Somos Big Data en MTS y esta es nuestra primera publicación. Hoy hablaremos sobre qué tecnologías nos permiten almacenar y procesar grandes datos para que siempre haya suficientes recursos para el análisis, y el costo de la compra de hierro no llegue a distancias muy altas.
Pensaron en crear el centro de Big Data en MTS en 2014: era necesario escalar el almacenamiento analítico clásico y los informes de BI sobre él. En ese momento, el motor de procesamiento de datos y BI era SAS, sucedió históricamente. Y aunque las necesidades comerciales de almacenamiento se cerraron, con el tiempo, la funcionalidad de BI y análisis ad-hoc en la parte superior del almacenamiento analítico creció tanto que fue necesario resolver el problema del aumento de la productividad, dado que a lo largo de los años el número de usuarios aumentó diez veces y continuó creciendo.
Como resultado del concurso, el sistema Teradata MPP apareció en MTS, cubriendo las necesidades de las telecomunicaciones en ese momento. Este fue el impulso para probar algo más popular y de código abierto.
 En la foto, el equipo de Big Data MTS en la nueva oficina de Descartes en Moscú
En la foto, el equipo de Big Data MTS en la nueva oficina de Descartes en Moscú El primer grupo era de 7 nodos. Esto fue suficiente para probar varias hipótesis de negocios y rellenar los primeros golpes. Los esfuerzos no fueron en vano: Big Data ha existido en MTS durante tres años y ahora el análisis de datos está involucrado en casi todas las áreas funcionales. El equipo creció de tres a doscientos.
Queríamos tener procesos de desarrollo fáciles, probar hipótesis rápidamente. Para hacer esto, necesita tres cosas: un equipo con pensamiento de inicio, procesos de desarrollo livianos e infraestructura desarrollada. Hay muchos lugares donde puede leer y escuchar sobre el primero y el segundo, pero vale la pena contar sobre la infraestructura desarrollada por separado, porque las fuentes de datos y legado que están en las telecomunicaciones son importantes aquí. Una infraestructura de datos desarrollada no solo está construyendo un lago de datos, una capa de datos detallada y una capa de escaparate. También incluye herramientas e interfaces de acceso a datos, aislamiento de recursos informáticos para productos y comandos, mecanismos para entregar datos a los consumidores, tanto en tiempo real como en modo por lotes. Y mucho, mucho más.
Todo este trabajo se ha destacado en un área separada, que se dedica al desarrollo de utilidades y herramientas de datos. Esta área se llama la plataforma de Big Data IT.
¿De dónde viene Big Data en MTS?
MTS tiene muchas fuentes de datos. Una de las principales son las estaciones base; servimos a la base de suscriptores de más de 78 millones de suscriptores en Rusia. También tenemos muchos servicios que no están relacionados con las telecomunicaciones y le permiten recibir datos más versátiles (comercio electrónico, integración de sistemas, Internet de las cosas, servicios en la nube, etc., todos los que no son de telecomunicaciones ya generan alrededor del 20% de todos los ingresos).
Brevemente, nuestra arquitectura se puede representar como un gráfico:
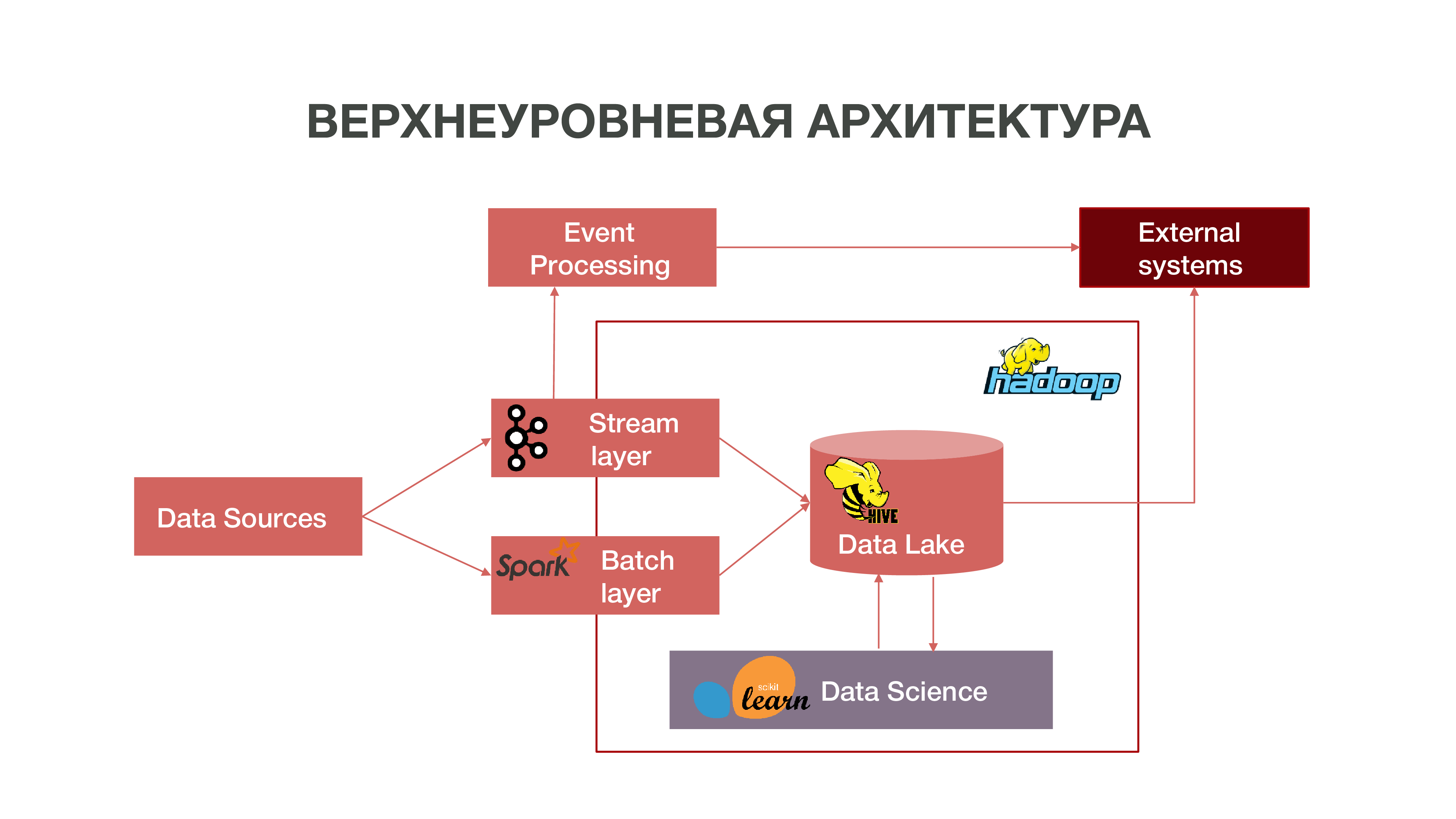
Como puede ver en el gráfico, Datasources puede entregar información en tiempo real. Usamos la capa de transmisión: podemos procesar información en tiempo real, extraer de ella algunos eventos que nos interesan y desarrollar análisis al respecto. Para proporcionar dicho procesamiento de eventos, hemos desarrollado una implementación bastante estándar (desde el punto de vista de la arquitectura) usando Apache Kafka, Apache Spark y código en el lenguaje Scala. La información obtenida como resultado de dicho análisis se puede consumir tanto dentro de MTS como en el futuro fuera: las empresas a menudo están interesadas en el hecho de ciertas acciones de los suscriptores.
También hay un modo de cargar datos en lotes: capa de lotes. Por lo general, la descarga se realiza una vez por hora en un horario, usamos Apache Airflow como el programador, y los procesos de descarga por lotes se implementan en Python. En este caso, se carga una cantidad significativamente mayor de datos en Data Lake, que es necesario para llenar Big Data con datos históricos, sobre los cuales se deben capacitar nuestros modelos de Data Science. Como resultado, se forma un perfil de suscriptor en el contexto histórico basado en datos sobre la actividad de su red. Esto nos permite obtener estadísticas predictivas y construir modelos de comportamiento humano, incluso crear un retrato psicológico de él: tenemos un producto tan separado. Esta información es muy útil, por ejemplo, para empresas de marketing.
También tenemos una gran cantidad de datos que componen el repositorio clásico. Es decir, agregamos información sobre varios eventos, tanto de usuario como de red. Todos estos datos anónimos también ayudan a predecir con mayor precisión los intereses y eventos de los usuarios que son importantes para la empresa, por ejemplo, para predecir posibles fallas de equipos y solucionar problemas a tiempo.
Hadoop
Si observa el pasado y recuerda cómo aparecieron los grandes datos en general, debe tenerse en cuenta que, básicamente, la acumulación de datos se realizó con fines de marketing. No existe una definición tan clara de lo que son los grandes datos: son gigabytes, terabytes, petabytes. Imposible dibujar una línea. Para algunos, el big data es decenas de gigabytes, para otros, petabytes.
Dio la casualidad de que con el tiempo se han acumulado muchos datos en todo el mundo. Y para llevar a cabo algún tipo de análisis más o menos significativo de estos datos, los depósitos habituales que se han estado desarrollando desde los años 70 del siglo pasado ya no eran suficientes. Cuando comenzó el flujo de información en los años 2000, 10 y cuando había muchos dispositivos que tenían acceso a Internet, cuando apareció el Internet de las cosas, estos repositorios simplemente no podían hacer frente conceptualmente. La base de estos repositorios era la teoría relacional. Es decir, había relaciones de diferentes formas que interactuaban entre sí. Había un sistema para describir cómo construir y diseñar repositorios.
Cuando las viejas tecnologías fallan, aparecen nuevas. En el mundo moderno, el problema del análisis de big data se resuelve de dos maneras:
Creando su propio marco que le permite procesar grandes cantidades de información. Por lo general, esta es una aplicación distribuida de muchos cientos de miles de servidores, como Google, Yandex, que han creado sus propias bases de datos distribuidas que le permiten trabajar con tal volumen de información.
El desarrollo de la tecnología Hadoop es un marco informático distribuido, un sistema de archivos distribuido que puede almacenar y procesar una gran cantidad de información. Las herramientas de Data Science son principalmente compatibles con Hadoop y esta compatibilidad abre muchas posibilidades para el análisis avanzado de datos. Muchas empresas, incluidos nosotros, se están moviendo hacia el ecosistema de código abierto de Hadoop.
El grupo central de Hadoop se encuentra en Nizhny Novgorod. Acumula información de casi todas las regiones del país. En términos de volumen, ahora se pueden descargar allí alrededor de 8,5 petabytes de datos. También en Moscú, tenemos grupos separados de RND donde realizamos experimentos.
Dado que tenemos alrededor de un millar de servidores en diferentes regiones, donde llevamos a cabo análisis, además de planificar la expansión, surge la cuestión de la elección correcta de equipos para sistemas analíticos distribuidos. Puede comprar equipo que sea suficiente para el almacenamiento de datos, pero que resulta inadecuado para el análisis, simplemente porque no habrá suficientes recursos, la cantidad de núcleos de CPU y RAM libre en los nodos. Es importante encontrar un equilibrio para obtener buenas oportunidades de análisis y costos de equipo no muy altos.
Intel nos ofreció diferentes opciones sobre cómo optimizar el trabajo con un sistema distribuido para que se puedan obtener análisis en nuestro volumen de datos por dinero razonable. Intel avanza la tecnología de unidad de estado sólido SSD NAND Es cientos de veces más rápido que un HDD normal. Lo que es bueno para nosotros: SSD, especialmente con la interfaz NVMe, proporciona un acceso lo suficientemente rápido a los datos.
Además, Intel lanzó los SSD del servidor Intel Optane SSD basados en el nuevo tipo de memoria no volátil Intel 3D XPoint. Enfrentan cargas mixtas intensivas en el sistema de almacenamiento y tienen un recurso más largo que los SSD NAND normales. ¿Por qué es bueno para nosotros ?: Intel Optane SSD le permite trabajar de manera estable bajo cargas pesadas con baja latencia. Inicialmente vimos el NAND SSD como un reemplazo para los discos duros tradicionales, porque tenemos una gran cantidad de datos que se mueven entre el disco duro y la RAM, y necesitábamos optimizar estos procesos.
Primera prueba
La primera prueba que realizamos en 2016. Simplemente tomamos e intentamos reemplazar el HDD con un SSD NAND rápido. Para hacer esto, pedimos muestras del nuevo disco Intel, en ese momento era DC P3700. Y ejecutaron la prueba estándar de Hadoop, un ecosistema que le permite evaluar cómo cambia el rendimiento en diferentes condiciones. Estas son pruebas estandarizadas TeraGen, TeraSort, TeraValidate.

TeraGen le permite "generar" datos artificiales de un determinado volumen. Por ejemplo, tomamos 1 GB y 1 TB. Con TeraSort, clasificamos esta cantidad de datos en Hadoop. Esta es una operación bastante intensiva en recursos. Y la última prueba, TeraValidate, le permite asegurarse de que los datos estén ordenados en el orden correcto. Es decir, los revisamos por segunda vez.

Como experimento, tomamos autos solo con SSD, es decir, Hadoop instaló solo en SSD sin usar discos duros. En la segunda versión, utilizamos SSD para almacenar archivos temporales, HDD, para almacenar datos básicos. Y en la tercera versión, se utilizaron discos duros para ambos.
Los resultados de estos experimentos no fueron muy agradables para nosotros, porque la diferencia en los indicadores de rendimiento no superó el 10-20%. Es decir, nos dimos cuenta de que Hadoop no es muy amigable con los SSD en términos de almacenamiento, porque inicialmente el sistema fue creado para almacenar grandes datos en el HDD, y nadie lo optimizó especialmente para SSD rápidos y costosos. Y dado que el costo de SSD en ese momento era bastante alto, decidimos hasta ahora no entrar en esta historia y sobrevivir con los discos duros.
Segunda prueba
Luego, Intel presentó las nuevas SSD Intel Optane del lado del servidor basadas en la memoria 3D XPoint. Fueron lanzados a fines de 2017, pero las muestras estaban disponibles antes. Las características de memoria 3D XPoint hacen posible el uso de la SSD Intel Optane como una extensión de RAM en los servidores. Como ya nos dimos cuenta de que no sería fácil resolver el problema de rendimiento de IO Hadoop a nivel de dispositivos de almacenamiento en bloque, decidimos probar una nueva opción: expandir la RAM utilizando la tecnología Intel Memory Drive (IMDT). Y a principios de este año, fuimos uno de los primeros en el mundo en probarlo.
Esto es bueno para nosotros: es más barato que la RAM, lo que le permite recolectar servidores que tienen terabytes de RAM. Y como la RAM es lo suficientemente rápida, puede cargar grandes conjuntos de datos en ella y analizarlos. Permítame recordarle que la peculiaridad de nuestro proceso analítico es que accedemos a los datos varias veces. Para realizar algún tipo de análisis, necesitamos cargar la mayor cantidad de datos posible en la memoria y "desplazar" varias veces algún tipo de análisis de estos datos.
El laboratorio de inglés de Intel en Swindon nos asignó un grupo de tres servidores, que durante las pruebas comparamos con nuestro grupo de pruebas ubicado en MTS.

Como se puede ver en el gráfico, de acuerdo con los resultados de la prueba, obtuvimos resultados bastante buenos.
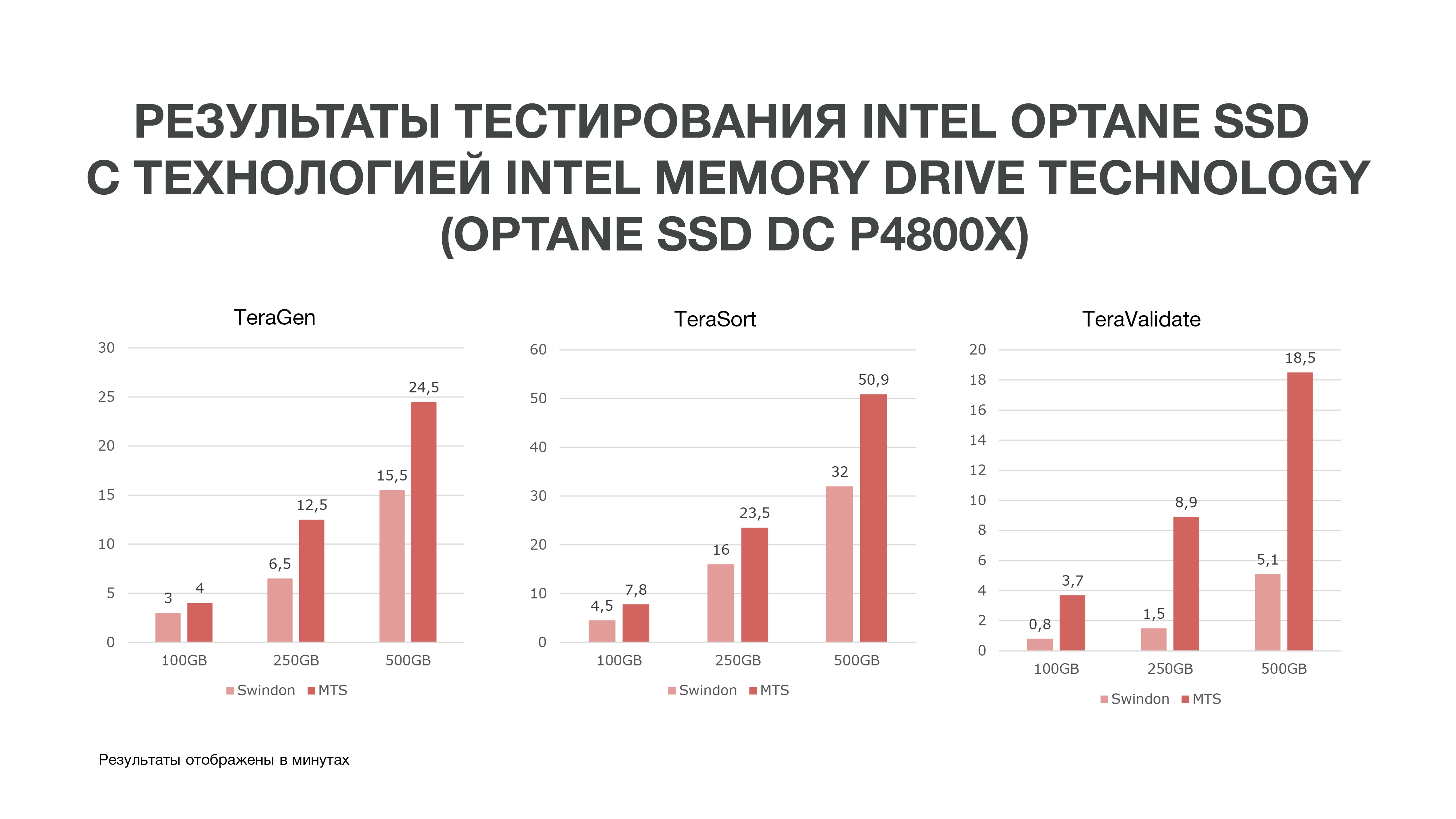
El mismo TeraGen mostró un aumento casi doble en la productividad, TeraValidate, en un 75%. Esto es muy bueno para nosotros porque, como dije, accedemos a los datos que tenemos en nuestra memoria varias veces. En consecuencia, si obtenemos tal aumento de rendimiento, esto nos ayudará especialmente en el análisis de datos, especialmente en tiempo real.
Realizamos tres pruebas en diferentes condiciones. 100 GB, 250 GB y 500 GB. Y cuanto más usamos la memoria, el SSD Intel Optane con tecnología Intel Memory Drive funcionó mejor. Es decir, cuantos más datos analizamos, más eficiencia conseguimos. La analítica que se realizó en más nodos puede realizarse en menos de ellos. Y también obtenemos una cantidad bastante grande de memoria en nuestras máquinas, lo cual es muy bueno para las tareas de Data Science. Según los resultados de la prueba, decidimos comprar estas unidades para trabajar en MTS.
Si también tuvo que elegir y probar hardware para almacenar y procesar una gran cantidad de datos, estaremos interesados en leer qué dificultades encontró y qué resultados obtuvo: escriba los comentarios.
Autores
Grigory Koval, jefe del Centro de Competencia de Arquitectura Aplicada del Departamento de Big Data de MTS, grigory_koval
Jefe de la tribu de gestión de datos del Departamento de Big Data MTS Dmitry Shostko zloi_diman