¡Continuamos la historia de cómo reconocer las placas para aquellos que pueden escribir la aplicación hello world en python! En esta parte, aprenderemos cómo entrenar modelos que buscan una región de un objeto determinado, y también aprender a escribir una red RNN simple que pueda leer los números mejor que algunas contrapartes comerciales.
En esta parte, le diré cómo entrenar a Nomeroff Net para sus datos, cómo obtener una alta calidad de reconocimiento, cómo configurar el soporte de GPU y acelerar todo en un orden de magnitud ...
Entrenamos a Mask RCNN para encontrar el área con el número
Por supuesto, puede encontrar no solo un número, sino cualquier otro objeto que necesite encontrar. Por ejemplo, puede, por analogía, buscar una tarjeta de crédito y leer sus detalles. En general, encontrar la máscara en la que se inscribe el objeto en la imagen se denomina tarea "Segmentación de instancias" (ya escribí sobre esto en la primera parte).
Ahora descubriremos cómo entrenar a la red para resolver este problema. De hecho, hay poca programación aquí, todo se reduce a un marcado de datos monótono, tedioso y uniforme. Sí, sí, después de marcar tus primeros cien entenderás lo que quiero decir :)
Entonces, el algoritmo de preparación de datos es el siguiente:
- Tomamos imágenes de al menos 300x300 de tamaño, volcamos todo en una carpeta
- Descargue la herramienta de marcado VGG Image Annotator (VIA) , puede marcarlo en línea , el resultado será un directorio con una foto y el archivo json que creó con el marcado. Hay dos carpetas de este tipo, en la llamada tren poner la parte principal de los ejemplos, en el segundo valor aproximadamente 20-30% del número de ejemplos del primer paquete (Por supuesto, estas carpetas no deberían tener las mismas fotos). Puede ver un ejemplo de datos etiquetados para el proyecto Nomeroff Net . Por cantidad, cuanto más mejor. Algunos expertos recomiendan 5,000 ejemplos, somos perezosos, escribimos un poco más de 1,000 ya que el resultado fue bastante bueno para nosotros.

- Para comenzar a entrenar, debe descargar el proyecto Nomeroff Net en sí desde Github, instalar Mask RCNN con todas las dependencias y puede intentar ejecutar el script de entrenamiento train / mrcnn.ipynb en nuestros datos
- Te advierto de inmediato, esto no funciona rápido. Si no tiene una GPU, esto puede llevar días. Para acelerar significativamente el proceso de aprendizaje, es recomendable instalar tensorflow con soporte de GPU .
- Si la capacitación en nuestro conjunto de datos fue exitosa, ahora puede cambiar de manera segura a la suya.
Tenga en cuenta: no entrenamos todo desde cero, entrenamos el modelo entrenado en los datos del conjunto de datos COCO , que Mask RCNN descarga en la primera ejecución
- Puede entrenar no coco, pero nuestro modelo mask_rcnn_numberplate_0700.h5 , y especificar la ruta a este modelo en el parámetro de configuración PESOS (por defecto, "PESOS": "coco")
- De los parámetros que se pueden ampliar son: EPOCH, STEPS_PER_EPOCH
- El resultado después de cada era se volcará a la carpeta ./logs/numberplate<date of launch> /
Para probar el modelo entrenado en la práctica, en los
ejemplos del
proyecto, reemplace
MASK_RCNN_MODEL_PATH con la ruta a su modelo.
Mejorando el clasificador de matrículas a sus requerimientos
Después de encontrar las áreas con placas de matrícula, debe intentar determinar qué estado / tipo de número reconocemos. Aquí la universalización va en contra de la calidad del reconocimiento. Por lo tanto, idealmente, debe capacitar a un clasificador que no solo determine de qué país es el número, sino también el tipo de diseño de este número (ubicación de caracteres, opciones de símbolos para un tipo de número dado).
En nuestro proyecto, implementamos soporte para reconocer los números de Ucrania, la Federación de Rusia y los números europeos en general. La calidad de reconocimiento de los números europeos es ligeramente peor, ya que hay números con diferentes diseños y un mayor número de caracteres encontrados. Quizás, con el tiempo, habrá módulos de reconocimiento separados para "eu-ee", "eu-pl", "eu-nl", ...
Antes de clasificar una placa de matrícula, debe "recortarla" de la imagen y normalizarla, en otras palabras, eliminar todas las distorsiones al máximo y obtener un rectángulo limpio que será sometido a un análisis posterior. Esta tarea resultó ser bastante trivial, incluso tuve que recordar las matemáticas escolares y escribir una implementación especializada del algoritmo de agrupación k-means :). El módulo que procesa esto se llama RectDetector, así es como se ven los números normalizados, que luego clasificaremos y reconoceremos.

Para automatizar de alguna manera el proceso de creación de un conjunto de datos para clasificar números, desarrollamos un
pequeño panel de administración en nodejs . Con este panel de administración, puede marcar la inscripción en la placa y la clase a la que pertenece.
Puede haber varios clasificadores. En nuestro caso, por tipo de número y si está esbozado / pintado en la foto.
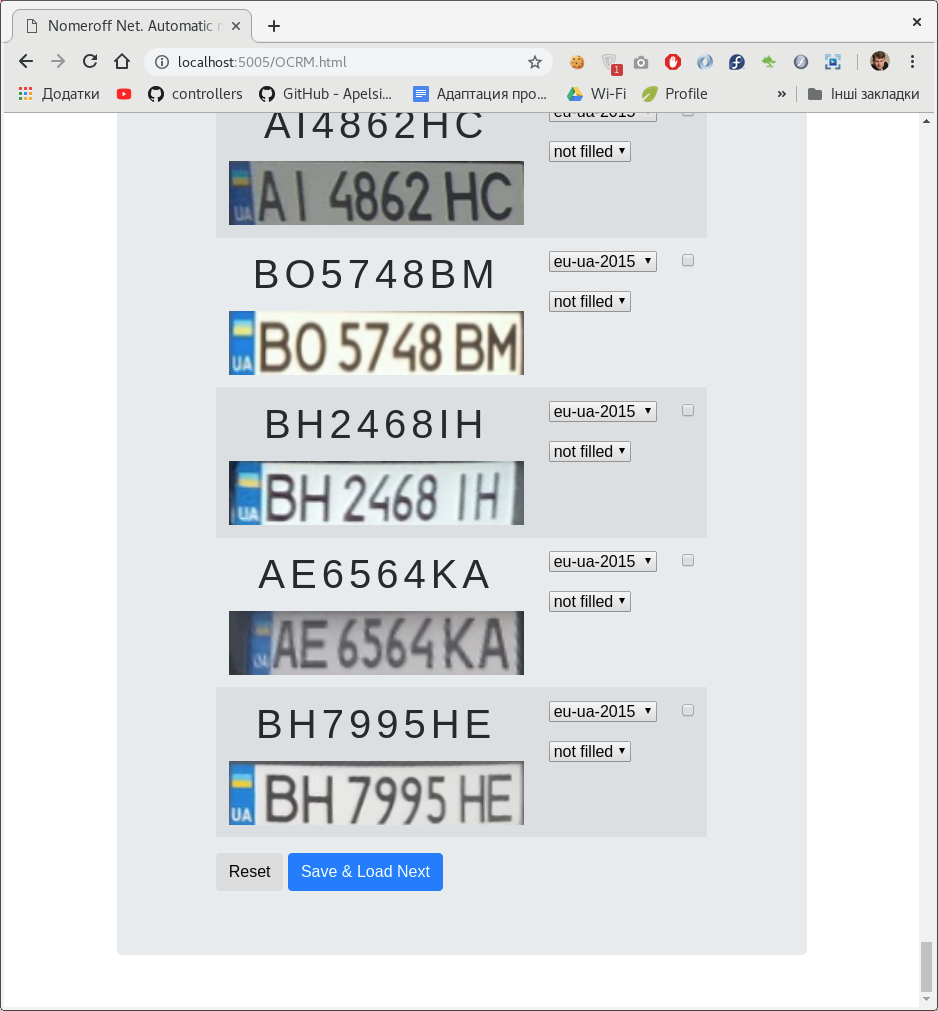
Después de marcar el conjunto de datos, lo dividimos en muestras de capacitación, validación y prueba. Como ejemplo, descargue nuestro
conjunto de
datos autoriaNumberplateOptions3Dataset-2019-05-20.zip para ver cómo
funciona todo allí.
Como la selección ya se ha marcado (moderado), debe cambiar "isModerated": 1 a "isModerated": 0 en archivos json aleatorios y luego iniciar el panel de administración .
Entrenamos el clasificador:
El script de entrenamiento
train / options.ipynb te ayudará a obtener tu versión del modelo. Nuestro ejemplo muestra que para la clasificación de regiones / tipos de matrículas, obtuvimos una precisión del
98.8% , para la clasificación de "¿Se ha pintado el número?"
99.4% en nuestro conjunto de datos. De acuerdo, resultó bien.
Entrene su OCR (reconocimiento de texto)
Bueno, encontramos el área con el número y la normalizamos en un rectángulo que contiene la inscripción con el número. ¿Cómo leemos el texto? La forma más fácil es ejecutarlo a través de FineReader o Tesseract. La calidad será "no muy", pero con una buena resolución del área con el número puede obtener una precisión del 80%. En realidad, esto no es una mala precisión, pero si te digo que puedes obtener el
97% y al mismo tiempo gastar significativamente menos recursos de computadora. Suena bien, intentémoslo. Una arquitectura ligeramente inusual es adecuada para estos fines, en la que se utilizan tanto capas convolucionales como recurrentes. La arquitectura de esta red se parece a esto:
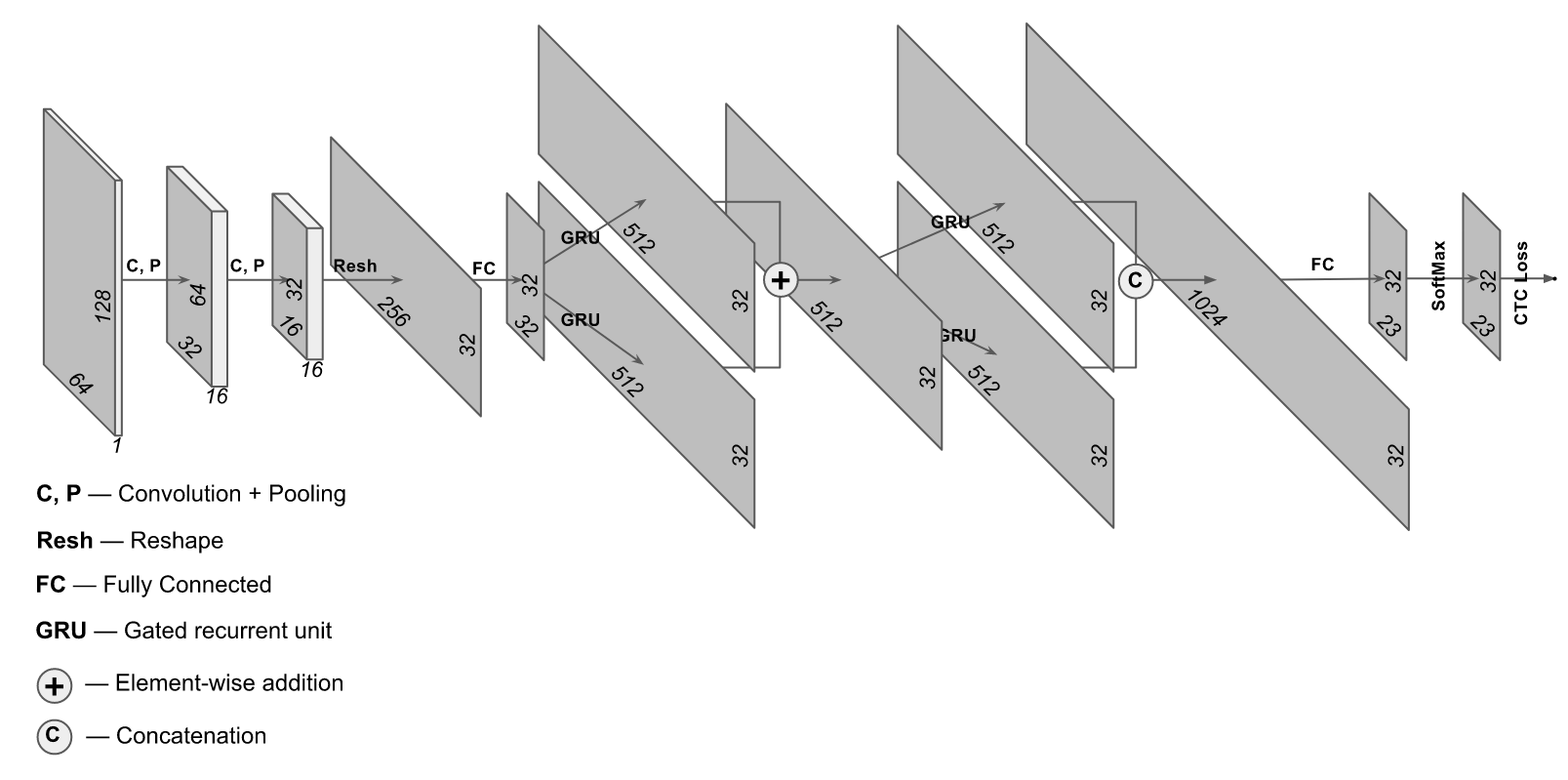
La implementación se tomó del sitio
https://supervise.ly/ , la modificamos un poco para entrenar en fotos reales (en el sitio web supervisado, se hizo una opción para el muestreo sintético)
Ahora comienza la parte divertida, marca al menos 5,000 números :). Marcamos alrededor de
~ 100,000 ucranianos ,
~ 50,000 ucranianos con el diseño "antiguo" ,
~ 6,500 europeos ,
~ 10,000 RF . Esta fue la parte más difícil del desarrollo. Ni siquiera puedes imaginar cuántas veces me quedé dormido en una silla de computadora moderando varias horas al día para la siguiente porción de números. Pero el verdadero héroe del marcado es
dimabendera : marcó 2/3 de todo el contenido (dale un plus si entiendes lo aburrido que fue hacer todo este trabajo :))
Puede intentar automatizar de alguna manera este proceso, por ejemplo, habiendo reconocido previamente cada imagen con Tesseract, y luego corregir los errores utilizando
nuestro panel de administración .
Tenga en cuenta: el mismo panel de administración se utiliza para marcar el clasificador y el OCR en el número. Puede cargar los mismos datos tanto allí como allí, a excepción de los números bosquejados, por supuesto.
Si marca al menos 5000 números y puede entrenar su OCR, no dude en organizar un premio para usted con sus superiores, ¡estoy seguro de que esta prueba no es para débiles!
Comenzando a entrenar
El
script train / ocr-ru.ipynb entrena el modelo para números rusos, hay ejemplos para
Ucrania y
Europa .
Tenga en cuenta que en la configuración de entrenamiento solo hay una era (un pase).
Una característica del entrenamiento de este conjunto de datos será un resultado muy diferente para cada intento, antes de cada sesión de entrenamiento, los datos se mezclan en orden aleatorio, a veces es más exitoso para el entrenamiento, a veces no muy. Le recomiendo que lo intente al menos 5 veces, mientras controla la precisión de los datos de prueba. Con diferentes intentos de lanzamiento, nuestra precisión podría "saltar" del
87% al 97% .
Algunas recomendaciones :
- No es necesario inicializar todo de una manera nueva, solo reinicie la línea model = ocrTextDetector.train (mode = MODE) hasta obtener el resultado esperado
- Una razón para la precisión deficiente es la insuficiencia de datos. Si no le gusta, lo marcamos una y otra vez, en algún momento la calidad deja de crecer, para cada conjunto de datos es diferente, puede concentrarse en la cantidad de 10,000 ejemplos etiquetados
- El entrenamiento será más rápido si tiene instalado el controlador NVIDIA CuDNN , cambie el valor MODE = "gpu" en el script de entrenamiento y CuDNNGRU se conectará en lugar de la capa GRU, lo que conducirá a una aceleración triple.
Un poco sobre la configuración de tensorflow para GPU NVIDIA
Si eres un feliz propietario de una GPU de NVIDIA, entonces puedes acelerar las cosas a veces: tanto el modelo de entrenamiento como los números de inferencia (modo de reconocimiento). El problema es instalar y compilar todo correctamente.
Usamos Fedora Linux en nuestros servidores ML (esto sucedió históricamente).
La secuencia aproximada de acciones para quienes usan este sistema operativo es la siguiente:
- Ponemos el controlador de GPU para su versión del sistema operativo, aquí para Fedora
- Conectamos el repositorio de NVIDIA e instalamos el paquete CUDA desde allí, aquí para CentOS / Fedora
- Ponemos bazel y recopilamos tensorflow de las fuentes en este muelle
- También es recomendable instalar la versión anterior del compilador gcc, llamada cuda-gcc, todo me iba bien en cuda-gcc 6.4. Al configurar el ensamblaje, especifique la ruta a cuda-gcc
Si no puede compilar tensorflow con soporte de gpu, puede ejecutar todo a través de docker, y además de docker, debe instalar el paquete nvidia-docker2. Dentro del contenedor acoplable, puede ejecutar jupyter notebook y luego ejecutar todo allí.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Enlaces utiles
También quiero agradecer a los usuarios de 2expres,
glassofkvass habrayusers por proporcionar las fotos con los números y
dimabendera por escribir la mayor parte del código y marcar la mayoría de los datos del proyecto Nomeroff Net.
UPD1: Dado que I y Dmitri se envían a las preguntas estándar de PM sobre el reconocimiento de números, una combinación de tensorflow con gpu, etc. y Dmitry y yo damos las mismas respuestas, quiero optimizar de alguna manera este proceso.
Sugerimos que la correspondencia en los comentarios sea más estructurada, dividida por tema. Hay una funcionalidad conveniente en GitHub para esto. En el futuro, haga preguntas no en los comentarios, sino en el
tema temático sobre github Nomeroff NetUPD2: Con el tiempo, también aparecieron conjuntos de datos:
números kazajos ,
números georgianos