Este artículo es una transcripción del video del informe de Alexei Vakhov de Uchi.ru "Nubes en las nubes"
Uchi.ru es una plataforma en línea para la educación escolar, más de 2 millones de estudiantes, las clases interactivas regularmente deciden con nosotros. Todos nuestros proyectos están alojados completamente en nubes públicas, el 100% de las aplicaciones funcionan en contenedores, comenzando desde el más pequeño, para uso interno, y terminando con grandes producciones a 1k + solicitudes por segundo. Dio la casualidad de que tenemos 15 clústeres de acopladores aislados (¡no Kubernetes, sic!) En cinco proveedores de la nube. Mil quinientas aplicaciones de usuario, cuyo número crece constantemente.
Hablaré sobre cosas muy específicas: cómo cambiamos a contenedores, cómo gestionamos la infraestructura, los problemas que encontramos, qué funcionó y qué no.
Durante el informe, discutiremos:
- Motivación para la selección de tecnología y características comerciales
- Herramientas: Ansible, Terraform, Docker, Github Flow, Consul, Nomad, Prometheus, Shaman: una interfaz web para Nomad.
- Uso de la federación de clústeres para gestionar la infraestructura distribuida
- Implementaciones de NoOps, entornos de prueba, circuitos de aplicación (los desarrolladores realizan sus propios cambios prácticamente por su cuenta)
- Historias entretenidas de la práctica
A quién le importa, por favor, debajo del gato.
Me llamo Alexey Vakhov. Trabajo como director técnico en Uchi.ru. Nos alojamos en nubes públicas. Utilizamos activamente Terraform, Ansible. Desde entonces, nos hemos cambiado por completo a Docker. Muy satisfecho Qué contento, qué contentos estamos, lo diré.

La empresa Uchi.ru se dedica a la producción de productos para la educación escolar. Tenemos una plataforma principal en la que los niños resuelven problemas interactivos en diversas materias en Rusia, Brasil y Estados Unidos. Realizamos olimpiadas, concursos, clubes, campamentos en línea. Cada año esta actividad está creciendo.

Desde el punto de vista de la ingeniería, la pila web clásica (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). La característica principal es que muchas aplicaciones. Las aplicaciones están alojadas en todo el mundo. Todos los días hay lanzamientos en producción.
La segunda característica es que nuestros esquemas cambian muy a menudo. Piden plantear una nueva aplicación, detener la anterior, agregar cron para trabajos en segundo plano. Cada 2 semanas hay una nueva Olimpiada, esta es una nueva aplicación. Todo es necesario para acompañar, monitorear, respaldar. Por lo tanto, el ambiente es superdinámico. El dinamismo es nuestra principal dificultad.
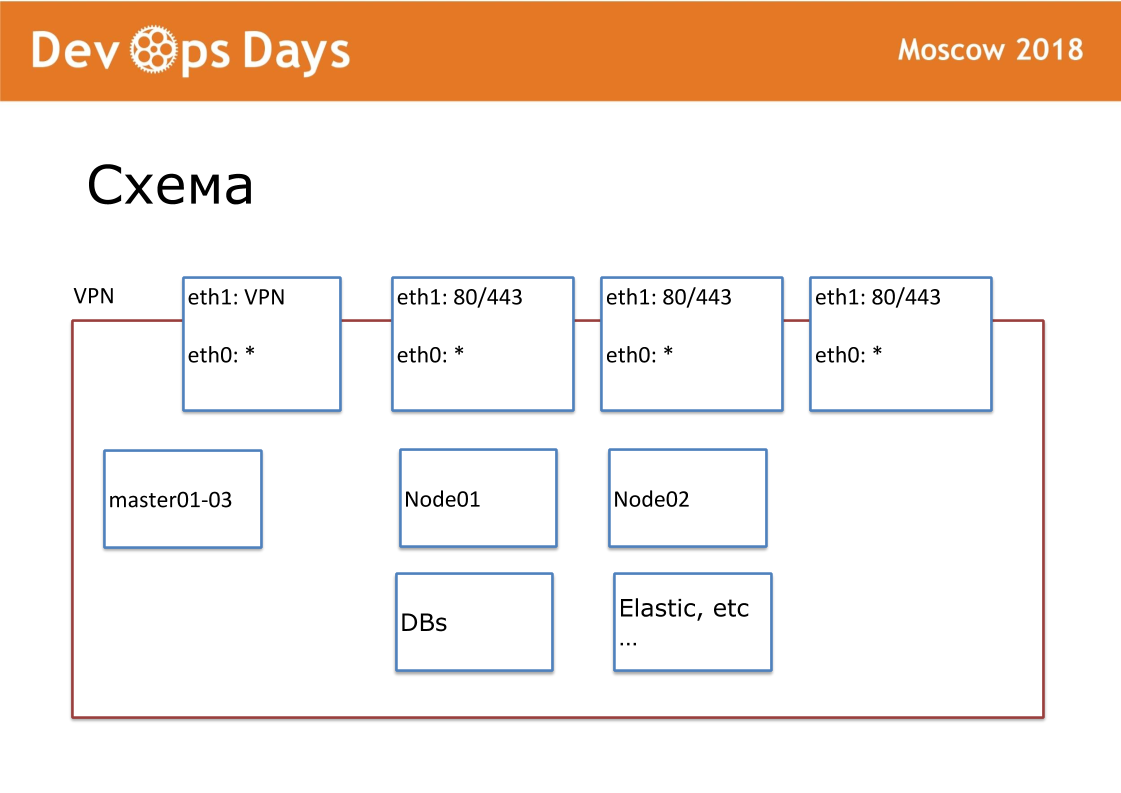
Nuestra unidad de trabajo es el sitio. En términos de proveedores de la nube, este es el Proyecto. Nuestro sitio es una entidad completamente aislada con una API y una subred privada. Cuando ingresamos al país, buscamos proveedores locales en la nube. No en todas partes hay Google y Amazon. A veces sucede que no hay API para el proveedor de la nube. Exteriormente publicamos VPN y HTTP, HTTPS para equilibradores. Todos los demás servicios se comunican dentro de la nube.

Para cada sitio hemos creado nuestro propio repositorio Ansible. El repositorio tiene hosts.yml, libro de jugadas, roles y 3 carpetas secretas, de las que hablaré más adelante. Esto es terraformación, provisión, enrutamiento. Somos fanáticos de la estandarización. Nuestro repositorio siempre debe llamarse el "nombre ansible del sitio". Estandarizamos cada nombre de archivo, estructura interna. Esto es muy importante para una mayor automatización.

Configuramos Terraform hace un año y medio, por lo que lo usamos. Terraform sin módulos, sin estructura de archivo (se utiliza estructura plana). Estructura del archivo Terraform: 1 servidor - 1 archivo, configuraciones de red y otras configuraciones. Usando terraform, describimos servidores, unidades, dominios, s3-buckets, redes, etc. Terraform en el sitio está preparando completamente el hierro.

Terraform crea el servidor, luego el conjunto rueda estos servidores. Debido al hecho de que usamos la misma versión del sistema operativo en todas partes, escribimos todos los roles desde cero. Los roles relevantes generalmente se publican en Internet para todos los sistemas operativos que no funcionan en ningún lugar. Todos tomamos roles de Ansible y dejamos solo lo que necesitábamos. Roles Ansibles Estandarizados. Tenemos 6 libros de jugadas básicos. Cuando se inicia, Ansible instala una lista estándar de software: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes que no usamos.

Usamos Consul + Nomad. Estos son programas muy simples. Ejecute 2 programas escritos en Golang en cada servidor. El cónsul es responsable del descubrimiento del servicio, la verificación del estado y el valor clave para almacenar la configuración. Nomad es responsable de la programación, de la implementación. Nomad lanza contenedores, proporciona despliegues, incluida la actualización continua en la comprobación de estado, le permite ejecutar contenedores sidecar. El clúster es fácil de expandir o viceversa para reducir. Nomad admite cron distribuido.
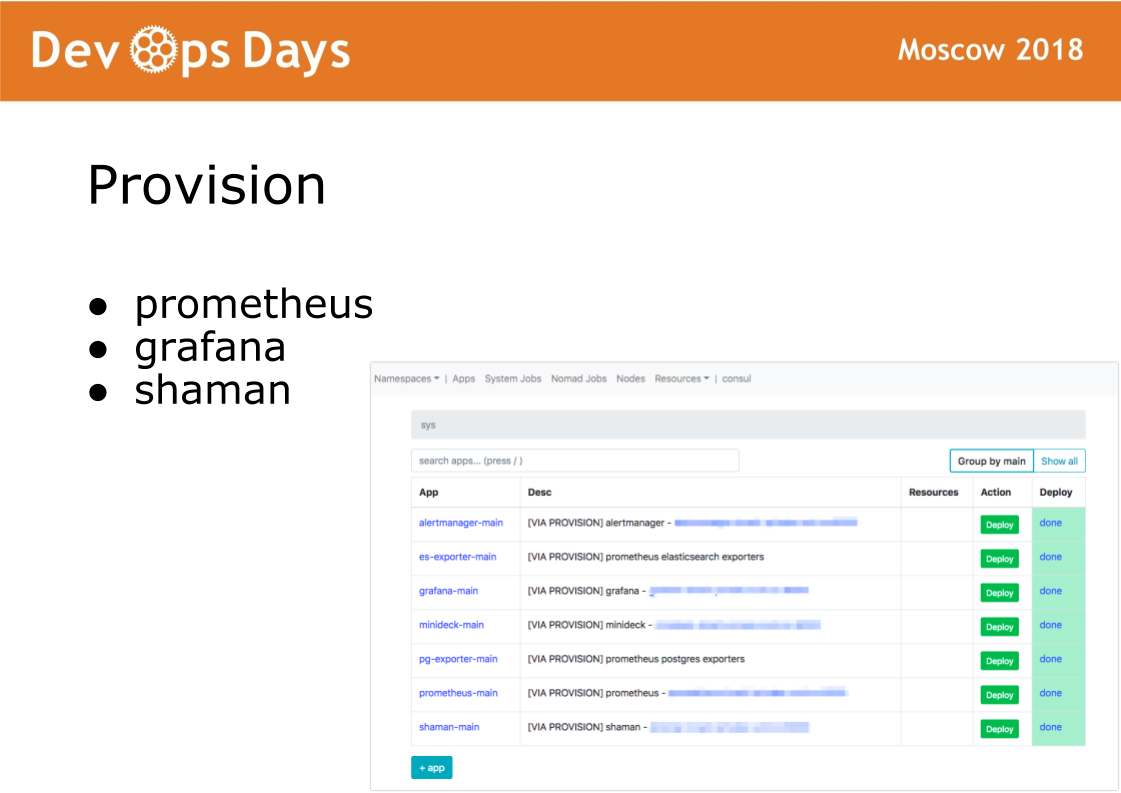
Después de ingresar al sitio, Ansible ejecuta el libro de jugadas ubicado en el directorio de suministro. El libro de jugadas en este directorio es responsable de instalar el software en el cluster docker que usan los administradores. Instale el software prometheus, grafana y secret shaman.
Shaman es un tablero web para nómadas. Nomad es de bajo nivel y realmente no quiero dejar entrar a los desarrolladores. En chamán vemos una lista de aplicaciones, les damos a los desarrolladores un botón de implementación para las aplicaciones. Los desarrolladores pueden cambiar las configuraciones: agregar contenedores, variables de entorno, iniciar servicios.
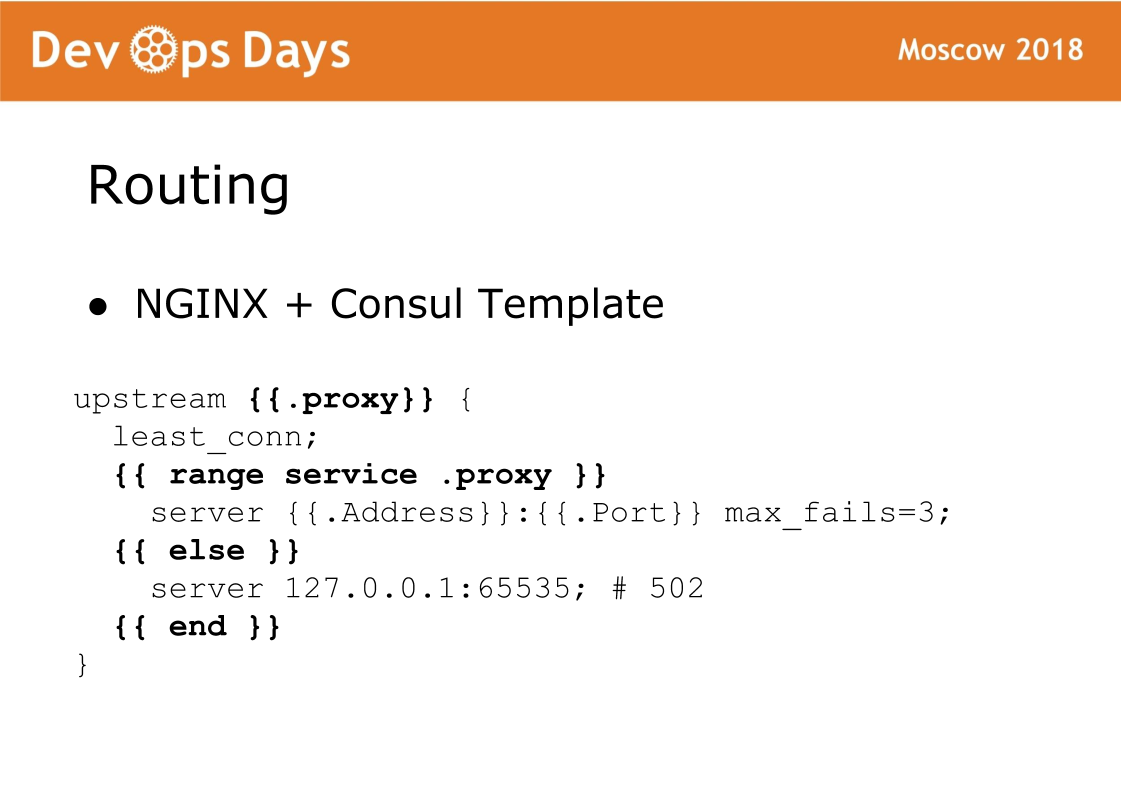
Y finalmente, el componente final del sitio es el enrutamiento. El enrutamiento se almacena en el almacenamiento K / V del cónsul, es decir, hay un enlace entre el flujo ascendente, el servicio, la URL, etc. En cada equilibrador, hay una plantilla de Cónsul que genera una configuración nginx y hace que se vuelva a cargar. Una cosa muy confiable, nunca tuvimos un problema con eso. La característica de este esquema es que el tráfico acepta nginx estándar y siempre puede ver qué configuración se generó y funciona como con nginx estándar.

Por lo tanto, cada sitio consta de 5 capas. Con terraform, personalizamos el hardware. Ansible llevamos a cabo la configuración básica de los servidores, poner el docker-cluster. La provisión acumula el software del sistema. El enrutamiento dirige el tráfico dentro del sitio. Aplicaciones contiene aplicaciones de usuario y aplicaciones de administrador.
Depuramos estas capas durante mucho tiempo para que fueran lo más idénticas posible. Provisión, coincidencia de enrutamiento 100% entre sitios. Por lo tanto, para los desarrolladores, cada sitio es absolutamente igual.
Si los profesionales de TI cambian de un proyecto a otro, caen en un entorno completamente típico. En realidad, no pudimos hacer que la configuración de firewall y VPN sea idéntica para diferentes proveedores de la nube. Con una red, todos los proveedores de la nube funcionan de manera diferente. Terraform es propio en todas partes, porque contiene diseños específicos para cada proveedor de la nube.
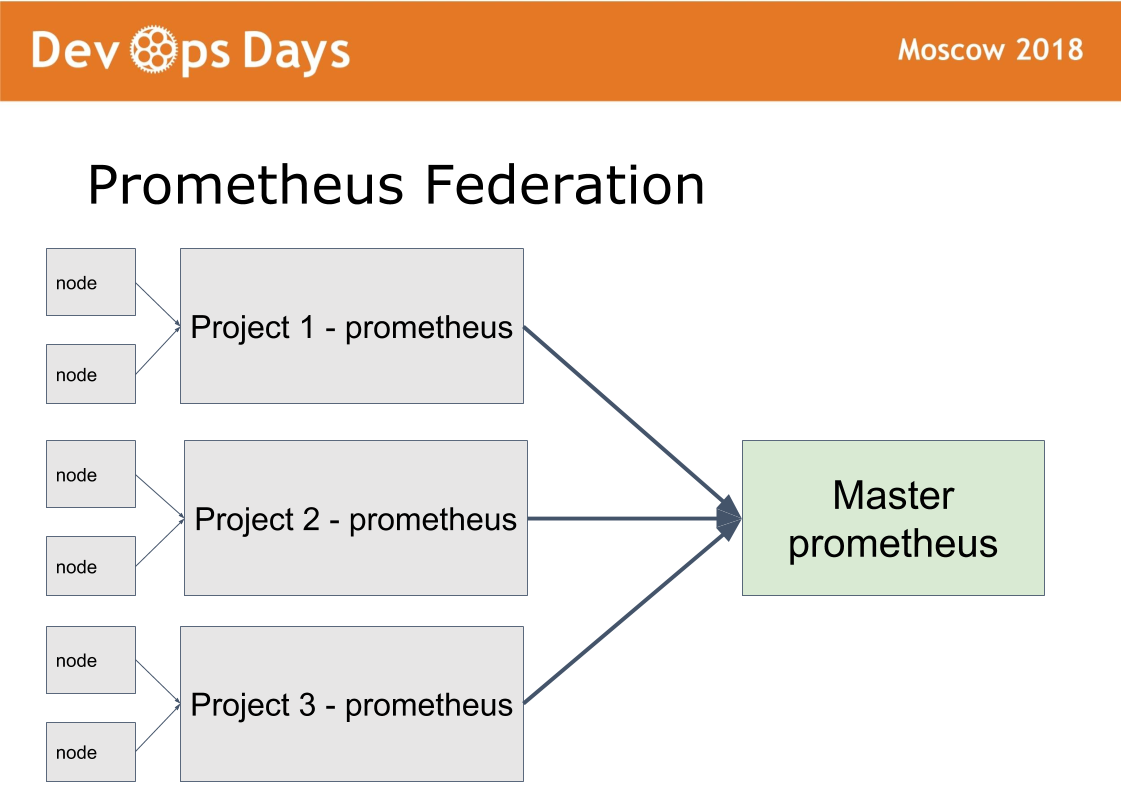
Tenemos 14 sitios de producción. Surge la pregunta: ¿cómo gestionarlos? Creamos el decimoquinto sitio maestro, en el que solo permitimos administradores. Ella trabaja en un esquema de federación.
La idea fue tomada de prometeo. Hay un modo en prometheus cuando instalamos prometheus en cada sitio. Publicamos Prometheus a través de la autorización de autenticación básica HTTPS. Prometheus master recoge solo las métricas necesarias de prometheus remoto. Esto permite comparar métricas de aplicaciones en diferentes nubes, encontrar las aplicaciones más descargadas o descargadas. La notificación centralizada (alerta) pasa por el maestro prometheus para administradores. Los desarrolladores reciben alertas de prometheus local.

El chamán está configurado de la misma manera. A través del sitio principal, los administradores pueden implementar y configurar en cualquier sitio a través de una única interfaz. Resolvemos una clase suficientemente grande de problemas sin salir de este sitio maestro.

Te diré cómo nos cambiamos a Docker. Este proceso es muy lento. Cruzamos unos 10 meses. En el verano de 2017, tuvimos 0 contenedores de producción. En abril de 2018, acoplamos y lanzamos nuestra última aplicación a producción.

Somos del mundo del rubí sobre rieles. Solía haber 99% de las aplicaciones de Ruby on Rails. Los rieles se extienden por Capistrano. Técnicamente, Capistrano funciona de la siguiente manera: el desarrollador inicia la implementación de la tapa, capistrano va a todos los servidores de aplicaciones a través de ssh, recoge la última versión del código, recopila activos y migra la base de datos. Capistrano crea un enlace simbólico a la nueva versión del código y envía una señal USR2 a la aplicación web. A esta señal, el servidor web recoge el nuevo código.
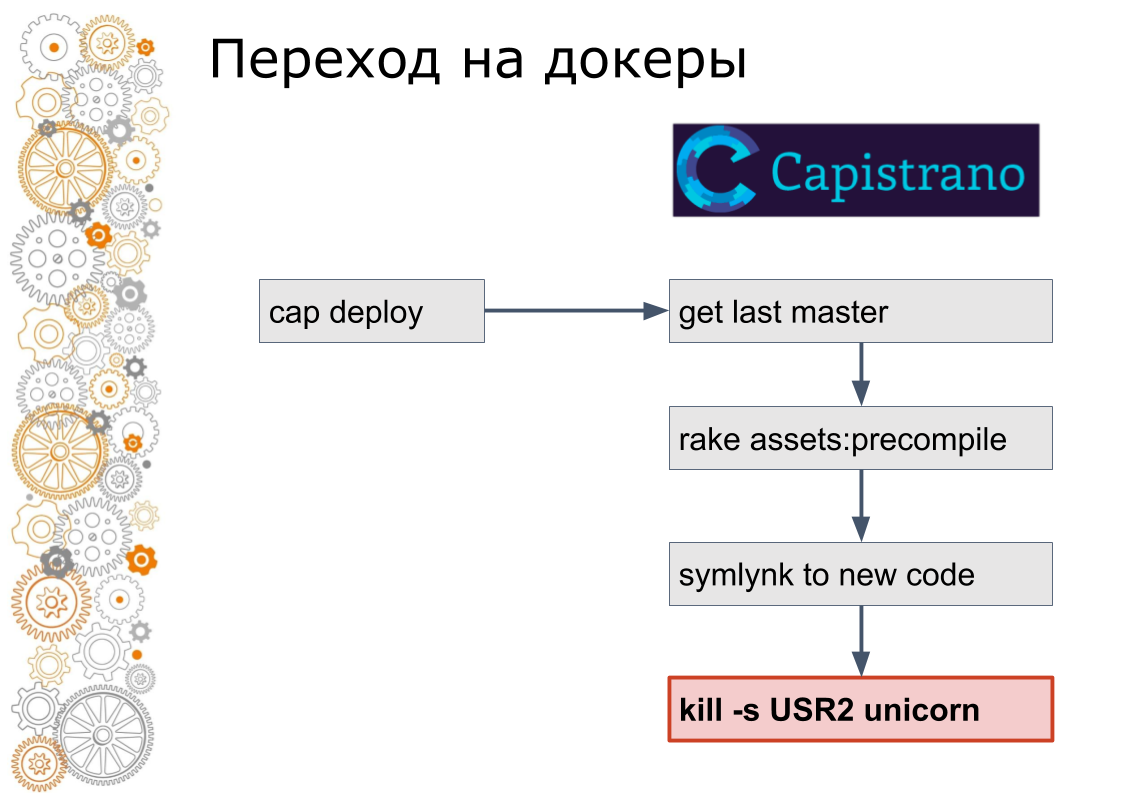
El último paso en Docker no se hace así. En la ventana acoplable, debe detener el contenedor anterior, levantar el contenedor nuevo. Esto plantea la pregunta: ¿cómo cambiar el tráfico? En el mundo de la nube, el descubrimiento de servicios es responsable de esto.

Por lo tanto, agregamos cónsul a cada sitio. Cónsul fue agregado porque usaron Terraform. Empaquetamos todas las configuraciones de nginx en una plantilla de cónsul. Formalmente, lo mismo, pero ya estábamos listos para administrar dinámicamente el tráfico dentro de los sitios.

Luego, escribimos un script de ruby que recogía una imagen en uno de los servidores, la introducía en el registro, luego se enviaba por ssh a cada servidor, recogía nuevos y detenía los contenedores antiguos, registrándolos en el cónsul. Los desarrolladores también continuaron ejecutando la implementación de cap, pero los servicios ya se estaban ejecutando en Docker.
Recuerdo que había dos versiones del guión, la segunda resultó ser bastante avanzada, hubo una actualización continua, cuando se detuvo un pequeño número de contenedores, se levantaron otros nuevos, el cónsul Helfcheki esperó y siguió adelante.

Luego se dieron cuenta de que este es un método sin salida. El guión aumentó a 600 líneas. El siguiente paso en la eliminación manual reemplazamos a Nomad. Ocultando los detalles del trabajo del desarrollador. Es decir, todavía llamaron despliegue de tope, pero por dentro ya era una tecnología completamente diferente.
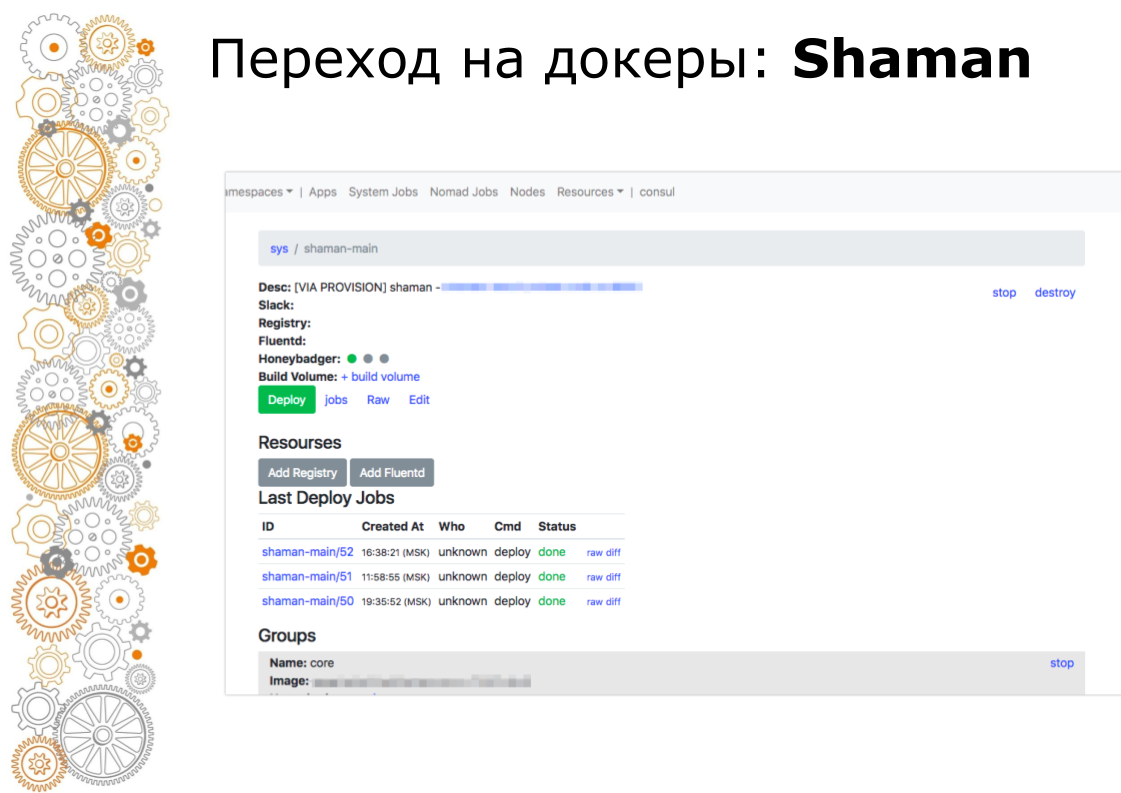
Y al final, trasladamos la implementación a la interfaz de usuario y eliminamos el acceso al servidor, dejando el botón de implementación verde y la interfaz de control.
En principio, tal transición resultó ser, por supuesto, larga, pero evitamos el problema que encontré varias veces.
Hay algún tipo de pila heredada, sistema o algo así. Khachennaya ya solo en flaps. Comienza el desarrollo de una nueva versión. Después de un par de meses o un par de años, dependiendo del tamaño de la empresa, en la nueva versión se implementa menos de la mitad de la funcionalidad necesaria, y la versión anterior aún escapó. Y ese nuevo también se convirtió en un gran legado. Y es hora de comenzar una nueva tercera versión desde cero. En general, este es un proceso interminable.
Por lo tanto, siempre movemos toda la pila como un todo. En pequeños pasos, torcidos, con muletas, pero enteramente. No podemos actualizar, por ejemplo, el motor acoplable en un sitio. Es necesario actualizar en todas partes, si hay un deseo.

Roll-outs. Todas las instrucciones de la ventana acoplable despliegan 10 contenedores nginx, o 10 contenedores redis, en la ventana acoplable. Este es un mal ejemplo, porque las imágenes ya están ensambladas, las imágenes son claras. Empaquetamos nuestras aplicaciones de rieles en Docker. El tamaño de las imágenes de la ventana acoplable era de 2-3 gigabytes. Saldrán no tan rápido.
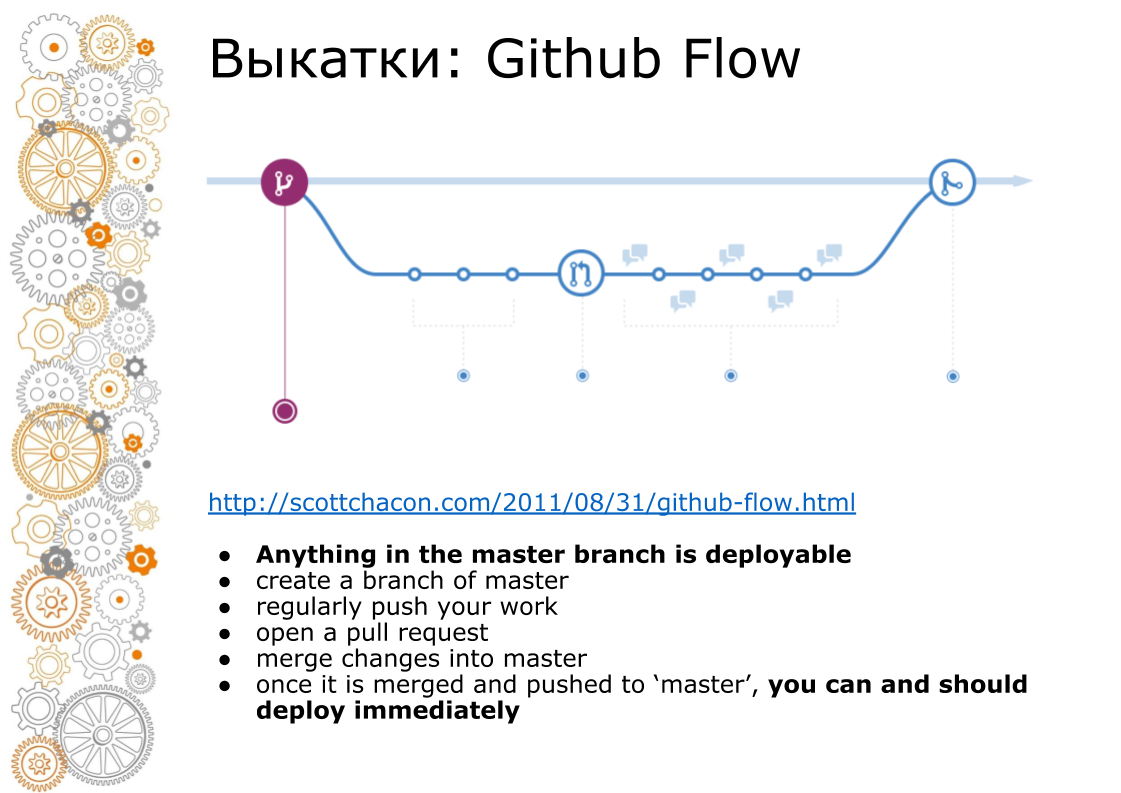
El segundo problema vino de la web hipster. Una web hipster siempre es Github Flow. En 2011, hubo una publicación de creación de época que Github Flow dirige, por lo que toda la web rueda. ¿Cómo se ve? La rama maestra es siempre producción. Al agregar una nueva funcionalidad, hacemos una rama. Cuando fusionamos, revisamos el código, ejecutamos pruebas, aumentamos el entorno de preparación. Negocios buscando entorno de puesta en escena. En el momento X, si todo tiene éxito, fusionamos la sucursal en master y la lanzamos a producción.
En capistrano, esto funcionó bien, porque fue creado para esto. Docker siempre nos vende una tubería. Montado el contenedor. El contenedor puede ser transferido al desarrollador, probador, transferido a producción. Pero en el momento de la fusión en master, el código ya es diferente. Todas las imágenes de la ventana acoplable que se recopilaron de la rama de características, no se recopilaron del maestro.

Como lo hicimos Recopilamos la imagen, la colocamos en el registro local de acopladores. Y después de eso, hacemos el resto de las operaciones: migración, implementación en producción.

Para ensamblar rápidamente esta imagen, utilizamos Docker-in-Docker. En Internet, todos escriben que esto es un antipatrón, se bloquea. No teníamos nada de eso. Cuántos ya trabajan con él nunca tuvo un problema. Reenviamos el directorio / var / lib / docker al servidor principal utilizando el volumen Persistente. Todas las imágenes intermedias están en el servidor primario. Ensamblar una nueva imagen se ajusta en unos minutos.

Para cada aplicación, creamos un registro local de acopladores internos y nuestro volumen de compilación. Porque Docker guarda todas las capas en el disco y es difícil de limpiar. Ahora sabemos la utilización del disco de cada registro local de acopladores. Sabemos cuánto disco requiere. Puede recibir alertas a través de Grafana centralizado y limpio. Mientras nos limpiamos las manos. Pero lo automatizaremos.

Otro punto Imagen de Docker recopilada. Ahora esta imagen necesita descomponerse en servidores. Al copiar una imagen de acoplador grande, la red no hace frente. En la nube tenemos 1 Gbit / s. Hay un cierre global en la nube. Ahora estamos implementando una imagen acoplable en 4 servidores de producción pesada. En el gráfico puede ver que el disco funcionó en 1 paquete de servidores. Luego se despliega el segundo paquete de servidores. A continuación puede ver la utilización del canal. Aproximadamente 1 Gbit / s casi tiramos. Ya no hay mucha aceleración allí.

Mi producción favorita es Sudáfrica. Hay hierro muy caro y lento. Cuatro veces más caro que en Rusia. Hay muy mal internet. Internet de nivel de módem, pero no con errores. Allí implementamos aplicaciones en 40 minutos, teniendo en cuenta el ajuste de cachés, parámetros de tiempo de espera.

El último problema que me preocupó antes de que Docker contactara fue la carga. De hecho, la carga es la misma que sin un acoplador con hierro idéntico. El único matiz que encontramos en un solo punto. Si recolecta registros del motor Docker a través del controlador fluido incorporado, entonces a una carga de aproximadamente 1000 rps, el búfer fluido interno comienza a ensuciarse y las solicitudes comienzan a disminuir. Sacamos el registro en contenedores de sidecar. En nómada, esto se llama log-shipper. Un pequeño contenedor cuelga al lado de un gran contenedor de aplicaciones. La única tarea es recogerlo y enviarlo a un repositorio centralizado.

Cuáles fueron los problemas / soluciones / desafíos. Traté de analizar cuál era la tarea. Las características de nuestros problemas son:
- muchas aplicaciones independientes
- cambios continuos en la infraestructura
- Flujo de Github y grandes imágenes acoplables

Nuestras soluciones
- Federación de agrupaciones de acopladores. Desde el punto de vista del manejo es difícil. Pero Docker es bueno para implementar la funcionalidad empresarial en la producción. Trabajamos con datos personales y tenemos certificación en todos los países. En un sitio aislado, dicha certificación es fácil de aprobar. Durante la certificación surgen todas las preguntas: dónde está alojado, cómo tiene un proveedor en la nube, dónde almacena datos personales, dónde realiza copias de seguridad y quién tiene acceso a los datos. Cuando todo está aislado, es mucho más fácil describir el círculo de sospechosos y monitorear todo esto es mucho más fácil.
- Orquestación Está claro que kubernetes. El esta en todas partes. Pero quiero decir que Consul + Nomad es una solución de producción completa.
- Montaje de imágenes. Puede crear imágenes rápidamente en Docker-in-Docker.
- Cuando se usa Docker, también es posible una carga de 1000 rps.
Vector de dirección de desarrollo
Ahora uno de los grandes problemas es la desincronización de las versiones de software en los sitios. Anteriormente, configuramos el servidor a mano. Luego nos convertimos en ingenieros devops. Ahora configure el servidor usando ansible. Ahora tenemos unificación total, estandarización. Introducimos el pensamiento ordinario en la cabeza. No podemos arreglar PostgreSQL con nuestras manos en el servidor. Si necesita algún tipo de ajuste en solo 1 servidor, entonces pensamos cómo difundir esta configuración en todas partes. Si no estandariza, habrá un zoológico de configuraciones.
Estoy encantado y muy contento de que salgamos de la caja de forma gratuita una infraestructura de trabajo realmente muy agradable.

Puedes agregarme en facebook. Si hacemos algo bueno, escribiré sobre eso.
Preguntas:
¿Cuál es la ventaja de la plantilla de cónsul sobre la plantilla de Ansible, por ejemplo, para configurar reglas de firewall y más?
Respuesta: Ahora tenemos tráfico de balanceadores externos que van directamente a los contenedores. No hay nadie en el medio. Allí se forma una configuración que reenvía las direcciones IP y los puertos del clúster. Además, tenemos todas las configuraciones de balance en K / V en Consul. Tenemos la idea de proporcionar configuraciones de enrutamiento a los desarrolladores a través de una interfaz segura para que no rompan nada.
Pregunta: Respecto a la homogeneidad de todos los sitios. ¿Realmente no hay solicitudes de empresas o desarrolladores que necesiten implementar algo no estándar en este sitio? Por ejemplo, tarantool con cassandra.
Respuesta: Sucede, pero es muy raro. Esto dibujamos un artefacto interno separado. Existe tal problema, pero es raro.
Pregunta: La solución al problema de entrega es usar un registro privado de acopladores en cada sitio y desde allí ya es rápido obtener imágenes de acopladores.
Respuesta: De todos modos, la implementación se ejecutará en la red, ya que estamos implementando la imagen del acoplador en 15 servidores allí simultáneamente. Descansamos contra la red. Dentro de la red, 1 Gbit / s.
Pregunta: ¿Hay tantos contenedores acoplables basados aproximadamente en la misma pila tecnológica?
Respuesta: Ruby, Python, NodeJS.
Pregunta: ¿Con qué frecuencia prueba o verifica las imágenes de su ventana acoplable en busca de actualizaciones? ¿Cómo se resuelven los problemas de actualización, por ejemplo, cuando glibc, openssl debe corregirse en todos los acopladores?
Respuesta: Si encuentra tal error, vulnerabilidad, entonces nos sentamos por una semana y lo reparamos. Si necesita implementar, entonces podemos implementar toda la nube (todas las aplicaciones) desde cero a través de la federación. Podemos hacer clic en todos los botones verdes para el despliegue de aplicaciones y salir a tomar té.
Pregunta: ¿Vas a liberar a tu chamán en código abierto?
Respuesta: Aquí Andrei (señala a la persona de la audiencia) nos promete que tendremos un chamán en el otoño. Pero allí debe agregar soporte para kubernetes. OpenSource siempre debería ser mejor.