
Uno de los problemas acuciantes en todo momento es el problema de la preparación de informes. Dado que Julia es un lenguaje cuyos usuarios están directamente conectados con las tareas de análisis de datos, preparación de artículos y hermosas presentaciones con los resultados de cálculos e informes, este tema simplemente no puede ser ignorado.
Inicialmente, este artículo planeó un conjunto de recetas para generar informes, pero al lado de los informes está el tema de la documentación, con el cual los generadores de informes tienen muchas intersecciones. Por lo tanto, esto incluye herramientas para el criterio de la posibilidad de incrustar el código ejecutable de Julia en una plantilla con algún marcado. Finalmente, observamos que la revisión incluyó generadores de informes, ambos implementados en la propia Julia, y herramientas escritas en otros lenguajes de programación. Bueno, por supuesto, algunos puntos clave del lenguaje Julia en sí no se dejaron sin atención, sin lo cual podría no estar claro en qué casos y qué medios deberían usarse.
Cuaderno Jupyter
Esta herramienta, quizás, debería atribuirse a la más popular entre los involucrados en el análisis de datos. Debido a la capacidad de conectar varios núcleos informáticos, es popular entre los investigadores y matemáticos que están acostumbrados a sus lenguajes de programación específicos, uno de los cuales es Julia. Los módulos correspondientes para el lenguaje Julia están completamente implementados para el Jupyter Notebook. Y es por eso que aquí se menciona el Cuaderno.
El proceso de instalación de Jupyter Notebook no es complicado. Para el pedido, consulte https://github.com/JuliaLang/IJulia.jl Si Jupyter Notebook ya está instalado, solo necesita instalar el paquete Ijulia y registrar el núcleo informático correspondiente.
Dado que el producto Jupyter Notebook es lo suficientemente conocido como para no escribirlo en detalle, mencionaremos solo un par de puntos. El Bloc de notas (utilizaremos la terminología del bloc de notas) en un Jupyter Notebook consta de bloques, cada uno de los cuales puede contener código o marcado en sus diversas formas (por ejemplo, Markdown). El resultado del procesamiento es la visualización del marcado (texto, fórmulas, etc.) o el resultado de la última operación. Si se coloca un punto y coma al final de la línea con el código, el resultado no se mostrará.
Ejemplos. El cuaderno antes de la ejecución se muestra en la siguiente figura:

El resultado de su implementación se muestra en la siguiente figura.
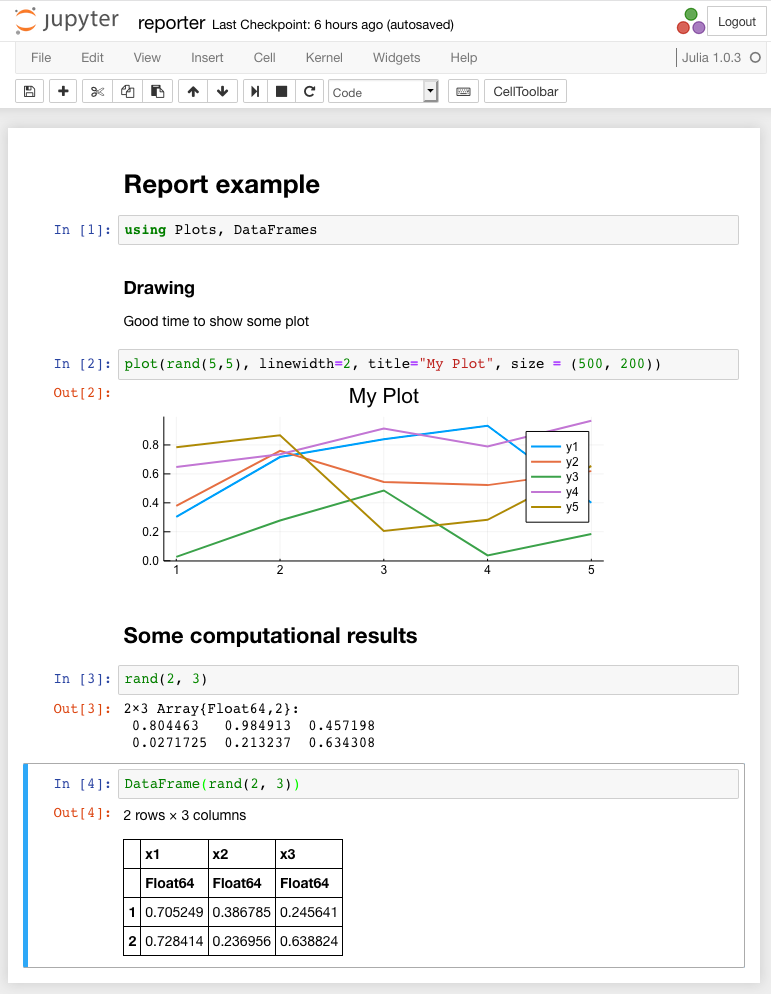
El Bloc de notas contiene gráficos y algo de texto. Tenga en cuenta que para generar la matriz, es posible usar el tipo DataFrame , para el que el resultado se muestra en forma de una tabla html con bordes explícitos y un desplazador, si es necesario.
El cuaderno Jupyter puede exportar el cuaderno actual al archivo html. Si hay herramientas de conversión instaladas, puede convertir a pdf.
Para crear informes de acuerdo con algunas reglamentaciones, puede usar el módulo nbconvert y el siguiente comando, que se llama en segundo plano de acuerdo con la programación:
jupyter nbconvert --to html --execute julia_filename.ipynb
Al realizar cálculos largos, es aconsejable agregar una opción que indique el tiempo de espera - --ExecutePreprocessor.timeout=180
Un informe html generado a partir de este archivo aparecerá en el directorio actual. La opción --execute aquí significa forzar el inicio del recuento.
Para obtener un conjunto completo de nbconvert módulo nbconvert consulte
https://nbconvert.readthedocs.io/en/latest/usage.html
El resultado de la conversión a html es casi completamente consistente con la figura anterior, excepto que no tiene una barra de menú o botones.
Jupytext
Una utilidad bastante interesante que le permite convertir notas ipynb creadas previamente en texto Markdown o código Julia.
Podemos transformar el ejemplo considerado anteriormente usando el comando
jupytext --to julia julia_filename.ipynb
Como resultado, obtenemos el archivo julia_filename.jl con el código de Julia y un marcado especial en forma de comentarios.
# --- # jupyter: # jupytext: # text_representation: # extension: .jl # format_name: light # format_version: '1.3' # jupytext_version: 0.8.6 # kernelspec: # display_name: Julia 1.0.3 # language: julia # name: julia-1.0 # --- # # Report example using Plots, DataFrames # ### Drawing # Good time to show some plot plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
Los separadores de bloques de nota son solo alimentaciones de doble línea.
Podemos hacer la transformación inversa usando el comando:
jupytext --to notebook julia_filename.jl
Como resultado, se generará un archivo ipynb, que, a su vez, puede procesarse y convertirse a pdf o html.
Ver detalles https://github.com/mwouts/jupytext
El inconveniente general de jupytext y jupyter notebook es que la "belleza" del informe está limitada por las capacidades de estas herramientas.
HTML autogenerado
Si por alguna razón creemos que el Jupyter Notebook es un producto demasiado pesado, que requiere la instalación de numerosos paquetes de terceros que no son necesarios para que Julia funcione, o que no son lo suficientemente flexibles como para crear el formulario de informe que necesitamos, entonces una forma alternativa es generar una página html manualmente. Sin embargo, aquí tendrá que sumergirse un poco en las características de la imagen.
Para Julia, una forma típica de generar algo en la secuencia de salida es usar la función Base.write , y para decorar, Base.show(io, mime, x) . Además, para los diversos métodos de salida de mime solicitados, puede haber varias opciones de visualización. Por ejemplo, un DataFrame cuando se muestra como texto se muestra en una tabla pseudo-gráfica.
julia> show(stdout, MIME"text/plain"(), DataFrame(rand(3, 2))) 3×2 DataFrame │ Row │ x1 │ x2 │ │ │ Float64 │ Float64 │ ├─────┼──────────┼───────────┤ │ 1 │ 0.321698 │ 0.939474 │ │ 2 │ 0.933878 │ 0.0745969 │ │ 3 │ 0.497315 │ 0.0167594 │
Si, mime se especifica como text/html , entonces el resultado es un marcado HTML.
julia> show(stdout, MIME"text/html"(), DataFrame(rand(3, 2))) <table class="data-frame"> <thead> <tr><th></th><th>x1</th><th>x2</th></tr> <tr><th></th><th>Float64</th><th>Float64</th></tr> </thead> <tbody><p>3 rows × 2 columns</p> <tr><th>1</th><td>0.640151</td><td>0.219299</td></tr> <tr><th>2</th><td>0.463402</td><td>0.764952</td></tr> <tr><th>3</th><td>0.806543</td><td>0.300902</td></tr> </tbody> </table>
Es decir, utilizando los métodos de la función show definidos para el tipo de datos correspondiente (tercer argumento) y el formato de salida correspondiente, es posible asegurar la formación de un archivo en cualquier formato de datos deseado.
La situación con las imágenes es más complicada. Si necesitamos crear un solo archivo html, entonces la imagen debe incrustarse en el código de la página.
Considere el ejemplo en el que esto se implementa. La salida al archivo será realizada por la función Base.write , para lo cual definimos los métodos apropiados. Entonces el código:
#!/usr/bin/env julia using Plots using Base64 using DataFrames # p = plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # , , @show typeof(p) # => typeof(p) = Plots.Plot{Plots.GRBackend} # , 3 # abstract type Png end abstract type Svg end abstract type Svg2 end # Base.write # # — , # Base64-. # HTML img src="data:image/png;base64,..." function Base.write(file::IO, ::Type{Png}, p::Plots.Plot) local io = IOBuffer() local iob64_encode = Base64EncodePipe(io); show(iob64_encode, MIME"image/png"(), p) close(iob64_encode); write(file, string("<img src=\"data:image/png;base64, ", String(take!(io)), "\" alt=\"fig.png\"/>\n")) end # Svg function Base.write(file::IO, ::Type{Svg}, p::Plots.Plot) local io = IOBuffer() show(io, MIME"image/svg+xml"(), p) write(file, replace(String(take!(io)), r"<\?xml.*\?>" => "" )) end # XML- , SVG Base.write(file::IO, ::Type{Svg2}, p::Plots.Plot) = show(file, MIME"image/svg+xml"(), p) # DataFrame Base.write(file::IO, df::DataFrame) = show(file, MIME"text/html"(), df) # out.html HTML open("out.html", "w") do file write(file, """ <!DOCTYPE html> <html> <head><title>Test report</title></head> <body> <h1>Test html</h1> """) write(file, Png, p) write(file, "<br/>") write(file, Svg, p) write(file, "<br/>") write(file, Svg2, p) write(file, DataFrame(rand(2, 3))) write(file, """ </body> </html> """) end
Para crear imágenes, el motor Plots.GRBackend se usa de manera predeterminada, que puede realizar la salida de imágenes ráster o vectoriales. Dependiendo de qué tipo se especifica en el argumento mime de la función show , se genera el resultado correspondiente. MIME"image/png"() forma una imagen en formato png . MIME"image/svg+xml"() genera una imagen svg. Sin embargo, en el segundo caso, debe prestar atención al hecho de que se forma un documento xml completamente independiente, que puede escribirse como un archivo separado. Al mismo tiempo, nuestro objetivo es incrustar una imagen en una página HTML, que en HTML5 se puede hacer simplemente insertando marcado SVG. Es por eso que el método Base.write(file::IO, ::Type{Svg}, p::Plots.Plot) corta el encabezado xml, que, de lo contrario, violaría la estructura del documento HTML. Aunque, la mayoría de los navegadores pueden mostrar correctamente la imagen incluso en este caso.
Con respecto al método para Base.write(file::IO, ::Type{Png}, p::Plots.Plot) , la característica de implementación aquí es que solo podemos insertar datos binarios en HTML en formato Base64. Hacemos esto usando el <img src="data:image/png;base64,"/> construct. Y para la transcodificación usamos Base64EncodePipe .
El método Base.write(file::IO, df::DataFrame) proporciona resultados en el formato de tabla html del objeto DataFrame .
La página resultante es la siguiente:
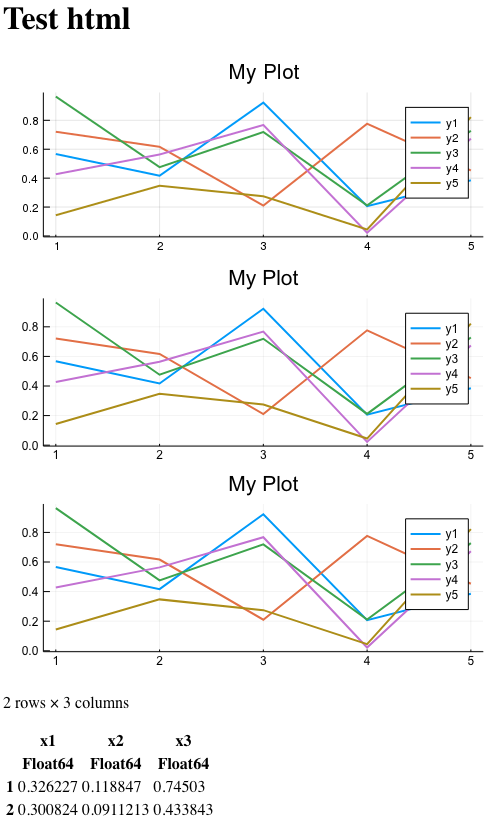
En la imagen, las tres imágenes se ven aproximadamente iguales, sin embargo, recuerde que una de ellas está insertada incorrectamente desde el punto de vista de HTML (encabezado xml adicional). Una es la trama, lo que significa que no se puede aumentar sin pérdida de detalles. Y solo uno de ellos se inserta como el fragmento svg correcto dentro del marcado HTML. Y se puede escalar fácilmente sin pérdida de detalles.
Naturalmente, la página resultó ser muy simple. Pero cualquier mejora visual es posible con CSS.
Este método de generación de informes es útil, por ejemplo, cuando el número de tablas mostradas está determinado por datos reales y no por una plantilla. Por ejemplo, necesita agrupar datos por algún campo. Y para que cada grupo forme bloques separados. Dado que al formar una página, el resultado está determinado por el número de llamadas a Base.write , es obvio que no hay ningún problema en envolver el bloque deseado en un bucle, haciendo que la salida dependa de los datos, etc.
Ejemplo de código:
using DataFrames # ptable = DataFrame( Symbol = ["H", "He", "C", "O", "Fe" ], Room = [:Gas, :Gas, :Solid, :Gas, :Solid] ) res = groupby(ptable, [:Room]) # open("out2.html", "w") do f for df in (groupby(ptable, [:Room])) write(f, "<h2>$(df[1, :Room])</h2>\n") show(f, MIME"text/html"(), DataFrame(df)) write(f, "\n") end end
El resultado de este script es un fragmento de la página HTML.

Tenga en cuenta que todo lo que no requiere conversión de decoración / formato se muestra directamente a través de la función Base.write . Al mismo tiempo, todo lo que requiere conversión se Base.show través de Base.show .
Weave.jl
Weave es un generador de informes científicos implementado por Julia. Utiliza las ideas de los generadores Pweave, Knitr, rmarkdown, Sweave. Su tarea principal es exportar el marcado de origen en cualquiera de los idiomas propuestos (Noweb, Markdown, formato de script) a formatos LaTex, Pandoc, Github markdown, MultiMarkdown, Asciidoc, reStructuredText. Y, incluso en IJulia Notebooks y viceversa. En la última parte, es similar a Jupytext.
Es decir, Weave es una herramienta que le permite escribir plantillas que contienen código Julia en varios lenguajes de marcado, y en la salida para tener marcado en otro idioma (pero con los resultados de la ejecución del código Julia). Y esta es una herramienta muy útil específicamente para investigadores. Por ejemplo, puede preparar un artículo sobre Latex, que tendrá inserciones en Julia con el cálculo automático del resultado y su sustitución. Weave generará un archivo para el artículo final.
Hay soporte para el editor Atom usando el complemento correspondiente https://atom.io/packages/language-weave . Esto le permite desarrollar y depurar scripts de Julia integrados en el marcado, y luego generar el archivo de destino.
El principio básico en Weave, como ya se mencionó, es analizar una plantilla que contiene marcado con texto (fórmulas, etc.) y pegar el código en Julia. El resultado de la ejecución del código se puede mostrar en el informe final. La salida de texto, código, la salida de resultados, la salida de gráficos: todo esto se puede configurar individualmente.
Para procesar las plantillas, debe ejecutar un script externo que recopilará todo en un solo documento y lo convertirá al formato de salida deseado. Es decir, plantillas por separado, manejadores por separado.
Un ejemplo de tal secuencia de comandos de procesamiento:
# : # Markdown weave("w_example.jmd", doctype="pandoc" out_path=:pwd) # HTML weave("w_example.jmd", out_path=:pwd, doctype = "md2html") # pdf weave("w_example.jmd", out_path=:pwd, doctype = "md2pdf")
jmd en los nombres de archivo es Julia Markdown.
Tome el mismo ejemplo que usamos en herramientas anteriores. Sin embargo, insertaremos un encabezado con información sobre el autor que Weave entiende.
--- title : Intro to Weave.jl with Plots author : Anonymous date : 06th Feb 2019 --- # Intro ## Plot ` ``{julia;} using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``julia rand(2, 3) ` `` ` ``julia DataFrame(rand(2, 3)) ` ``
Este fragmento, que se convierte a pdf, se parece a esto:

Las fuentes y el diseño son bien reconocidos por los usuarios de Latex.
Para cada pieza de código incrustado, puede determinar cómo se procesará este código y qué se mostrará al final.
Por ejemplo:
- echo = true: se mostrará el código
- eval = true: se mostrará el resultado de la ejecución del código
- etiqueta: agrega una etiqueta. Si se usa Latex, se usará como fig: label
- fig_width, fig_height - tamaños de imagen
- y así sucesivamente
Para conocer los formatos de noweb y script, así como más sobre esta herramienta, consulte http://weavejl.mpastell.com/stable/
Literate.jl
Los autores de este paquete, cuando se les preguntó por qué Literate, se refieren al paradigma de programación literaria de Donald Knutt. La tarea de esta herramienta es generar documentos basados en el código de Julia que contiene comentarios en formato de descuento. A diferencia de la herramienta de tejido anterior examinada, no puede hacer documentos con los resultados de la ejecución. Sin embargo, la herramienta es ligera y se centra principalmente en documentar código. Por ejemplo, ayuda a escribir hermosos ejemplos que se pueden colocar en cualquier plataforma de descuento. A menudo se usa en una cadena de otras herramientas de documentación, por ejemplo, junto con Documenter.jl .
Hay tres opciones posibles para el formato de salida: descuento, cuaderno y secuencia de comandos (código Julia puro). Ninguno de ellos ejecutará el código implementado.
Ejemplo de archivo fuente con comentarios de Markdown (después del primer carácter #):
#!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd()) # documenter=true # # Intro # ## Plot using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
El resultado de su trabajo será un documento de Markdown y directivas para el Documenter , si su generación no se ha desactivado explícitamente.
` ``@meta EditURL = "https://github.com/TRAVIS_REPO_SLUG/blob/master/" ` `` ` ``@example literate_example #!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd(), documenter=true) ` `` # Intro ## Plot ` ``@example literate_example using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``@example literate_example rand(2, 3) DataFrame(rand(2, 3)) ` `` *This page was generated using [Literate.jl](https://github.com/fredrikekre/Literate.jl).*
Las inserciones de código dentro de markdown aquí se colocan deliberadamente con un espacio entre el primer apóstrofo y el posterior, para no estropearse al publicar el artículo.
Ver más detalles https://fredrikekre.imtqy.com/Literate.jl/stable/
Documenter.jl
Generador de documentación. Su objetivo principal es formar documentación legible para paquetes escritos en Julia. Documentador convierte ejemplos html o pdf con marcado Markdown y código incrustado de Julia, así como archivos fuente de módulos, extrayendo cadenas de documentos de Julia (comentarios de Julia).
Un ejemplo de documentación típica:

En este artículo no nos detendremos en los principios de documentación, ya que, en el buen sentido, esto debería hacerse como parte de un artículo separado sobre el desarrollo de módulos. Sin embargo, veremos algunos aspectos del Documentador aquí.
En primer lugar, vale la pena prestar atención al hecho de que la pantalla está dividida en dos partes: el lado izquierdo contiene una tabla interactiva de contenido. El lado derecho es, de hecho, el texto de la documentación.
Una estructura de directorio típica con ejemplos y documentación es la siguiente:
docs/ src/ make.jl src/ Example.jl ...
El directorio docs/src es la documentación de rebajas. Y se encuentran ejemplos en algún lugar del directorio fuente compartido src .
El archivo de clave para Docuementer es docs/make.jl El contenido de este archivo para el propio Documentador:
using Documenter, DocumenterTools makedocs( modules = [Documenter, DocumenterTools], format = Documenter.HTML( # Use clean URLs, unless built as a "local" build prettyurls = !("local" in ARGS), canonical = "https://juliadocs.imtqy.com/Documenter.jl/stable/", ), clean = false, assets = ["assets/favicon.ico"], sitename = "Documenter.jl", authors = "Michael Hatherly, Morten Piibeleht, and contributors.", analytics = "UA-89508993-1", linkcheck = !("skiplinks" in ARGS), pages = [ "Home" => "index.md", "Manual" => Any[ "Guide" => "man/guide.md", "man/examples.md", "man/syntax.md", "man/doctests.md", "man/latex.md", hide("man/hosting.md", [ "man/hosting/walkthrough.md" ]), "man/other-formats.md", ], "Library" => Any[ "Public" => "lib/public.md", hide("Internals" => "lib/internals.md", Any[ "lib/internals/anchors.md", "lib/internals/builder.md", "lib/internals/cross-references.md", "lib/internals/docchecks.md", "lib/internals/docsystem.md", "lib/internals/doctests.md", "lib/internals/documenter.md", "lib/internals/documentertools.md", "lib/internals/documents.md", "lib/internals/dom.md", "lib/internals/expanders.md", "lib/internals/mdflatten.md", "lib/internals/selectors.md", "lib/internals/textdiff.md", "lib/internals/utilities.md", "lib/internals/writers.md", ]) ], "contributing.md", ], ) deploydocs( repo = "github.com/JuliaDocs/Documenter.jl.git", target = "build", )
Como puede ver, los métodos clave aquí son makedocs y deploydocs , que determinan la estructura de la documentación futura y el lugar para su colocación. makedocs proporciona la formación de marcado de marcado a partir de todos los archivos especificados, que incluye tanto la ejecución de código incrustado como la extracción de comentarios de docstrings.
Documenter admite una serie de directivas para insertar código. Su formato es `` @something
@docs , @autodocs : enlaces a la documentación de cadenas de documentos extraída de los archivos de Julia.@ref , @meta , @index , @contents : enlaces, indicaciones de páginas de índice, etc.@example , @repl , @eval : modos de ejecución del código incrustado de Julia.- ...
La presencia de las directivas @example, @repl, @eval , de hecho, determinó si incluir Documenter en este resumen o no. Además, el Literate.jl mencionado anteriormente puede generar automáticamente dicho marcado, como se demostró anteriormente. Es decir, no existen restricciones fundamentales sobre el uso del generador de documentación como generador de informes.
Para obtener más información sobre Documenter.jl, consulte https://juliadocs.imtqy.com/Documenter.jl/stable/
Conclusión
A pesar de la juventud del lenguaje Julia, los paquetes y herramientas ya desarrollados para él nos permiten hablar sobre el uso completo en servicios altamente cargados, y no solo sobre la implementación de proyectos de prueba. Como puede ver, ya se proporciona la capacidad de generar varios documentos e informes, incluidos los resultados de la ejecución del código, tanto en texto como en forma gráfica. Además, dependiendo de la complejidad del informe, podemos elegir entre la facilidad de crear una plantilla y la flexibilidad de generar informes.
El artículo no considera el generador Flax del paquete Genie.jl. Genie.jl es un intento de implementar Julia on Rails, y Flax es una especie de análogo de eRubis con insertos de código para Julia. Sin embargo, Flax no se proporciona como un paquete separado, y Genie no se incluye en el repositorio principal del paquete, por lo que no se incluyó en esta revisión.
Por separado, me gustaría mencionar los paquetes Makie.jl y Luxor.jl , que proporcionan la formación de visualizaciones vectoriales complejas. El resultado de su trabajo también se puede utilizar como parte de los informes, pero también se debe escribir un artículo separado sobre esto.
Referencias