.), así como la fuga de datos confidenciales (entrada de contraseña en registros de eventos, transferencia de datos insegura).
Intentemos simular una tarea. Supongamos que queremos rastrear n banderas -
. Mucha información aquí será una gran cantidad de subconjuntos
\ {f_1, ..., f_n \} , ya que para cada variable en cada punto del programa queremos definir sus banderas.
A continuación, necesitamos definir las funciones de flujo. En este caso, las funciones de flujo se pueden determinar mediante las siguientes consideraciones.
- Se dan muchas reglas en las que se definen las construcciones que conducen a la aparición o al cambio de un conjunto de banderas.
- La operación de asignación voltea las banderas de derecha a izquierda.
- Cualquier operación desconocida para conjuntos de reglas combina indicadores de todos los operandos y el conjunto final de indicadores se agrega a los resultados de la operación.
Finalmente, debe definir las reglas para fusionar información en los puntos de unión de los arcos CFG. La fusión está determinada por la regla de unión, es decir, si diferentes conjuntos de banderas para una sola variable provienen de diferentes bloques base, entonces se fusionan cuando se fusionan. Aquí se incluyen falsos positivos: el algoritmo no garantiza que se pueda ejecutar la ruta al CFG en el que apareció la bandera.
Por ejemplo, necesita detectar vulnerabilidades como la inyección SQL. Esta vulnerabilidad se produce cuando los datos no verificados del usuario entran en los métodos de trabajo con la base de datos. Es necesario determinar que los datos provienen del usuario y agregar el indicador de contaminación a estos datos. Por lo general, la base de reglas del analizador establece las reglas para establecer el indicador de contaminación. Por ejemplo, establezca un indicador en el valor de retorno del método getParameter () de la clase Request.
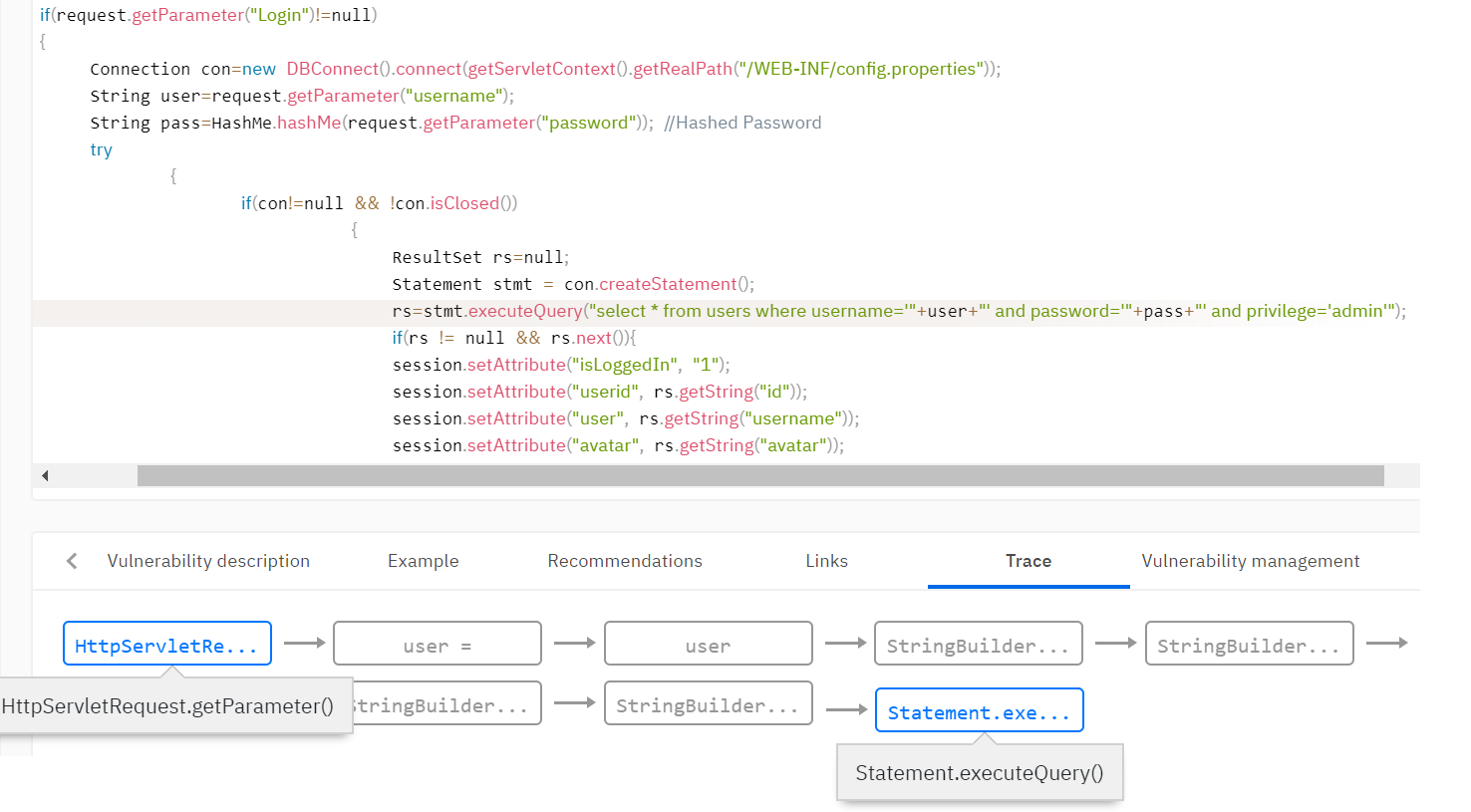
A continuación, debe distribuir el indicador en todo el programa analizado mediante el análisis de contaminación, dado que los datos se pueden validar y el indicador puede desaparecer en una de las rutas de ejecución. El analizador establece muchas funciones que eliminan las banderas. Por ejemplo, la función de validar datos de etiquetas html puede borrar el indicador de vulnerabilidades de scripting entre sitios (XSS). O bien, la función para vincular una variable a una expresión SQL elimina el indicador para incrustar en SQL.
Reglas de búsqueda de vulnerabilidad
Como resultado de aplicar los algoritmos anteriores, la representación intermedia se complementa con la información necesaria para buscar vulnerabilidades. Por ejemplo, en el modelo de código, aparece información sobre qué variables pertenecen a ciertas banderas, qué datos son constantes. Las reglas de búsqueda de vulnerabilidad se formulan en términos de un modelo de código. Las reglas describen qué características en la vista intermedia final pueden indicar una vulnerabilidad.
Por ejemplo, puede aplicar una regla de búsqueda de vulnerabilidad que defina una llamada a un método con un parámetro que tenga el indicador de contaminación. Volviendo al ejemplo de la inyección SQL, verificamos que las variables con el indicador de contaminación no caen en la función de consulta de la base de datos.
Resulta que una parte importante del analizador estático, además de la calidad de los algoritmos, es la configuración y la base de la regla: una descripción de qué construcciones en el código generan indicadores u otra información, qué construcciones validan dichos datos, y para cuáles construcciones el uso de dichos datos es crítico.
Otros enfoques
Además del análisis del flujo de datos, existen otros enfoques. Uno de los famosos es la ejecución simbólica o la interpretación abstracta. En estos enfoques, el programa se ejecuta en dominios abstractos, el cálculo y la distribución de restricciones de datos en el programa. Con este enfoque, uno no solo puede encontrar la vulnerabilidad, sino también calcular las condiciones en los datos de entrada bajo los cuales la vulnerabilidad es explotable. Sin embargo, este enfoque tiene serios inconvenientes: con soluciones estándar en programas reales, los algoritmos explotan exponencialmente y las optimizaciones conducen a graves pérdidas en la calidad del análisis.
Conclusiones
Al final, creo que vale la pena resumirlo, hablando de los pros y los contras del análisis estático. Es lógico que lo comparemos con el análisis dinámico, en el que la búsqueda de vulnerabilidad se produce durante la ejecución del programa.

La ventaja indudable del análisis estático es la cobertura completa del código analizado. Además, las ventajas del análisis estático incluyen el hecho de que para ejecutarlo no es necesario ejecutar la aplicación en un entorno de combate. El análisis estático se puede implementar en las primeras etapas de desarrollo, minimizando el costo de las vulnerabilidades encontradas.
Las desventajas del análisis estático son la presencia inevitable de falsos positivos, el consumo de recursos y un largo tiempo de exploración en grandes cantidades de código. Sin embargo, estas desventajas son inevitables, según los detalles de los algoritmos. Como vimos, un analizador rápido nunca encontrará una vulnerabilidad real como la inyección SQL y similares.
Escribimos en
otro artículo sobre las dificultades restantes del uso de herramientas de análisis estático, que, como resultado, se pueden superar bastante bien.