
Todos los días no se publican materiales escandalosos, importantes y simplemente muy geniales, y ningún editor se comprometerá a predecir el éxito de un artículo con una precisión del 100%. Lo máximo que tiene el equipo es en el nivel de instinto para decir material "fuerte" u "ordinario". Eso es todo. Luego comienza la magia impredecible de los medios, gracias a la cual el artículo puede llegar a la cima de los resultados de búsqueda con docenas de enlaces de otras publicaciones o el material se hundirá en el olvido. Y solo en el caso de la publicación de artículos geniales, los sitios de medios periódicamente caen bajo la monstruosa afluencia de usuarios, que modestamente llamamos el "efecto habrae".
Este verano, el sitio web de la publicación de la
República se convirtió en una víctima de la profesionalidad de sus propios autores: los artículos sobre el tema de la reforma de las pensiones, la educación escolar y la nutrición adecuada en total reunieron una audiencia de varios millones de lectores. La publicación de cada uno de los materiales mencionados condujo a cargas tan altas que hasta la caída del sitio web de la República, quedó absolutamente un "poco espacio". La administración se dio cuenta de que había que cambiar algo: era necesario cambiar la estructura del proyecto de tal manera que pudiera reaccionar vigorosamente a los cambios en las condiciones de trabajo (principalmente carga externa), mientras permanecía completamente funcional y accesible para los lectores incluso en momentos de saltos muy bruscos. Y una gran ventaja sería la mínima intervención manual del equipo técnico de la República en esos momentos.
Según los resultados de una discusión conjunta con expertos de la República sobre varias opciones para implementar la lista de deseos sonora, decidimos transferir el sitio web de la publicación a Kubernetes *. Sobre lo que nos costó a todos, y será nuestra historia de hoy.
* Durante la mudanza, ni un solo especialista técnico republicano resultó heridoCómo se veía en términos generales
Todo comenzó, por supuesto, con negociaciones sobre cómo sucederá todo "ahora" y "más tarde". Desafortunadamente, el paradigma moderno en el mercado de TI implica que tan pronto como cualquier compañía se vaya a un lado por algún tipo de solución de infraestructura, la coloquen en una lista de precios de servicios llave en mano. Parecería que el trabajo es "llave en mano": ¿qué podría ser más y mejor que un director condicional o dueño de un negocio? Pagué y no me duele la cabeza: planificación, desarrollo, apoyo: todo está ahí, por parte del contratista, el negocio solo puede ganar dinero para pagar un servicio tan agradable.
Sin embargo, la transferencia completa de la infraestructura de TI no siempre es apropiada para el cliente a largo plazo. Es más correcto desde todos los puntos de vista trabajar como un gran equipo, de modo que después de que se complete el proyecto, el cliente entienda cómo vivir aún más con la nueva infraestructura, y los colegas en el taller no tengan la pregunta "oh, pero ¿qué hicieron aquí? después de firmar el certificado de finalización y la demostración de los resultados. Los chicos de la República eran de la misma opinión. Como resultado, durante dos meses conseguimos un aterrizaje de cuatro personas para el cliente, que no solo se dieron cuenta de nuestra idea, sino también especialistas técnicamente capacitados en el lado de la República para un mayor trabajo y existencia en las realidades de Kubernetes.
Y todas las partes se beneficiaron de esto: completamos rápidamente el trabajo, mantuvimos a nuestros especialistas listos para los nuevos logros y obtuvimos a Republic como cliente en soporte consultivo con nuestros propios ingenieros. La publicación, por otro lado, recibió una nueva infraestructura adaptada a los "efectos de habra", su propio personal retenido de especialistas técnicos y la capacidad de buscar ayuda si es necesario.
Estamos preparando una cabeza de puente
"Destruir, no construir". Este dicho se aplica a cualquier cosa. Por supuesto, la solución más simple parece ser la toma de rehenes mencionada anteriormente de la infraestructura del cliente y encadenarlo a él, al cliente para sí mismo, o overclocking del personal existente y el requisito de contratar a un gurú en nuevas tecnologías. Fuimos el tercero, no la forma más popular hoy, y comenzamos con la capacitación de ingenieros de la República.
Al comienzo, vimos una solución de este tipo para garantizar el funcionamiento del sitio:
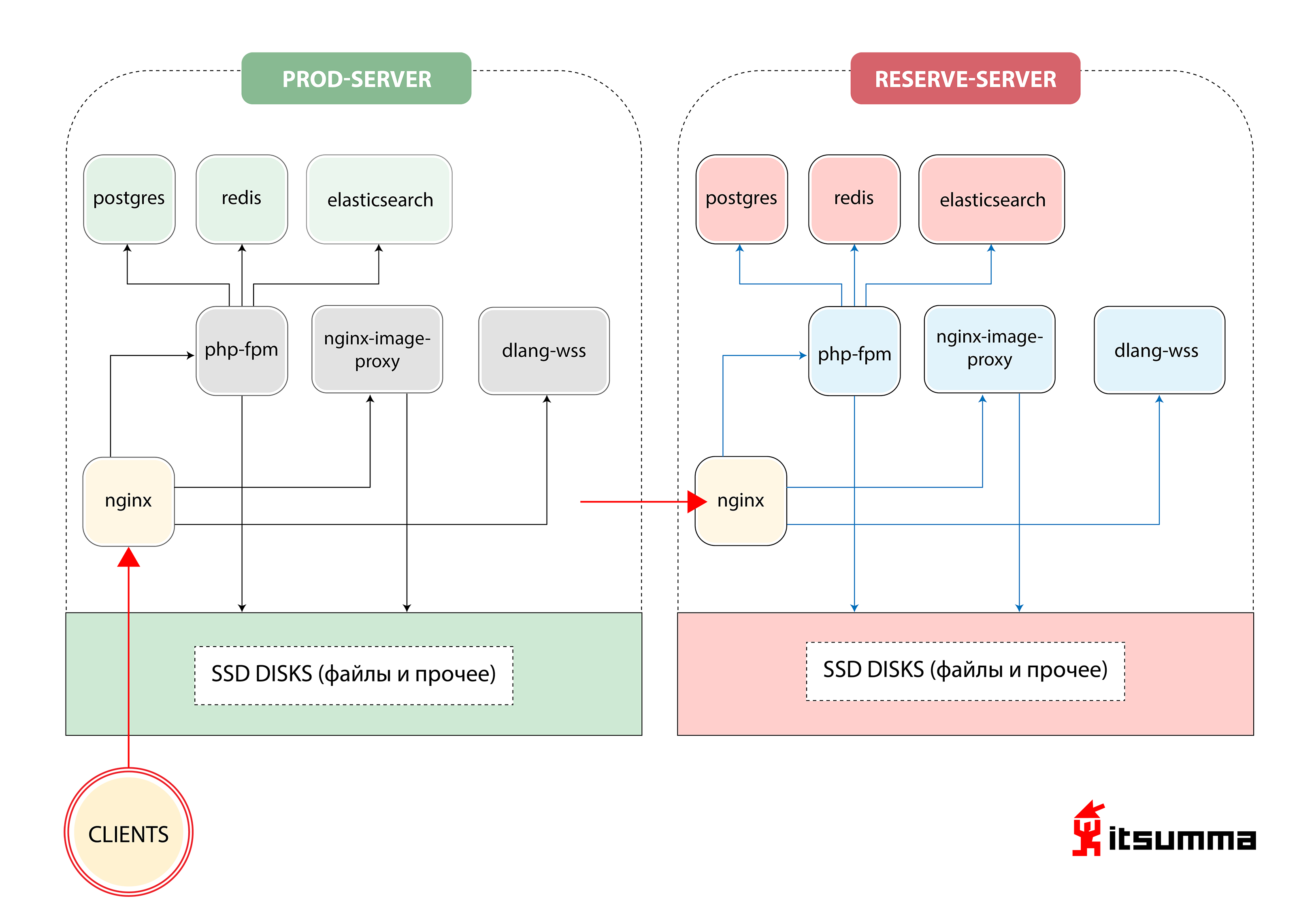
Es decir, Republic tenía solo dos servidores de hierro: el principal y el de respaldo. Lo más importante para nosotros fue lograr un cambio de paradigma en el pensamiento de los especialistas técnicos del cliente, porque antes se ocupaban de un grupo muy simple de NGINX, PHP-fpm y PostgreSQL. Ahora se enfrentaron con la arquitectura escalable de contenedores de Kubernetes. Entonces, primero, cambiamos el desarrollo local de la República al entorno docker-compose. Y este fue solo el primer paso.
Antes de nuestro aterrizaje, los desarrolladores de Republic mantuvieron su entorno de trabajo local en máquinas virtuales configuradas a través de Vagrant, o trabajaron directamente con el servidor de desarrollo a través de sftp. Basado en la imagen básica general de una máquina virtual, cada desarrollador "preconfiguró" su máquina "para sí mismo", lo que dio lugar a un conjunto completo de configuraciones diferentes. Como resultado de este enfoque, la inclusión de nuevas personas en el equipo aumentó exponencialmente el tiempo que ingresaron al proyecto.
En las nuevas realidades, ofrecimos al equipo una estructura más transparente del entorno de trabajo. Describió declarativamente qué software y qué versiones se necesitan para el proyecto, el orden de las conexiones e interacciones entre los servicios (aplicaciones). Esta descripción se cargó en un repositorio git separado para que pueda administrarse de manera conveniente y centralizada.
Todas las aplicaciones necesarias comenzaron a ejecutarse en contenedores Docker separados, y este es un sitio php regular con nginx, muchas estadísticas, servicios para trabajar con imágenes (redimensionar, optimizar, etc.) y ... un servicio separado para sockets web escritos en D Todos los archivos de configuración (nginx-conf, php-conf ...) también se convirtieron en parte de la base del código del proyecto.
En consecuencia, el entorno local fue completamente "recreado", completamente idéntico a la infraestructura del servidor actual. Por lo tanto, se redujo el tiempo requerido para mantener el mismo entorno tanto en las máquinas locales de los desarrolladores como en el producto. Lo que, a su vez, ayudó enormemente a evitar problemas completamente innecesarios causados por las configuraciones locales autoescritas de cada desarrollador.
Como resultado, los siguientes servicios se generaron en el entorno docker-compose:
- web para la aplicación php-fpm;
- nginx;
- impproxy y cairosvg (servicios para trabajar con imágenes);
- postgres
- redis
- búsqueda elástica;
- trompeta (el mismo servicio para sockets web en D).
Desde el punto de vista de los desarrolladores, el trabajo con el código base se mantuvo sin cambios: se montó en los servicios necesarios desde un directorio separado (el repositorio base con el código del sitio) en los servicios necesarios: el directorio público en el servicio nginx, todo el código de la aplicación php en el servicio php-fpm. Desde el directorio separado (que contiene todas las configuraciones del entorno de composición), los archivos de configuración correspondientes se montan en los servicios nginx y php-fpm. Los directorios con postgres de datos, elasticsearch y redis también se montan en la máquina local del desarrollador, de modo que si todos los contenedores tienen que ser reconstruidos / eliminados, los datos en estos servicios no se perderán.
Para trabajar con registros de aplicaciones, también en el entorno de compilación acoplable, se generaron los servicios de la pila ELK. Anteriormente, parte de los registros de la aplicación se escribían en estándar / var / log / ..., los registros de la aplicación php y las ejecuciones se escribían en Sentry, y esta opción de almacenamiento de registro "descentralizado" era extremadamente inconveniente para trabajar. Ahora, las aplicaciones y servicios se han configurado y refinado para interactuar con la pila ELK. El uso de registros se ha vuelto mucho más fácil; los desarrolladores ahora tienen una interfaz conveniente para buscar y filtrar registros. En el futuro (ya en el cubo), puede ver los registros de una versión específica de la aplicación (por ejemplo, un kronzhoba lanzado anteayer).
Además, el equipo de la República comenzó un corto período de adaptación. El equipo necesitaba comprender y aprender a trabajar en el nuevo paradigma de desarrollo, en el cual se debe considerar lo siguiente:
- Las aplicaciones se vuelven sin estado y pueden perder datos en cualquier momento, por lo que trabajar con bases de datos, sesiones y archivos estáticos se debe construir de manera diferente. Las sesiones PHP deben almacenarse centralmente y compartirse entre todas las instancias de la aplicación. Puede seguir siendo archivos, pero más a menudo se toma redis para estos fines debido a su mayor facilidad de administración. Los contenedores para bases de datos deberían "montar" un datadir o la base de datos debería ejecutarse fuera de la infraestructura del contenedor.
- Un almacenamiento de archivos de aproximadamente 50-60 GB de imágenes no debe estar "dentro de la aplicación web". Para tales fines, es necesario utilizar algún almacenamiento externo, sistemas cdn, etc.
- Todas las aplicaciones (bases de datos, servidores de aplicaciones ...) ahora son "servicios" separados, y la interacción entre ellos debe configurarse en relación con el nuevo espacio de nombres.
Después de que el equipo de desarrollo de Republic se acostumbró a las innovaciones, comenzamos a transferir la infraestructura de ventas de la publicación a Kubernetes.
Y aquí está Kubernetes.
Basado en el entorno construido para el desarrollo local docker-compose, comenzamos a traducir el proyecto en un "cubo". Todos los servicios en los que se construye el proyecto localmente, los "empaquetamos en contenedores": organizamos un procedimiento lineal y comprensible para construir aplicaciones, almacenar configuraciones, compilar estadísticas. Desde el punto de vista del desarrollo, eliminaron los parámetros de configuración que necesitábamos en variables de entorno, comenzaron a almacenar sesiones no en archivos, sino en rábanos. Elevamos el entorno de prueba, donde implementamos una versión viable del sitio.
Dado que este es un proyecto monolítico anterior, es obvio que había una relación dura entre las versiones frontend y backend, respectivamente, y estos dos componentes se implementaron al mismo tiempo. Por lo tanto, decidimos construir los pods de la aplicación web de tal manera que dos contenedores giraran en un pod: php-fpm y nginx.
También creamos el escalado automático para que las aplicaciones web escalen a un máximo de 12 en el pico de tráfico, establezcan ciertas pruebas de vida / preparación, porque la aplicación requiere al menos 2 minutos para ejecutarse (ya que necesita calentar el caché, generar configuraciones ...)
Inmediatamente, por supuesto, hubo todo tipo de cardúmenes y matices. Por ejemplo: las estadísticas compiladas eran necesarias tanto para el servidor web que lo distribuyó como para el servidor de aplicaciones en fpm, que en algún lugar sobre la marcha generó algún tipo de imágenes, en algún lugar que svg le dio directamente al código. Nos dimos cuenta de que para no levantarnos dos veces, necesitamos crear un contenedor de construcción intermedio y contenerizar el ensamblaje final a través de múltiples etapas. Para hacer esto, creamos varios contenedores intermedios, en cada uno de los cuales las dependencias se extraen por separado, luego las estadísticas (css y js) se recopilan por separado y luego en dos contenedores, en nginx y en fpm, se copian del contenedor de compilación intermedio.
Empezamos
Para trabajar con archivos en la primera iteración, creamos un directorio común que se sincronizó con todas las máquinas en funcionamiento. Por la palabra "sincronizado" quiero decir aquí exactamente lo que se puede pensar con horror en primer lugar: rsync en un círculo. Obviamente una mala decisión. Como resultado, obtuvimos todo el espacio en disco en GlusterFS, configuramos el trabajo con imágenes para que siempre estuvieran accesibles desde cualquier máquina y nada se ralentizara. Para la interacción de nuestras aplicaciones con los sistemas de almacenamiento (postgres, elasticsearch, redis), se crearon servicios externalName en k8s, de modo que, por ejemplo, en caso de un cambio urgente a la base de datos de respaldo, actualice los parámetros de conexión en un solo lugar.
Todo el trabajo con crones fue llevado a las nuevas entidades k8s: cronjob, que puede ejecutarse de acuerdo con un cronograma específico.
Como resultado, obtuvimos esta arquitectura:
 Clickable
ClickableOh dificil
Este fue el lanzamiento de la primera versión, porque en paralelo con la reestructuración completa de la infraestructura, el sitio todavía estaba siendo rediseñado. Parte del sitio fue construido con algunos parámetros - para estadísticas y todo lo demás, y parte - con otros. Allí era necesario ... para decirlo suavemente ... pervertir con todos estos contenedores de varias etapas, copiar datos de ellos en un orden diferente, etc.
También tuvimos que bailar con panderetas alrededor del sistema CI \ CD para enseñar todo esto a implementar y controlar desde diferentes repositorios y desde diferentes entornos. Después de todo, se necesita un control constante sobre las versiones de la aplicación para que pueda comprender cuándo se implementó un servicio u otro servicio y con qué versión de la aplicación se inició uno u otro error. Para hacer esto, configuramos el sistema de registro correcto (así como la propia cultura de registro) e implementamos ELK. Los colegas aprendieron a establecer ciertos selectores, ver qué cron genera qué errores, cómo se ejecuta generalmente, porque en el "cubo" después de que se ejecuta el contenedor cron, ya no entrará en él.
Pero lo más difícil para nosotros fue reelaborar y revisar todo el código base.
Permítame recordarle que Republic es un proyecto que ahora tiene 10 años. Comenzó con un equipo, otro se está desarrollando ahora, y es realmente difícil extraer todos los códigos fuente para detectar posibles errores y fallas. Por supuesto, en este momento, nuestro grupo de desembarco de cuatro hombres conectó los recursos del resto del equipo: hicimos clic y probamos todo el sitio con pruebas, incluso en aquellas secciones que la gente en vivo no había visitado desde 2016.
No falla en ninguna parte
El lunes, temprano en la mañana, cuando la gente fue al correo masivo con un resumen, todos obtuvimos una apuesta. El culpable se encontró con bastante rapidez: cronjob comenzó y frenéticamente comenzó a enviar cartas a todos los que querían obtener una selección de noticias durante la semana pasada, devorando los recursos de todo el grupo en el camino. No pudimos soportar ese comportamiento, por lo que rápidamente pusimos límites estrictos a todos los recursos: cuánto procesador y memoria puede consumir un contenedor, etc.
¿Cómo hizo frente el equipo de desarrolladores de la República?
Nuestras actividades trajeron muchos cambios, y lo entendimos. De hecho, no solo rediseñamos la infraestructura de la publicación, en lugar del paquete habitual de "servidor de respaldo principal", implementamos una solución de contenedor que conecta recursos adicionales según sea necesario, sino que cambiamos completamente el enfoque para un mayor desarrollo.
Después de un tiempo, los chicos comenzaron a comprender que esto no funciona directamente con el código, sino que funciona con una aplicación abstracta. Dados los procesos CI \ CD (basados en Jenkins), comenzaron a escribir pruebas, obtuvieron entornos completos de desarrollo-etapa-producto donde pueden probar nuevas versiones de su aplicación en tiempo real, ver dónde se cae todo y aprender a vivir Nuevo mundo ideal.
¿Qué recibió el cliente?
En primer lugar, ¡Republic finalmente obtuvo un proceso de implementación controlado! Solía ser: en la República había una persona responsable que fue al servidor, comenzó todo manualmente, luego recopiló estadísticas, comprobó con sus manos que nada se había caído ... Ahora el proceso de implementación se construye para que los desarrolladores se involucren en el desarrollo y no pierdan el tiempo en nada más . Y la persona responsable ahora tiene una tarea: monitorear cómo fue el lanzamiento en general.
Después de que se produce un empuje a la rama maestra, ya sea de forma automática o mediante una implementación de "botón" (periódicamente, debido a ciertos requisitos comerciales, la implementación automática se desactiva), Jenkins entra en la refriega: comienza el ensamblaje del proyecto. Primero, todos los contenedores acoplables se ensamblan: las dependencias (compositor, hilo, npm) se instalan en los contenedores preparatorios, lo que le permite acelerar el proceso de compilación si la lista de bibliotecas requeridas no ha cambiado durante la implementación; luego se recopilan contenedores para php-fpm, nginx, otros servicios, en los que, por analogía con el entorno de compilación de acoplador, solo se copian las partes necesarias de la base de código. Después de eso, se inician las pruebas y, en caso de aprobarlas con éxito, hay un impulso de imágenes a la tienda privada y, de hecho, despliegan implementaciones en el cubo.
Gracias a la transferencia de Republic a k8s, obtuvimos una arquitectura usando un grupo de tres máquinas reales en las que hasta doce copias de la aplicación web pueden "girar" al mismo tiempo. Al mismo tiempo, el sistema mismo, basado en las cargas actuales, decide cuántas copias necesita en este momento. Tomamos Republic de la lotería “funciona - no funciona” con servidores primarios y de respaldo estáticos y construimos un sistema flexible para ellos, listo para un aumento similar a una avalancha en la carga en el sitio.
En este momento, puede surgir la pregunta "muchachos, cambiaron dos piezas de hierro por las mismas piezas de hierro, pero con la virtualización, ¿cuál es la ganancia? ¿Están bien allí?" Y, por supuesto, será lógico. Pero solo en parte. Como resultado, no solo obtuvimos piezas de hardware con virtualización. Conseguimos un entorno de trabajo estable, igual en alimentos y virgo. Un entorno que se gestiona de forma centralizada para todos los participantes del proyecto. Tenemos un mecanismo para ensamblar todo el proyecto y lanzar lanzamientos, nuevamente, lo mismo para todos. Tenemos un conveniente sistema de orquestación de proyectos. Tan pronto como el equipo de Republic se da cuenta de que generalmente dejan de tener suficientes recursos actuales y los riesgos de cargas ultra altas (o cuando ya ha sucedido y todo se ha calmado), simplemente toman otro servidor, en 10 minutos implementan la función de un nodo de clúster en él y op-op Todo es hermoso y bueno de nuevo. La estructura del proyecto anterior no sugería tal enfoque en absoluto; no había soluciones lentas ni rápidas para tales problemas.
En segundo lugar, ha aparecido una implementación perfecta: el visitante podrá acceder a la versión anterior de la aplicación o a una nueva. Y no como antes, cuando el contenido podría ser nuevo, pero los estilos son viejos.
Como resultado, el negocio está satisfecho: todo tipo de cosas nuevas ahora se pueden hacer más rápido y con más frecuencia.
En total, desde "pero intentemos" hasta "hecho", el trabajo en el proyecto tomó 2 meses. El equipo de nuestra parte es un aterrizaje heroico de cuatro personas + soporte para la "base" durante la verificación del código y las pruebas.
Lo que obtuvieron los usuarios
Y los visitantes, en principio, no vieron los cambios. El proceso de implementación de la estrategia de RollingUpdate se construye "a la perfección". El lanzamiento de una nueva versión del sitio de ninguna manera perjudica a los usuarios, la nueva versión del sitio, hasta que pasen las pruebas y las pruebas de vida / preparación, no estarán disponibles. Simplemente ven que el sitio funciona y que no se caerá después de publicar artículos geniales. Que, en general, es lo que cualquier proyecto necesita.