¿Te sucedió que te aferras a algún tipo de juego simple, pensando que la inteligencia artificial podría hacer frente a él? Solía hacerlo, y decidí tratar de crear un reproductor bot de este tipo. Además, ahora hay muchas herramientas para la visión por computadora y el aprendizaje automático que le permiten construir modelos sin una comprensión profunda de los detalles de implementación. Los mortales ordinarios pueden hacer un prototipo sin construir redes neuronales durante meses desde cero.

Debajo del corte, encontrará el proceso de creación de un bot de prueba de concepto para el juego Clash Royale, en el que utilicé las bibliotecas Scala, Python y CV. Utilizando la visión por computadora y el aprendizaje automático, intenté crear un bot para un juego que interactúa como un jugador en vivo.
Mi nombre es Sergey Tolmachev, soy desarrollador principal de Scala en la plataforma Waves y enseño
un curso de Scala en el distrito binario, y en mi tiempo libre estudio otras tecnologías, como la IA. Y quería reforzar las habilidades adquiridas con algo de experiencia práctica. A diferencia de las competiciones de IA, donde tu bot juega contra los bots de otros usuarios, Clash Royale puede jugar contra personas, lo que suena divertido. ¡Tu bot puede aprender a vencer a jugadores reales!
Mecánica del juego en Clash Royale
La mecánica del juego es bastante simple. Tú y tu oponente tienen tres edificios: una fortaleza y dos torres. Los jugadores antes del juego recogen mazos: 8 unidades disponibles, que luego se usan en la batalla. Tienen diferentes niveles, y se pueden bombear, recolectando más tarjetas de estas unidades y comprando actualizaciones.
Después del comienzo del juego, puedes colocar las unidades disponibles a una distancia segura de las torres enemigas, mientras gastas unidades de maná, que se restauran lentamente durante el juego. Las unidades se envían a los edificios enemigos y son distraídas por los enemigos que se encuentran en el camino. El jugador solo puede controlar la posición inicial de las unidades; solo puede afectar su movimiento y daño adicionales configurando otras unidades.
Todavía hay hechizos que se pueden jugar en cualquier parte del campo, generalmente causan daño a las unidades de diferentes maneras. Los hechizos pueden clonar, congelar o acelerar unidades en un área.
El objetivo del juego es destruir edificios enemigos. Para una victoria completa, debes destruir la fortaleza o después de dos minutos del juego destruir más edificios (las reglas dependen de los modos de juego, pero en general suenan así).
Durante el juego, debes tener en cuenta el movimiento de las unidades, el número posible de maná y las cartas enemigas actuales. También debe considerar cómo la instalación de la unidad afecta el campo de juego.
Construyendo una solución
Clash Royale es un juego móvil, así que decidí ejecutarlo en Android e interactuar con él a través de ADB. Esto apoyaría el trabajo con el simulador o con un dispositivo real.
Decidí que el bot, como muchas otras IA de juegos, debería funcionar en el algoritmo de Percepción-Análisis-Acción. Todo el entorno del juego se muestra en la pantalla, y la interacción con él se produce al hacer clic en la pantalla. Por lo tanto, el bot debe ser un programa cuya entrada describa el estado actual del juego: la ubicación y características de las unidades y edificios, las posibles cartas actuales y la cantidad de maná. En la salida, el bot debe dar una matriz de coordenadas donde la unidad debe ser grabada.
Pero antes de crear el bot en sí, era necesario resolver el problema de extraer información sobre el estado actual del juego de la captura de pantalla. En general, el contenido adicional del artículo está dedicado a esta tarea.
Para resolver este problema, decidí usar Computer Vision. Quizás esta no sea la mejor solución: un CV sin mucha experiencia y recursos claramente tiene limitaciones y no puede reconocer todo a nivel humano.
Sería más preciso tomar datos de la memoria, pero no tenía esa experiencia. Se requiere root y, en general, esta solución parece más complicada. Tampoco está claro si la velocidad en tiempo real se puede lograr aquí si busca objetos con una JVM de montón dentro del dispositivo. Además, quería resolver el problema de CV más que esto.
En teoría, uno podría hacer un servidor proxy y tomar información de allí. Pero el protocolo de red del juego a menudo cambia, aparecen proxies en Internet, pero rápidamente se vuelven obsoletos y no son compatibles.
Recursos de juego disponibles
Para empezar, decidí familiarizarme con los materiales disponibles del juego. Encontré un
club de artesanos sacando recursos de juego repletos
[1] [2] . En primer lugar, me interesaban las imágenes de unidades, pero en el paquete de juego desempaquetado se presentan en forma de un mapa en mosaico (partes de las cuales consta una unidad).
También encontré guiones pegados (aunque no perfectos) de cuadros de animación de unidad: fueron útiles para entrenar el modelo de reconocimiento.

Además, en los recursos puedes encontrar csv con varios datos del juego: la cantidad de HP, el daño a unidades de diferentes niveles, etc. Esto es útil al crear lógica de bot. Por ejemplo, a partir de los datos quedó claro que el campo se dividió en 18 x 29 celdas, y las unidades solo se pueden colocar en ellas. También había todas las imágenes de mapas de unidades, que nos serán útiles más adelante.
Visión por computadora para los perezosos
Después de buscar soluciones CV disponibles, quedó claro que, en cualquier caso, tendrían que ser capacitados en un conjunto de datos etiquetado. Tomé capturas de pantalla y ya estaba listo para marcar un cierto número de capturas de pantalla con mis manos. Esto resultó ser un desafío.
Encontrar programas de reconocimiento disponibles tomó algo de tiempo. Me
decidí por
labelImg . Todas las aplicaciones de anotación que encontré eran bastante primitivas: muchas no admitían atajos de teclado, la selección de objetos y sus tipos se hizo mucho menos conveniente que en labelImg.
Durante el marcado, resultó útil tener el código fuente de la aplicación. Tomé capturas de pantalla cada dos segundos del partido. Hay muchos objetos en las capturas de pantalla (por ejemplo, un ejército de esqueletos), e hice una modificación en labelImg: de forma predeterminada, al marcar la siguiente imagen, se tomaron las etiquetas de la anterior. A menudo, simplemente tenían que ser movidos a una nueva posición de las unidades, eliminar las unidades muertas y agregar algunas aparecidas, y no marcar desde cero.

El proceso resultó ser intensivo en recursos: en dos días en modo silencioso, publiqué unas 200 capturas de pantalla. La muestra parece muy pequeña, pero decidí comenzar a experimentar. Siempre puede agregar más ejemplos y mejorar la calidad del modelo.
En el momento del marcado, no sabía qué herramienta de capacitación usaría, así que decidí guardar los resultados del marcado en el formato VOC, uno de los conservadores y aparentemente universal.
Puede surgir la pregunta: ¿por qué no buscar imágenes de unidades píxel por píxel por coincidencia completa? El problema es que para esto tendría que buscar una gran cantidad de diferentes cuadros de animación de diferentes unidades. Difícilmente funcionaría. Quería hacer una solución universal que admita diferentes permisos. Además, las unidades pueden tener un color diferente según el efecto que se les aplique: congelación, aceleración.
¿Por qué elegí YOLO?
Comencé a explorar posibles soluciones de reconocimiento de imágenes. Miré la aplicación de varios algoritmos: OpenCV, TensorFlow, Torch. Quería hacer el reconocimiento lo más rápido posible, incluso sacrificar la precisión, y obtener POC lo antes posible.
Después de leer los
artículos , me di cuenta de que mi tarea no encaja con los clasificadores HOG / LBP / SVM / HAAR / ... Aunque son rápidos, tendrían que aplicarse muchas veces, según el clasificador de cada unidad, y luego uno por uno para aplicarlos a la imagen para la búsqueda. Además, su principio de funcionamiento en teoría daría malos resultados: las unidades pueden tener una forma diferente, por ejemplo, cuando se mueven hacia la izquierda y hacia arriba.
Teóricamente, utilizando una red neuronal, puede aplicarla una vez a una imagen y obtener todas las unidades de diferentes tipos con su posición, por lo que comencé a buscar redes neuronales. TensorFlow ha encontrado soporte para redes neuronales convolucionales (CNN). Resultó que no es necesario entrenar redes neuronales desde cero: puede
volver a entrenar la poderosa red existente .
Luego encontré un algoritmo YOLO más práctico, que promete menos complejidad y, por lo tanto, tenía que proporcionar un algoritmo de búsqueda de alta velocidad sin sacrificar mucha precisión (y en algunos casos, superar otros modelos).
El sitio web de YOLO promete una gran diferencia de velocidad utilizando el modelo pequeño y una red más pequeña y optimizada. YOLO también le permite volver a entrenar la red neuronal terminada para su tarea, y
darknet , un marco de código abierto para usar varias neuronas cuyos creadores desarrollaron YOLO, es una aplicación C nativa simple, y todo el trabajo con ella ocurre a través de sus llamadas de parámetros.
TensorFlow, escrito en Python, es de hecho una biblioteca de Python y se usa usando scripts escritos por usted mismo que necesita descifrar o refinar para satisfacer sus necesidades. Probablemente, para algunos, la flexibilidad de TensorFlow es una ventaja, pero sin entrar en detalles, es casi imposible tomarlo rápidamente y usarlo. Por lo tanto, en mi proyecto, la elección recayó en YOLO.
Edificio modelo
Para trabajar en la capacitación de modelos, instalé Ubuntu 18.10, entregué paquetes de ensamblaje, el paquete OpenCL de NVIDIA y otras dependencias, y construí darknet.
Github tiene una
sección con pasos simples para volver a
entrenar el modelo YOLO : debe descargar el modelo y las configuraciones, cambiarlos y comenzar a volver a entrenar.
Primero quería intentar volver a entrenar un modelo simple de YOLO, luego Tiny y compararlos. Sin embargo, resultó que para entrenar modelos simples, necesita 4 GB de memoria de tarjeta de video, y solo tuve una tarjeta gráfica NVIDIA GeForce GTX 1060 de 3 GB comprada para juegos. Por lo tanto, pude entrenar inmediatamente solo el modelo Tiny.
El marcado de las unidades en las imágenes que tenía estaba en formato VOC, y YOLO funcionaba con su propio formato, así que utilicé la utilidad
convert2Yolo para convertir archivos de anotaciones.
Después de una noche de entrenamiento en mis 200 capturas de pantalla, obtuve los primeros resultados, y me sorprendieron: ¡el modelo realmente pudo reconocer algo correctamente! Me di cuenta de que me estaba moviendo en la dirección correcta y decidí hacer más ejemplos de enseñanza.

No quería continuar diseñando capturas de pantalla, y recordaba los cuadros de las animaciones de la unidad. Marqué todas las imágenes pequeñas con sus clases e intenté entrenar a la red en este set. El resultado fue muy malo. Supongo que el modelo no pudo seleccionar los patrones correctos de imágenes pequeñas para usar en imágenes grandes.
Después de eso, decidí colocarlos en fondos ya preparados de campos de batalla y crear programáticamente un archivo de marcado VOC. Resultó una captura de pantalla sintética con un diseño automático 100% preciso.
Escribí un script en Scala que divide la captura de pantalla en 16 cuadrados de 4x4 y establece las unidades en su centro para que no se crucen entre sí. El guión también me permitió personalizar la creación de ejemplos de entrenamiento: al recibir daño, las unidades se pintan en el color de su equipo (rojo / azul), y durante la clasificación reconozco por separado las unidades de diferentes colores. Además de las manchas, las unidades de diferentes equipos que recibieron daños tienen ligeras diferencias en la vestimenta. Además, aumenté y disminuí aleatoriamente un poco las unidades, de modo que el modelo aprendió a no depender mucho del tamaño de la unidad. Como resultado, aprendí a crear decenas de miles de ejemplos de entrenamiento que son aproximadamente similares a las capturas de pantalla reales.
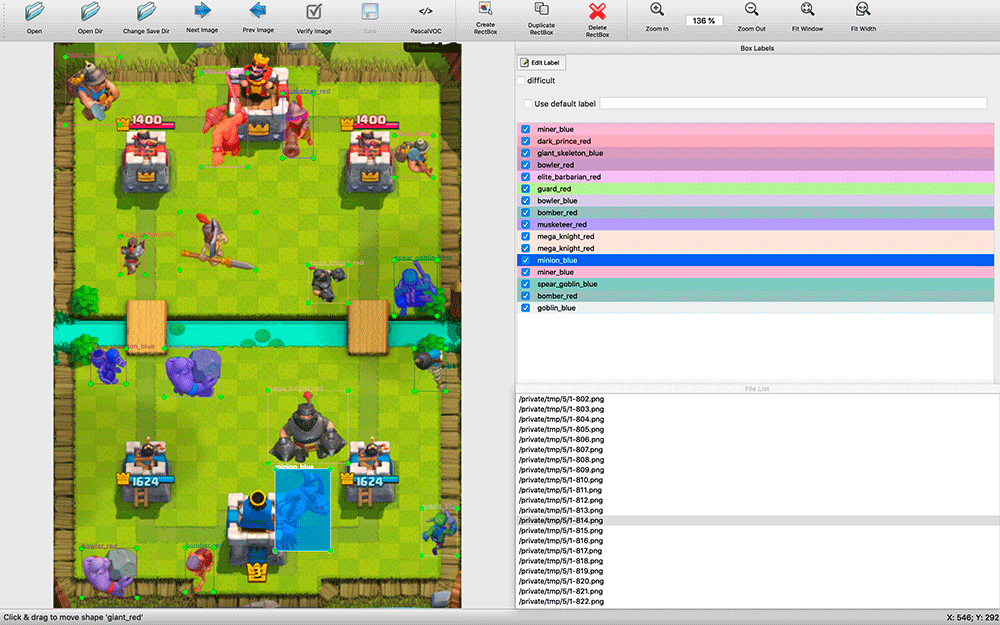
La generación no fue perfecta. A menudo, las unidades se colocaban en la parte superior de los edificios, aunque en el juego estarían detrás de ellos; no hubo ejemplos de partes superpuestas de la unidad, aunque esta no es una situación rara en el juego. Pero hasta ahora decidí descuidarlo.

El modelo obtenido después de varias noches de entrenamiento en una mezcla de 200 capturas de pantalla reales y 5,000 imágenes generadas que se recrearon durante el proceso de entrenamiento una vez al día, cuando se probaron en estas capturas de pantalla, arrojaron malos resultados. No es sorprendente, porque las imágenes generadas tienen muchas diferencias con las reales.
Por lo tanto, puse el modelo resultante para volver a entrenar en una muestra media, en la que solo había 200 de mis capturas de pantalla. Después de eso, ella comenzó a trabajar mucho mejor.
Maldita vergüenzaPido disculpas por manejar medidas tan poco científicas como "mucho mejor", pero no sé cómo validar rápidamente las imágenes, por lo que probé varias capturas de pantalla de un conjunto sin entrenamiento y busqué para ver si los resultados me satisfacen. Esto es lo más importante. Somos perezosos y estamos haciendo un prototipo, ¿verdad?
Los siguientes pasos para mejorar el modelo fueron comprensibles: marque con sus manos capturas de pantalla más reales y capacítelas en el modelo, pre-entrenadas en las capturas de pantalla generadas.
Vamos al bot
Decidí escribir un bot en Python: tiene muchas herramientas disponibles para ML. Decidí usar mi modelo con OpenCV, que desde
3.5 aprendí a usar modelos de redes neuronales , e incluso encontré un
ejemplo simple . Después de probar varias bibliotecas para trabajar con ADB, elegí
pure-python-adb ; todo lo que necesito simplemente se implementa allí: la función de captura de pantalla y la operación en el dispositivo shell; Toco usando el 'toque de entrada'.
Entonces, habiendo recibido una captura de pantalla del juego, reconociendo las unidades en él y metiéndolo en la pantalla, continué trabajando para reconocer el estado del juego. Además de las unidades, necesitaba reconocer el nivel de maná actual y las cartas disponibles para el jugador.
El nivel de maná en el juego se muestra como una barra de progreso y números. Sin pensarlo dos veces, comencé a cortar el número, invertir y reconocer usando
pytesseract .
Para determinar las tarjetas disponibles y su posición, utilicé el
detector de puntos clave KAZE de OpenCV . Hasta ahora no quería volver a aprender la red neuronal nuevamente, y elegí un método que fuera más rápido y fácil, aunque al final resultó que tenía la precisión mínima suficiente en el caso en que necesita buscar muchos objetos.
Al iniciar el bot, conté los puntos clave para todas las imágenes de las cartas (hay varias docenas en total), y durante el juego busqué coincidencias de todas las cartas con el área de cartas del jugador para reducir el número de errores y aumentar la velocidad. Se ordenaron por precisión y por la coordenada
x para obtener el orden de los mapas: información sobre cómo se encuentran en la pantalla.
Después de jugar un poco con los parámetros, en la práctica obtuve muchos errores, aunque algunas imágenes complejas de tarjetas, que a veces se confundían con el algoritmo, se reconocieron con gran precisión. Tuve que agregar un búfer de tres elementos: si tres reconocimientos seguidos obtenemos los mismos valores, entonces condicionalmente creemos que podemos confiar en ellos.

Después de recibir toda la información necesaria (unidades y su posición aproximada, maná disponible y cartas), puedes tomar algunas decisiones.
Para empezar, decidí tomar algo simple: por ejemplo, si hay suficiente maná en una carta accesible, juégalo en el campo. Pero el bot aún no sabe cómo "jugar" las cartas: sabe qué cartas tenemos, dónde está el campo, debe hacer clic en la carta deseada y luego en la celda deseada en el campo.
Conociendo la resolución de la captura de pantalla, puede comprender las coordenadas del mapa y la celda de campo deseada. Ahora he vinculado a la resolución de pantalla exacta, pero si es necesario, puedo ignorar esto. La función de decisión devolverá una serie de toques que deben hacerse en un futuro próximo. En general, nuestro bot será un bucle infinito (simplificado):
: = : ( ) : = () = () = () += (, , , )
Hasta ahora, el bot solo puede poner unidades en un punto, pero ya tiene suficiente información para construir una estrategia más compleja.
Primeros problemas
En realidad, me encontré con un problema inesperado y muy desagradable. Crear una captura de pantalla a través de ADB toma alrededor de 100 ms, lo que introduce un retraso significativo: esperaba tal retraso máximo, teniendo en cuenta todos los cálculos y la elección de la acción, pero no en un solo paso para crear una captura de pantalla. No se pudo encontrar una solución simple y rápida. En teoría, usando el emulador de Android, puede tomar capturas de pantalla directamente desde la ventana de la aplicación, o puede hacer una utilidad para transmitir imágenes desde un teléfono con compresión a través de UDP y conectar el bot, pero tampoco encontré soluciones rápidas aquí.
Entonces
Habiendo evaluado sobriamente el estado de mi proyecto, decidí detenerme en este modelo por ahora. Pasé varias semanas de mi tiempo libre haciendo esto, y el reconocimiento de unidades es solo una parte del juego.
Decidí desarrollar las partes del bot gradualmente, para hacer la lógica básica de percepción, luego la lógica simple del juego y la interacción con el juego, y luego será posible mejorar las partes individuales del bot. Cuando el nivel del modelo de reconocimiento de unidades se vuelve suficiente, agregar información sobre HP y el nivel de unidades puede llevar el desarrollo del bot del juego a una etapa completamente nueva. Quizás este sea el próximo objetivo, pero en este momento definitivamente no vale la pena centrarse en esta tarea.
Repositorio de proyectos GithubPasé mucho tiempo en el proyecto y, francamente, estoy cansado de ello, pero no me arrepiento un poco: obtuve una nueva experiencia en ML / CV.
Tal vez volveré con él más tarde; me alegrará si alguien se une a mí. Si está interesado, únase al grupo en
Telegram y también venga a mi
curso de Scala .